

Feed aggregator
Oracle VirtualBox 7.2.14
Oracle released VirtualBox 7.2.14 a couple of days ago. As I mentioned in my previous post, I was expecting this release to coincide with the the normal quarterly patch cycle. The downloads and changelog are in the usual places. I’ve done installations on Windows 11 and Linux Mint and both worked fine. Vagrant I didn’t bother updating my Vagrant boxes for … Continue reading "Oracle VirtualBox 7.2.14"
The post Oracle VirtualBox 7.2.14 first appeared on The ORACLE-BASE Blog.Oracle VirtualBox 7.2.14 was first posted on July 23, 2026 at 6:30 am.©2024 "The ORACLE-BASE Blog". Use of this feed is for personal non-commercial use only. If you are not reading this article in your feed reader, then the site is guilty of copyright infringement. Please contact me at timseanhall@gmail.com
Customer experience – Certificat SSL on an SQL Server Reporting Services
Recently, I had to renew an SSL certificate on an SQL Server Reporting Services (SSRS) server. The task seemed straightforward: replacing an expired certificate with a new one containing the same configuration. However, once the change had been made, HTTPS wasn’t working anywhere — neither via the usual DNS names nor even when accessing the server directly. Only HTTP remained accessible.
Here is a step-by-step guide to how the problem was solved.
SymptomAfter the certificate was renewed:
- HTTP was working normally, both remotely and locally.
- HTTPS was not working.
- There were no certificate warnings or TLS errors: the issue manifested as an application error (404).
A 404 error is an application error, not an encryption error. It means that the TLS connection was established correctly (the certificate was presented and accepted), but that the server could not find any resource matching the request.
 Step 1: Check the installed certificate
Step 1: Check the installed certificate
The first thing to check in any case is the certificate. Go to the server certificates and select the proprieties of the right certificate. You must ensure that it does indeed contain the correct SANs (Subject Alternative Names).
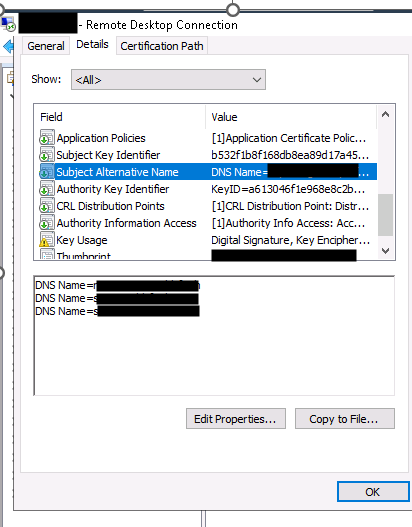
A point that is often overlooked: the CN (Common Name) of a certificate is no longer considered 100 per cent reliable. If you wish to connect via HTTPS using a specific name . That name must be included in the certificate’s SAN field, and not just in the CN.
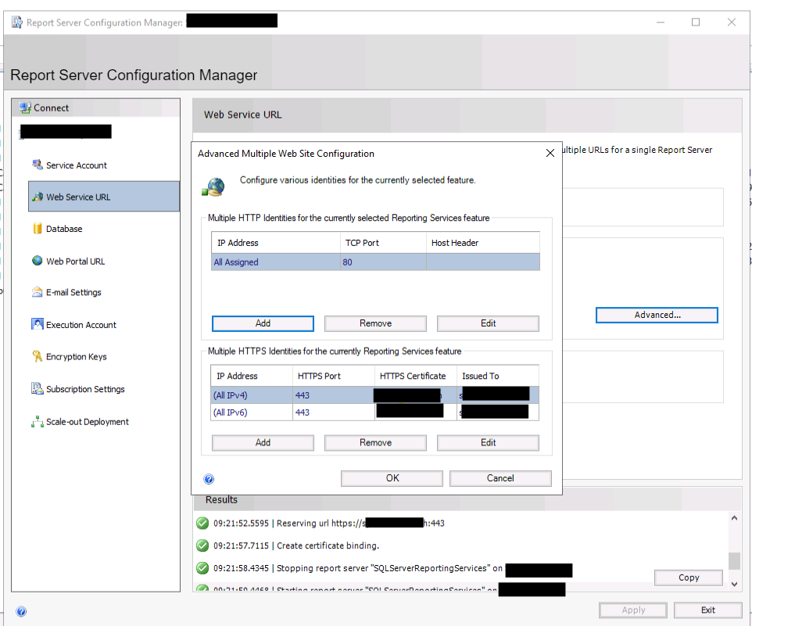
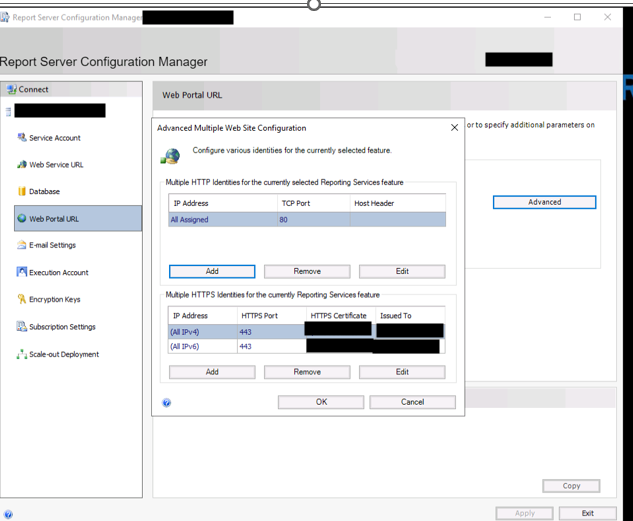
Step 2: Check the SSRS configurationThe next step is to check the configuration of SSRS itself:
- Check that the certificate has been correctly associated with the service in Reporting Services Configuration Manager (Web Service URL and Web Portal URL).
- Check that the certificate is recognised for both IPv4 and IPv6.
- Ensure that the binding is consistent on both the SSRS service side and the server side (Windows / HTTP.sys).
This final check can be carried out via the command line using:
netsh http show sslcertThis command lists the mappings between IP addresses/ports and certificates (identified by their hash). In my case, the binding was set up using wildcards (0.0.0.0:443 and [::]:443) with a single certificate for all incoming HTTPS requests on port 443.
 Step 4: URL Reservations
Step 4: URL Reservations
It was whilst looking into reserved URLs that the problem came to light. The following command lists the URLs reserved with HTTP.sys, the Windows component that manages HTTP/HTTPS listening at the system level:
netsh http show urlaclThe result revealed the source of the problem: the entries did indeed exist, but only for the server name, with an explicit host header. However, as the server name was not present in the certificate’s SAN. This is why the HTTPS connection was not working either:
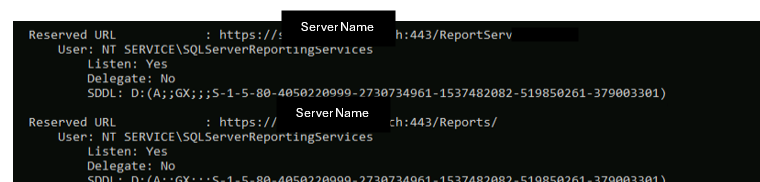 Reserve the right URLs
Reserve the right URLs
The fix involves recreating the reservations assigned to each DNS so that the host header is accepted. Here, we add the URL by specifying the service account. It is important to add the SDDL (Security Descriptor Definition Language) . This is used to grant service accounts (like ReportServer) the permissions required to reserve specific URLs for web traffic. For SSRS 2017 and later, the AccountSid value is S-1-5-80-4050220999-2730734961-1537482082-519850261-379003301 and the AccountName value is NT SERVICE\SQLServerReportingServices. For Power BI Report Server, the AccountSid value is S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663 and the AccountName value is NT SERVICE\PowerBIReportServer. Here, we use the specifications for SSRS
cmd
netsh http add urlacl url=https://"dns.name":443/Reports
user="NT Service\ReportServerSQLServerReportingServices" sddl=D:(A;;GX;;;S-1-5-80-4050220999-2730734961-1537482082-519850261-379003301)
netsh http add urlacl url=https://"dns.name":443/ReportServer
user="NT Service\SQLServerReportingServices" sddl=D:(A;;GX;;;S-1-5-80-4050220999-2730734961-1537482082-519850261-379003301)
Once the previous steps had been completed without any issues being detected, the certificate contained the correct SANs, the SSRS configuration appeared to be consistent, and the DNS records were correctly pointing to the correct IP address. we had to dig deeper into the service’s configuration file itself:
C:\Program Files\Microsoft Power BI Report Server\PBIRS\ReportServer\rsreportserver.config
Contrary to what one might think, URL reservations at the HTTP.sys level (netsh http show urlacl) are not sufficient on their own: the SSRS/PBIRS service also maintains its own list of authorised names directly within this configuration file. Additions must be made after this tag : one entry for the web service (/ReportServer/) and another for the web portal (/Reports/). If a DNS entry is not explicitly declared in both of these locations, the service may refuse to recognise it as a valid name, even though HTTP.sys would be prepared to allow the request through.
The fix therefore involves manually editing the rsreportserver.config file and adding each relevant DNS to both instances of the tag, whilst strictly adhering to the syntax already in place for the existing entries.
Once changes have been made, the service must be restarted for the changes to take effect.
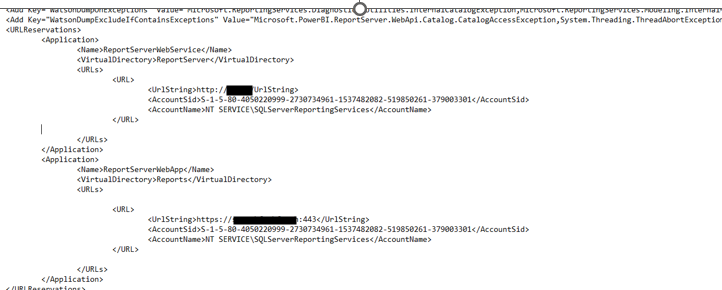 In summary
In summary
So here are a few key points to bear in mind:
- A 404 error over HTTPS following a certificate change is not necessarily related to the certificate itself. If the TLS connection is established without any warnings, the problem is likely to lie in application routing (URL reservations), not in the trust chain.
netsh http show urlaclandnetsh http show sslcertare the two key commands for distinguishing between a certificate binding issue and a URL reservation issue.- An explicit host header (name:443) restricts access to that name only
- The service account is just as important as the URL itself. A technically correct reservation that is associated with the wrong account will prevent the service from creating its own endpoint, resulting in an E_ACCESSDENIED error on start-up.
Some Sources:
About reservations URL :Configure Reporting Services to use a Subject Alternative Name (SAN) – SQL Server Reporting Services (SSRS) | Microsoft Learn
About Common name on certificat : Chrome 58: Common Name in SSL Certificates Finally Dies | Dataprise
L’article Customer experience – Certificat SSL on an SQL Server Reporting Services est apparu en premier sur dbi Blog.
When an idle transaction starves the worker pool (THREADPOOL)
A production instance, mid-afternoon, nothing unusual on any dashboard. An engineer opens a transaction to patch a single row while investigating a data issue:
BEGIN TRANSACTION;
UPDATE dbo.Orders SET Status = 'Reviewed' WHERE OrderId = 482193;
No COMMIT. No ROLLBACK. The tab gets buried under three others, the investigation moves on, and the lock is still held an hour later.
Every query, every batch, every login needs a worker thread to execute on. That pool is not infinite, it is sized by max worker threads, either left on its computed default or pinned to a fixed number.
SELECT name, value_in_use FROM sys.configurations WHERE name = 'max worker threads';
name value_in_use
----------------------------------- -------------------------------------------------------------------------------------------------------------------------
max worker threads 128
SQL Server schedules work cooperatively, not preemptively. Each worker is handed a quantum (4 milliseconds) to run before it is expected to voluntarily yield the scheduler to the next runnable task. This is the mechanism behind SOS_SCHEDULER_YIELD: a worker that still has work to do, but whose quantum has expired, stepping aside so someone else gets a turn.
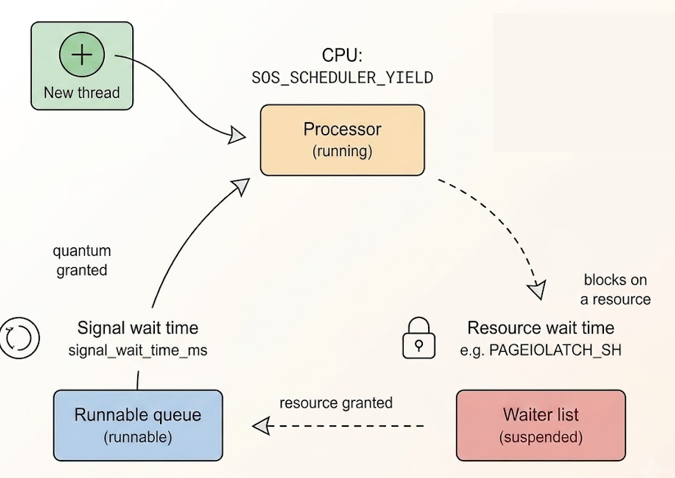
None of this applies to the open transaction from earlier. A session that has issued no command has no task and holds no worker. Its status in sys.dm_exec_sessions is sleeping, not running, not suspended.
SELECT
s.session_id,
s.status AS session_status,
ct.text
FROM sys.dm_exec_sessions s
LEFT JOIN sys.dm_exec_requests r ON s.session_id = r.session_id
LEFT JOIN sys.dm_exec_connections c ON s.session_id = c.session_id
OUTER APPLY sys.dm_exec_sql_text(c.most_recent_sql_handle) ct
WHERE s.session_id = 54;
session_id session_status text
---------- ------------------------------ --------------------------------------------------------------------------------------------------------------------
54 sleeping UPDATE dbo.Orders SET Status = 'Reviewed' WHERE OrderId = 482193;
It is not waiting for a quantum, because it is not competing for one. The lock it holds costs the engine nothing in scheduling terms; it is bookkeeping in the lock manager, entirely separate from the worker pool.
Two hundred sessions walk into a lockLet’s say that the application wants to confirm that the orders has been reviewed now it’s in the processed state.
BEGIN TRANSACTION;
UPDATE dbo.Orders SET Status = 'Processed' WHERE OrderId = 482193;
Seeing that the query didn’t complete to update the item, it will keep sending this transaction again and again, sending it 200 times let’s say.
Unlike the sleeping session above, each of these has issued a command. Each one is granted a worker to execute it, immediately hits the lock, and transitions to suspended, waiting on LCK_M_X.
wait_type waiting_tasks_count wait_time_ms
THREADPOOL 521 2881770
SOS_SCHEDULER_YIELD 710 41
session_id status wait_type wait_time blocking_session_id
68 suspended LCK_M_X 29873 54
...
206 suspended LCK_M_X 29478 68
207 suspended LCK_M_X 29478 68
scheduler_id runnable_tasks_count work_queue_count active_workers_count
0 0 19 43
1 0 5 45
2 0 10 45
3 0 2 44
active_workers max_workers_count
205 128
Note: max_workers_count only counts the user-facing pool; internal system threads, including the DAC’s own reserved worker used to capture this very output, sit outside that ceiling.
The worker is not released while the task waits. It stays attached to the suspended task for the entire duration of the block, doing nothing, simply reserved, waiting for the resource (the order line to update) to be available for updates.
The remainder cannot even be granted a worker to start waiting. They queue behind everyone else, and eventually give up entirely:
Login timeout expired
Login/Query timeout: 15/0 seconds
By this point the server has simply stopped accepting new connections.
When the fire exit is also on fireReleasing the original lock should be the easy part: switch back to the session from the very first transaction, issue a ROLLBACK, and watch everything clear. Except that session, which has been sitting sleeping and worker-free this whole time, now has to issue a command of its own. And issuing a command means asking the pool for a worker (the same exhausted pool every other session is already queued for). The session responsible for the deadlock has no priority for fixing it. It gets in line like everyone else, behind two hundred sessions it created the conditions for.
This is where the Dedicated Admin Connection comes in the game. It runs on its own scheduler, with a worker reserved outside the regular pool, built specifically for an instance too exhausted to serve itself.
sqlcmd -A -S"." -E
SELECT blocking_session_id
FROM sys.dm_exec_requests
WHERE blocking_session_id <> 0;
KILL 54;
Note: the “.” here resolves to the local default instance but unlike an ordinary local connection (which typically uses Shared Memory), the DAC always connects over its own dedicated TCP listener on the loopback adapter, regardless of protocol settings on the port 1434 or a dynamic one (full documentation here).
The KILL forces the rollback from outside the exhausted pool entirely. Workers free up in cascade, and the two hundred suspended sessions complete their updates and release their own.
In this example, we set the parameter max worker threads to 128 to easily saturate the worker threads. However, the default value for max worker threads is 0, which lets SQL Server compute the number of worker threads automatically at startup based on the number of logical CPUs and the platform architecture. Microsoft best practice can be found here and shows the following table:
And the key take-away from this experiment:
- Sleeping costs nothing, suspended costs a worker. The distinction between an idle transaction and a blocked one is the entire mechanism behind this incident: both hold a lock, only one of them holds a thread.
- The scheduler’s quantum explains CPU pressure, not threadpool exhaustion. Yielding after 4ms is about sharing a CPU among runnable workers; it has nothing to do with how many workers exist in the first place.
- The session that caused the block is not exempt from the consequences of the block. It has to compete for a worker like anything else, the moment it tries to clean up after itself.
- Never let a statement end without a
COMMITor aROLLBACK.
L’article When an idle transaction starves the worker pool (THREADPOOL) est apparu en premier sur dbi Blog.
Why search is the most underrated ECM feature
When organizations evaluate an Enterprise Content Management (ECM) solution, the conversation usually revolves around Artificial Intelligence, workflow automation, and integrations.
Yet the feature employees use more than any other is rarely the one showcased in demonstrations or marketing brochures: search.

The reality is simple. Most users don’t spend their days creating workflows or configuring metadata. They spend it looking for information.
Every unsuccessful search comes at a cost!
Search happens more often than you thinkThink about your workday.
How many documents do you create?
Maybe a few.
How many do you approve?
Perhaps a few more.
Now, ask yourself a different question: How many times do you search for information?
Procedures, invoices, contracts, customer communications…
For most employees, searching is the most common interaction with an ECM system by far.
This means that even minor improvements to the search function can significantly impact productivity.
Finding a document is only half the problemMany ECM vendors claim they can find any document in seconds.
That’s great, but it’s often not enough.
Imagine a customer calls about an invoice. You know the supplier, but not the invoice number.
A good ECM lets you find the document in seconds by searching the supplier, project, purchase order, or even the contract linked to it.
A poor search experience forces you to browse folders, ask colleagues, or search through emails.
An effective search is about relevance, not just speed.
Search starts long before someone types a keywordMany organizations try to improve their search function by tweaking the search engine.
In reality, a good search starts much earlier.
It begins with:
- meaningful metadata
- consistent naming conventions
- well-designed object relationships
- document classifications
- quality-controlled information
Poor information management cannot be fixed with search alone.
Even the most advanced search engine will struggle to deliver useful results if the metadata is inconsistent or incomplete.
Search should reduce decisionsA good search experience should minimize the amount of thought required of users.
Instead of asking:
“What was the exact document name?”
Users should be able to search naturally:
- customer name
- supplier
- project
- Invoice number
- Contract type
- Date
- Keywords
The system should handle the complexities.
Users shouldn’t need to understand how the information is stored.
What about AI?Generative AI doesn’t replace search, it changes users’ expectations of search.
Now users want to be able to ask questions like:
“Show me all contracts that expire next quarter.”
Or:
“Find the latest approved procedure for handling customer complaints.”
Behind these simple questions lies something much less glamorous: reliable metadata.
Without it, AI cannot consistently provide trustworthy answers.
In many ways, AI has made search even more important.
Search is a user experience featureWhen discussing user adoption, project teams often focus on training.
Training certainly matters.
However, the user experience during searches is also important.
If employees consistently find what they need in seconds, their confidence in the system grows.
However, if they repeatedly fail to find information, they’ll quickly return to shared drives, email folders, or ask colleagues for help.
The quality of the search function shapes the perception of the entire enterprise content management (ECM) solution.
Search is a business capabilityA good search is about more than just saving a few minutes.
- It enables better decision-making.
- It prevents duplicate work.
- It improves compliance.
- It accelerates customer service.
- It helps preserve organizational knowledge.
The value of an ECM system isn’t measured by how many documents it stores.
Rather, it’s measured by how effectively those documents can be found and used.
Final wordsSearch rarely appears as the headline feature in product demonstrations because every ECM platform offers some form of search.
The real difference isn’t whether a system can search, it’s how effectively users can find the right information when they need it.
A successful ECM implementation isn’t one where information is simply stored.
Rather, it’s one where information is found effortlessly, trusted confidently, and reused effectively.
After all, a document that can’t be found might as well not exist.
L’article Why search is the most underrated ECM feature est apparu en premier sur dbi Blog.
Zabbix Agent 2 service terminated unexpectedly on Windows server
The Zabbix Agent 2 service on a Windows server was repeatedly becoming unresponsive and eventually crashing. The issue caused intermittent monitoring interruptions and required further investigation through Event Viewer messages and Zabbix Agent 2 logs to better understand why the service was no longer responding properly.
While monitoring a Windows server with Zabbix Agent 2, we encountered repeated crashes of the agent service accompanied by the following Event Viewer message:
A timeout (30000 milliseconds) was reached while waiting for a transaction response from the Zabbix Agent 2 service.
A few moments later, Windows reported:
The Zabbix Agent 2 service terminated unexpectedly.
The first assumption was that a plugin or item was taking too long to execute, causing the agent to become unresponsive. A natural idea was therefore to increase the timeout value. Here the official documentation for the PluginTimout.
Inside the Zabbix Agent 2 configuration, we identified the following parameter:
### Option:PluginTimeout
# Timeout for connections with external plugins.
## Mandatory: no
# Range: 1-30
# Default: <Global timeout>
# PluginTimeout=
However, this parameter only supports values between 1 and 30 seconds.
This raised an important question:
If a timeout already exists, why does the entire agent still become blocked and eventually crash?
Understanding the ProblemZabbix Agent 2 uses a plugin-based architecture written in Go.
Unlike isolated external processes, many plugins run inside the same agent process.
This means that if a plugin becomes blocked:
- worker threads remain occupied
- new requests start queuing
- the agent gradually stops responding
- Windows eventually considers the service frozen
The 30-second timeout seen in Event Viewer is actually the Windows Service Control Manager (SCM) timeout, not a protection mechanism for the plugin itself.
In other words:
- the plugin blocks first
- the agent becomes unresponsive
- Windows waits 30 seconds
- Windows kills the service
The Zabbix Agent 2 logs quickly pointed toward the real culprit.
[WindowsPerfMon] failed to get performance counters data:'cannot collect value No data to return.'
This indicated that the agent was struggling to collect Windows Performance Counters.
The most important recurring message was:
[WindowsPerfInstance] Cannot refresh object cache:Unable to connect to the specified computer or the computer is offline.
This error appeared continuously for several days.
The key observation here is that the agent was running locally, so the message below should never normally appear:
Unable to connect to the specified computer
This strongly suggested:
- an invalid or corrupted performance counter
- a problematic PerfMon object
- or a failing wildcard instance (
Process(*),LogicalDisk(*), etc.)
Later in the logs, additional symptoms appeared:
failed to accept an incoming connection:accept tcp [::]:10050:acceptex: The I/O operation has been aborted because of either a thread exit or an application request.
At this stage, the agent was no longer able to accept incoming connections because its internal workers were saturated or blocked.
This confirmed that the issue was not a traditional crash, but rather a thread starvation / blocking situation.
Why the Existing 30s Timeout Was Not EnoughAn important misunderstanding was clarified during the investigation.
The default timeout value of 30 seconds does not immediately protect the agent.
Instead:
- the plugin may block for the full 30 seconds
- multiple blocked requests accumulate
- worker threads remain occupied
- the agent becomes globally unresponsive
By the time Windows notices the issue, the agent is already effectively frozen.
The Solution: Reduce PluginTimeoutInstead of increasing the timeout, the correct approach was to reduce it significantly.
The following configuration was applied:
PluginTimeout=15
This acts as a protection mechanism inside the agent itself.
With this configuration:
- problematic plugin executions are aborted quickly
- blocked threads are released faster
- the agent remains responsive
- only the affected items temporarily fail
The issue was not caused by the timeout itself.
The real root cause was a problematic WindowsPerfInstance plugin execution blocking the Zabbix Agent 2 internal workers.
Reducing the plugin timeout from 30 seconds to 15 seconds prevented the entire agent from becoming unresponsive while still allowing the monitoring system to recover automatically when the plugin started responding again.
This is a good example of why increasing timeouts is not always the right solution. Sometimes, shorter timeouts are actually what keeps a monitoring agent stable.
You can find other blogs regarding Zabbix or database administration or other topics at this link: dbi blogs
L’article Zabbix Agent 2 service terminated unexpectedly on Windows server est apparu en premier sur dbi Blog.
Oracle GenAI – Ask EM – Deploy Oracle Enterprise Manager 24ai from Marketplace
I have been looking to study and test what Oracle GenAI Ask EM assistant, also called now Oracle AI database assistant, can offer. This generative AI assistant is directly integrated into Oracle Enterprise Manager 24ai. Before being able to look into Ask EM, I first had to install an Oracle EM platform. I had the choice between doing all the installation myself manually or installing it from Oracle Marketplace. Knowing my current need, I decided to install it from the Oracle Marketplace. I would like to share in this first Ask EM series blogs this installation.
Pros and Cons for a Marketplace installationFor my current purpose of getting a lab in order to test GenAI Ask EM feature, the advantages of doing an installation from the marketplace are the following:
- Faster and less work to get a working environment ready for Ask Em testing
- Less possible errors and problems
- Oracle prope a full preconfigured image with OS and EM
- Minimalize deployement time
- More time to focus on Ask EM testing
The disadvantage would be to have:
- Less flexibility
But I really do not need any customized installation.
The manual installation complexity would mainly be to install and configure manually:
- Oracle VM with OS (Oracle Linux)
- EM repository database
- EM weblogic
- EM software installation and patching
- OMS
- …
Please note following:
- I will be installing a simple deployment sizing lab.
- Enterprise Manager Instance Shape, VM.Standard2.4, will then be suffisient.
- I will use existing VCN and subnet
- I will make a single node installation with Enterprise Manager and database installed in a private subnet. This will have the benefit not to expose the Instance on the public network. I will then need a bastion VM which will be part of the installation
But what would be the cost? The cost will come mainly from the cost of the components:
- Compute instance will be charged based on the shape, OCPU and memory. It is in general the biggest cost
- Block Volume which is charged per provisioned GB
- Networking. VCN, subnets and security lists are free of charge, and are anyhow already existing.
- Single instance repository database does not require any license
- Use EM features only covered by your existing oracle licenses. Pack such as the Diagnostics Pack, Tuning Pack, Lifecycle Management Pack, etc., require the appropriate licenses.
The EM stack from the Marketplace is with BYOL (Bring Your Own License). In any case, I will strongly recommend to check your license and evaluate the cost on your side before doing any installation, moreover if it is for a production installation. My case is just a lab testing case.
Oracle Enterprise Manager 24ai installationI will first sign in to OCI and go to Marketplace. From there I will search and click on Oracle Enterprise Manager, see below pictures.
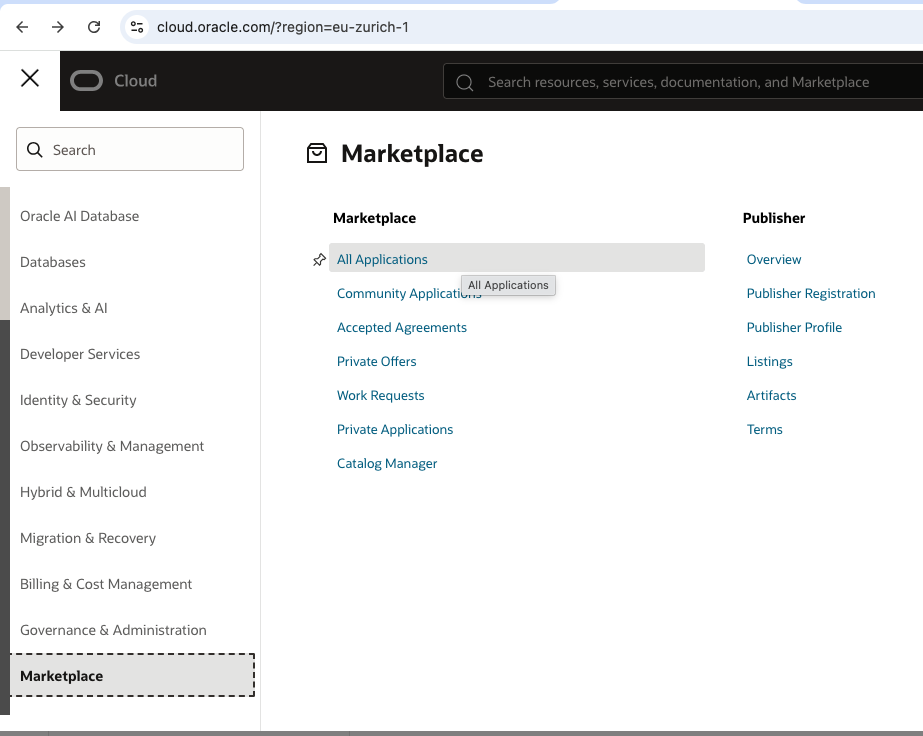
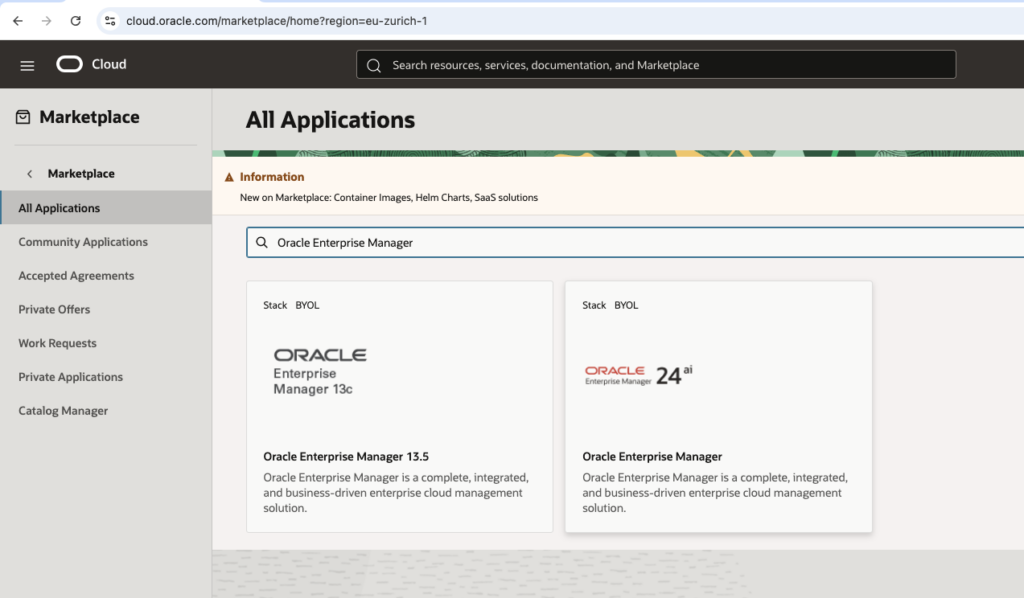
Once you have selected the Oracle Enterprise Manager 24ai stack, review the information to ensure it is accurate and click on Launch State.
Following 3 pictures will show the details.
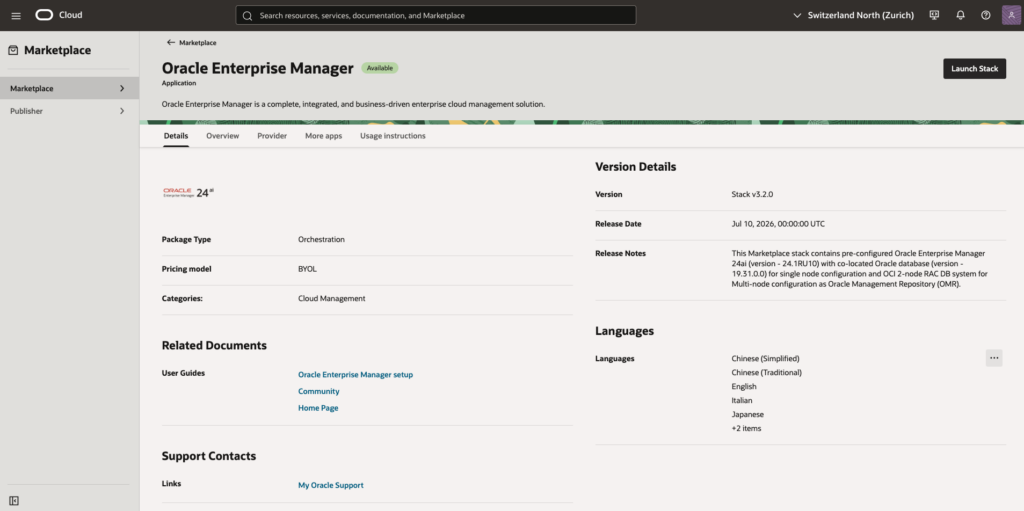
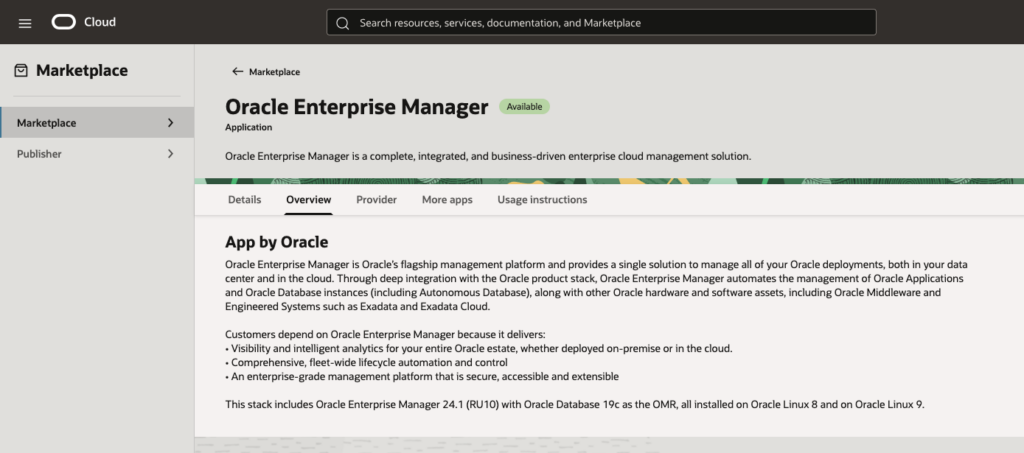
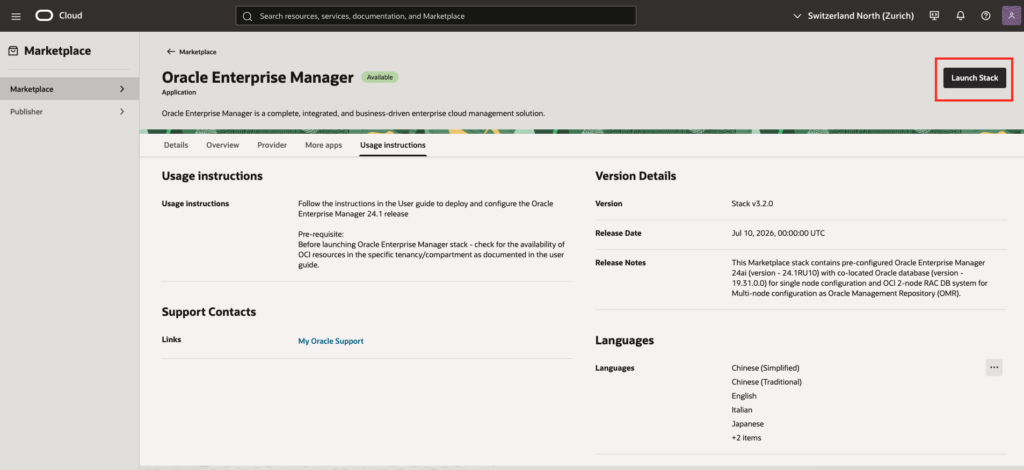
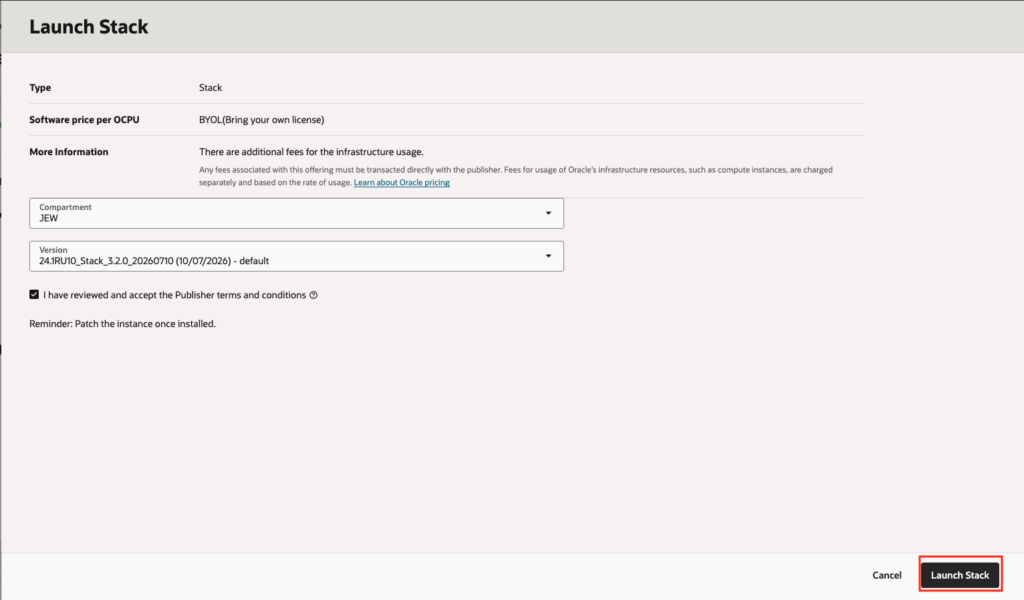
Configure Compartment, accept the terms and conditions and launch the stack, see:
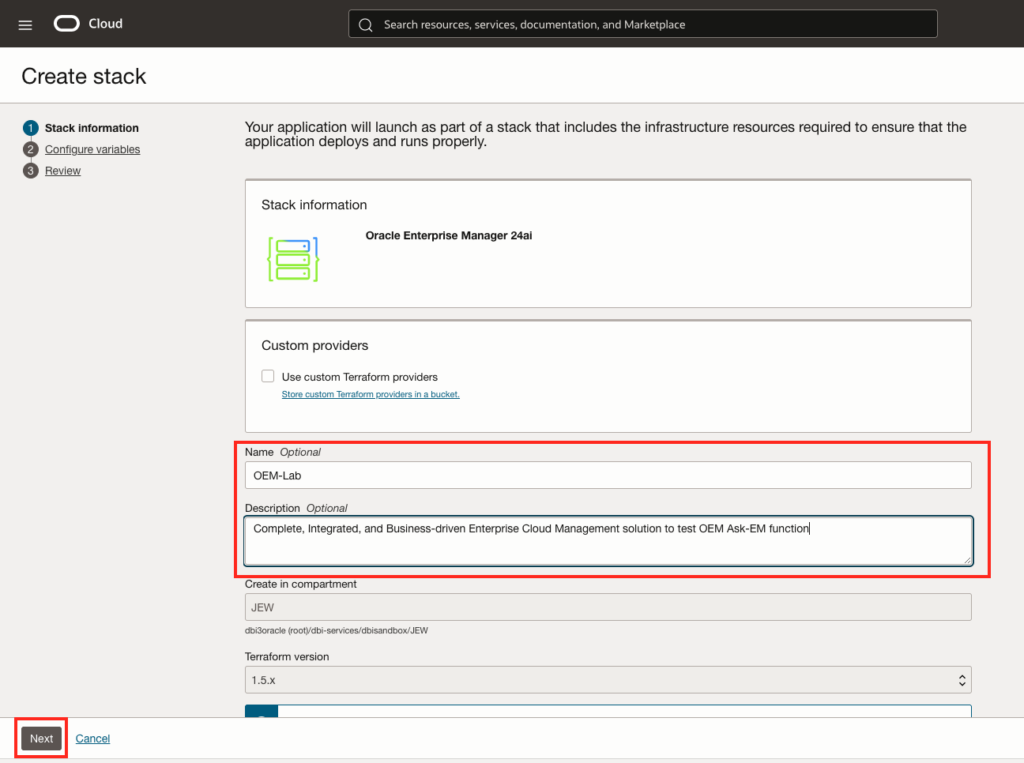
Provide a name and a desciption, and click next, see:
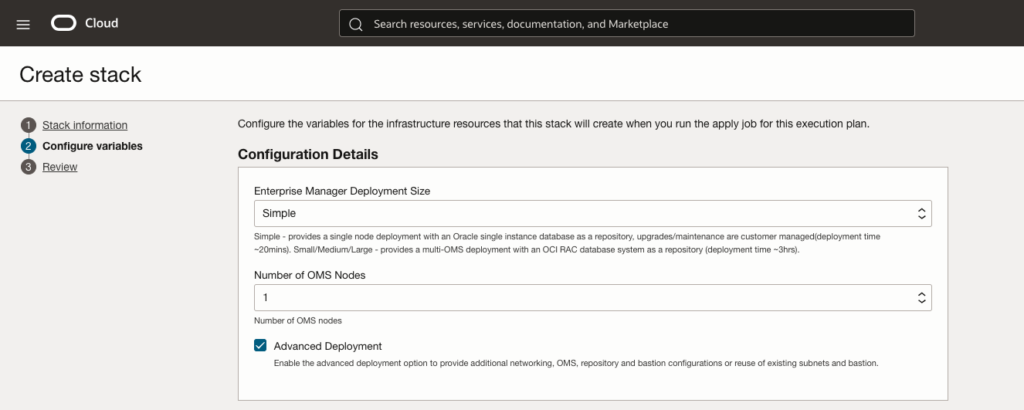
Configure the installation and sizing details:
- Choose simple as deployment size. One node is suffisient for our lab and test
- Click on advanced deployment to reuse existing infracsture (VCN and subnets)
See following picture:
Provide existing VCN Name:
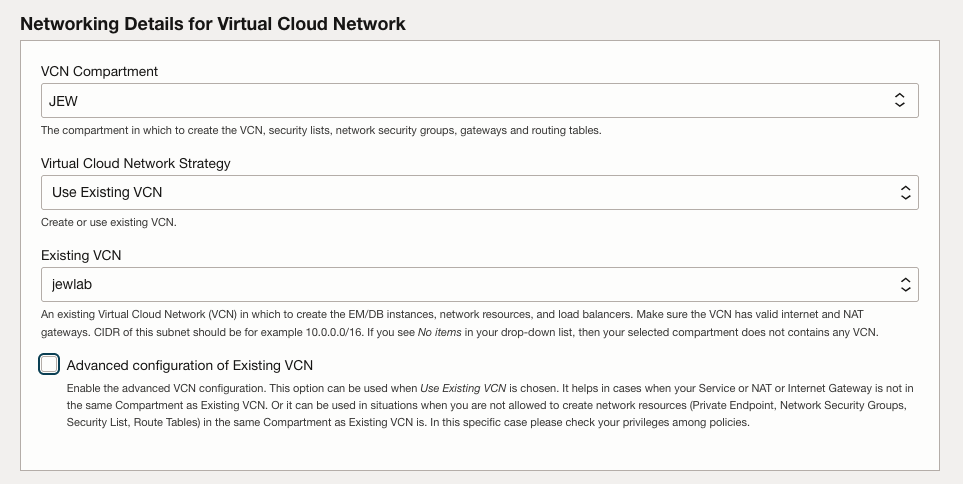
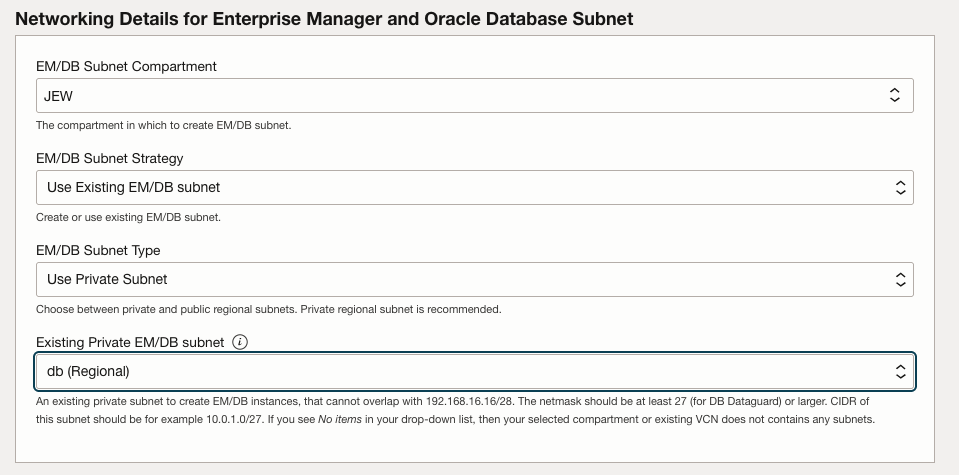
Provide networking details making sure to chose existing private subnet:
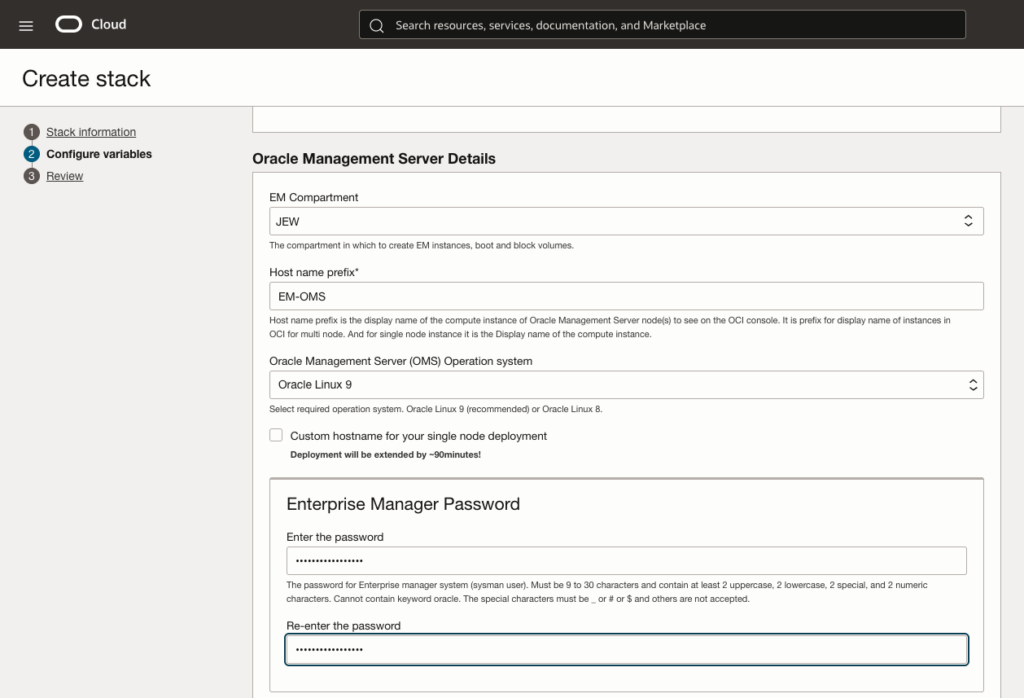
Configure Oracle Management providing Server details.
First we will provide an hostname prefix, choose Operating System version and provide Enterprise Manager password:
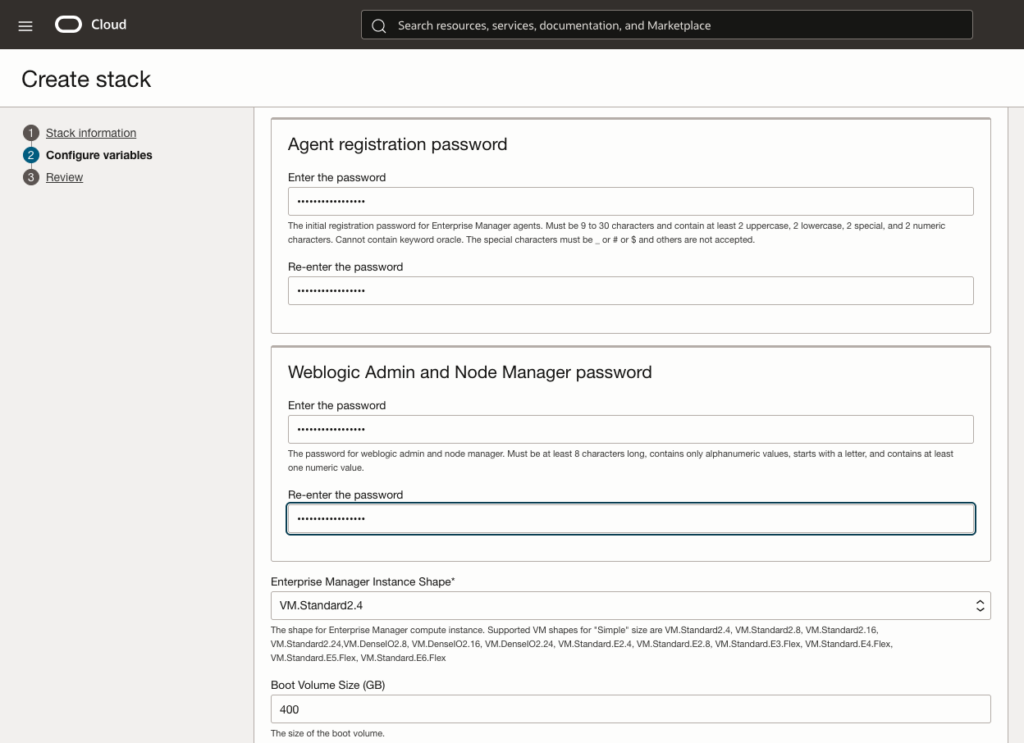
We will provide agent registration password and weblogic admin and node manager password, before chosing Enterprise Manager Instance shape and boot volume size. As discussed in the pre-requirement, a VM.Standard2.4 is enough for my need.
And finally also provide the public key to be able to access the VM later on with SSH.
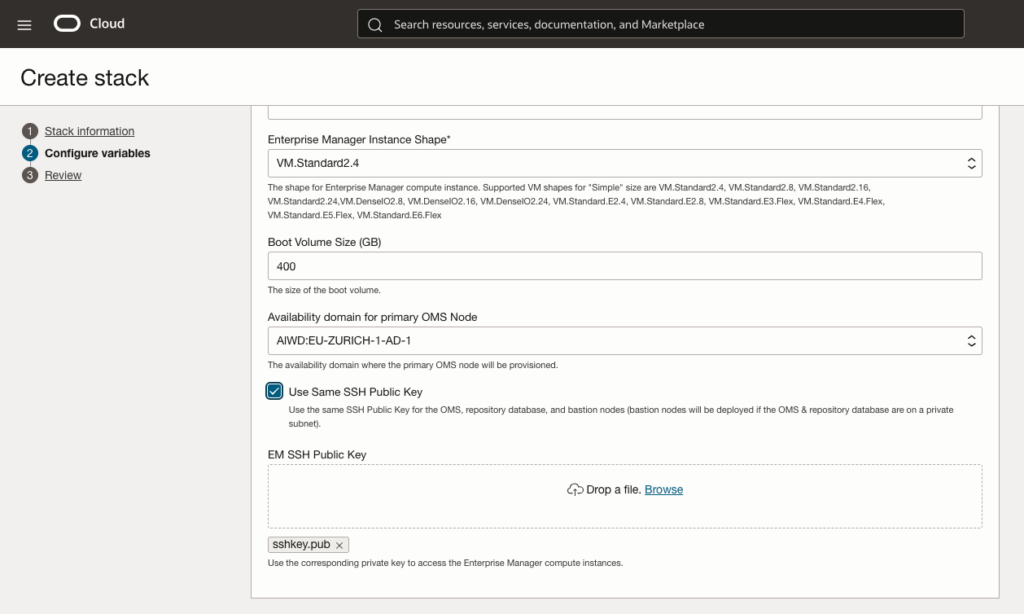
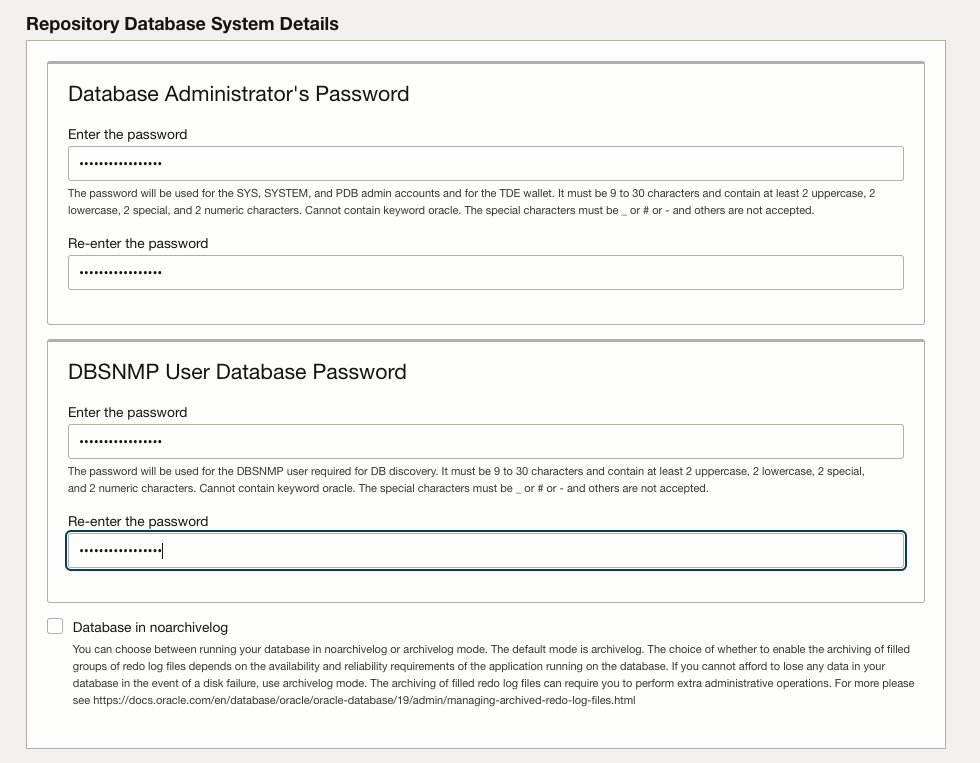
I will also have to provide all the details concerning the repository database, that’s to say database sys and dnsnmp user password. I will keep the database in archive log mode.
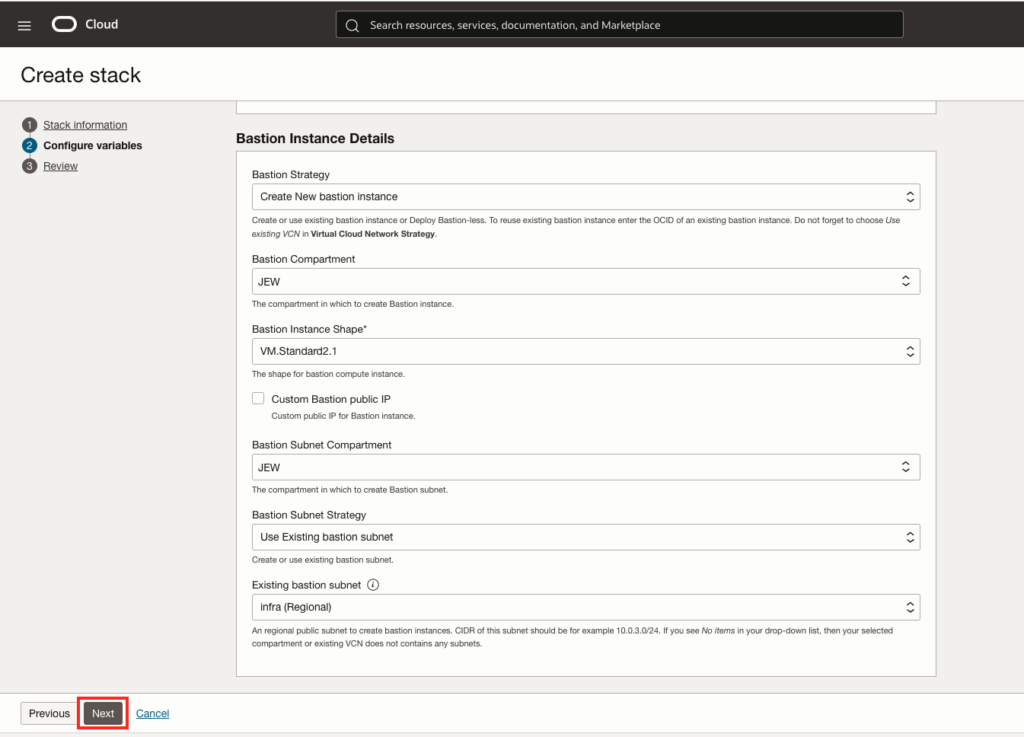
As I choose to install Enterprise Manager in the private subnet, I will need a bastion. I could decide to use an existing one where the installation will make needed changes or create a new one specific for EM. I decided to create a new one, but using existing subnet, see following information that needs to be provided, before clicking next button:
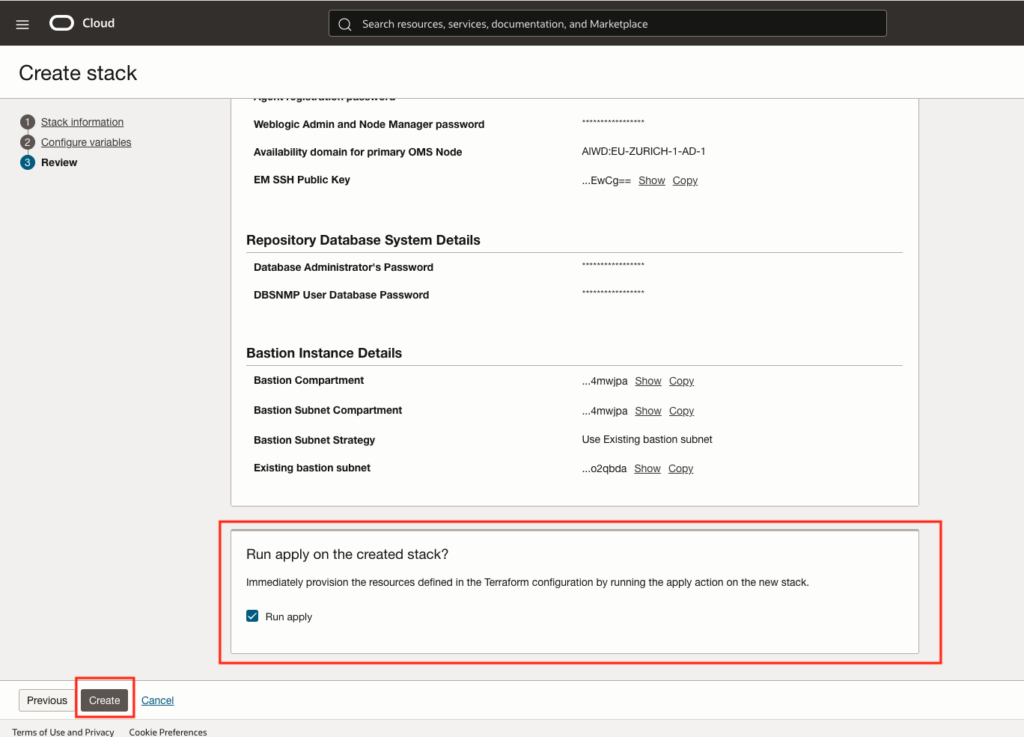
Review the whole configuration:
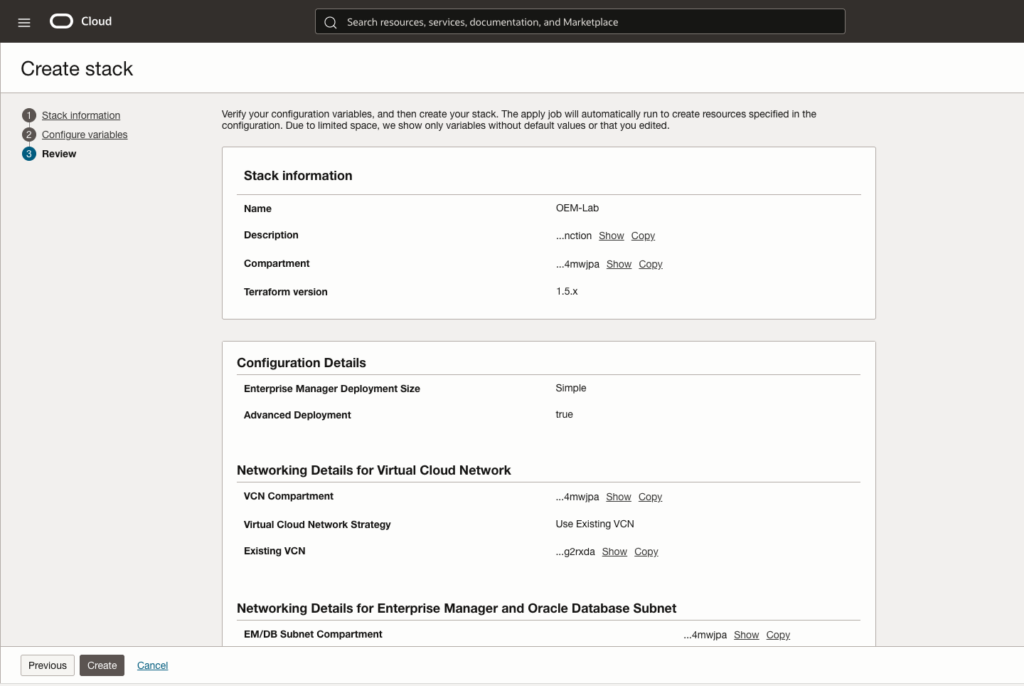
Select run apply and click the create button.
And the we can see the job stack execution. The status will first go to Accepted status and then In progress status, see next pictures:
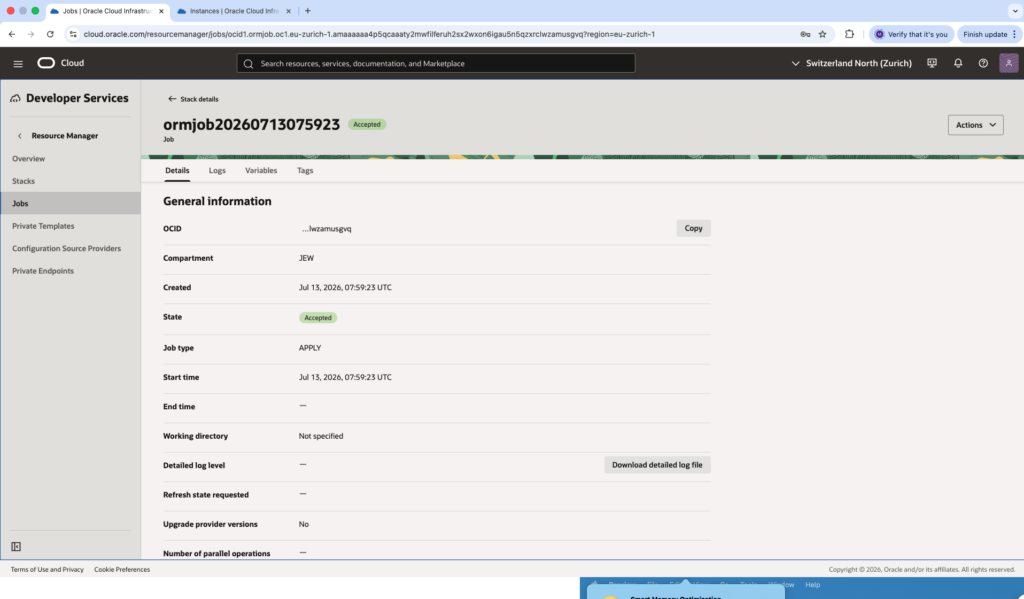
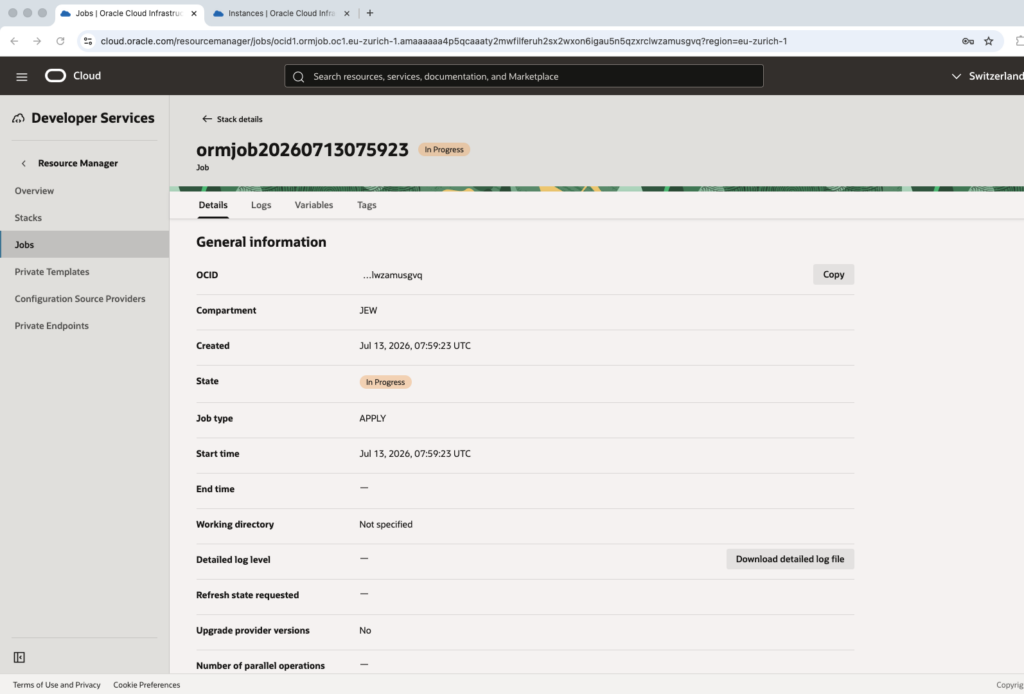
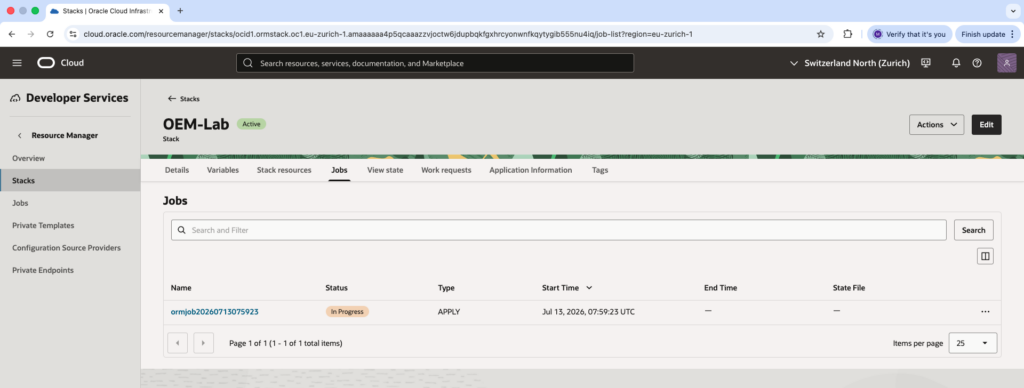 Checks…
Checks…
Once completed, we can check the job stack status, the created VM compute instance (OMS server, bastion) and EM access.
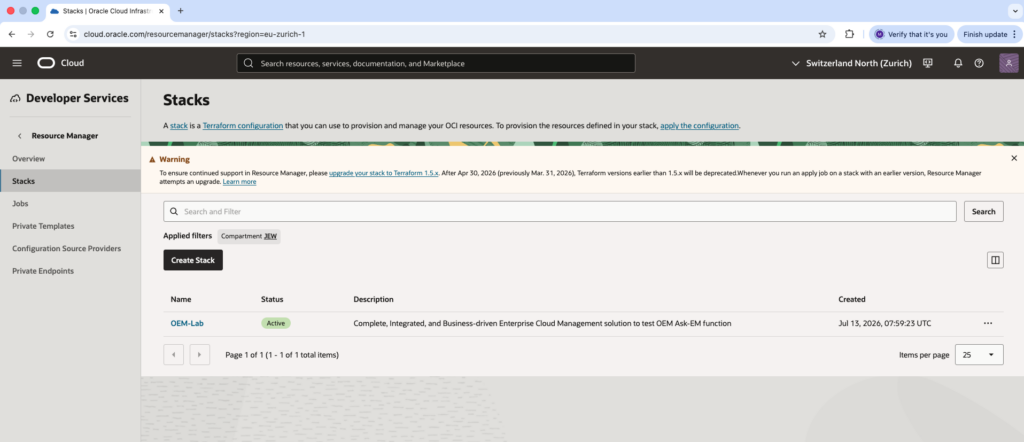
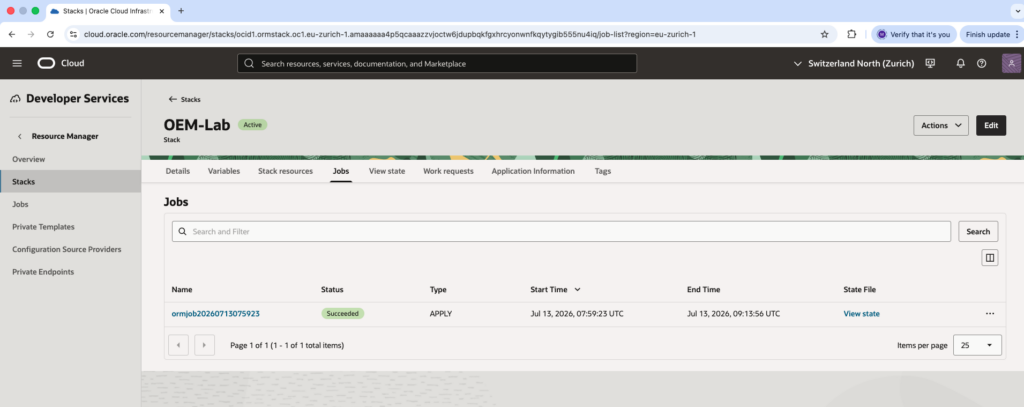
Job stackAs we can see in the next picture, the job status is now Succeeded.
In Resource Manager, under Stacks menu, we can see our OEM-Lab stack that is active. All components information will be provided.
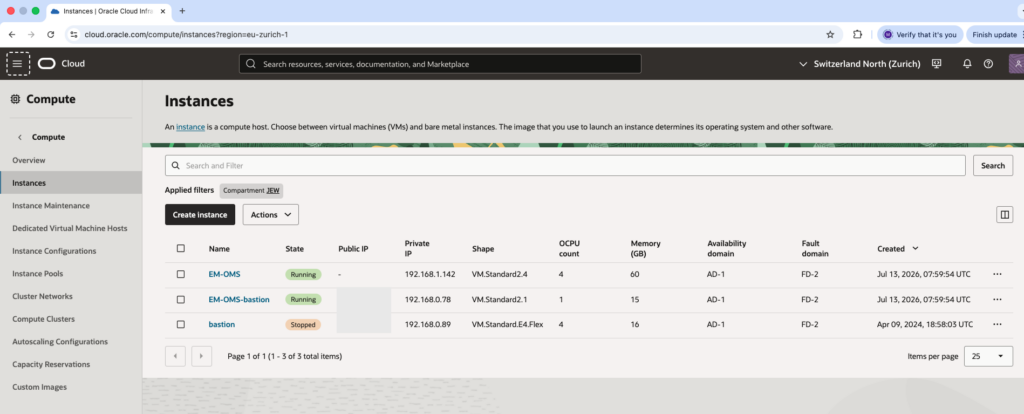
 Compute VM instances
Compute VM instances
We can check in our compartment the running EM-OMS VM compute instance and EM-OMS-bastion.
 EM Web access
EM Web access
Let’s first check and confirm that I can join the OMS Bastion from my MAC.
maw@DBI-LT-MAW2 ~ % ssh -i /Users/maw/Documents/Current-Dokument/Dokument/pem_ssh_key/yak_beta_workshop/srv/sshkey opc@152.67.XX.XXX The authenticity of host '152.67.XX.XXX (152.67.XX.XXX)' can't be established. ED25519 key fingerprint is: SHA256:CVPCXt9EwZ153fUVnZf3AGADYNVqT9fJGaU70TKbX+I This key is not known by any other names. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes Warning: Permanently added '152.67.XX.XXX' (ED25519) to the list of known hosts. ** WARNING: connection is not using a post-quantum key exchange algorithm. ** This session may be vulnerable to "store now, decrypt later" attacks. ** The server may need to be upgraded. See https://openssh.com/pq.html Last login: Mon Jul 13 08:25:33 2026 from 140.238.169.22 [opc@em-oms-bastion ~]$
AS I choose an installation on private network, I do not have access to EM through a web browser from my MAC. I first need to configure a ssh tunnel.
maw@DBI-LT-MAW2 ~ % ssh -i /Users/maw/Documents/Current-Dokument/Dokument/pem_ssh_key/yak_beta_workshop/srv/sshkey -L 7799:192.168.1.142:7799 opc@152.67.XX.XXX ** WARNING: connection is not using a post-quantum key exchange algorithm. ** This session may be vulnerable to "store now, decrypt later" attacks. ** The server may need to be upgraded. See https://openssh.com/pq.html Last login: Mon Jul 13 11:02:53 2026 from 146.4.101.46 [opc@em-oms-bastion ~]$
Check from OMS bastion that EM console is reachable.
[opc@em-oms-bastion ~]$ curl -k https://192.168.1.142:7799/em 302 Moved TemporarilyThis document you requested has moved temporarily.
It's now at https://192.168.1.142:7799/em/login.jsp.
[opc@em-oms-bastion ~]$
Check that the connection is possible on EM from my MAC directly after I have created the SSH tunnel:
maw@DBI-LT-MAW2 ~ % curl -k https://localhost:7799/em 302 Moved TemporarilyThis document you requested has moved temporarily.
It's now at https://localhost:7799/em/login.jsp.
maw@DBI-LT-MAW2 ~ %
All is good, I can not test from my MAC using a web browser.
Let’s go in the summary page.
 To wrap up…
To wrap up…
The easiest way for me to have got a EM lab installation to look into GenAI Ask EM was to install it from the marketplace. Now I’m ready to install some agent on some database host and test Ask EM functionality. I will be sharing this in a next blog.
L’article Oracle GenAI – Ask EM – Deploy Oracle Enterprise Manager 24ai from Marketplace est apparu en premier sur dbi Blog.
Designing metadata cards that users like
Over the past few weeks, I’ve addressed philosophical questions related to enterprise content management (ECM), such as “What should be done?” and “Why?” Now, it’s time to focus on the “how.”
When discussing user adoption of M-Files, the conversation often centers on training, change management, and automation. While these aspects are important, another factor immediately impacts the user experience: the Metadata Card.
A poorly designed Metadata Card can overwhelm users with unnecessary fields and irrelevant questions, making creating a document feel like filling out a tax form. Conversely, a well-designed Metadata Card naturally guides users through the process by displaying only the necessary information.

The goal is not to collect as much metadata as possible but rather to collect the right metadata at the right time.
Just a reminder that in M-Files, a metadata card is the panel that displays and allows users to edit the metadata properties of an object. It is an essential component of the tool.
Start with the user journeyBefore creating properties or configuring rules, ask a simple question:
What information does the user actually know at this stage?
Consider an invoice.
At creation, the user probably knows:
- Supplier
- Invoice number
- Invoice date
- Amount
They probably don’t know:
- Approval status
- Payment date
- Accounting reference
- Archive classification
Those properties should appear only when they become relevant.
Metadata Card should evolve with the document lifecycle rather than exposing every possible property from the beginning.
Hide what isn’t neededOne of the most effective improvements is dynamic property visibility.
Rather than displaying every property permanently, configure the card so that properties only appear when certain conditions are met.
For example:
- If the document class is “Contract”, display the contract expiration date.
- If the supplier is external, display vendor-specific properties.
- If the document is confidential, display the security classification section.
- If the document enters the approval workflow, display approval-related properties.
This approach reduces visual clutter and helps users focus on the task at hand.
Make properties mandatory only when necessaryOne common mistake is making too many properties mandatory.
Although mandatory properties can be useful, they should only be used when appropriate.
For example:
The “termination date” property should not be mandatory when creating a new employee contract. This property only becomes relevant if the employee leaves the company.
Conditional mandatory properties allow for validation without frustrating users.
Rather than forcing users to enter placeholder values just to save the document, only ask for this information when it is required by the business process.
Group related informationMetadata cards are easier to navigate when related properties are grouped together.
Instead of a long list of unrelated fields, organize them into logical sections.
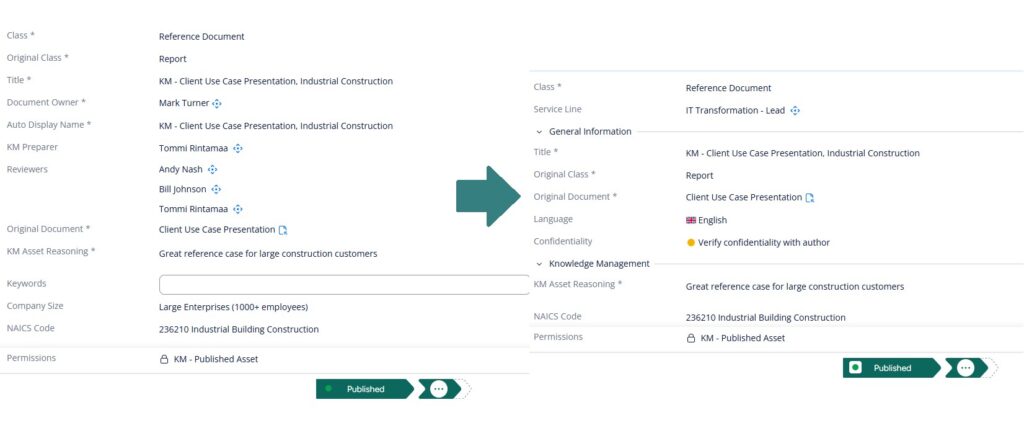 Same properties but on the right we organized them
Same properties but on the right we organized them
Users scan information much faster when it is visually organized.
Additionally, sections that are not needed at a given stage can be hidden or collapsed.
Reduce decisionsEvery visible property asks the user to make a decision.
Should I fill this in?
Does this apply to my document?
What does this property even mean?
A good metadata card minimizes these decisions.
It is good practice to use:
- Automatic values
- Default values
- Value lists
- Metadata inheritance
- Calculated properties
The fewer decisions users have to make, the faster and more accurately they can classify documents.
Avoid the “Everything might be useful”One of the biggest design mistakes is trying to satisfy every department.
For instance, the Human Resources department requires three properties, the Legal department requests five more, the Finance department submits a request for four additional fields, and finally, the Compliance department adds another six.
After a few workshops, the metadata card ends up with thirty or forty properties.
Technically, everything is possible.
Practically, nobody enjoys using it.
Whenever a new property is requested, ask:
- Who will maintain it?
- Who actually uses it?
- What business process depends on it?
- What happens if it remains empty?
If there isn’t a clear answer, then the property probably isn’t necessary.
Design for the common caseMost users perform the same actions repeatedly.
Optimize the metadata card for 80% of documents rather than exceptional cases.
Advanced scenarios can reveal additional properties as needed.
Simple cases should remain simple.
Administrators often focus on configuration, whereas it is the users who interact with the interface.
Therefore, it is important to keep in mind that every additional property increases cognitive load.
Similarly, every unnecessary required field creates friction.
Conversely, every hidden property reduces complexity.
A well-designed metadata card improves not only data quality but also the user experience of the entire M-Files system.
ConclusionMetadata is one of M-Files’ greatest strengths, but only if users provide it.
The best metadata card isn’t the one that captures the most information.
Rather, it’s the one that asks the fewest questions while still collecting everything the business needs.
When users feel that the system understands their tasks instead of getting in their way, they will naturally adopt it.
Sometimes improving user satisfaction isn’t about adding new functionality; it’s about designing a better metadata card.
Whether you’re planning a new M-Files implementation or looking to improve an existing one, we can help you design a solution that is efficient, user-friendly, and aligned with your business needs. Feel free to contact us to discuss your project.
L’article Designing metadata cards that users like est apparu en premier sur dbi Blog.
Measuring the real performance cost of SQL Server XE buffers
Extended Events have a reputation for being lightweight, and most of the time they are. However, poorly configured setups can heavily degrade your SQL Server Extended Events performance, stalling application threads and keeping a disk busy for minutes after your workload has ended. The events you choose to capture matter just as much as the session settings: some events, like the showplan ones, carry a heavy cost by design regardless of how you configure the rest of the session. I wanted to see what all of this looks like from the DMV side, so I built the worst XE session I could think of, threw a StackOverflow workload at it, and compared the numbers with a healthy session.
Two DMVs are enough for this analysis:
sys.dm_xe_sessions for buffer state, data volume and dropped eventssys.dm_os_wait_stats for the wait types produced by the XE
Keep in mind that both are in-memory structures. The counters in sys.dm_xe_sessions accumulate since the session started (create_time), and sys.dm_os_wait_stats accumulates since the instance started but everything resets after a restart.
Also note that wait statistics are instance-wide: if several XE sessions run at the same time, the XE wait types aggregate all of them (that’s why we will focus on one specific XE called XE_STRESS_TEST, all others are disabled even the built-in ones).
Monitoring with sys.dm_xe_sessions
SELECT
s.name AS session_name,
s.dropped_event_count,
s.dropped_buffer_count,
s.buffer_policy_desc,
CAST(ROUND(s.total_buffer_size / 1024.0 / 1024.0, 2) AS FLOAT) AS total_buffer_size_mb,
s.total_regular_buffers,
CAST(ROUND(s.regular_buffer_size / 1024.0 / 1024.0, 2) AS FLOAT) AS regular_buffer_size_mb,
s.buffer_processed_count,
CAST(ROUND(s.total_bytes_generated / 1024.0 / 1024.0, 2) AS FLOAT) AS total_bytes_generated_mb,
DATEDIFF(MINUTE, s.create_time, GETDATE()) AS session_age_minutes,
CAST(ROUND(s.total_bytes_generated / 1024.0 / 1024.0
/ NULLIF(DATEDIFF(MINUTE, s.create_time, GETDATE()), 0), 2) AS FLOAT) AS bytes_generated_mb_per_minute,
CAST(ROUND(s.dropped_event_count * 1.0
/ NULLIF(DATEDIFF(MINUTE, s.create_time, GETDATE()), 0), 2) AS FLOAT) AS dropped_event_count_per_minute
FROM sys.dm_xe_sessions s
WHERE s.name = '<XE_NAME>';
Since the counters are cumulative, a single snapshot tells you very little. What you want to know is whether they increase between two runs of the query. In practice:
ColumnWhat an increase meansdropped_event_countThe server sacrificed events because it could not keep up with the volumedropped_buffer_countEntire buffers were lost, usually because the target cannot drain them fast enoughbuffer_processed_countNormal activitybytes_generated_mb_per_minuteThe session captures more data than expected for its age
buffer_policy_desc is worth a look too: drop_event means the session is asynchronous and accepts losing events under pressure, block means NO_EVENT_LOSS was configured and application threads will wait instead of dropping anything. More on that below.
There are more XE-related wait types than this, but after testing I only kept the three that actually tell you something:
SELECT
wait_type,
waiting_tasks_count,
wait_time_ms,
max_wait_time_ms,
CAST(wait_time_ms * 1.0 / NULLIF(waiting_tasks_count, 0) AS DECIMAL(10,2)) AS avg_wait_time_ms
FROM sys.dm_os_wait_stats
WHERE wait_type IN (
'XE_TIMER_EVENT',
'XE_DISPATCHER_WAIT',
'PREEMPTIVE_XE_DISPATCHER'
)
AND waiting_tasks_count > 0
ORDER BY wait_time_ms DESC;
XE_TIMER_EVENT is the dispatcher thread waiting for the next flush cycle defined by MAX_DISPATCH_LATENCY. It is always present and always harmless.
XE_DISPATCHER_WAIT is the dispatcher waiting for buffers to process. Counter-intuitively, a high average is good news: the dispatcher spends its time waiting for work. A very low average means it never gets to rest between flushes.
PREEMPTIVE_XE_DISPATCHER occurs when the dispatcher switches to preemptive mode to execute an operation outside of SQLOS control, typically writing event data to disk through an OS call. It shows up under high XE load, during OS interactions, or when the storage cannot absorb the writes. On a healthy instance this stays at zero. When it starts growing, your XE session has become a real workload for the server.
On my lab, the system_health session has been running for about 132 days:

4 GB in 132 days, nothing dropped. On the wait side, XE_DISPATCHER_WAIT averages around 57 seconds per wait, meaning the dispatcher spends almost a minute idle between two buffers, and PREEMPTIVE_XE_DISPATCHER sits at 0 ms. That is what an XE session that nobody notices looks like.
Now the opposite. This session combines everything you should not do:
CREATE EVENT SESSION [XE_STRESS_TEST] ON SERVER
ADD EVENT sqlserver.sql_statement_completed (
ACTION (
sqlserver.sql_text,
sqlserver.query_hash,
sqlserver.query_plan_hash,
sqlserver.plan_handle,
sqlserver.username,
sqlserver.database_name,
sqlserver.client_hostname,
package0.collect_system_time
)
),
ADD EVENT sqlserver.query_post_execution_showplan (
ACTION (
sqlserver.sql_text,
sqlserver.database_name,
package0.collect_system_time
)
)
ADD TARGET package0.event_file (
SET filename = N'C:\XE\XE_STRESS_TEST.xel',
max_file_size = 10,
max_rollover_files = 999
)
WITH (
MAX_MEMORY = 512 KB,
EVENT_RETENTION_MODE = NO_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 1 SECONDS,
MAX_EVENT_SIZE = 10240 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
);
Why each configuration option is a bad idea:
query_post_execution_showplancaptures the full XML execution plan of every single query. A plan can weigh several hundred KB, sometimes a couple of MB. Microsoft documents this event as having performance overhead (link).MAX_MEMORY = 512 KBgives the session a tiny buffer pool that fills up after a handful of events once plans are involved, so the dispatcher flushes constantly.NO_EVENT_LOSStells SQL Server that losing an event is not acceptable. The consequence is that any thread firing an event while all buffers are full has to wait. Your queries pay for the XE session.MAX_DISPATCH_LATENCY = 1 SECONDSforces a flush cycle every second no matter what.TRACK_CAUSALITY = ONadds a GUID and a sequence number to every event, which costs a bit of CPU and space each time (link to the documentation).
To create the pressure on this XE, the workload was as follows: 10 parallel SSMS sessions, each running 1 000 iterations of joins between Posts, Users and Votes on the StackOverflow database, with a variable predicate so that no plan gets reused and every execution produces a fresh showplan event (the query is not important here, the only goal is to generate workload so that the XE has something heavy to capture).
Weighting the damagesEarly in the load, the session had already generated 1 GB. Nothing dropped, PREEMPTIVE_XE_DISPATCHER still at zero, but the average of XE_DISPATCHER_WAIT was down to 6 ms. The dispatcher was already working non-stop, the disk was simply keeping up so far.

A minute later the picture changed completely. 2.5 GB generated, and PREEMPTIVE_XE_DISPATCHER had jumped to over 1 168 690 ms accumulated. The dispatcher was now spending its life in preemptive mode, out of SQLOS control, waiting for the OS to complete disk writes.

Then the interesting part. The 10 load sessions finished, and the XE session kept writing. With NO_EVENT_LOSS and a 512 KB pool, a backlog of buffers had piled up in memory during the load, and the dispatcher was draining it file after file. The max_wait_time_ms of XE_DISPATCHER_WAIT climbed to 74 seconds while total_bytes_generated_mb barely moved: the disk was the bottleneck.

Eight minutes after the session started, the tally was 5.4 GB written, more than 500 rollover files of 10 MB on disk, for a workload that had ended long before.
 Healthy vs stressed, side by side
Metricsystem_healthXE_STRESS_TEST
Healthy vs stressed, side by side
Metricsystem_healthXE_STRESS_TESTtotal_bytes_generated_mb4’083 MB in 132 days5’410 MB in 8 minutesbytes_generated_mb_per_minute0.02~676dropped_event_count00XE_DISPATCHER_WAIT avg~57’000 ms6 to 25 msPREEMPTIVE_XE_DISPATCHER0 msover 1’168’000 ms
Note the trap on dropped_event_count: both sessions show zero, for opposite reasons. The healthy session drops nothing because it has nothing to drop. The stressed session drops nothing because NO_EVENT_LOSS made the application threads wait instead. Looking at that counter alone, both sessions look fine. Only the wait types reveal the difference.
NO_EVENT_LOSS does not buy you capacity, it converts event loss into query latency. It has its place for a short targeted capture where completeness matters, never for a permanent session.
query_post_execution_showplan without a predicate will drown any buffer configuration. If you need to capture it, scope it to a database or an object using predicates.
An undersized MAX_MEMORY turns every couple of events into a flush, and every flush is an opportunity for the dispatcher to end up in PREEMPTIVE_XE_DISPATCHER.
And check both DMVs, not just one. sys.dm_xe_sessions tells you what happened to your data, sys.dm_os_wait_stats tells you what it cost the server. In my stress test, the first one looked almost reassuring. The second one did not.
L’article Measuring the real performance cost of SQL Server XE buffers est apparu en premier sur dbi Blog.
Oracle VirtualBox 7.2.12
Oracle released VirtualBox 7.2.12 a couple of days ago. This comes hot on the heels of version 7.2.10, which I wrote about here. The downloads and changelog are in the usual places. I’ve done installations on Windows 11 and Linux Mint and both seem OK. As with the last version, on Windows 11 I got away with a straight upgrade, but … Continue reading "Oracle VirtualBox 7.2.12"
The post Oracle VirtualBox 7.2.12 first appeared on The ORACLE-BASE Blog.Oracle VirtualBox 7.2.12 was first posted on July 2, 2026 at 10:39 am.©2024 "The ORACLE-BASE Blog". Use of this feed is for personal non-commercial use only. If you are not reading this article in your feed reader, then the site is guilty of copyright infringement. Please contact me at timseanhall@gmail.com
M-Files Outlook Pro add-in configuration
In this blog post, I will outline the steps required to enable and configure the M-Files Outlook Pro add-in. This includes configuring Microsoft Outlook rules to automate email handling. It took me some time to configure the rules, as they were not working as I expected. I hope this blog helps others save time.
InstallationThe installation is very straight forward and well documented, it can take some time for the creation of the necessary self signed certificated for the Microsoft Azure Application. In addition, you must ensure that you have management access to the Microsoft Azure Admin Centre or an admin aside to perform the required steps
I will. not go through each step in detail, but I will highlight important steps from my point of view. The step by step documentation can be found on the M-Files web page for Integrations.
Important steps:
- Allow third-party cookies for Outlook Web.
https://[*.]office365.com
https://[*.]office.com - Ensure that the lins below not blocked by the firewall.
https://mfnewoutlookaddinprod.m-files.com
https://login.microsoftonline.com/common
https://login.m-files.com/ - Create a self signed certificate and convert them to be able to configure the M-Files Vault Application.
- Create and configure the Application in Azure, according the M-Files documentation.
- Installation and configure the M-Files Vault Application, just follow the M-Files documnetation.
- Install or deploy the M-Files for Outlook add-in. It is a certified Microsoft application. It can be installed individually or deployed to a specific group of users. This is the standard Microsoft process.
Create a self signed certificate for use in a cloud setup
Open PowerShell with administrative access and use the command below.
$certname = "{certificateName}" ## Replace {certificateName}
$cert = New-SelfSignedCertificate -Subject "CN=$certname" -CertStoreLocation "Cert:\CurrentUser\My" -KeyExportPolicy Exportable -KeySpec Signature -KeyLength 2048 -KeyAlgorithm RSA -HashAlgorithm SHA256
Export-Certificate -Cert $cert -FilePath "C:\Users\admin\Desktop\$certname.cer" ## Specify your preferred location
$mypwd = ConvertTo-SecureString -String "{myPassword}" -Force -AsPlainText ## Replace {myPassword}
Export-PfxCertificate -Cert $cert -FilePath "C:\Users\admin\Desktop\$certname.pfx" -Password $mypwd ## Specify your preferred locationIn case you get an execution error from PowerShell, you can use the command below to allow the execution
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -ForceIf everything worked as expected you have files as in the example below.
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 29/06/2026 08:18 772 testcert.cer
-a---- 29/06/2026 08:20 2644 testcert.pfxTo convert the certificates, you will need to use OpenSSH and Cygwin. M-Files strongly recommends using Cygwin. I encountered issues when I did not use Cygwin and it did not work.
Conversion is required in order to configure the certificate within the M-Files Vault application.
After the installation of Cygwin the command below must be executed in a Cygwin command window.
openssl pkcs12 -in MyCert.pfx -out MyCert.pem -nokeys
openssl pkcs12 -in MyCert.pfx -out MyCert.key -nocerts
openssl rsa -in MyCert.key -out MyCert_encrypted.key -aes256You can use the Outlook and M-Files rules to automatically save received emails to the M-Files system. It is important to understand how each rule works within the M-Files Outlook add-in. This differs from creating an object in M-Files, where the workflow and required state must be explicitly defined.
Open the M-Files Outlook Add-In in Outlook and navigate to “Manage folder rules.
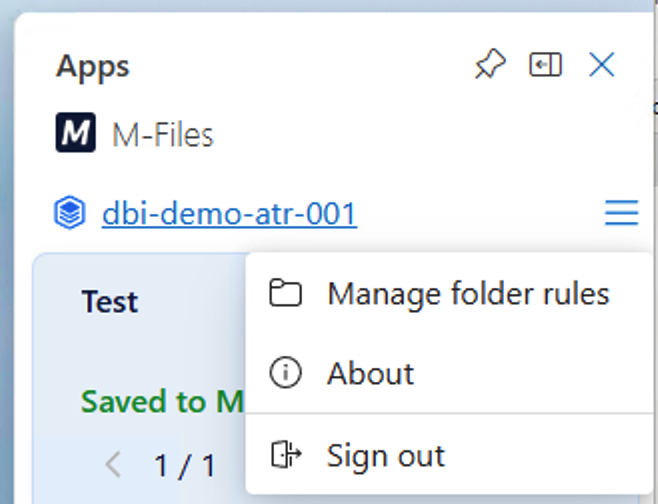
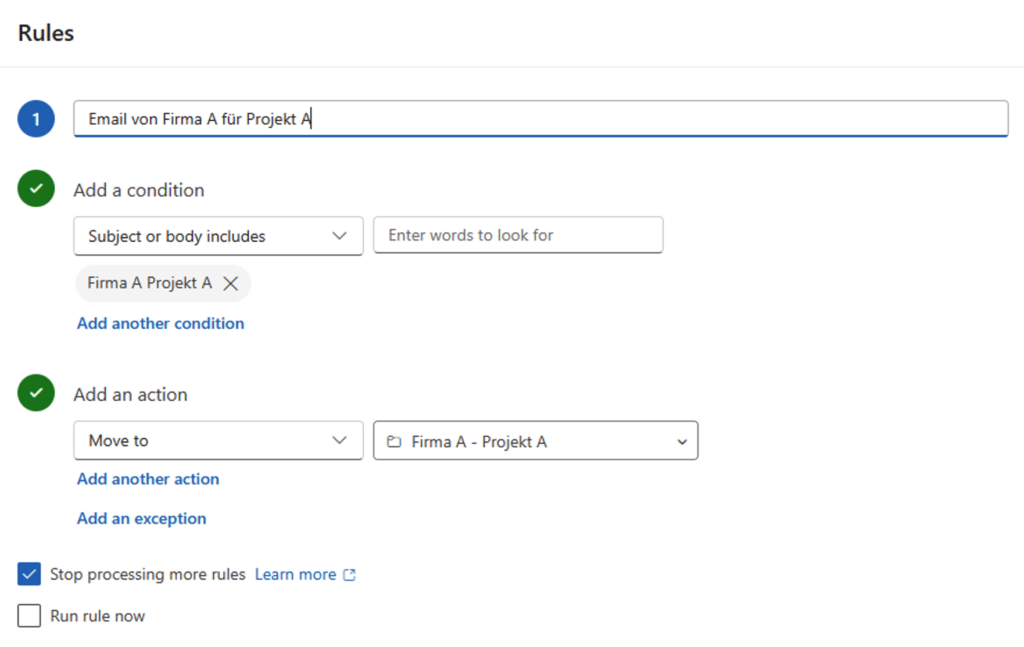
The screenshot below shows the configuration of the Outlook folder “Firma A – Projekt A”, which will be imported automatically and assigned to the M-Files class ‘Email Import’. Additionally, the “Email Import Validation” workflow with the state “Import prüfen” is assigned.
If the workflow is not defined in the rule, it will not be assigned as expected. As we know, when a new object is created in M-Files, the workflow of the class is used automatically.
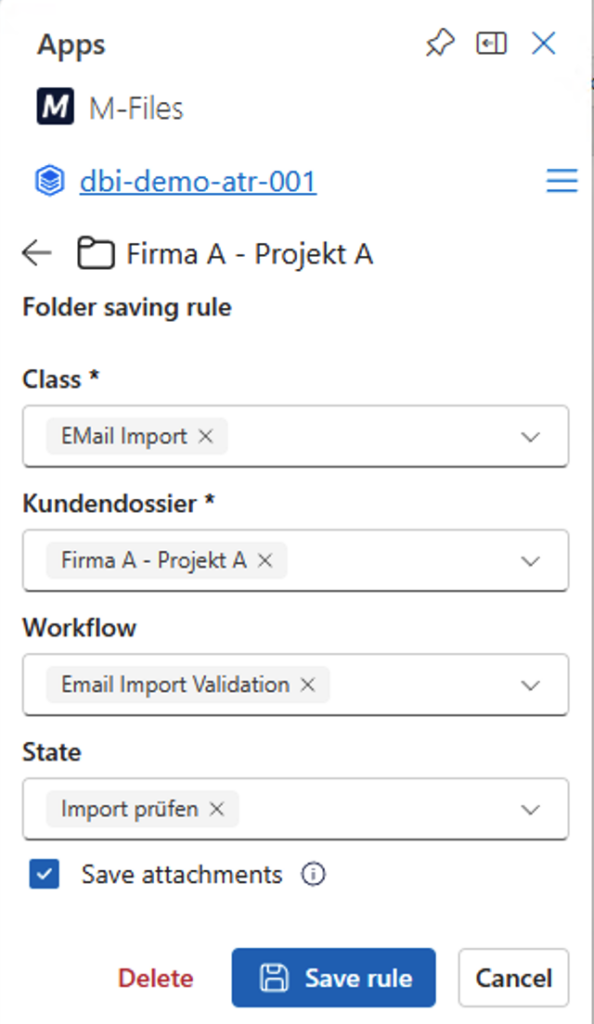 Conclusion
Conclusion
In order to automate the process of moving incoming emails into M-Files, two steps are required. First, define the usual Outlook rule, then create a rule in the M-Files Outlook add-in, as explained above.
Don’t hesitate to get in touch with us or directly with me if you have any more questions or need support with implementation.
L’article M-Files Outlook Pro add-in configuration est apparu en premier sur dbi Blog.
Bug using SQL_MACRO (TABLE) with table parameter
Forensic Analysis for records in Oracle with no Timestamp
Posted by Pete On 25/06/26 At 10:53 AM
DV_SECANALYST Analyse Database Vault Views
Posted by Pete On 02/06/26 At 12:49 PM
I forgot my Oracle Database Vault owner Password
Posted by Pete On 28/05/26 At 02:17 PM