

Yann Neuhaus

What’s New in M-Files 25.3

I’m not a big fan of doing a post for each new release, but I think the last one is a big step towards what M-Files will tend to be in the coming months.
M-Files 25.3, was released to the cloud on March 30th, and is available for download and auto-update since April 2nd. It brings a suite of powerful updates designed to improve document management efficiency and user experience.
Here’s a breakdown of the most notable features, improvements, and fixes.
Admin Workflow State Changes in M-Files Web
System administrators can now override any workflow state directly from the context menu in M-Files Web using the new “Change state (Admin)” option. This allows for greater control and quicker resolution of workflow issues.
Zero-Click Metadata Filling
When users drag and drop new objects into specific views, required metadata fields can now be automatically prefilled without displaying the metadata card. This creates a seamless and efficient upload process.
Object-Based Hierarchies Support
Object-based hierarchies are now available on the metadata card in both M-Files Web and the new Desktop interface, providing more structured data representation.
Enhanced Keyboard Navigation
Improved keyboard shortcuts now allow users to jump quickly to key interface elements like the search bar and tabs, streamlining navigation for power users.
Document Renaming in Web and Desktop
Users can now rename files in M-Files Web and the new Desktop interface via the context menu or the F2 key, making file management more intuitive.
Default gRPC Port Update
The default gRPC port for new vault connections is now set to 443, improving compatibility with standard cloud environments and simplifying firewall configurations.
AutoCAD 2025 Support
The M-Files AutoCAD add-in is now compatible with AutoCAD 2025, ensuring continued integration with the latest CAD workflows.
- Drag-and-Drop Upload Error Resolved: Fixed a bug that caused “Upload session not found” errors during file uploads.
- Automatic Property Filling: Ensured property values now update correctly when source properties are modified.
- Version-Specific Links: Resolved an issue where links pointed to the latest version rather than the correct historical version.
- Anonymous User Permissions: Closed a loophole that allowed anonymous users to create and delete views.
- Theme Display Consistency: Custom themes now persist correctly across multiple vault sessions.
- Office Add-In Fixes: Resolved compatibility issues with merged cells in Excel documents.
- Date & Time Accuracy: Fixed timezone issues that affected Date & Time metadata.
- Metadata Card Configuration: Ensured proper application of workflow settings.
- Annotation Display in Web: Annotations are now correctly tied to their document versions.
- Improved Link Functionality: Object ID-based links now work as expected in the new Desktop client.
M-Files 25.3 introduces thoughtful improvements that empower both administrators and end-users. From seamless metadata handling to improved keyboard accessibility and robust error fixes, this release makes it easier than ever to manage documents effectively.
Stay tuned for more insights and tips on making the most of your M-Files solution with us!
L’article What’s New in M-Files 25.3 est apparu en premier sur dbi Blog.
PostgreSQL 18: Support for asynchronous I/O
This is maybe one the biggest steps forward for PostgreSQL: PostgreSQL 18 will come with support for asynchronous I/O. Traditionally PostgreSQL relies on the operating system to hide the latency of writing to disk, which is done synchronously and can lead to double buffering (PostgreSQL shared buffers and the OS file cache). This is most important for WAL writes, as PostgreSQL must make sure that changes are flushed to disk and needs to wait until it is confirmed.
Before we do some tests let’s see what’s new from a parameter perspective. One of the new parameters is io_method:
postgres=# show io_method;
io_method
-----------
worker
(1 row)
The default is “worker” and the maximum number of worker processes to perform asynchronous is controller by io_workers:
postgres=# show io_workers;
io_workers
------------
3
(1 row)
This can also be seen on the operating system:
postgres=# \! ps aux | grep "io worker" | grep -v grep
postgres 29732 0.0 0.1 224792 7052 ? Ss Apr08 0:00 postgres: pgdev: io worker 1
postgres 29733 0.0 0.2 224792 9884 ? Ss Apr08 0:00 postgres: pgdev: io worker 0
postgres 29734 0.0 0.1 224792 7384 ? Ss Apr08 0:00 postgres: pgdev: io worker 2
The other possible settings for io_method are:
io_uring: Asynchronous I/O using io_uringsync: The behavior before PostgreSQL 18, do synchronous I/O
io_workers only has an effect if io_method is set to “worker”, which is the default configuration.
As usual: What follows are just some basic tests. Test for your own, in your environment with your specific workload to get some meaningful numbers. Especially if you test in a public cloud, be aware that the numbers might not show you the full truth.
We’ll do the tests on an AWS EC2 t3.large instance running Debian 12. The storage volume is gp3 with ext4 (default settings):
postgres@ip-10-0-1-209:~$ grep proc /proc/cpuinfo
processor : 0
processor : 1
postgres@ip-10-0-1-209:~$ free -g
total used free shared buff/cache available
Mem: 7 0 4 0 3 7
Swap: 0 0 0
postgres@ip-10-0-1-209:~$ mount | grep 18
/dev/nvme1n1 on /u02/pgdata/18 type ext4 (rw,relatime)
PostgreSQL was initialized with the default settings:
postgres@ip-10-0-1-209:~$ /u01/app/postgres/product/18/db_0/bin/initdb --pgdata=/u02/pgdata/18/data/
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "C.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are enabled.
fixing permissions on existing directory /u02/pgdata/18/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default "max_connections" ... 100
selecting default "autovacuum_worker_slots" ... 16
selecting default "shared_buffers" ... 128MB
selecting default time zone ... Etc/UTC
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
initdb: warning: enabling "trust" authentication for local connections
initdb: hint: You can change this by editing pg_hba.conf or using the option -A, or --auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
/u01/app/postgres/product/18/db_0/bin/pg_ctl -D /u02/pgdata/18/data/ -l logfile start
The following settings have been changed:
postgres@ip-10-0-1-209:~$ echo "shared_buffers='2GB'" >> /u02/pgdata/18/data/postgresql.auto.conf
postgres@ip-10-0-1-209:~$ echo "checkpoint_timeout='20min'" >> /u02/pgdata/18/data/postgresql.auto.conf
postgres@ip-10-0-1-209:~$ echo "random_page_cost=1.1" >> /u02/pgdata/18/data/postgresql.auto.conf
postgres@ip-10-0-1-209:~$ echo "max_wal_size='8GB'" >> /u02/pgdata/18/data/postgresql.auto.conf
postgres@ip-10-0-1-209:~$ /u01/app/postgres/product/18/db_0/bin/pg_ctl --pgdata=/u02/pgdata/18/data/ -l /dev/null start
postgres@ip-10-0-1-209:~$ /u01/app/postgres/product/18/db_0/bin/psql -c "select version()"
version
---------------------------------------------------------------------------------------
PostgreSQL 18devel dbi services build on x86_64-linux, compiled by gcc-12.2.0, 64-bit
(1 row)
postgres@ip-10-0-1-209:~$ export PATH=/u01/app/postgres/product/18/db_0/bin/:$PATH
The first test is data loading. How long does that take when io_method is set to worker (3 times in a row), this gives a data set of around 1536MB:
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 31.85 s (drop tables 0.00 s, create tables 0.01 s, client-side generate 24.82 s, vacuum 0.35 s, primary keys 6.68 s).
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 31.97 s (drop tables 0.24 s, create tables 0.00 s, client-side generate 25.44 s, vacuum 0.34 s, primary keys 5.93 s).
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 30.72 s (drop tables 0.26 s, create tables 0.00 s, client-side generate 23.93 s, vacuum 0.55 s, primary keys 5.98 s).
The same test with “sync”:
postgres@ip-10-0-1-209:~$ psql -c "alter system set io_method='sync'"
ALTER SYSTEM
postgres@ip-10-0-1-209:~$ pg_ctl --pgdata=/u02/pgdata/18/data/ restart -l /dev/null
postgres@ip-10-0-1-209:~$ psql -c "show io_method"
io_method
-----------
sync
(1 row)
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 20.89 s (drop tables 0.29 s, create tables 0.01 s, client-side generate 14.70 s, vacuum 0.45 s, primary keys 5.44 s).
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 21.57 s (drop tables 0.20 s, create tables 0.00 s, client-side generate 16.13 s, vacuum 0.46 s, primary keys 4.77 s).
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 21.44 s (drop tables 0.20 s, create tables 0.00 s, client-side generate 16.04 s, vacuum 0.52 s, primary keys 4.67 s).
… and finally “io_uring”:
postgres@ip-10-0-1-209:~$ psql -c "alter system set io_method='io_uring'"
ALTER SYSTEM
postgres@ip-10-0-1-209:~$ pg_ctl --pgdata=/u02/pgdata/18/data/ restart -l /dev/null
waiting for server to shut down.... done
server stopped
waiting for server to start.... done
server started
postgres@ip-10-0-1-209:~$ psql -c "show io_method"
io_method
-----------
io_uring
(1 row)
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 20.63 s (drop tables 0.35 s, create tables 0.01 s, client-side generate 14.92 s, vacuum 0.47 s, primary keys 4.88 s).
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 20.81 s (drop tables 0.29 s, create tables 0.00 s, client-side generate 14.43 s, vacuum 0.46 s, primary keys 5.63 s).
postgres@ip-10-0-1-209:~$ pgbench -i -s 100
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 21.11 s (drop tables 0.24 s, create tables 0.00 s, client-side generate 15.63 s, vacuum 0.53 s, primary keys 4.70 s).
There not much difference for “sync” and “io_uring”, but “worker” clearly is slower for that type of workload.
Moving on, let’s see how that looks like for a standard pgbench benchmark. We’ll start with “io_uring” as this is the current setting:
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 567989
number of failed transactions: 0 (0.000%)
latency average = 2.113 ms
initial connection time = 8.996 ms
tps = 946.659673 (without initial connection time)
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 557640
number of failed transactions: 0 (0.000%)
latency average = 2.152 ms
initial connection time = 6.994 ms
tps = 929.408406 (without initial connection time)
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 563613
number of failed transactions: 0 (0.000%)
latency average = 2.129 ms
initial connection time = 16.351 ms
tps = 939.378627 (without initial connection time)
Same test with “worker”:
postgres@ip-10-0-1-209:~$ psql -c "alter system set io_method='worker'"
ALTER SYSTEM
postgres@ip-10-0-1-209:~$ pg_ctl --pgdata=/u02/pgdata/18/data/ restart -l /dev/null
waiting for server to shut down............. done
server stopped
waiting for server to start.... done
server started
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 549176
number of failed transactions: 0 (0.000%)
latency average = 2.185 ms
initial connection time = 7.189 ms
tps = 915.301403 (without initial connection time)
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 564898
number of failed transactions: 0 (0.000%)
latency average = 2.124 ms
initial connection time = 11.332 ms
tps = 941.511304 (without initial connection time)
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 563041
number of failed transactions: 0 (0.000%)
latency average = 2.131 ms
initial connection time = 9.120 ms
tps = 938.412979 (without initial connection time)
… and finally “sync”:
postgres@ip-10-0-1-209:~$ psql -c "alter system set io_method='sync'"
ALTER SYSTEM
postgres@ip-10-0-1-209:~$ pg_ctl --pgdata=/u02/pgdata/18/data/ restart -l /dev/null
waiting for server to shut down............ done
server stopped
waiting for server to start.... done
server started
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 560420
number of failed transactions: 0 (0.000%)
latency average = 2.141 ms
initial connection time = 12.000 ms
tps = 934.050237 (without initial connection time)
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 560077
number of failed transactions: 0 (0.000%)
latency average = 2.143 ms
initial connection time = 7.204 ms
tps = 933.469665 (without initial connection time)
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=2 --jobs=2
pgbench (18devel dbi services build)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 100
query mode: simple
number of clients: 2
number of threads: 2
maximum number of tries: 1
duration: 600 s
number of transactions actually processed: 566150
number of failed transactions: 0 (0.000%)
latency average = 2.120 ms
initial connection time = 7.579 ms
tps = 943.591451 (without initial connection time)
As you see there is not much difference, no matter the io_method. Let’s stress the system a bit more (only putting the summaries here):
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=10 --jobs=10
## sync
tps = 2552.785398 (without initial connection time)
tps = 2505.476064 (without initial connection time)
tps = 2542.419230 (without initial connection time)
## io_uring
tps = 2511.138931 (without initial connection time)
tps = 2529.705311 (without initial connection time)
tps = 2573.195751 (without initial connection time)
## worker
tps = 2531.657962 (without initial connection time)
tps = 2523.854335 (without initial connection time)
tps = 2515.490351 (without initial connection time)
Some picture, there is not much difference. One last test, hammering the system even more:
postgres@ip-10-0-1-209:~$ pgbench --time=600 --client=20 --jobs=20
## worker
tps = 2930.268033 (without initial connection time)
tps = 2799.499964 (without initial connection time)
tps = 3033.491153 (without initial connection time)
## io_uring
tps = 2942.542882 (without initial connection time)
tps = 3061.487286 (without initial connection time)
tps = 2995.175169 (without initial connection time)
## sync
tps = 2997.654084 (without initial connection time)
tps = 2924.269626 (without initial connection time)
tps = 2753.853272 (without initial connection time)
At least for these tests, there is not much difference between the three settings for io_method (sync seems to be a bit slower), but I think this is still great. For such a massive change getting to the same performance as before is great. Things in PostgreSQL improve all the time, and I am sure there will be a lot of improvements in this area as well.
Usually I link to the commit here, but in this case that would be a whole bunch of commits. To everyone involved in this, a big thank you.
L’article PostgreSQL 18: Support for asynchronous I/O est apparu en premier sur dbi Blog.
Use a expired SLES with OpenSUSE repositories
Last week, I hit a wall when my SUSE Linux Enterprise Server license expired, stopping all repository access. Needing PostgreSQL urgently, I couldn’t wait for SUSE to renew my license and had to act fast.
I chose to disable every SLES repository and switched to the openSUSE Leap repository. This worked flawless and made my system usable in very short time. This is why I wanted to make a short blog about it:
# First, check what repos are active with:
$ sudo zypper repos
# In case you only have SLES-Repositories on your system you can disable all of them at once. Otherwise you will be spammed with error messages when running zypper. To disable all repos in one shot, use:
$ sudo zypper modifyrepo --all --disable
# Now we come to the fun part. Depending on what minor version of release 15 you use, it is needed to change it inside the repository link. In my case I'm using 15.6:
$ slesver=15.6 && sudo zypper addrepo http://download.opensuse.org/distribution/leap/$slesver/repo/oss/ opensuse-leap-oss
# Now we only need to refresh the repositories and accept the gpg-keys:
$ sudo zypper refresh
# From now on we can install any packages we need without ever having to activate the system.This guide shows you how to swap out the paid SUSE Linux Enterprise Server (SLES) repositories, which are professionally managed and maintained by SUSE, for the open-source openSUSE Leap repositories. A community of volunteers, with some help from SUSE, drives and supports the openSUSE Leap repositories. But they lack the enterprise grade support, testing, and update guarantees provided by SLES. By following these steps, you will lose access to SUSE’s official updates, security patches, and support services tied to your expired SLES license. This process converts your system into a community supported setup, which may not align with production or enterprise needs. Proceed at your own risk, and ensure you understand the implications. Especially regarding security, stability, and compliance. To stay up to date with security announcements on OpenSUSE you can subscribe here.
L’article Use a expired SLES with OpenSUSE repositories est apparu en premier sur dbi Blog.
PostgreSQL 18: Add function to report backend memory contexts
Another great feature was committed for PostgreSQL 18 if you are interested how memory is used by a backend process. While you can take a look at the memory contexts for your current session since PostgreSQL 14, there was no way to retrieve that information for another backend.
Since PostgreSQL 14 there is the pg_backend_memory_contexts catalog view. This view displays the memory contexts of the server process attached to the current session, e.g.:
postgres=# select * from pg_backend_memory_contexts;
name | ident | type | level | path | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes
------------------------------------------------+------------------------------------------------+------------+-------+-----------------------+-------------+---------------+------------+-------------+------------
TopMemoryContext | | AllocSet | 1 | {1} | 174544 | 7 | 36152 | 20 | 138392
Record information cache | | AllocSet | 2 | {1,2} | 8192 | 1 | 1640 | 0 | 6552
RegexpCacheMemoryContext | | AllocSet | 2 | {1,3} | 1024 | 1 | 784 | 0 | 240
collation cache | | AllocSet | 2 | {1,4} | 8192 | 1 | 6808 | 0 | 1384
TableSpace cache | | AllocSet | 2 | {1,5} | 8192 | 1 | 2152 | 0 | 6040
Map from relid to OID of cached composite type | | AllocSet | 2 | {1,6} | 8192 | 1 | 2544 | 0 | 5648
Type information cache | | AllocSet | 2 | {1,7} | 24624 | 2 | 2672 | 0 | 21952
Operator lookup cache | | AllocSet | 2 | {1,8} | 24576 | 2 | 10816 | 4 | 13760
search_path processing cache | | AllocSet | 2 | {1,9} | 8192 | 1 | 5656 | 8 | 2536
RowDescriptionContext | | AllocSet | 2 | {1,10} | 8192 | 1 | 6920 | 0 | 1272
MessageContext | | AllocSet | 2 | {1,11} | 32768 | 3 | 1632 | 0 | 31136
Operator class cache | | AllocSet | 2 | {1,12} | 8192 | 1 | 616 | 0 | 7576
smgr relation table | | AllocSet | 2 | {1,13} | 32768 | 3 | 16904 | 9 | 15864
PgStat Shared Ref Hash | | AllocSet | 2 | {1,14} | 9264 | 2 | 712 | 0 | 8552
PgStat Shared Ref | | AllocSet | 2 | {1,15} | 8192 | 4 | 3440 | 5 | 4752
PgStat Pending | | AllocSet | 2 | {1,16} | 16384 | 5 | 15984 | 58 | 400
TopTransactionContext | | AllocSet | 2 | {1,17} | 8192 | 1 | 7776 | 0 | 416
TransactionAbortContext | | AllocSet | 2 | {1,18} | 32768 | 1 | 32528 | 0 | 240
Portal hash | | AllocSet | 2 | {1,19} | 8192 | 1 | 616 | 0 | 7576
TopPortalContext | | AllocSet | 2 | {1,20} | 8192 | 1 | 7688 | 0 | 504
Relcache by OID | | AllocSet | 2 | {1,21} | 16384 | 2 | 3608 | 3 | 12776
CacheMemoryContext | | AllocSet | 2 | {1,22} | 8487056 | 14 | 3376568 | 3 | 5110488
LOCALLOCK hash | | AllocSet | 2 | {1,23} | 8192 | 1 | 616 | 0 | 7576
WAL record construction | | AllocSet | 2 | {1,24} | 50200 | 2 | 6400 | 0 | 43800
PrivateRefCount | | AllocSet | 2 | {1,25} | 8192 | 1 | 608 | 0 | 7584
MdSmgr | | AllocSet | 2 | {1,26} | 8192 | 1 | 7296 | 0 | 896
GUCMemoryContext | | AllocSet | 2 | {1,27} | 24576 | 2 | 8264 | 1 | 16312
Timezones | | AllocSet | 2 | {1,28} | 104112 | 2 | 2672 | 0 | 101440
ErrorContext | | AllocSet | 2 | {1,29} | 8192 | 1 | 7952 | 0 | 240
RegexpMemoryContext | ^(.*memory.*)$ | AllocSet | 3 | {1,3,30} | 13360 | 5 | 6800 | 8 | 6560
PortalContext | <unnamed> | AllocSet | 3 | {1,20,31} | 1024 | 1 | 608 | 0 | 416
relation rules | pg_backend_memory_contexts | AllocSet | 3 | {1,22,32} | 8192 | 4 | 3840 | 1 | 4352
index info | pg_toast_1255_index | AllocSet | 3 | {1,22,33} | 3072 | 2 | 1152 | 2 | 1920
index info | pg_toast_2619_index | AllocSet | 3 | {1,22,34} | 3072 | 2 | 1152 | 2 | 1920
index info | pg_constraint_conrelid_contypid_conname_index | AllocSet | 3 | {1,22,35} | 3072 | 2 | 1016 | 1 | 2056
index info | pg_statistic_ext_relid_index | AllocSet | 3 | {1,22,36} | 2048 | 2 | 752 | 2 | 1296
index info | pg_index_indrelid_index | AllocSet | 3 | {1,22,37} | 2048 | 2 | 680 | 2 | 1368
index info | pg_db_role_setting_databaseid_rol_index | AllocSet | 3 | {1,22,38} | 3072 | 2 | 1120 | 1 | 1952
index info | pg_opclass_am_name_nsp_index | AllocSet | 3 | {1,22,39} | 3072 | 2 | 1048 | 1 | 2024
index info | pg_foreign_data_wrapper_name_index | AllocSet | 3 | {1,22,40} | 2048 | 2 | 792 | 3 | 1256
index info | pg_enum_oid_index | AllocSet | 3 | {1,22,41} | 2048 | 2 | 824 | 3 | 1224
index info | pg_class_relname_nsp_index | AllocSet | 3 | {1,22,42} | 3072 | 2 | 1080 | 3 | 1992
index info | pg_foreign_server_oid_index | AllocSet | 3 | {1,22,43} | 2048 | 2 | 824 | 3 | 1224
index info | pg_publication_pubname_index | AllocSet | 3 | {1,22,44} | 2048 | 2 | 824 | 3 | 1224
index info | pg_statistic_relid_att_inh_index | AllocSet | 3 | {1,22,45} | 3072 | 2 | 872 | 2 | 2200
index info | pg_cast_source_target_index | AllocSet | 3 | {1,22,46} | 3072 | 2 | 1080 | 3 | 1992
index info | pg_language_name_index | AllocSet | 3 | {1,22,47} | 2048 | 2 | 824 | 3 | 1224
index info | pg_transform_oid_index | AllocSet | 3 | {1,22,48} | 2048 | 2 | 824 | 3 | 1224
index info | pg_collation_oid_index | AllocSet | 3 | {1,22,49} | 2048 | 2 | 680 | 2 | 1368
index info | pg_amop_fam_strat_index | AllocSet | 3 | {1,22,50} | 3248 | 3 | 840 | 0 | 2408
index info | pg_index_indexrelid_index | AllocSet | 3 | {1,22,51} | 2048 | 2 | 680 | 2 | 1368
index info | pg_ts_template_tmplname_index | AllocSet | 3 | {1,22,52} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_ts_config_map_index | AllocSet | 3 | {1,22,53} | 3072 | 2 | 1192 | 2 | 1880
index info | pg_opclass_oid_index | AllocSet | 3 | {1,22,54} | 2048 | 2 | 680 | 2 | 1368
index info | pg_foreign_data_wrapper_oid_index | AllocSet | 3 | {1,22,55} | 2048 | 2 | 792 | 3 | 1256
index info | pg_publication_namespace_oid_index | AllocSet | 3 | {1,22,56} | 2048 | 2 | 792 | 3 | 1256
index info | pg_event_trigger_evtname_index | AllocSet | 3 | {1,22,57} | 2048 | 2 | 824 | 3 | 1224
index info | pg_statistic_ext_name_index | AllocSet | 3 | {1,22,58} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_publication_oid_index | AllocSet | 3 | {1,22,59} | 2048 | 2 | 824 | 3 | 1224
index info | pg_ts_dict_oid_index | AllocSet | 3 | {1,22,60} | 2048 | 2 | 824 | 3 | 1224
index info | pg_event_trigger_oid_index | AllocSet | 3 | {1,22,61} | 2048 | 2 | 824 | 3 | 1224
index info | pg_conversion_default_index | AllocSet | 3 | {1,22,62} | 2224 | 2 | 216 | 0 | 2008
index info | pg_operator_oprname_l_r_n_index | AllocSet | 3 | {1,22,63} | 3248 | 3 | 840 | 0 | 2408
index info | pg_trigger_tgrelid_tgname_index | AllocSet | 3 | {1,22,64} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_extension_oid_index | AllocSet | 3 | {1,22,65} | 2048 | 2 | 824 | 3 | 1224
index info | pg_enum_typid_label_index | AllocSet | 3 | {1,22,66} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_ts_config_oid_index | AllocSet | 3 | {1,22,67} | 2048 | 2 | 824 | 3 | 1224
index info | pg_user_mapping_oid_index | AllocSet | 3 | {1,22,68} | 2048 | 2 | 824 | 3 | 1224
index info | pg_opfamily_am_name_nsp_index | AllocSet | 3 | {1,22,69} | 3072 | 2 | 1192 | 2 | 1880
index info | pg_foreign_table_relid_index | AllocSet | 3 | {1,22,70} | 2048 | 2 | 824 | 3 | 1224
index info | pg_type_oid_index | AllocSet | 3 | {1,22,71} | 2048 | 2 | 680 | 2 | 1368
index info | pg_aggregate_fnoid_index | AllocSet | 3 | {1,22,72} | 2048 | 2 | 680 | 2 | 1368
index info | pg_constraint_oid_index | AllocSet | 3 | {1,22,73} | 2048 | 2 | 824 | 3 | 1224
index info | pg_rewrite_rel_rulename_index | AllocSet | 3 | {1,22,74} | 3072 | 2 | 1152 | 3 | 1920
index info | pg_ts_parser_prsname_index | AllocSet | 3 | {1,22,75} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_ts_config_cfgname_index | AllocSet | 3 | {1,22,76} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_ts_parser_oid_index | AllocSet | 3 | {1,22,77} | 2048 | 2 | 824 | 3 | 1224
index info | pg_publication_rel_prrelid_prpubid_index | AllocSet | 3 | {1,22,78} | 3072 | 2 | 1264 | 2 | 1808
index info | pg_operator_oid_index | AllocSet | 3 | {1,22,79} | 2048 | 2 | 680 | 2 | 1368
index info | pg_namespace_nspname_index | AllocSet | 3 | {1,22,80} | 2048 | 2 | 680 | 2 | 1368
index info | pg_ts_template_oid_index | AllocSet | 3 | {1,22,81} | 2048 | 2 | 824 | 3 | 1224
index info | pg_amop_opr_fam_index | AllocSet | 3 | {1,22,82} | 3072 | 2 | 904 | 1 | 2168
index info | pg_default_acl_role_nsp_obj_index | AllocSet | 3 | {1,22,83} | 3072 | 2 | 1160 | 2 | 1912
index info | pg_collation_name_enc_nsp_index | AllocSet | 3 | {1,22,84} | 3072 | 2 | 904 | 1 | 2168
index info | pg_publication_rel_oid_index | AllocSet | 3 | {1,22,85} | 2048 | 2 | 824 | 3 | 1224
index info | pg_range_rngtypid_index | AllocSet | 3 | {1,22,86} | 2048 | 2 | 824 | 3 | 1224
index info | pg_ts_dict_dictname_index | AllocSet | 3 | {1,22,87} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_type_typname_nsp_index | AllocSet | 3 | {1,22,88} | 3072 | 2 | 1080 | 3 | 1992
index info | pg_opfamily_oid_index | AllocSet | 3 | {1,22,89} | 2048 | 2 | 680 | 2 | 1368
index info | pg_statistic_ext_oid_index | AllocSet | 3 | {1,22,90} | 2048 | 2 | 824 | 3 | 1224
index info | pg_statistic_ext_data_stxoid_inh_index | AllocSet | 3 | {1,22,91} | 3072 | 2 | 1264 | 2 | 1808
index info | pg_class_oid_index | AllocSet | 3 | {1,22,92} | 2048 | 2 | 680 | 2 | 1368
index info | pg_proc_proname_args_nsp_index | AllocSet | 3 | {1,22,93} | 3072 | 2 | 1048 | 1 | 2024
index info | pg_partitioned_table_partrelid_index | AllocSet | 3 | {1,22,94} | 2048 | 2 | 792 | 3 | 1256
index info | pg_range_rngmultitypid_index | AllocSet | 3 | {1,22,95} | 2048 | 2 | 824 | 3 | 1224
index info | pg_transform_type_lang_index | AllocSet | 3 | {1,22,96} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_attribute_relid_attnum_index | AllocSet | 3 | {1,22,97} | 3072 | 2 | 1080 | 3 | 1992
index info | pg_proc_oid_index | AllocSet | 3 | {1,22,98} | 2048 | 2 | 680 | 2 | 1368
index info | pg_language_oid_index | AllocSet | 3 | {1,22,99} | 2048 | 2 | 824 | 3 | 1224
index info | pg_namespace_oid_index | AllocSet | 3 | {1,22,100} | 2048 | 2 | 680 | 2 | 1368
index info | pg_amproc_fam_proc_index | AllocSet | 3 | {1,22,101} | 3248 | 3 | 840 | 0 | 2408
index info | pg_foreign_server_name_index | AllocSet | 3 | {1,22,102} | 2048 | 2 | 824 | 3 | 1224
index info | pg_attribute_relid_attnam_index | AllocSet | 3 | {1,22,103} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_publication_namespace_pnnspid_pnpubid_index | AllocSet | 3 | {1,22,104} | 3072 | 2 | 1264 | 2 | 1808
index info | pg_conversion_oid_index | AllocSet | 3 | {1,22,105} | 2048 | 2 | 824 | 3 | 1224
index info | pg_user_mapping_user_server_index | AllocSet | 3 | {1,22,106} | 3072 | 2 | 1264 | 2 | 1808
index info | pg_subscription_rel_srrelid_srsubid_index | AllocSet | 3 | {1,22,107} | 3072 | 2 | 1264 | 2 | 1808
index info | pg_sequence_seqrelid_index | AllocSet | 3 | {1,22,108} | 2048 | 2 | 824 | 3 | 1224
index info | pg_extension_name_index | AllocSet | 3 | {1,22,109} | 2048 | 2 | 824 | 3 | 1224
index info | pg_conversion_name_nsp_index | AllocSet | 3 | {1,22,110} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_authid_oid_index | AllocSet | 3 | {1,22,111} | 2048 | 2 | 680 | 2 | 1368
index info | pg_auth_members_member_role_index | AllocSet | 3 | {1,22,112} | 3072 | 2 | 1160 | 2 | 1912
index info | pg_subscription_oid_index | AllocSet | 3 | {1,22,113} | 2048 | 2 | 824 | 3 | 1224
index info | pg_parameter_acl_oid_index | AllocSet | 3 | {1,22,114} | 2048 | 2 | 824 | 3 | 1224
index info | pg_tablespace_oid_index | AllocSet | 3 | {1,22,115} | 2048 | 2 | 680 | 2 | 1368
index info | pg_parameter_acl_parname_index | AllocSet | 3 | {1,22,116} | 2048 | 2 | 824 | 3 | 1224
index info | pg_shseclabel_object_index | AllocSet | 3 | {1,22,117} | 3072 | 2 | 1192 | 2 | 1880
index info | pg_replication_origin_roname_index | AllocSet | 3 | {1,22,118} | 2048 | 2 | 792 | 3 | 1256
index info | pg_database_datname_index | AllocSet | 3 | {1,22,119} | 2048 | 2 | 680 | 2 | 1368
index info | pg_subscription_subname_index | AllocSet | 3 | {1,22,120} | 3072 | 2 | 1296 | 3 | 1776
index info | pg_replication_origin_roiident_index | AllocSet | 3 | {1,22,121} | 2048 | 2 | 792 | 3 | 1256
index info | pg_auth_members_role_member_index | AllocSet | 3 | {1,22,122} | 3072 | 2 | 1160 | 2 | 1912
index info | pg_database_oid_index | AllocSet | 3 | {1,22,123} | 2048 | 2 | 680 | 2 | 1368
index info | pg_authid_rolname_index | AllocSet | 3 | {1,22,124} | 2048 | 2 | 680 | 2 | 1368
GUC hash table | | AllocSet | 3 | {1,27,125} | 32768 | 3 | 11696 | 6 | 21072
ExecutorState | | AllocSet | 4 | {1,20,31,126} | 49200 | 4 | 13632 | 3 | 35568
tuplestore tuples | | Generation | 5 | {1,20,31,126,127} | 32768 | 3 | 13360 | 0 | 19408
printtup | | AllocSet | 5 | {1,20,31,126,128} | 8192 | 1 | 7952 | 0 | 240
Table function arguments | | AllocSet | 5 | {1,20,31,126,129} | 8192 | 1 | 7912 | 0 | 280
ExprContext | | AllocSet | 5 | {1,20,31,126,130} | 32768 | 3 | 5656 | 4 | 27112
pg_get_backend_memory_contexts | | AllocSet | 6 | {1,20,31,126,130,131} | 16384 | 2 | 5664 | 3 | 10720
(131 rows)
This is quite some information, but as said above, this information is only available for the backend process which is attached to the current session.
Starting with PostgreSQL 18, you can most probably get those statistics for other backends as well. For this a new function was added:
postgres=# \dfS pg_get_process_memory_contexts
List of functions
Schema | Name | Result data type | Argument da>
------------+--------------------------------+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------->
pg_catalog | pg_get_process_memory_contexts | SETOF record | pid integer, summary boolean, retries double precision, OUT name text, OUT ident text, OUT type text, OUT path integer[], OUT level integer, OUT total_bytes bigint, OUT >
(1 row)
Let’s play a bit with this. Suppose we have a session which reports this backend process ID:
postgres=# select version();
version
--------------------------------------------------------------------
PostgreSQL 18devel on x86_64-linux, compiled by gcc-14.2.1, 64-bit
(1 row)
postgres=# select pg_backend_pid();
pg_backend_pid
----------------
31291
(1 row)
In another session we can now ask for the summary of the memory contexts for the PID we got in the first session like this (the second parameter turns on the summary, the third is the waiting time in seconds for updated statistics):
postgres=# select * from pg_get_process_memory_contexts(31291,true,2);
name | ident | type | path | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes | num_agg_contexts | stats_timestamp
------------------------------+-------+----------+--------+-------+-------------+---------------+------------+-------------+------------+------------------+------------------------------
TopMemoryContext | | AllocSet | {1} | 1 | 141776 | 6 | 5624 | 11 | 136152 | 1 | 2025-04-08 13:37:38.63979+02
| | ??? | | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2025-04-08 13:37:38.63979+02
search_path processing cache | | AllocSet | {1,2} | 2 | 8192 | 1 | 5656 | 8 | 2536 | 1 | 2025-04-08 13:37:38.63979+02
RowDescriptionContext | | AllocSet | {1,3} | 2 | 8192 | 1 | 6920 | 0 | 1272 | 1 | 2025-04-08 13:37:38.63979+02
MessageContext | | AllocSet | {1,4} | 2 | 16384 | 2 | 7880 | 2 | 8504 | 2 | 2025-04-08 13:37:38.63979+02
Operator class cache | | AllocSet | {1,5} | 2 | 8192 | 1 | 616 | 0 | 7576 | 1 | 2025-04-08 13:37:38.63979+02
smgr relation table | | AllocSet | {1,6} | 2 | 16384 | 2 | 4664 | 3 | 11720 | 1 | 2025-04-08 13:37:38.63979+02
PgStat Shared Ref Hash | | AllocSet | {1,7} | 2 | 9264 | 2 | 712 | 0 | 8552 | 1 | 2025-04-08 13:37:38.63979+02
PgStat Shared Ref | | AllocSet | {1,8} | 2 | 4096 | 3 | 1760 | 3 | 2336 | 1 | 2025-04-08 13:37:38.63979+02
PgStat Pending | | AllocSet | {1,9} | 2 | 8192 | 4 | 7832 | 28 | 360 | 1 | 2025-04-08 13:37:38.63979+02
TopTransactionContext | | AllocSet | {1,10} | 2 | 8192 | 1 | 7952 | 0 | 240 | 1 | 2025-04-08 13:37:38.63979+02
TransactionAbortContext | | AllocSet | {1,11} | 2 | 32768 | 1 | 32528 | 0 | 240 | 1 | 2025-04-08 13:37:38.63979+02
Portal hash | | AllocSet | {1,12} | 2 | 8192 | 1 | 616 | 0 | 7576 | 1 | 2025-04-08 13:37:38.63979+02
TopPortalContext | | AllocSet | {1,13} | 2 | 8192 | 1 | 7952 | 1 | 240 | 1 | 2025-04-08 13:37:38.63979+02
Relcache by OID | | AllocSet | {1,14} | 2 | 16384 | 2 | 3608 | 3 | 12776 | 1 | 2025-04-08 13:37:38.63979+02
CacheMemoryContext | | AllocSet | {1,15} | 2 | 737984 | 182 | 183208 | 221 | 554776 | 88 | 2025-04-08 13:37:38.63979+02
LOCALLOCK hash | | AllocSet | {1,16} | 2 | 8192 | 1 | 616 | 0 | 7576 | 1 | 2025-04-08 13:37:38.63979+02
WAL record construction | | AllocSet | {1,17} | 2 | 50200 | 2 | 6400 | 0 | 43800 | 1 | 2025-04-08 13:37:38.63979+02
PrivateRefCount | | AllocSet | {1,18} | 2 | 8192 | 1 | 2672 | 0 | 5520 | 1 | 2025-04-08 13:37:38.63979+02
MdSmgr | | AllocSet | {1,19} | 2 | 8192 | 1 | 7936 | 0 | 256 | 1 | 2025-04-08 13:37:38.63979+02
GUCMemoryContext | | AllocSet | {1,20} | 2 | 57344 | 5 | 19960 | 7 | 37384 | 2 | 2025-04-08 13:37:38.63979+02
Timezones | | AllocSet | {1,21} | 2 | 104112 | 2 | 2672 | 0 | 101440 | 1 | 2025-04-08 13:37:38.63979+02
Turning off the summary, gives you the full picture:
postgres=# select * from pg_get_process_memory_contexts(31291,false,2) order by level, name;
name | ident | type | path | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes | num_agg_contexts | stats_timestamp
---------------------------------------+------------------------------------------------+----------+------------+-------+-------------+---------------+------------+-------------+------------+------------------+-------------------------------
TopMemoryContext | | AllocSet | {1} | 1 | 141776 | 6 | 5624 | 11 | 136152 | 1 | 2025-04-08 13:38:02.508423+02
CacheMemoryContext | | AllocSet | {1,15} | 2 | 524288 | 7 | 101280 | 1 | 423008 | 1 | 2025-04-08 13:38:02.508423+02
ErrorContext | | AllocSet | {1,22} | 2 | 8192 | 1 | 7952 | 4 | 240 | 1 | 2025-04-08 13:38:02.508423+02
GUCMemoryContext | | AllocSet | {1,20} | 2 | 24576 | 2 | 8264 | 1 | 16312 | 1 | 2025-04-08 13:38:02.508423+02
LOCALLOCK hash | | AllocSet | {1,16} | 2 | 8192 | 1 | 616 | 0 | 7576 | 1 | 2025-04-08 13:38:02.508423+02
MdSmgr | | AllocSet | {1,19} | 2 | 8192 | 1 | 7936 | 0 | 256 | 1 | 2025-04-08 13:38:02.508423+02
MessageContext | | AllocSet | {1,4} | 2 | 16384 | 2 | 2664 | 4 | 13720 | 1 | 2025-04-08 13:38:02.508423+02
Operator class cache | | AllocSet | {1,5} | 2 | 8192 | 1 | 616 | 0 | 7576 | 1 | 2025-04-08 13:38:02.508423+02
PgStat Pending | | AllocSet | {1,9} | 2 | 8192 | 4 | 7832 | 28 | 360 | 1 | 2025-04-08 13:38:02.508423+02
PgStat Shared Ref | | AllocSet | {1,8} | 2 | 4096 | 3 | 1760 | 3 | 2336 | 1 | 2025-04-08 13:38:02.508423+02
PgStat Shared Ref Hash | | AllocSet | {1,7} | 2 | 9264 | 2 | 712 | 0 | 8552 | 1 | 2025-04-08 13:38:02.508423+02
Portal hash | | AllocSet | {1,12} | 2 | 8192 | 1 | 616 | 0 | 7576 | 1 | 2025-04-08 13:38:02.508423+02
PrivateRefCount | | AllocSet | {1,18} | 2 | 8192 | 1 | 2672 | 0 | 5520 | 1 | 2025-04-08 13:38:02.508423+02
Relcache by OID | | AllocSet | {1,14} | 2 | 16384 | 2 | 3608 | 3 | 12776 | 1 | 2025-04-08 13:38:02.508423+02
RowDescriptionContext | | AllocSet | {1,3} | 2 | 8192 | 1 | 6920 | 0 | 1272 | 1 | 2025-04-08 13:38:02.508423+02
search_path processing cache | | AllocSet | {1,2} | 2 | 8192 | 1 | 5656 | 8 | 2536 | 1 | 2025-04-08 13:38:02.508423+02
smgr relation table | | AllocSet | {1,6} | 2 | 16384 | 2 | 4664 | 3 | 11720 | 1 | 2025-04-08 13:38:02.508423+02
Timezones | | AllocSet | {1,21} | 2 | 104112 | 2 | 2672 | 0 | 101440 | 1 | 2025-04-08 13:38:02.508423+02
TopPortalContext | | AllocSet | {1,13} | 2 | 8192 | 1 | 7952 | 1 | 240 | 1 | 2025-04-08 13:38:02.508423+02
TopTransactionContext | | AllocSet | {1,10} | 2 | 8192 | 1 | 7952 | 0 | 240 | 1 | 2025-04-08 13:38:02.508423+02
TransactionAbortContext | | AllocSet | {1,11} | 2 | 32768 | 1 | 32528 | 0 | 240 | 1 | 2025-04-08 13:38:02.508423+02
WAL record construction | | AllocSet | {1,17} | 2 | 50200 | 2 | 6400 | 0 | 43800 | 1 | 2025-04-08 13:38:02.508423+02
GUC hash table | | AllocSet | {1,20,111} | 3 | 32768 | 3 | 11696 | 6 | 21072 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_dict_oid_index | AllocSet | {1,15,46} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_event_trigger_oid_index | AllocSet | {1,15,47} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_conversion_default_index | AllocSet | {1,15,48} | 3 | 2224 | 2 | 216 | 0 | 2008 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_operator_oprname_l_r_n_index | AllocSet | {1,15,49} | 3 | 2224 | 2 | 216 | 0 | 2008 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_trigger_tgrelid_tgname_index | AllocSet | {1,15,50} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_extension_oid_index | AllocSet | {1,15,51} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_enum_typid_label_index | AllocSet | {1,15,52} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_config_oid_index | AllocSet | {1,15,53} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_user_mapping_oid_index | AllocSet | {1,15,54} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_opfamily_am_name_nsp_index | AllocSet | {1,15,55} | 3 | 3072 | 2 | 1192 | 2 | 1880 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_foreign_table_relid_index | AllocSet | {1,15,56} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_type_oid_index | AllocSet | {1,15,57} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_aggregate_fnoid_index | AllocSet | {1,15,58} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_constraint_oid_index | AllocSet | {1,15,59} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_rewrite_rel_rulename_index | AllocSet | {1,15,60} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_parser_prsname_index | AllocSet | {1,15,61} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_config_cfgname_index | AllocSet | {1,15,62} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_parser_oid_index | AllocSet | {1,15,63} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_publication_rel_prrelid_prpubid_index | AllocSet | {1,15,64} | 3 | 3072 | 2 | 1264 | 2 | 1808 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_operator_oid_index | AllocSet | {1,15,65} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_namespace_nspname_index | AllocSet | {1,15,66} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_template_oid_index | AllocSet | {1,15,67} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_amop_opr_fam_index | AllocSet | {1,15,68} | 3 | 3072 | 2 | 1192 | 2 | 1880 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_default_acl_role_nsp_obj_index | AllocSet | {1,15,69} | 3 | 3072 | 2 | 1160 | 2 | 1912 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_collation_name_enc_nsp_index | AllocSet | {1,15,70} | 3 | 3072 | 2 | 1192 | 2 | 1880 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_publication_rel_oid_index | AllocSet | {1,15,71} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_range_rngtypid_index | AllocSet | {1,15,72} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_dict_dictname_index | AllocSet | {1,15,73} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_type_typname_nsp_index | AllocSet | {1,15,74} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_opfamily_oid_index | AllocSet | {1,15,75} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_statistic_ext_oid_index | AllocSet | {1,15,76} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_statistic_ext_data_stxoid_inh_index | AllocSet | {1,15,77} | 3 | 3072 | 2 | 1264 | 2 | 1808 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_class_oid_index | AllocSet | {1,15,78} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_proc_proname_args_nsp_index | AllocSet | {1,15,79} | 3 | 3072 | 2 | 1048 | 1 | 2024 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_partitioned_table_partrelid_index | AllocSet | {1,15,80} | 3 | 2048 | 2 | 792 | 3 | 1256 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_range_rngmultitypid_index | AllocSet | {1,15,81} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_transform_type_lang_index | AllocSet | {1,15,82} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_attribute_relid_attnum_index | AllocSet | {1,15,83} | 3 | 3072 | 2 | 1080 | 3 | 1992 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_proc_oid_index | AllocSet | {1,15,84} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_language_oid_index | AllocSet | {1,15,85} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_namespace_oid_index | AllocSet | {1,15,86} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_amproc_fam_proc_index | AllocSet | {1,15,87} | 3 | 3248 | 3 | 912 | 0 | 2336 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_foreign_server_name_index | AllocSet | {1,15,88} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_attribute_relid_attnam_index | AllocSet | {1,15,89} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_publication_namespace_pnnspid_pnpubid_index | AllocSet | {1,15,90} | 3 | 3072 | 2 | 1264 | 2 | 1808 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_conversion_oid_index | AllocSet | {1,15,91} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_user_mapping_user_server_index | AllocSet | {1,15,92} | 3 | 3072 | 2 | 1264 | 2 | 1808 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_subscription_rel_srrelid_srsubid_index | AllocSet | {1,15,93} | 3 | 3072 | 2 | 1264 | 2 | 1808 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_sequence_seqrelid_index | AllocSet | {1,15,94} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_extension_name_index | AllocSet | {1,15,95} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_conversion_name_nsp_index | AllocSet | {1,15,96} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_authid_oid_index | AllocSet | {1,15,97} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_subscription_oid_index | AllocSet | {1,15,99} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_parameter_acl_oid_index | AllocSet | {1,15,100} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_tablespace_oid_index | AllocSet | {1,15,101} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_parameter_acl_parname_index | AllocSet | {1,15,102} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_shseclabel_object_index | AllocSet | {1,15,103} | 3 | 3072 | 2 | 1192 | 2 | 1880 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_replication_origin_roname_index | AllocSet | {1,15,104} | 3 | 2048 | 2 | 792 | 3 | 1256 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_database_datname_index | AllocSet | {1,15,105} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_subscription_subname_index | AllocSet | {1,15,106} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_replication_origin_roiident_index | AllocSet | {1,15,107} | 3 | 2048 | 2 | 792 | 3 | 1256 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_auth_members_role_member_index | AllocSet | {1,15,108} | 3 | 3072 | 2 | 1160 | 2 | 1912 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_database_oid_index | AllocSet | {1,15,109} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_authid_rolname_index | AllocSet | {1,15,110} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_auth_members_member_role_index | AllocSet | {1,15,98} | 3 | 3072 | 2 | 1160 | 2 | 1912 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_db_role_setting_databaseid_rol_index | AllocSet | {1,15,24} | 3 | 3072 | 2 | 1120 | 1 | 1952 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_opclass_am_name_nsp_index | AllocSet | {1,15,25} | 3 | 3072 | 2 | 1192 | 2 | 1880 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_foreign_data_wrapper_name_index | AllocSet | {1,15,26} | 3 | 2048 | 2 | 792 | 3 | 1256 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_enum_oid_index | AllocSet | {1,15,27} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_class_relname_nsp_index | AllocSet | {1,15,28} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_foreign_server_oid_index | AllocSet | {1,15,29} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_publication_pubname_index | AllocSet | {1,15,30} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_statistic_relid_att_inh_index | AllocSet | {1,15,31} | 3 | 3072 | 2 | 1160 | 2 | 1912 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_cast_source_target_index | AllocSet | {1,15,32} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_language_name_index | AllocSet | {1,15,33} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_transform_oid_index | AllocSet | {1,15,34} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_collation_oid_index | AllocSet | {1,15,35} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_amop_fam_strat_index | AllocSet | {1,15,36} | 3 | 2224 | 2 | 216 | 0 | 2008 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_index_indexrelid_index | AllocSet | {1,15,37} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_template_tmplname_index | AllocSet | {1,15,38} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_ts_config_map_index | AllocSet | {1,15,39} | 3 | 3072 | 2 | 1192 | 2 | 1880 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_opclass_oid_index | AllocSet | {1,15,40} | 3 | 2048 | 2 | 680 | 2 | 1368 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_foreign_data_wrapper_oid_index | AllocSet | {1,15,41} | 3 | 2048 | 2 | 792 | 3 | 1256 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_publication_namespace_oid_index | AllocSet | {1,15,42} | 3 | 2048 | 2 | 792 | 3 | 1256 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_event_trigger_evtname_index | AllocSet | {1,15,43} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_statistic_ext_name_index | AllocSet | {1,15,44} | 3 | 3072 | 2 | 1296 | 3 | 1776 | 1 | 2025-04-08 13:38:02.508423+02
index info | pg_publication_oid_index | AllocSet | {1,15,45} | 3 | 2048 | 2 | 824 | 3 | 1224 | 1 | 2025-04-08 13:38:02.508423+02
pg_get_remote_backend_memory_contexts | | AllocSet | {1,4,23} | 3 | 16384 | 2 | 6568 | 3 | 9816 | 1 | 2025-04-08 13:38:02.508423+02
(111 rows)
As you can see above there are many entries with “index info” which are not directly visible in the summary view. The reason is the aggregation when you go for the summary. All “index info” entries are aggregated into under “CacheMemoryContext” and we can easily verify this:
postgres=# select count(*) from pg_get_process_memory_contexts(31291,false,2) where name = 'index info';
count
-------
87
(1 row)
… which is very close to the 88 aggregations reported in the summary. Excluding all the system/catalog indexes we get the following picture:
postgres=# select * from pg_get_process_memory_contexts(31291,false,2) where name = 'index info' and ident !~ 'pg_';
name | ident | type | path | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes | num_agg_contexts | stats_timestamp
------+-------+------+------+-------+-------------+---------------+------------+-------------+------------+------------------+-----------------
(0 rows)
-- system/catalog indexes
postgres=# select count(*) from pg_get_process_memory_contexts(31291,false,2) where name = 'index info' and ident ~ 'pg_';
count
-------
87
(1 row)
Creating a new table and an index on that table in the first session will change the picture to this:
-- first session
postgres=# create table t ( a int );
CREATE TABLE
postgres=# create index i on t(a);
CREATE INDEX
postgres=#
-- second session
postgres=# select * from pg_get_process_memory_contexts(31291,false,2) where name = 'index info' and ident !~ 'pg_';
name | ident | type | path | level | total_bytes | total_nblocks | free_bytes | free_chunks | used_bytes | num_agg_contexts | stats_timestamp
------------+-------+----------+-----------+-------+-------------+---------------+------------+-------------+------------+------------------+-------------------------------
index info | i | AllocSet | {1,16,26} | 3 | 2048 | 2 | 776 | 3 | 1272 | 1 | 2025-04-08 13:44:55.496668+02
(1 row)
… and this will also increase the aggregation count we did above:
postgres=# select count(*) from pg_get_process_memory_contexts(31291,false,2) where name = 'index info';
count
-------
98
(1 row)
… but why to 98 and not to 89? Because additional system indexes have also been loaded (I let it as an exercise to you find out which ones those are):
postgres=# select count(*) from pg_get_process_memory_contexts(31291,false,2) where name = 'index info' and ident ~ 'pg_';
count
-------
97
(1 row)
You can go on and do additional tests for the other memory contexts to get an idea how that works. Personally, I think this is a great new feature because you can now have a look at the memory contexts of problematic processes. Thanks to all involved, details here.
L’article PostgreSQL 18: Add function to report backend memory contexts est apparu en premier sur dbi Blog.
PostgreSQL 18: Allow NOT NULL constraints to be added as NOT VALID
Before we take a look at what this new feature is about, let’s have a look at how PostgreSQL 17 (and before) handles “NOT NULL” constraints when they get created. As usual we start with a simple table:
postgres=# select version();
version
-----------------------------------------------------------------------------------------------------------------------------
PostgreSQL 17.2 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 14.2.1 20250110 (Red Hat 14.2.1-7), 64-bit
(1 row)
postgres=# create table t ( a int not null, b text );
CREATE TABLE
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | not null |
b | text | | |
Trying to insert data into that table which violates the constraint of course will fail:
postgres=# insert into t select null,1 from generate_series(1,2);
ERROR: null value in column "a" of relation "t" violates not-null constraint
DETAIL: Failing row contains (null, 1).
Even if you can set the column to “NOT NULL” syntax wise, this will not disable the constraint:
postgres=# alter table t alter column a set not null;
ALTER TABLE
postgres=# insert into t select null,1 from generate_series(1,2);
ERROR: null value in column "a" of relation "t" violates not-null constraint
DETAIL: Failing row contains (null, 1).
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | not null |
b | text | | |
The only option you have when you want to do this, is to drop the constraint:
postgres=# alter table t alter column a drop not null;
ALTER TABLE
postgres=# insert into t select null,1 from generate_series(1,2);
INSERT 0 2
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | |
b | text | | |
The use case for this is data loading. Maybe you want to load data where you know that the constraint would be violated but you’re ok with fixing that manually afterwards and then re-enable the constraint like this:
postgres=# update t set a = 1;
UPDATE 2
postgres=# alter table t alter column a set not null;
ALTER TABLE
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | not null |
b | text | | |
postgres=# insert into t select null,1 from generate_series(1,2);
ERROR: null value in column "a" of relation "t" violates not-null constraint
DETAIL: Failing row contains (null, 1).
This will change with PostgreSQL 18. From now you have more options. The following still behaves as before:
postgres=# select version();
version
--------------------------------------------------------------------
PostgreSQL 18devel on x86_64-linux, compiled by gcc-14.2.1, 64-bit
(1 row)
postgres=# create table t ( a int, b text );
CREATE TABLE
postgres=# alter table t add constraint c1 not null a;
ALTER TABLE
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | not null |
b | text | | |
postgres=# insert into t select null,1 from generate_series(1,2);
ERROR: null value in column "a" of relation "t" violates not-null constraint
DETAIL: Failing row contains (null, 1).
This, of course, leads to the same behavior as with PostgreSQL 17 above. But now you can do this:
postgres=# create table t ( a int, b text );
CREATE TABLE
postgres=# insert into t select null,1 from generate_series(1,2);
INSERT 0 2
postgres=# alter table t add constraint c1 not null a not valid;
ALTER TABLE
This gives us a “NOT NULL” constraint which will not be enforced when it is created. Doing the same in PostgreSQL 17 (and before) will scan the table and enforce the constraint:
postgres=# select version();
version
-----------------------------------------------------------------------------------------------------------------------------
PostgreSQL 17.2 dbi services build on x86_64-pc-linux-gnu, compiled by gcc (GCC) 14.2.1 20250110 (Red Hat 14.2.1-7), 64-bit
(1 row)
postgres=# create table t ( a int, b text );
CREATE TABLE
postgres=# insert into t select null,1 from generate_series(1,2);
INSERT 0 2
postgres=# alter table t add constraint c1 not null a not valid;
ERROR: syntax error at or near "not"
LINE 1: alter table t add constraint c1 not null a not valid;
^
postgres=# alter table t alter column a set not null;
ERROR: column "a" of relation "t" contains null values
As you can see the syntax is not supported and adding a “NOT NULL” constraint will scan the table and enforce the constraint.
Back to the PostgreSQL 18 cluster. As we now have data which would violate the constraint:
postgres=# select * from t;
a | b
---+---
| 1
| 1
(2 rows)
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
a | integer | | not null |
b | text | | |
… we can fix that manually and then validate the constraint afterwards:
postgres=# update t set a = 1;
UPDATE 2
postgres=# alter table t validate constraint c1;
ALTER TABLE
postgres=# insert into t values (null, 'a');
ERROR: null value in column "a" of relation "t" violates not-null constraint
DETAIL: Failing row contains (null, a).
Nice, thanks to all involved, details here.
L’article PostgreSQL 18: Allow NOT NULL constraints to be added as NOT VALID est apparu en premier sur dbi Blog.
Best Practices for Structuring Metadata in M-Files
In one of my previous post, I talked about the importance of Metadata, it is the skeleton of efficient document management system and particularly in M-Files!
As I like to say, M-Files is like an empty shell that can be very easily customized to obtain the ideal solution for our business/customers.
Unlike traditional folder-based storage, M-Files leverages metadata to classify, search, and retrieve documents with ease.
Properly structuring metadata ensures better organization, improved searchability, and enhanced workflow automation.
In this blog post, we will explore best practices for structuring metadata in M-Files to maximize its potential.
Metadata in M-Files is used to describe documents, making them easier to find and categorize.
Instead of placing files in rigid folder structures, metadata allows documents to be dynamically organized based on properties such as document type, project, client, or status…
Metadata are then used to create views, which are simply predefined searches based on them.
Additionally M-files is able to make automatic relations between different objects.
For example in a project “XXX” related to a customer “YYY”, all associated documents to this project are automatically related (and findable) to the customer.
Or Choosing a “Document Type” can dictate required approval workflows.
Another advantage can be, only the members working on the project can access the customers information and contacts…
Define Clear and Consistent Metadata FieldsWhen setting up metadata in M-Files, define clear fields that align with your business processes. Some essential metadata fields include:
- Document Type (e.g., Invoice, Contract, Report)
- Department (e.g., HR, Finance, Legal)
- Project or Client Name
- Status (e.g., Draft, Approved, Archived)
Ensure consistency by using standardized field names and avoiding duplicate or unnecessary fields.
When values are known like for Departments or Status,… better to use the Value lists to ensure the accuracy of the data (no typo-mistake, no end user creativity).
To make sure to respect the company naming convention, use the automatic values on properties, it can be:
- Automatic numbering
- Customized Numbering
- Concatenation of properties
- Calculated value (script)
M-Files provides customizable metadata cards, allowing users to input relevant data efficiently.
Often there are properties not relevant for the end user, we can use the Metadata card configuration to hide them.
To improve readability, we can also create “section” to logically group the properties.
And Finally, Metadata card Configuration can be used to set default value and provide tips (Property description and/or Tooltip).

Reduce manual entry and improve accuracy by setting up automatic metadata population.
M-Files, with the help of its intelligence service (previous post here), can suggest metadata from file properties, templates, or integrated systems, minimizing human error and saving time.
M-Files is a living system and needs and must evolve with the business needs.
It is important to periodically review metadata structures to ensure they remain relevant.
Refine metadata rules, and continuously train employees on best practices to keep your M-Files environment optimized.

A well-structured metadata system in M-Files enhances efficiency, improves document retrieval, and supports seamless automation. By implementing these best practices, organizations can create a smarter document management strategy that adapts to their needs.
Are you making the most of metadata in M-Files? Good news it’s never to late with M-Files, so start optimizing your structure today!
If you feel a bit lost, we can help you!
L’article Best Practices for Structuring Metadata in M-Files est apparu en premier sur dbi Blog.
Working with Btrfs & Snapper
In this Blog post I will try to give a pure technical cheat sheet using Btrfs on any distribution. Additionally I will explain how to use one of the most sophisticated backup/ restore tool called “snapper”.
What is Btrfs and how to set it up if not already installed?Btrfs (aka Butter FS or aka B-Tree FS) is like xfs and ext4 a filesystem which offers any linux user many features to maintain or manage their filesystem. Usually Btrfs is used stand-alone but it works with LVM2 too, without any additional configuration.
Key Features of Btrfs:
- Copy-on-Write (CoW): Btrfs uses CoW, meaning it creates new copies of data instead of overwriting existing files.
- Snapshots: You can create instant, space-efficient snapshots of your filesystem or specific directories, like with Snapper on SUSE. These are perfect for backups, rollbacks, or tracking changes (e.g., before/after updates).
- Self-Healing: Btrfs supports data integrity with checksums and can detect and repair errors, especially with RAID configurations.
- Flexible Storage: It handles multiple devices, RAID (0, 1, 5, 6, 10), and dynamic resizing, making it adaptable for growing storage needs.
- Compression: Btrfs can compress files on the fly (e.g., using Zstandard or LZO), saving space without sacrificing performance.
- Subvolumes: Btrfs lets you create logical partitions (subvolumes) within the same filesystem, enabling fine-grained control. It is like having separate root, home, or snapshot subvolumes.
Usually Btrfs is used by default in any SuSE Linux Server (and OpenSuSE) and can be used in RHEL & OL and other distribution. To use Btrfs on any RPM based distribution just install the package “btrfs-progs”. With Debian and Ubuntu this is a bit more tricky, which is why we will keep this blog about RPM-based distributions only.
Create new filesystem and increase it with Btrfs# Wipe any old filesystem on /dev/sdb (careful—data’s toast!)
wipefs -a /dev/vdb
# Create a Btrfs filesystem on /dev/sdb
mkfs.btrfs /dev/vdb
# Make a mount point
mkdir /mnt/btrfs
# Mount it—basic setup, no fancy options yet
mount /dev/vdb /mnt/btrfs
# Check it’s there and Btrfs
df -h /mnt/btrfs
# Add to /etc/fstab for permanence (use your device UUID from blkid)
/dev/vdb /mnt/btrfs btrfs defaults 0 2
# Test fstab
mount -a
# List all Btrfs Filesystems
btrfs filesystem show
# Add additional storage to existing Btrfs filesystem (in our case /)
btrfs add device /dev/vdd /
# In some cases it is smart to balance the storage between all the devices
btrfs balance start /
# If the space allows it you can remove devices from a Btrfs filesystem
btrfs device delete /dev/vdd /# List all snapshots for the root config
snapper -c root list
# Pick a snapshot and check its diff (example with 5 & 6)
snapper -c root diff 5..6
# Roll back to snapshot 5 (dry run first)
snapper -c root rollback 5 --print-number
# Do it for real—reboots to snapshot 5
snapper -c root rollback 5
reboot
# Verify after reboot—root’s now at snapshot 5
snapper -c root list# Mount the Btrfs root filesystem (not a subvolume yet)
mount /dev/vdb /mnt/butter
# Create a subvolume called ‘data’ (only possible inside a existing Btrfs volume)
btrfs subvolume create /mnt/butter/data
# List subvolumes
btrfs subvolume list /mnt/butter
# Make a mount point for the subvolume
mkdir /mnt/data
# Mount the subvolume explicitly
mount -o subvol=data /dev/vdb /mnt/data
# Check it’s mounted as a subvolume
df -h /mnt/data
# Create a new subvolume by creating a snapshot inside the btrfs volume
btrfs subvolume snapshot /mnt/data /mnt/butter/data-snap1
# Delete the snapshot which is a subvolume
btrfs subvolume delete /mnt/data-snap1# Install Snapper if it’s not there
zypper install snapper
# Create a snapper config of filesystem
snapper -c <ConfigName> create-config <btrfs-mountpoint>
# Enable timeline snapshots (if not enabled by default)
echo "TIMELINE_CREATE=\"yes\"" >> /etc/snapper/configs/root
# Set snapshot limits (e.g., keep 10 hourly)
sed -i 's/TIMELINE_LIMIT_HOURLY=.*/TIMELINE_LIMIT_HOURLY="10"/' /etc/snapper/configs/root
# Start the Snapper timer (if not enabled by default)
systemctl enable snapper-timeline.timer
systemctl start snapper-timeline.timer
# Trigger a manual snapshot to test
snapper -c <ConfigName> create -d "Manual test snapshot"
# List snapshots to confirm
snapper -c <ConfigName> listHere is a small overview of the most important settings to use within a snapper config file:
- SPACE_LIMIT=”0.5″
- Sets the maximum fraction of the filesystem’s space that snapshots can occupy. 0.5 = 50%
- FREE_LIMIT=”0.2″
- Ensures a minimum fraction of the filesystem stays free. 0.2= 20%
- ALLOW_USERS=”admin dbi”
- Lists users allowed to manage this Snapper config.
- ALLOW_GROUPS=”admins”
- A list of Groups that are allowed to manage this config.
- SYNC_ACL=”no”
- Syncs permissions from ALLOW_USERS and ALLOW_GROUPS to the .snapshots directory. If yes, Snapper updates the access control lists on /.snapshots to match ALLOW_USERS/ALLOW_GROUPS. With no, it skips this, and you manage permissions manually.
- NUMBER_CLEANUP=”yes”
- When yes, Snapper deletes old numbered snapshots (manual and/ or automated ones) when they exceed NUMBER_LIMIT or age past NUMBER_MIN_AGE.
- NUMBER_MIN_AGE=”1800″
- Minimum age (in seconds) before a numbered snapshot can be deleted.
- NUMBER_LIMIT=”50″
- Maximum number of numbered snapshots to keep.
- NUMBER_LIMIT_IMPORTANT=”10″
- Maximum number of numbered snapshots marked as “important” to keep.
- TIMELINE_CREATE=”yes”
- Enables automatic timeline snapshots.
- TIMELINE_CLEANUP=”yes”
- Enables cleanup of timeline snapshots based on limits.
- TIMELINE_LIMIT_*=”10″
- TIMELINE_LIMIT_HOURLY=”10″
- TIMELINE_LIMIT_DAILY=”10″
- TIMELINE_LIMIT_WEEKLY=”0″ (disabled)
- TIMELINE_LIMIT_MONTHLY=”10″
- TIMELINE_LIMIT_YEARLY=”10″
- Controls how many snapshots Snapper retains over time. Keeps 10 hourly, 10 daily, 10 monthly, and 10 yearly, but skips weekly 0.
For further information about the settings, check out the SUSE documentation.
Btrfs RAID and Multi-Device management# Format two disks (/dev/vdb, /dev/vdc) as Btrfs RAID1
mkfs.btrfs -d raid1 -m raid1 /dev/vdb /dev/vdc
# Mount it
mount /dev/vdb /mnt/btrfs-raid
# Check RAID status
btrfs filesystem show /mnt/btrfs-raid
# Add a third disk (/dev/sdd) to the array
btrfs device add /dev/sdd /mnt/btrfs-raid
# Rebalance to RAID1 across all three (dconvert is data raid and mconvert is metadata raid definition)
btrfs balance start -dconvert=raid1 -mconvert=raid1 /mnt/btrfs-raid
# Check device stats for errors
btrfs device stats /mnt/btrfs-raid
# Remove a disk if needed
btrfs device delete /dev/vdc /mnt/btrfs-raid# Check disk usage?
btrfs filesystem df /mnt/btrfs
# Full filesystem and need more storage? Add an additional empty storage device to the Btrfs volume:
btrfs add device /dev/vde /mnt/btrfs
# If the storage devices has grown (via LVM or virtually) one can resize the size to max:
btrfs filesystem resize max /mnt/btrfs
# Balance to free space if it’s tight (dusage defines from what % the rebalance should start. In our case only 50% or less data per block will trigger the re-balance)
btrfs balance start -dusage=50 /mnt/btrfs
# Too many snapshots? List them
snapper -c root list | wc -l
# Delete old snapshots (e.g., #10)
snapper -c root delete 10
# Check filesystem for corruption
btrfs check /dev/vdb
# Repair if it’s borked (careful—backup first!)
btrfs check --repair /dev/vdb
# Rollback stuck? Force it
snapper -c root rollback 5 --force
Something that needs to be pointed out is that the snapper list is sorted from the oldest (starting at point 1) to the newest. BUT: At the top there is always the current state of the filesystem with the number 0.
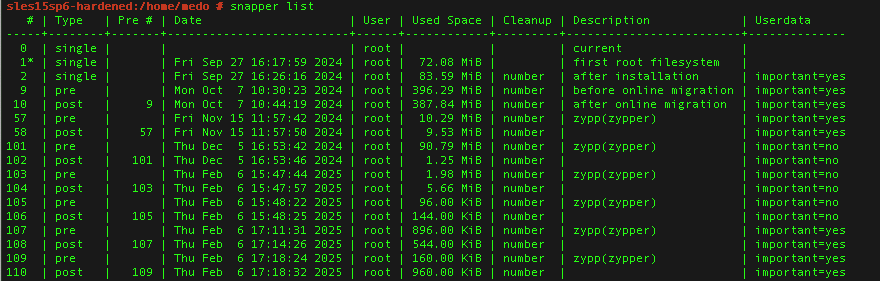
L’article Working with Btrfs & Snapper est apparu en premier sur dbi Blog.
Installing and configuring Veeam RMAN plug-in on an ODA
I recently had to install and configure the Veeam RMAN plug-in on an ODA, and would like to provide the steps in this article, as it might be helpful for many other people.
Read more: Installing and configuring Veeam RMAN plug-in on an ODA Create Veeam linux OS user
We will create an OS linux user on the ODA that will be used to authenticate on the Veeam Backup server. This user on the sever will need to have the Veeam Backup Administrator role or Veeam Backup Operator and Veeam Restore Operator roles.
Check if role for user and group is not already used:
[root@ODA02 ~]# grep 497 /etc/group [root@ODA02 ~]# grep 54323 /etc/passwd
Create the group:
[root@ODA02 ~]# groupadd -g 497 veeam
Create the user:
[root@ODA02 ~]# useradd -g 497 -u 54323 -d /home/veeam -s /bin/bash oda_veeam [root@ODA02 ~]# passwd oda_veeam Changing password for user oda_veeam. New password: Retype new password: passwd: all authentication tokens updated successfully.Installing Veeam RMAN plug-in
As we know, we might need to be careful installing new packages on an ODA, and we might need to remove them during patching in case of issue. We could easily here install the plug-in with a rpm, knowing no dependencies are needed, but I decided to even be less transparent installing the plugin with the tar file.
I installed the agent with the root user.
The downloaded tar file:
[root@ODA02 ~]# ls -ltrh Veeam*.tar* -rw-r--r-- 1 root root 62M Oct 31 15:08 VeeamPluginforOracleRMAN.tar.gz
I created the directory for the installation:
[root@ODA02 ~]# mkdir /opt/veeam
And uncompressed it in the newly created directory:
[root@ODA02 ~]# tar -xzvf VeeamPluginforOracleRMAN.tar.gz -C /opt/veeam VeeamPluginforOracleRMAN/ VeeamPluginforOracleRMAN/oracleproxy VeeamPluginforOracleRMAN/RMANPluginManager VeeamPluginforOracleRMAN/OracleRMANConfigTool VeeamPluginforOracleRMAN/3rdPartyNotices.txt VeeamPluginforOracleRMAN/libOracleRMANPlugin.so VeeamPluginforOracleRMAN/veeamagent
I checked the files:
[root@ODA02 ~]# ls -ltrh /opt/veeam/ total 4.0K drwxr-xr-x 2 grid 1000 4.0K Aug 24 04:10 VeeamPluginforOracleRMAN [root@ODA02 ~]# cd /opt/veeam/VeeamPluginforOracleRMAN/ [root@ODA02 VeeamPluginforOracleRMAN]# ls -ltrh total 167M -rwxr-xr-x 1 grid 1000 81M Aug 24 04:10 veeamagent -rwxr-xr-x 1 grid 1000 37M Aug 24 04:10 RMANPluginManager -rwxr-xr-x 1 grid 1000 35M Aug 24 04:10 OracleRMANConfigTool -rwxr-xr-x 1 grid 1000 6.7M Aug 24 04:10 oracleproxy -rwxr-xr-x 1 grid 1000 7.0M Aug 24 04:10 libOracleRMANPlugin.so -r--r--r-- 1 grid 1000 65K Aug 24 04:10 3rdPartyNotices.txt
And changed the ownership to root:
[root@ODA02 veeam]# pwd /opt/veeam [root@ODA02 veeam]# ls -l total 4 drwxr-xr-x 2 grid 1000 4096 Aug 24 04:10 VeeamPluginforOracleRMAN [root@ODA02 veeam]# chown -R root: VeeamPluginforOracleRMAN/ [root@ODA02 veeam]# ls -l total 4 drwxr-xr-x 2 root root 4096 Aug 24 04:10 VeeamPluginforOracleRMAN [root@ODA02 veeam]# ls -l VeeamPluginforOracleRMAN/ total 170052 -r--r--r-- 1 root root 65542 Aug 24 04:10 3rdPartyNotices.txt -rwxr-xr-x 1 root root 7251448 Aug 24 04:10 libOracleRMANPlugin.so -rwxr-xr-x 1 root root 6968560 Aug 24 04:10 oracleproxy -rwxr-xr-x 1 root root 36475936 Aug 24 04:10 OracleRMANConfigTool -rwxr-xr-x 1 root root 38515744 Aug 24 04:10 RMANPluginManager -rwxr-xr-x 1 root root 84837408 Aug 24 04:10 veeamagent
I gave writable permissions to other group, so oracle linux user can write in the directory:
[root@ODA02 veeam]# pwd /opt/veeam [root@ODA02 veeam]# chmod o+w VeeamPluginforOracleRMAN/ [root@ODA02 veeam]# ls -l total 4 drwxr-xrwx 2 root root 4096 Aug 24 04:10 VeeamPluginforOracleRMANConfigure Veeam RMAN plug-in
With oracle linux, we now need to configure the plugin. The information like the backup repositories name, will come from the Veeam Backup server side. We are running SE2 databases, so there will be no parallelism. The installation script will not ask for any number of channels.
The following information that can be requested:
- DNS name or IP address of the Veeam Backup & Replication server
- port which will be used to communicate with the Veeam Backup & Replication server. Default port is 10006
- OS user credentials to authenticate against the Veeam Backup & Replication server
- The backup repository to be selected from a list of available one. For duplexing functionality you can select up to 4 repositories.
- The number of channel for parallelism backup. In our case, as we use SE2 database, this options will not be requested.
- Compression or no compression
- Authentication method between OS or database one. We will use OS authentication. We will use oracle linux user as it is part of DBA group (mandatory)
Running the configuration command:
[oracle@ODA02 VeeamPluginforOracleRMAN]$ ./OracleRMANConfigTool --wizard Enter backup server name or IP address: X.X.X.41 Enter backup server port number [10006]: Enter username: oda_veeam Enter password for oda_veeam: Available backup repositories: 1. Select Veeam repository from the list by typing the repository number: 1 RMAN parallelism is not supported in Oracle Standard Edition. Do you want to use Veeam compression? (Y/n): Y Select the Oracle environment authentication method: 1. Operating system authentication 2. Database authentication Enter [1]: The current user is restricted and cannot read required OS information. Please re-run the following command with root rights: OracleRMANConfigTool --set-credentials RMAN settings: CONFIGURE DEFAULT DEVICE TYPE TO SBT_TAPE; CONFIGURE CHANNEL DEVICE TYPE SBT_TAPE PARMS 'SBT_LIBRARY=/opt/veeam/VeeamPluginforOracleRMAN/libOracleRMANPlugin.so' FORMAT 'e718bc55-0c60-43bc-b1f7-f8cf2c793120/RMAN_%I_%d_%T_%U.vab'; CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE SBT_TAPE TO 1; CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE SBT_TAPE TO 1; CONFIGURE DEVICE TYPE SBT_TAPE PARALLELISM 1; CONFIGURE CONTROLFILE AUTOBACKUP ON; CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE SBT_TAPE TO '%F_RMAN_AUTOBACKUP.vab'; RMAN settings will be applied automatically to the following databases: ORACLE_SID=INST1 ORACLE_HOME=/u01/app/odaorahome/oracle/product/19.0.0.0/dbhome_1 ORACLE_SID=INST2 ORACLE_HOME=/u01/app/odaorahome/oracle/product/19.0.0.0/dbhome_1 ORACLE_SID=INST3 ORACLE_HOME=/u01/app/odaorahome/oracle/product/19.0.0.0/dbhome_2 ORACLE_SID=INST4 ORACLE_HOME=/u01/app/odaorahome/oracle/product/19.0.0.0/dbhome_1 ORACLE_SID=INST5 ORACLE_HOME=/u01/app/odaorahome/oracle/product/19.0.0.0/dbhome_2 ORACLE_SID=INST6 ORACLE_HOME=/u01/app/odaorahome/oracle/product/19.0.0.0/dbhome_2 Channel definition for RMAN scripts: ALLOCATE CHANNEL VeeamAgentChannel1 DEVICE TYPE SBT_TAPE PARMS 'SBT_LIBRARY=/opt/veeam/VeeamPluginforOracleRMAN/libOracleRMANPlugin.so' FORMAT 'e718bc55-0c60-43bc-b1f7-f8cf2c793120/RMAN_%I_%d_%T_%U.vab'; Save configuration? 1. Apply configuration to the Oracle environment 2. Export configuration into a file for manual setup 3. Cancel without saving Enter: 1 *** Database instance INST1 is configured *** *** Database instance INST2 is configured *** *** Database instance INST3 is configured *** *** Database instance INST4 is configured *** *** Database instance INST5 is configured *** *** Database instance INST6 is configured ***
As root, we now need to run the following command to specify credentials to connect to the Veeam Backup Server, knowing current oracle linux user is restricted.
[root@ODA02 VeeamPluginforOracleRMAN]# pwd /opt/veeam/VeeamPluginforOracleRMAN [root@ODA02 VeeamPluginforOracleRMAN]# ./OracleRMANConfigTool --set-credentials 'oda_veeam' '***********' [root@ODA02 VeeamPluginforOracleRMAN]#RMAN configuration
We are using our own perl solution, named dmk (https://www.dbi-services.com/fr/produits/dmk-management-kit/), to perform the backup.
Following allocate channel had to be hard coded in our rcv scripts. We hard coded it as workaround for known bug to address through variable the % character:
ALLOCATE CHANNEL VeeamAgentChannel1 DEVICE TYPE SBT_TAPE PARMS 'SBT_LIBRARY=/opt/veeam/VeeamPluginforOracleRMAN/libOracleRMANPlugin.so' FORMAT 'e718bc55-0c60-43bc-b1f7-f8cf2c793120/RMAN_%I_%d_%T_%U.vab';
rcv example for inc0 backup:
oracle@ODA02:/u01/app/oracle/local/dmk_dbbackup/rcv/oracle12/ [rdbms1900] cat bck_inc0_no_arc_del_tape.rcv
#
# RMAN template: Online full database backup
#
# $Author: marc.wagner@dbi-services.com $
CONFIGURE ARCHIVELOG DELETION POLICY TO ;
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '_%F';
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '_snapcf_.f';
CONFIGURE BACKUP OPTIMIZATION ON;
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF DAYS;
show all;
run
{
#
ALLOCATE CHANNEL VeeamAgentChannel1 DEVICE TYPE SBT_TAPE PARMS 'SBT_LIBRARY=/opt/veeam/VeeamPluginforOracleRMAN/libOracleRMANPlugin.so' FORMAT 'e718bc55-0c60-43bc-b1f7-f8cf2c793120/RMAN_%I_%d_%T_%U.vab';
backup incremental level 0 section size filesperset database TAG 'INC0_';
backup filesperset archivelog all TAG 'ARCH_';
backup current controlfile TAG 'CTRL_';
sql "create pfile=''init_.ora'' from spfile";
RELEASE CHANNEL VeeamAgentChannel1;
}
Test
I could successfully test a backup on the Veeam tape and confirm with customer that the file was properly written on the server. We could also confirmed the same with RMAN.
oracle@ODA02:~/ [DB1 (CDB$ROOT)] /u01/app/oracle/local/dmk_ha/bin/check_primary.ksh DB1 "/u01/app/oracle/local/dmk_dbbackup/bin/dmk_rman.ksh -s DB1 -t bck_inc0_no_arc_del_tape.rcv -c /u01/app/odaorabase/oracle/admin/DB1_SITE1/etc/rman.cfg" 2025-02-04_11:12:48::check_primary.ksh::SetOraEnv ::INFO ==> Environment: DB1 (/u01/app/odaorahome/oracle/product/19.0.0.0/dbhome_2) 2025-02-04_11:12:48::check_primary.ksh::MainProgram ::INFO ==> Getting V$DATABASE.DB_ROLE for DB1 2025-02-04_11:12:48::check_primary.ksh::MainProgram ::INFO ==> DB1 Database Role is: PRIMARY 2025-02-04_11:12:48::check_primary.ksh::MainProgram ::INFO ==> Program going ahead and starting requested command 2025-02-04_11:12:48::check_primary.ksh::MainProgram ::INFO ==> Script : /u01/app/oracle/local/dmk_dbbackup/bin/dmk_rman.ksh -s DB1 -t bck_inc0_no_arc_del_tape.rcv -c /u01/app/odaorabase/oracle/admin/DB1_SITE1/etc/rman.cfg [OK]::customer::RMAN::dmk_dbbackup::DB1::bck_inc0_no_arc_del_tape.rcv::RMAN_retCode::0 Logfile is : /u01/app/odaorabase/oracle/admin/DB1_SITE1/log/DB1_bck_inc0_no_arc_del_tape_20250204_111249.log 2025-02-04_11:14:17::check_primary.ksh::CleanExit ::INFO ==> Program exited with ExitCode : 0To wrap up
Using Veeam RMAN plug-in on an ODA is working fine. I hope this article will help you configure it. In a next article I will test the backups restoring it in a new instance.
L’article Installing and configuring Veeam RMAN plug-in on an ODA est apparu en premier sur dbi Blog.
PostgreSQL 18: “swap” mode for pg_upgrade
When you want to upgrade from one major version of PostgreSQL to another you probably want to go with pg_upgrade (or logical replication). There are several modes of operations for this already:
- –copy: Copy the data files from the old to the new cluster
- –clone: Clone, instead of copying (when the file system supports it)
- –copy-file-range: Use the copy_file_range system call for efficient copying, if the file system supports it
- –link: Use hard links instead of copying files
What is best for you, depends on the requirements. We usually go with “–link” as this is pretty fast, but you can only do that if the old and the new cluster are in the same file system. The downside is, that you cannot anymore use the old cluster once the new cluster is started up.
With PostgreSQL 18 there will probably a new option called “–swap”. This mode, instead of linking or copying the files, moves the files from the old to the new cluster and then replaces the catalog files with the ones from the new cluster. The reason for this additional mode (see the link to the commit at the end of this post) is, that this might outperform even “–link” mode (and the others) when a cluster contains many relations.
Let’s see if we can prove this by creating two new PostgreSQL 17 clusters with many relations:
postgres@pgbox:/home/postgres/ [172] initdb --version
initdb (PostgreSQL) 17.2
postgres@pgbox:/home/postgres/ [172] initdb -D /var/tmp/dummy/17.2_1 --data-checksums
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
...
Success. You can now start the database server using:
pg_ctl -D /var/tmp/17.2 -l logfile start
postgres@pgbox:/home/postgres/ [172] echo "port=8888" >> /var/tmp/dummy/17.2_1/postgresql.auto.conf
postgres@pgbox:/home/postgres/ [172] pg_ctl --pgdata=/var/tmp/dummy/17.2_1 start -l /dev/null
waiting for server to start.... done
server started
postgres@pgbox:/home/postgres/ [172] psql -p 8888 -l
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | Locale | ICU Rules | Access privileges
-----------+----------+----------+-----------------+-------------+-------------+--------+-----------+-----------------------
postgres | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 | | |
template0 | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | en_US.UTF-8 | en_US.UTF-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
(3 rows)
Here is a little script that creates some tables, indexes and a bit of data:
#!/bin/bash
for i in {1..10000}; do
psql -p 8888 -c "create table t${i} ( a int, b text )"
psql -p 8888 -c "insert into t${i} select i, i::text from generate_series(1,1000) i;"
psql -p 8888 -c "create index i${i} on t${i}(a);"
done
If we run that against the cluster we’ll have 10’000 tables (each containing 1000 rows) and 10’000 indexes. This should be sufficient “many relations” to do a quick test.
We create the second cluster by copying the first one:
postgres@pgbox:/home/postgres/ [172] mkdir /var/tmp/dummy/17.2_2/
postgres@pgbox:/home/postgres/ [172] pg_basebackup --port=8888 --pgdata=/var/tmp/dummy/17.2_2/ --checkpoint=fast
postgres@pgbox:/home/postgres/ [172] sed -i 's/8888/8889/g' /var/tmp/dummy/17.2_2/postgresql.auto.conf
Now, lets create two PostgreSQL 18 clusters we will be upgrading to. One of them we will upgrade with “–link” mode, the other with the new “–swap” mode (we’ll also stop the old cluster):
postgres@pgbox:/home/postgres/ [pgdev] initdb --version
initdb (PostgreSQL) 18devel
postgres@pgbox:/home/postgres/ [pgdev] initdb --pgdata=/var/tmp/dummy/18link
postgres@pgbox:/home/postgres/ [pgdev] initdb --pgdata=/var/tmp/dummy/18swap
postgres@pgbox:/home/postgres/ [pgdev] echo "port=9000" >> /var/tmp/dummy/18link/postgresql.auto.conf
postgres@pgbox:/home/postgres/ [pgdev] echo "port=9001" >> /var/tmp/dummy/18swap/postgresql.auto.conf
postgres@pgbox:/home/postgres/ [pgdev] pg_ctl --pgdata=/var/tmp/dummy/17.2_1/ stop
A quick check if all seems to be fine for the first upgrade:
postgres@pgbox:/home/postgres/ [pgdev] pg_upgrade --version
pg_upgrade (PostgreSQL) 18devel
postgres@pgbox:/home/postgres/ [pgdev] export PGDATAOLD=/var/tmp/dummy/17.2_1/
postgres@pgbox:/home/postgres/ [pgdev] export PGDATANEW=/var/tmp/dummy/18link/
postgres@pgbox:/home/postgres/ [pgdev] export PGBINOLD=/u01/app/postgres/product/17/db_2/bin
postgres@pgbox:/home/postgres/ [pgdev] export PGBINNEW=/u01/app/postgres/product/DEV/db_0/bin/
postgres@pgbox:/home/postgres/ [pgdev] pg_upgrade --check
Performing Consistency Checks
-----------------------------
Checking cluster versions ok
Checking database connection settings ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for contrib/isn with bigint-passing mismatch ok
Checking for valid logical replication slots ok
Checking for subscription state ok
Checking data type usage ok
Checking for presence of required libraries ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for new cluster tablespace directories ok
*Clusters are compatible*
Time for a test using the “–link” mode:
postgres@pgbox:/home/postgres/ [pgdev] time pg_upgrade --link
Performing Consistency Checks
-----------------------------
Checking cluster versions ok
Checking database connection settings ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for contrib/isn with bigint-passing mismatch ok
Checking for valid logical replication slots ok
Checking for subscription state ok
Checking data type usage ok
Creating dump of global objects ok
Creating dump of database schemas
ok
Checking for presence of required libraries ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for new cluster tablespace directories ok
If pg_upgrade fails after this point, you must re-initdb the
new cluster before continuing.
Performing Upgrade
------------------
Setting locale and encoding for new cluster ok
Analyzing all rows in the new cluster ok
Freezing all rows in the new cluster ok
Deleting files from new pg_xact ok
Copying old pg_xact to new server ok
Setting oldest XID for new cluster ok
Setting next transaction ID and epoch for new cluster ok
Deleting files from new pg_multixact/offsets ok
Copying old pg_multixact/offsets to new server ok
Deleting files from new pg_multixact/members ok
Copying old pg_multixact/members to new server ok
Setting next multixact ID and offset for new cluster ok
Resetting WAL archives ok
Setting frozenxid and minmxid counters in new cluster ok
Restoring global objects in the new cluster ok
Restoring database schemas in the new cluster
ok
Adding ".old" suffix to old global/pg_control ok
If you want to start the old cluster, you will need to remove
the ".old" suffix from /var/tmp/dummy/17.2_1/global/pg_control.old.
Because "link" mode was used, the old cluster cannot be safely
started once the new cluster has been started.
Linking user relation files
ok
Setting next OID for new cluster ok
Sync data directory to disk ok
Creating script to delete old cluster ok
Checking for extension updates ok
Upgrade Complete
----------------
Some optimizer statistics may not have been transferred by pg_upgrade.
Once you start the new server, consider running:
/u01/app/postgres/product/DEV/db_0/bin/vacuumdb --all --analyze-in-stages --missing-stats-only
Running this script will delete the old cluster's data files:
./delete_old_cluster.sh
real 0m13.776s
user 0m0.654s
sys 0m1.536s
Let’s do the same test with the new “swap” mode:
postgres@pgbox:/home/postgres/ [pgdev] export PGDATAOLD=/var/tmp/dummy/17.2_2/
postgres@pgbox:/home/postgres/ [pgdev] export PGDATANEW=/var/tmp/dummy/18swap/
postgres@pgbox:/home/postgres/ [pgdev] export PGBINOLD=/u01/app/postgres/product/17/db_2/bin
postgres@pgbox:/home/postgres/ [pgdev] export PGBINNEW=/u01/app/postgres/product/DEV/db_0/
postgres@pgbox:/home/postgres/ [pgdev] pg_upgrade --check
Performing Consistency Checks
-----------------------------
Checking cluster versions ok
Checking database connection settings ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for contrib/isn with bigint-passing mismatch ok
Checking for valid logical replication slots ok
Checking for subscription state ok
Checking data type usage ok
Checking for presence of required libraries ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for new cluster tablespace directories ok
*Clusters are compatible*
postgres@pgbox:/home/postgres/ [pgdev] time pg_upgrade --swap
Performing Consistency Checks
-----------------------------
Checking cluster versions ok
Checking database connection settings ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for contrib/isn with bigint-passing mismatch ok
Checking for valid logical replication slots ok
Checking for subscription state ok
Checking data type usage ok
Creating dump of global objects ok
Creating dump of database schemas
ok
Checking for presence of required libraries ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for new cluster tablespace directories ok
If pg_upgrade fails after this point, you must re-initdb the
new cluster before continuing.
Performing Upgrade
------------------
Setting locale and encoding for new cluster ok
Analyzing all rows in the new cluster ok
Freezing all rows in the new cluster ok
Deleting files from new pg_xact ok
Copying old pg_xact to new server ok
Setting oldest XID for new cluster ok
Setting next transaction ID and epoch for new cluster ok
Deleting files from new pg_multixact/offsets ok
Copying old pg_multixact/offsets to new server ok
Deleting files from new pg_multixact/members ok
Copying old pg_multixact/members to new server ok
Setting next multixact ID and offset for new cluster ok
Resetting WAL archives ok
Setting frozenxid and minmxid counters in new cluster ok
Restoring global objects in the new cluster ok
Restoring database schemas in the new cluster
ok
Adding ".old" suffix to old global/pg_control ok
Because "swap" mode was used, the old cluster can no longer be
safely started.
Swapping data directories
ok
Setting next OID for new cluster ok
Sync data directory to disk ok
Creating script to delete old cluster ok
Checking for extension updates ok
Upgrade Complete
----------------
Some optimizer statistics may not have been transferred by pg_upgrade.
Once you start the new server, consider running:
/u01/app/postgres/product/DEV/db_0/bin/vacuumdb --all --analyze-in-stages --missing-stats-only
Running this script will delete the old cluster's data files:
./delete_old_cluster.sh
real 0m11.426s
user 0m0.600s
sys 0m0.659s
This was around 2 seconds faster, not much, but at least faster. Of course this was a very simple test case and this further needs to be tested further. Please also note the warning in the output:
Because "swap" mode was used, the old cluster can no longer be
safely started.
Swapping data directories
This is a consequence of using this mode. Thanks to all involved, details here.
L’article PostgreSQL 18: “swap” mode for pg_upgrade est apparu en premier sur dbi Blog.
PostgreSQL 18: Add “–missing-stats-only” to vacuumdb
Loosing all the object statistics after a major version upgrade of PostgreSQL with pg_upgrade is one of the real paint points in PostgreSQL. Collecting/generating the statistics can take much longer than the actual upgrade which is quite painful. A first the to resolve this was already committed for PostgreSQL 18 and I’ve written about this here. Yesterday, another bit was committed in this area, and this time it is vacuumdb which got a new switch.
Before we can take a look at this we need an object without any statistics and an object which already has statistics::
postgres=# create table t ( a int, b text );
CREATE TABLE
postgres=# create table tt ( a int, b text );
CREATE TABLE
postgres=# insert into t select i, 'aaa' from generate_series(1,10) i;
INSERT 0 100
postgres=# insert into tt select i, 'aaa' from generate_series(1,1000000) i;
INSERT 0 1000000
The first insert will not trigger statistics collection, while second insert will trigger it:
postgres=# select relname, last_autoanalyze from pg_stat_all_tables where relname in ('t','tt');
relname | last_autoanalyze
---------+-------------------------------
tt | 2025-03-20 10:18:03.745504+01
t |
(2 rows)
What the new switch for vacuumdb is providing, is to only collect statistics on objects which do not have any:
postgres@pgbox:/home/postgres/ [pgdev] vacuumdb --help | grep missing
--missing-stats-only only analyze relations with missing statistics
Using that, we should see fresh statistics on the first table, but not on the second one:
postgres@pgbox:/home/postgres/ [pgdev] vacuumdb --analyze-only --missing-stats-only postgres
vacuumdb: vacuuming database "postgres"
postgres@pgbox:/home/postgres/ [pgdev] psql -c "select relname, last_analyze from pg_stat_all_tables where relname in ('t','tt');"
relname | last_analyze
---------+------------------------------
tt |
t | 2025-03-20 10:24:36.88391+01
(2 rows)
Nice. All the details here and, as usual, thanks to everybody involved in this.
L’article PostgreSQL 18: Add “–missing-stats-only” to vacuumdb est apparu en premier sur dbi Blog.
Do you know Aino?
Nowadays, working in a company requires handling of huge amounts of information, and therefore efficiency is crucial!
M-Files Aino, your virtual assistant integrated in M-Files, is here to support you in your daily activities.
M-Files Aino leverages natural language processing to help users interact seamlessly with their organization’s knowledge base.
It can summarize documents, translate these summaries, answer questions, and save information as M-Files metadata.
This automation not only makes knowledge more accessible but also assists the users to better organize and classify new documents.
Aino brings many features to enterprise content management systems, in each new release new capabilities appear, but the main ones (currently) are:
- AI-Powered Summaries: Generate intelligent document summaries for quicker comprehension and review.
- Streamlined Information Discovery: Locate essential information rapidly, reducing data clutter.
- Language-Independent Queries: Interact with document content in any language, fostering global collaboration.
- Automated Task Processing: Automate manual tasks, freeing up time for strategic work.
- Secure Data Handling: Ensure data security, those are only processed by M-Files Aino in the M-Files Cloud, nothing is spread across other tools.
Advantages are obvious but here are some important points:
- Enhanced Productivity: By automating routine tasks, employees can focus on more strategic activities, leading to increased efficiency.
- Improved Accuracy: AI-driven processes reduce the likelihood of human errors in document handling and data entry.
- Global Collaboration: With multilingual support, teams across different regions can collaborate seamlessly.
- Informed Decision-Making: Quick access to summarized information and AI-generated insights aids in making timely and informed decisions.
OK, AI is cool and trendy, but does it really add anything? The answer is yes. We deal with more and more documents and retrieving the right information is always more challenging.
I’ve listed three very concrete scenarios where AI saves time for people who have little or no time:
- In Law firms can quickly summarize big legal documents, making it easier to extract pertinent information.
- Medical professionals can swiftly access patient information and research data, enhancing patient care.
- Financial analysts can efficiently process large volumes of financial reports and market analyses.
AI technology continues to evolve, M-Files Aino too, as written above, each version adds new interesting things, the way we manage and work with documents changes.
We are still at the premises of the awesome capabilities offered by this technology, which is revolutionizing the world of ECM.
If you want to see a small Aino introduction, it’s here.
And as usual for any question feel free to contact us.
L’article Do you know Aino? est apparu en premier sur dbi Blog.
PRGH-1030 when doing restore-node -g on ODA
Patching your Oracle Database Appliance from 19.20 or earlier release to 19.21 or newer release implies the use of Data Preserving Reprovisioning (DPR). Most of the time, and with an adequate preparation, the DPR works fine. But if something goes wrong at the restore-node -g step, you will need some troubleshooting and maybe opening a SR. There is no possible rollback. Here is the problem I recently had when patching an ODA from 19.20 to 19.26 using the intermediate 19.24 for DPR.
What is DPR and why you need it on ODA?Oracle Database Appliance has a global quarterly patch: this is the only patch you are supposed to use on this kind of hardware. The patch includes updates for Grid Infrastructure (GI) and database (DB), but also updates for the operating system (OS), BIOS, firmwares and other software components. Regarding the OS, Linux 7 was in use up to 19.20 version. Starting from 19.21, Linux 8 is mandatory and there is no update-server command available: you will need to reinstall the new OS on your ODA using DPR.
Basically, DPR is a complete reinstall of the OS without erasing the data disks. Before doing the reinstall, you will “detach” the node. After the reinstall, you will “restore” the node using an odacli command: restore-node -g. You can compare this to the unplug/plug operations on a PDB. Unplugging a PDB is writing the metadata in a file you will later use to plug in back your PDB somewhere else. The DPR feature is embedded in patch 19.21, 19.22, 19.23 and 19.24. As patches are only cumulative with the 4 previous versions, starting from 19.25 you’re supposed to use release 19.21 at least, meaning already in Linux 8.
My ODA setup: a real client environmentMy client has 2x ODA X9-2S with Enterprise Edition and Data Guard for production databases. These ODAs were deployed 2 years ago, and already patched from 19.17 to 19.20 1 year ago. Now, it’s time to patch them to the latest 19.26, using DPR 19.24 for the Linux 8 jump.
Pre-upgrade report and detach-nodeDCS components are updated to 19.24 at first step, then the pre-upgrade report can be tried:
odacli update-dcsadmin -v 19.24.0.0.0
odacli update-dcscomponents -v 19.24.0.0.0
odacli update-dcsagent -v 19.24.0.0.0
odacli create-preupgradereport -bm
odacli describe-preupgradereport -i 03f53c9c-fe82-4c2b-bf18-49fd31853054
...
This pre-upgrade report MUST be successful: if not, solve the listed problems and retry until it’s OK.
Once OK, the detach-node will backup the metadata of your ODA for later restore:
odacli detach-node -all
As detach files are stored locally, make sure to backup these files on an external volume otherwise you will not be able to restore your data after reimaging.
cp -r /opt/oracle/oak/restore/out/* /mnt/backup/ODA_backup/
Reimaging is done with patch 30403643 (version 19.24 in my case). This is an ISO file you will virtually plug in through ILOM as a virtual CDROM. Then you will reboot the server and automatic setup will start. After this reimaging, you will need to do a configure-firstnet for basic network configuration, and then register the new GI and the detached server archive:
odacli update-repository -f /mnt/backup/ODA_backup/odacli-dcs-19.24.0.0.0-240724-GI-19.24.0.0.zip
odacli update-repository -f /mnt/backup/ODA_backup/serverarchive_srvoda1.zipOnce both files have successfully been registered, the restore-node can be done:
odacli restore-node -g
The restore-node -g is similar to a create-appliance: it will configure the system, create the users, provision GI and configure ASM. Instead of configuring ASM with fresh disks without any data, it will read the ASM headers on disks and mount the existing diskgroups. It means that you will get back the DB homes, the databases and ACFS volumes.
This time, the restore-node -g didn’t work for me, it took a very long time (more than one hour) before ending with a failure, a timeout was probably triggered as odacli jobs always finish with a success or a failure:
odacli describe-job -i "46addc5f-7a1f-4f4b-bccf-78cb3708bef9"
Job details
----------------------------------------------------------------
ID: 46addc5f-7a1f-4f4b-bccf-78cb3708bef9
Description: Restore node service - GI
Status: Failure (To view Error Correlation report, run "odacli describe-job -i 46addc5f-7a1f-4f4b-bccf-78cb3708bef9 --ecr" command)
Created: March 5, 2025 9:03:44 AM CET
Message: DCS-10001:Internal error encountered: Failed to provision GI with RHP at the home: /u01/app/19.24.0.0/grid: DCS-10001:Internal error encountered: PRGH-1030 : The environments on nodes 'srvoda1' do not satisfy some of the prerequisite checks.
..
Task Name Start Time End Time Status
---------------------------------------- ---------------------------------------- ---------------------------------------- ---------
Restore node service creation March 5, 2025 9:04:01 AM CET March 5, 2025 10:17:35 AM CET Failure
Restore node service creation March 5, 2025 9:04:01 AM CET March 5, 2025 10:17:35 AM CET Failure
Restore node service creation March 5, 2025 9:04:01 AM CET March 5, 2025 10:17:35 AM CET Failure
Provisioning service creation March 5, 2025 9:04:01 AM CET March 5, 2025 10:17:35 AM CET Failure
Provisioning service creation March 5, 2025 9:04:01 AM CET March 5, 2025 10:17:35 AM CET Failure
Validate absence of Interconnect March 5, 2025 9:04:01 AM CET March 5, 2025 9:04:02 AM CET Success
network configuration file
Setting up Network March 5, 2025 9:04:03 AM CET March 5, 2025 9:04:03 AM CET Success
Restart network interface pubnet March 5, 2025 9:04:03 AM CET March 5, 2025 9:04:09 AM CET Success
Setting up Vlan March 5, 2025 9:04:09 AM CET March 5, 2025 9:04:10 AM CET Success
Restart network interface priv0.100 March 5, 2025 9:04:10 AM CET March 5, 2025 9:04:11 AM CET Success
Restart network interface privasm March 5, 2025 9:04:11 AM CET March 5, 2025 9:04:11 AM CET Success
Setting up Network March 5, 2025 9:04:11 AM CET March 5, 2025 9:04:11 AM CET Success
Restart network interface privasm March 5, 2025 9:04:11 AM CET March 5, 2025 9:04:17 AM CET Success
Network update March 5, 2025 9:04:17 AM CET March 5, 2025 9:04:30 AM CET Success
Updating network March 5, 2025 9:04:17 AM CET March 5, 2025 9:04:30 AM CET Success
Setting up Network March 5, 2025 9:04:17 AM CET March 5, 2025 9:04:17 AM CET Success
Restart network interface btbond1 March 5, 2025 9:04:17 AM CET March 5, 2025 9:04:20 AM CET Success
Restart network interface btbond1 March 5, 2025 9:04:20 AM CET March 5, 2025 9:04:24 AM CET Success
Restart network interface pubnet March 5, 2025 9:04:24 AM CET March 5, 2025 9:04:29 AM CET Success
Validate availability of pubnet March 5, 2025 9:04:30 AM CET March 5, 2025 9:04:30 AM CET Success
OS usergroup 'asmdba' creation March 5, 2025 9:04:30 AM CET March 5, 2025 9:04:30 AM CET Success
OS usergroup 'asmoper' creation March 5, 2025 9:04:30 AM CET March 5, 2025 9:04:30 AM CET Success
OS usergroup 'asmadmin' creation March 5, 2025 9:04:30 AM CET March 5, 2025 9:04:30 AM CET Success
OS usergroup 'dba' creation March 5, 2025 9:04:30 AM CET March 5, 2025 9:04:30 AM CET Success
OS usergroup 'dbaoper' creation March 5, 2025 9:04:30 AM CET March 5, 2025 9:04:30 AM CET Success
OS usergroup 'oinstall' creation March 5, 2025 9:04:30 AM CET March 5, 2025 9:04:31 AM CET Success
OS user 'grid' creation March 5, 2025 9:04:31 AM CET March 5, 2025 9:04:31 AM CET Success
OS user 'oracle' creation March 5, 2025 9:04:31 AM CET March 5, 2025 9:04:31 AM CET Success
Default backup policy creation March 5, 2025 9:04:31 AM CET March 5, 2025 9:04:31 AM CET Success
Backup Config name validation March 5, 2025 9:04:31 AM CET March 5, 2025 9:04:31 AM CET Success
Backup config metadata persist March 5, 2025 9:04:31 AM CET March 5, 2025 9:04:31 AM CET Success
Grant permission to RHP files March 5, 2025 9:04:31 AM CET March 5, 2025 9:04:31 AM CET Success
Add SYSNAME in Env March 5, 2025 9:04:32 AM CET March 5, 2025 9:04:32 AM CET Success
Install oracle-ahf March 5, 2025 9:04:32 AM CET March 5, 2025 9:06:13 AM CET Success
Stop DCS Admin March 5, 2025 9:06:16 AM CET March 5, 2025 9:06:16 AM CET Success
Generate mTLS certificates March 5, 2025 9:06:16 AM CET March 5, 2025 9:06:17 AM CET Success
Exporting Public Keys March 5, 2025 9:06:17 AM CET March 5, 2025 9:06:18 AM CET Success
Creating Trust Store March 5, 2025 9:06:18 AM CET March 5, 2025 9:06:22 AM CET Success
Update config files March 5, 2025 9:06:22 AM CET March 5, 2025 9:06:22 AM CET Success
Restart DCS Admin March 5, 2025 9:06:22 AM CET March 5, 2025 9:06:43 AM CET Success
Unzipping storage configuration files March 5, 2025 9:06:43 AM CET March 5, 2025 9:06:43 AM CET Success
Reloading multipath devices March 5, 2025 9:06:43 AM CET March 5, 2025 9:06:44 AM CET Success
Restart oakd March 5, 2025 9:06:44 AM CET March 5, 2025 9:06:55 AM CET Success
Restart oakd March 5, 2025 9:08:05 AM CET March 5, 2025 9:08:15 AM CET Success
Restore Quorum Disks March 5, 2025 9:08:15 AM CET March 5, 2025 9:08:16 AM CET Success
Creating GI home directories March 5, 2025 9:08:16 AM CET March 5, 2025 9:08:16 AM CET Success
Extract GI clone March 5, 2025 9:08:16 AM CET March 5, 2025 9:09:29 AM CET Success
Creating wallet for Root User March 5, 2025 9:09:29 AM CET March 5, 2025 9:09:33 AM CET Success
Creating wallet for ASM Client March 5, 2025 9:09:33 AM CET March 5, 2025 9:09:39 AM CET Success
Grid stack creation March 5, 2025 9:09:39 AM CET March 5, 2025 10:17:35 AM CET Failure
GI Restore with RHP March 5, 2025 9:09:39 AM CET March 5, 2025 10:17:35 AM CET FailureAccording to the error message, my system doesn’t satisfy the prerequisites checks.
Let’s check if error correlation may help:
odacli describe-job -i 46addc5f-7a1f-4f4b-bccf-78cb3708bef9 --ecr
ODA Assistant - Error Correlation report
----------------------------------------
Failed job ID: 46addc5f-7a1f-4f4b-bccf-78cb3708bef9
Description: Restore node service - GI
Start Time: 2025-03-05 09:04:01
End Time: 2025-03-05 10:17:35
EC report path: /opt/oracle/dcs/da/da_repo/46addc5f-7a1f-4f4b-bccf-78cb3708bef9.json
Failed Task Messages
--------------------
[Restore node service - GI] - DCS-10001:Internal error encountered: Failed to provision GI with RHP at the home: /u01/app/19.24.0.0/grid: DCS-10001:Internal error encountered: PRGH-1030 : The environments on nodes 'srvoda1' do not satisfy some of the prerequisite checks. ..
srvoda1 Log Messages
----------------------------
DCS Agent
~~~~~~~~~
Error Logs
==========
[Install oracle-ahf] - Trying to add string [ERROR] : Unable to switch to home directory
[Install oracle-ahf] - error is package tfa-oda is not installed
[GI Restore with RHP] - Calling rhp provGI
[GI Restore with RHP] - Task(id: TaskDcsJsonRpcExt_707, name: GI Restore with RHP) failed
[GI Restore with RHP] - .. d.subtasks.isempty=true d.status=Failure
[Grid stack creation] - ..
[Grid stack creation] - .. d.subtasks.isempty=false d.status=Failure
[Grid stack creation] - DCS-10001:Internal error encountered: PRGH-1030 : The environments on nodes 'srvoda1' do not satisfy some of the prerequisite checks.
Error code - DCS-10001
Cause: An internal error occurred.
Action: Contact Oracle Support for assistance.
[Grid stack creation] - .., output:
Warning Logs
============
[[ SEND-THREAD 77 ]] - [ [ SEND-THREAD 77 ] dcs0-priv:22001] Request failed: Operation: GET Host: dcs0-priv:22001 Path: /joblocks/46addc5f-7a1f-4f4b-bccf-78cb3708bef9 Data: null Status: 404
[Provisioning service creation] - dm_multipath module is not loaded, attempting to load it...
RHP
~~~
Error Logs
==========
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - [SiteFactoryImpl.fetchSite:136] EntityNotExistsException PRGR-110 : Repository object "SRVODA1" of type "SITE" does not exist.
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - [WorkingCopyOperationImpl.internalAddGI:18517] Expected: Site does not exist, will have to be created :PRGR-119 : Site "srvoda1" does not exist.
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - [RemoteFactoryImpl.getCRSHomeOfRemoteCluster:1377] COException: PRCZ-4001 : failed to execute command "/bin/cat" using the privileged execution plugin "odaexec" on nodes "srvoda1" within 120 seconds
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - PRCZ-2103 : Failed to execute command "/bin/cat" on node "srvoda1" as user "root". Detailed error:
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - /bin/cat: /etc/oracle/olr.loc: No such file or directory
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - [WorkingCopyOperationImpl.internalAddGI:18972] Exec Exception, expected here :PRGR-118 : Working copy "OraGrid192400" does not exist.
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - [OracleHomeImpl.addWCMarkerFile:4403] Ignore the exception to create RHP WC marker file : PRKH-1009 : CRS HOME must be defined in the environment or in the Oracle Cluster Registry
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - [ExecCommandNoUserEqImpl.runCmd:491] Final CompositeOperation exception: PRCC-1021 : One or more of the submitted commands did not execute successfully.
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - PRCC-1026 : Command "/u01/app/19.24.0.0/grid/gridSetup.sh -silent -responseFile /u01/app/19.24.0.0/grid//crs/install/rhpdata/grid7317919467403765800.rsp -ignorePrereq -J-Dskip.cvu.root.checks=true -J-Doracle.install.grid.validate.all=false oracle_install_crs_ODA_CONFIG=olite oracle_install_crs_ConfigureMgmtDB=false -J-Doracle.install.crs.skipGIMRDiskGroupSizeCheck=true oracle_install_asm_UseExistingDG=true -J-Doracle.install.grid.validate.CreateASMDiskGroup=false" submitted on node srvoda1 timed out after 4,000 seconds.
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - </OUTPUT>
[jobid-46addc5f-7a1f-4f4b-bccf-78cb3708bef9] - [OperationAPIImpl.provGI:676] OperationAPIException: PRGH-1030 : The environments on nodes 'srvoda1' do not satisfy some of the prerequisite checks.
Release Notes
-------------
No matching results were found.
Documentation
-------------
1. Error in restore node process in Data Preserving Reprovisioning
Abstract - In the Data Preserving Reprovisioning process, during node restore, an error may be encountered.
Link - https://srvoda1.dbi-services.net:7093/docs/cmtrn/issues-with-oda-odacli.html#GUID-F1385628-9F87-4FEF-8D27-289A3ED459EC
2. Error in restore node process in Data Preserving Reprovisioning
Abstract - In the Data Preserving Reprovisioning process, during node restore, an error may be encountered.
Link - https://srvoda1.dbi-services.net:7093/docs/cmtrn/issues-with-oda-odacli.html#GUID-75D52887-D425-4753-AF44-EFAB5C148873
3. Managing Backup, Restore, and Recovery on a DB System in a KVM Deployment
Abstract - Understand the backup, restore, and recovery operations supported on a DB system in a KVM deployment.
Link - https://srvoda1.dbi-services.net:7093/docs/cmtxp/managing-oracle-database-appliance-kvm-deployment1.html#GUID-7318F4D7-4CB8-486C-9DC7-A7490925B866
4. Backup, Restore and Recover Databases
Abstract - Review backup, restore, and recovery operations for your databases.
Link - https://srvoda1.dbi-services.net:7093/docs/cmtxp/backup-recover-restore.html#GUID-032C43EC-20B9-4036-ADA9-7631EEBBFEF6
5. Using the CLI to Backup, Restore, and Recover
Abstract - Use the command-line interface to backup, restore, and recover databases.
Link - https://srvoda1.dbi-services.net:7093/docs/cmtxp/backup-recover-restore.html#GUID-54F9A4A6-59B8-4A18-BE41-1CCB9096E2C5
NOTE: For additional details such as file name and line numbers of error logs, please refer to /opt/oracle/dcs/da/da_repo/924d139e-50cc-4893-ab0a-6acb7e7eeb9c.json
There is a lot of errors, but hard to find what is the source problem.
Let’s have a look at the logfile of the GI setup:
vi /u01/app/oraInventory/logs/GridSetupActions2025-03-05_09-09-40AM/gridSetupActions2025-03-05_09-09-40AM.out
…
Resolution failed, cached value is left untouched for variable
…
No ECDSA host key is known for srvoda1 and you have requested strict checking
…Could it be a DNS issue? Regarding the network settings, I’m pretty sure that IP, netmask and gateway are OK.
Identify and solve the problem by editing the json fileLike the create-appliance, the restore-node -g will use a json file restored previously with the update-repository of the server archive.
Let’s compare my own backup files and the json file used by restore-node -g:
cat /mnt/backup/ODA_backup/backup_ODA_srvoda1_20250312_0820/resolv.conf
search dbi-services.net
nameserver 10.1.2.127
nameserver 10.1.2.128
cat /opt/oracle/oak/restore/metadata/provisionInstance.json | grep dns
"dnsServers" : [ "10.4.110.4", "10.4.110.5" ],OK, DNS servers have been changed manually in the resolv.conf. They are no more correct in the json file.
As the restore-node -g failed, a cleanup of the system is mandatory:
/opt/oracle/oak/onecmd/cleanup.pl
INFO: Log file is /opt/oracle/oak/log/srvoda1/cleanup/cleanup_2025-03-05_10-40-06.log
INFO: Log file is /opt/oracle/oak/log/srvoda1/cleanup/dcsemu_diag_precleanup_2025-03-05_10-40-06.log
INFO: Platform is 'BM'
INFO: *******************************************************************
INFO: ** Starting process to cleanup provisioned host srvoda1 **
INFO: *******************************************************************
WARNING: DPR environment detected. DPR specific cleanup involves
WARNING: deconfiguring the ODA software stack without touching ASM
WARNING: storage to allow rerunning of the 'odacli restore-node -g'
WARNING: command. If regular cleanup(which erases ASM disk headers)
WARNING: is intended, rerun cleanup.pl with '-nodpr' option.
WARNING: If Multi-User Access is enabled, use '-omausers' option to
WARNING: delete the custom users created during the previous run.
Do you want to continue (yes/no) : yes
INFO:
Running cleanup will delete Grid User - 'grid' and
INFO: DB user - 'oracle' and also the
INFO: groups 'oinstall,dba,asmadmin,asmoper,asmdba'
INFO: nodes will be rebooted
Do you want to continue (yes/no) : yes
INFO: /u01/app/19.24.0.0/grid/bin/crsctl.bin
INFO: *************************************
INFO: ** Checking for GI bits presence
INFO: *************************************
INFO: GI bits /u01/app/19.24.0.0/grid found on system under /u01/app directory...
INFO: *************************************
INFO: ** DPR Cleanup
INFO: *************************************
INFO: Nothing to do.
SUCCESS: DPR cleanup actions completed.
INFO: Attempting to stop DCS agent on local node
INFO: *************************************
INFO: ** Executing AFD cleanup commands
INFO: *************************************
INFO: *************************************
INFO: ** Cleaning Oracle HAMI for ODA
INFO: *************************************
INFO: ** - Oracle HAMI for ODA - ensembles cleaned successfully
INFO: ** - Oracle HAMI for ODA - users cleaned successfully
INFO: *************************************
INFO: ** Executing stack deinstall commands
INFO: *************************************
INFO: *************************************
INFO: ** Removing IPC objects
INFO: *************************************
INFO: Cleaning up IDM configurations...
Deleting directory </opt/oracle/dcs/idm>INFO: *************************************
INFO: ** Cleaning miscellaneous components:
INFO: *************************************
INFO: ** - reset limits.conf
INFO: ** - delete users
INFO: ** - delete groups
INFO: ** - hostname, gateway and hosts reset commands
INFO: ** - dcs cleanup and orphan files removal commands
INFO: Attempting to clean MySQL tables on local node
INFO: Cleaning up network bridges
INFO: default net is: pubnet
INFO: Cleaning up network bridges: pubnet on btbond1
INFO: Reset public interface: pubnet
INFO: Cleaning up network bridges: privasm on priv0.100
INFO: remove VLAN config: /etc/sysconfig/network-scripts/ifcfg-priv0.100
INFO: BaseDBCC cleanup - skip
INFO: *************************************
INFO: ** Removing KVM files
INFO: *************************************
INFO: *************************************
INFO: ** Removing BM CPU Pool files
INFO: *************************************
INFO: ** - networking cleaning commands
INFO: ** - UTC reset commands
INFO: *************************************
INFO: ** Removing Oracle AHF RPM
INFO: *************************************
INFO: Oracle AHF RPM is installed as : oracle-ahf-2405000-20240715121646.x86_64
INFO: Uninstalling Oracle AHF RPM
INFO: Oracle AHF RPM uninstalled successfully
INFO: Oracle AHF RPM is installed as : oracle-ahf-2405000-20240715121646.x86_64
INFO: Delete directory clones.local (if existing)...
INFO: Cleaning up ACFS mounts...
INFO: Reset password for 'root' to default value
INFO: Executing <command to reset root password to default value>
INFO: Removing SSH keys on srvoda1
INFO: Rebooting the system via <reboot>...
INFO: Executing <reboot>
INFO: Cleanup was successful
INFO: Log file is /opt/oracle/oak/log/srvoda1/cleanup/cleanup_2025-03-05_10-40-06.log
WARNING: After system reboot, please re-run "odacli update-repository" for GI/DB clones,
WARNING: before running "odacli restore-node -g".
Once the server has rebooted, let’s register again the GI and server archive files:
odacli update-repository -f /mnt/backup/ODA_backup/odacli-dcs-19.24.0.0.0-240724-GI-19.24.0.0.zip
odacli update-repository -f /mnt/backup/ODA_backup/serverarchive_srvoda1.zipLet’s change the DNS in the provisionInstance.json and do the restore-node -g:
sed -i 's/10.4.110.4/10.1.2.127/g' /opt/oracle/oak/restore/metadata/provisionInstance.json
sed -i 's/10.4.110.5/10.1.2.128/g' /opt/oracle/oak/restore/metadata/provisionInstance.json
cat /opt/oracle/oak/restore/metadata/provisionInstance.json | grep dns
"dnsServers" : [ "10.1.2.127", "10.1.2.128" ],
odacli restore-node -g
...
odacli describe-job -i "f2e14691-1fc4-4b8d-9186-cbb55a69c5dd"
Job details
----------------------------------------------------------------
ID: f2e14691-1fc4-4b8d-9186-cbb55a69c5dd
Description: Restore node service - GI
Status: Success
Created: March 5, 2025 5:33:33 PM CET
Message:
Task Name Start Time End Time Status
---------------------------------------- ---------------------------------------- ---------------------------------------- ---------
Restore node service creation March 5, 2025 5:33:40 PM CET March 5, 2025 5:53:33 PM CET Success
Validate absence of Interconnect March 5, 2025 5:33:40 PM CET March 5, 2025 5:33:41 PM CET Success
network configuration file
Setting up Network March 5, 2025 5:33:42 PM CET March 5, 2025 5:33:42 PM CET Success
Restart network interface pubnet March 5, 2025 5:33:42 PM CET March 5, 2025 5:33:48 PM CET Success
Setting up Vlan March 5, 2025 5:33:48 PM CET March 5, 2025 5:33:49 PM CET Success
Restart network interface priv0.100 March 5, 2025 5:33:49 PM CET March 5, 2025 5:33:50 PM CET Success
Restart network interface privasm March 5, 2025 5:33:50 PM CET March 5, 2025 5:33:50 PM CET Success
Setting up Network March 5, 2025 5:33:51 PM CET March 5, 2025 5:33:51 PM CET Success
Restart network interface privasm March 5, 2025 5:33:51 PM CET March 5, 2025 5:33:56 PM CET Success
Network update March 5, 2025 5:33:56 PM CET March 5, 2025 5:34:09 PM CET Success
Updating network March 5, 2025 5:33:56 PM CET March 5, 2025 5:34:09 PM CET Success
Setting up Network March 5, 2025 5:33:56 PM CET March 5, 2025 5:33:56 PM CET Success
Restart network interface btbond1 March 5, 2025 5:33:56 PM CET March 5, 2025 5:34:00 PM CET Success
Restart network interface btbond1 March 5, 2025 5:34:00 PM CET March 5, 2025 5:34:03 PM CET Success
Restart network interface pubnet March 5, 2025 5:34:03 PM CET March 5, 2025 5:34:09 PM CET Success
Validate availability of pubnet March 5, 2025 5:34:09 PM CET March 5, 2025 5:34:09 PM CET Success
OS usergroup 'asmdba' creation March 5, 2025 5:34:09 PM CET March 5, 2025 5:34:09 PM CET Success
OS usergroup 'asmoper' creation March 5, 2025 5:34:09 PM CET March 5, 2025 5:34:09 PM CET Success
OS usergroup 'asmadmin' creation March 5, 2025 5:34:09 PM CET March 5, 2025 5:34:09 PM CET Success
OS usergroup 'dba' creation March 5, 2025 5:34:09 PM CET March 5, 2025 5:34:10 PM CET Success
OS usergroup 'dbaoper' creation March 5, 2025 5:34:10 PM CET March 5, 2025 5:34:10 PM CET Success
OS usergroup 'oinstall' creation March 5, 2025 5:34:10 PM CET March 5, 2025 5:34:10 PM CET Success
OS user 'grid' creation March 5, 2025 5:34:10 PM CET March 5, 2025 5:34:10 PM CET Success
OS user 'oracle' creation March 5, 2025 5:34:10 PM CET March 5, 2025 5:34:11 PM CET Success
Default backup policy creation March 5, 2025 5:34:11 PM CET March 5, 2025 5:34:11 PM CET Success
Backup Config name validation March 5, 2025 5:34:11 PM CET March 5, 2025 5:34:11 PM CET Success
Backup config metadata persist March 5, 2025 5:34:11 PM CET March 5, 2025 5:34:11 PM CET Success
Grant permission to RHP files March 5, 2025 5:34:11 PM CET March 5, 2025 5:34:11 PM CET Success
Add SYSNAME in Env March 5, 2025 5:34:11 PM CET March 5, 2025 5:34:11 PM CET Success
Install oracle-ahf March 5, 2025 5:34:11 PM CET March 5, 2025 5:35:54 PM CET Success
Stop DCS Admin March 5, 2025 5:35:56 PM CET March 5, 2025 5:35:56 PM CET Success
Generate mTLS certificates March 5, 2025 5:35:56 PM CET March 5, 2025 5:35:58 PM CET Success
Exporting Public Keys March 5, 2025 5:35:58 PM CET March 5, 2025 5:35:59 PM CET Success
Creating Trust Store March 5, 2025 5:35:59 PM CET March 5, 2025 5:36:02 PM CET Success
Update config files March 5, 2025 5:36:02 PM CET March 5, 2025 5:36:02 PM CET Success
Restart DCS Admin March 5, 2025 5:36:02 PM CET March 5, 2025 5:36:23 PM CET Success
Unzipping storage configuration files March 5, 2025 5:36:23 PM CET March 5, 2025 5:36:23 PM CET Success
Reloading multipath devices March 5, 2025 5:36:23 PM CET March 5, 2025 5:36:24 PM CET Success
Restart oakd March 5, 2025 5:36:24 PM CET March 5, 2025 5:36:34 PM CET Success
Restart oakd March 5, 2025 5:37:45 PM CET March 5, 2025 5:37:55 PM CET Success
Restore Quorum Disks March 5, 2025 5:37:55 PM CET March 5, 2025 5:37:56 PM CET Success
Creating GI home directories March 5, 2025 5:37:56 PM CET March 5, 2025 5:37:56 PM CET Success
Extract GI clone March 5, 2025 5:37:56 PM CET March 5, 2025 5:39:07 PM CET Success
Creating wallet for Root User March 5, 2025 5:39:07 PM CET March 5, 2025 5:39:15 PM CET Success
Creating wallet for ASM Client March 5, 2025 5:39:15 PM CET March 5, 2025 5:39:18 PM CET Success
Grid stack creation March 5, 2025 5:39:18 PM CET March 5, 2025 5:49:35 PM CET Success
GI Restore with RHP March 5, 2025 5:39:18 PM CET March 5, 2025 5:46:26 PM CET Success
Updating GIHome version March 5, 2025 5:46:28 PM CET March 5, 2025 5:46:31 PM CET Success
Restarting Clusterware March 5, 2025 5:46:32 PM CET March 5, 2025 5:49:35 PM CET Success
Post cluster OAKD configuration March 5, 2025 5:49:35 PM CET March 5, 2025 5:50:30 PM CET Success
Mounting disk group DATA March 5, 2025 5:50:30 PM CET March 5, 2025 5:50:31 PM CET Success
Mounting disk group RECO March 5, 2025 5:50:38 PM CET March 5, 2025 5:50:45 PM CET Success
Setting ACL for disk groups March 5, 2025 5:50:53 PM CET March 5, 2025 5:50:55 PM CET Success
Register Scan and Vips to Public Network March 5, 2025 5:50:55 PM CET March 5, 2025 5:50:57 PM CET Success
Adding Volume DUMPS to Clusterware March 5, 2025 5:51:10 PM CET March 5, 2025 5:51:13 PM CET Success
Adding Volume ACFSCLONE to Clusterware March 5, 2025 5:51:13 PM CET March 5, 2025 5:51:15 PM CET Success
Adding Volume ODABASE_N0 to Clusterware March 5, 2025 5:51:15 PM CET March 5, 2025 5:51:18 PM CET Success
Adding Volume COMMONSTORE to Clusterware March 5, 2025 5:51:18 PM CET March 5, 2025 5:51:20 PM CET Success
Adding Volume ORAHOME_SH to Clusterware March 5, 2025 5:51:20 PM CET March 5, 2025 5:51:23 PM CET Success
Enabling Volume(s) March 5, 2025 5:51:23 PM CET March 5, 2025 5:52:26 PM CET Success
Discover ACFS clones config March 5, 2025 5:53:18 PM CET March 5, 2025 5:53:27 PM CET Success
Configure export clones resource March 5, 2025 5:53:26 PM CET March 5, 2025 5:53:27 PM CET Success
Discover DbHomes ACFS config March 5, 2025 5:53:27 PM CET March 5, 2025 5:53:30 PM CET Success
Discover OraHomeStorage volumes March 5, 2025 5:53:27 PM CET March 5, 2025 5:53:30 PM CET Success
Setting up Hugepages March 5, 2025 5:53:30 PM CET March 5, 2025 5:53:30 PM CET Success
Provisioning service creation March 5, 2025 5:53:32 PM CET March 5, 2025 5:53:32 PM CET Success
Persist new agent state entry March 5, 2025 5:53:32 PM CET March 5, 2025 5:53:32 PM CET Success
Persist new agent state entry March 5, 2025 5:53:32 PM CET March 5, 2025 5:53:32 PM CET Success
Restart DCS Agent March 5, 2025 5:53:32 PM CET March 5, 2025 5:53:33 PM CET SuccessThis time it worked fine. Next step will be the restore-node -d for restoring the databases.
The backup script I use before patching an ODATroubleshooting is easier if you can have a look at configuration files that were in use prior reimaging. Here is a script I’ve been using for years before patching or reimaging an ODA. I would recommend making your own script based on mine according to your specific configuration:
vi /mnt/backup/prepatch_backup.sh
# Backup important files before patching
export BKPPATH=/mnt/backup/ODA_backup/backup_ODA_`hostname`_`date +"%Y%m%d_%H%M"`
echo "Backing up to " $BKPPATH
mkdir -p $BKPPATH
odacli list-databases > $BKPPATH/list-databases.txt
ps -ef | grep pmon | grep -v ASM | grep -v APX | grep -v grep | cut -c 58- | sort > $BKPPATH/running-instances.txt
odacli list-dbhomes > $BKPPATH/list-dbhomes.txt
odacli list-dbsystems > $BKPPATH/list-dbsystems.txt
odacli list-vms > $BKPPATH/list-vms.txt
crontab -u oracle -l > $BKPPATH/crontab-oracle.txt
crontab -u grid -l > $BKPPATH/crontab-grid.txt
crontab -l > $BKPPATH/crontab-root.txt
cat /etc/fstab > $BKPPATH/fstab.txt
cat /etc/oratab > $BKPPATH/oratab.txt
cat /etc/sysconfig/network > $BKPPATH/etc-sysconfig-network.txt
cat /etc/hosts > $BKPPATH/hosts
cat /etc/resolv.conf > $BKPPATH/resolv.conf
cp /etc/krb5.conf $BKPPATH/
cp /etc/krb5.keytab $BKPPATH/
mkdir $BKPPATH/network-scripts
cp /etc/sysconfig/network-scripts/ifcfg* $BKPPATH/network-scripts/
odacli describe-system > $BKPPATH/describe-system.txt
odacli describe-component > $BKPPATH/describe-component.txt
HISTFILE=~/.bash_history
set -o history
history > $BKPPATH/history-root.txt
cp /home/oracle/.bash_history $BKPPATH/history-oracle.txt
df -h > $BKPPATH/filesystems-status.txt
for a in `odacli list-dbhomes -j | grep dbHomeLocation | awk -F '"' '{print $4}' | sort` ; do mkdir -p $BKPPATH/$a/network/admin/ ; cp $a/network/admin/tnsnames.ora $BKPPATH/$a/network/admin/; cp $a/network/admin/sqlnet.ora $BKPPATH/$a/network/admin/; done
for a in `odacli list-dbhomes -j | grep dbHomeLocation | awk -F '"' '{print $4}' | sort` ; do mkdir -p $BKPPATH/$a/owm/ ; cp -r $a/owm/* $BKPPATH/$a/owm/; done
cp `ps -ef | grep -v grep | grep LISTENER | awk -F ' ' '{print $8}' | awk -F 'bin' '{print $1}'`network/admin/listener.ora $BKPPATH/gridhome-listener.ora
cp `ps -ef | grep -v grep | grep LISTENER | awk -F ' ' '{print $8}' | awk -F 'bin' '{print $1}'`/network/admin/sqlnet.ora $BKPPATH/gridhome-sqlnet.ora
tar czf $BKPPATH/u01-app-oracle-admin.tgz /u01/app/oracle/admin/
tar czf $BKPPATH/u01-app-oracle-local.tgz /u01/app/oracle/local/
tar czf $BKPPATH/home.tgz /home/
cp /etc/passwd $BKPPATH/
cp /etc/group $BKPPATH/
echo "End"
echo "Backup files size:"
du -hs $BKPPATH
echo "Backup files content:"
ls -lrt $BKPPATH
I would recommend these 3 rules to save hours of troubleshooting:
- as mentioned in the ODA documentation: never change networks parameters manually (IP, gateway, hostname, DNS, bonding mode, …)
- document every manual change you make on your ODA (additional tools setup, specific settings, …)
- do an extensive backup of all configuration files before doing a patching or a DPR (use the script provided in the previous chapter for creating yours)
L’article PRGH-1030 when doing restore-node -g on ODA est apparu en premier sur dbi Blog.
PostgreSQL 18: More granular log_connections
Many of our customers enable log_connections because of auditing requirements. This is a simple boolean which is either turned on or off. Once this is enabled and active every new connection to a PostgreSQL database is logged into the PostgreSQL log file. Up to PostgreSQL 17, a typical line in the log file for a logged connection looks like this:
2025-03-13 08:50:05.607 CET - 1 - 6195 - [local] - [unknown]@[unknown] - 0LOG: connection received: host=[local]
2025-03-13 08:50:05.607 CET - 2 - 6195 - [local] - postgres@postgres - 0LOG: connection authenticated: user="postgres" method=trust (/u02/pgdata/17/pg_hba.conf:117)
2025-03-13 08:50:05.607 CET - 3 - 6195 - [local] - postgres@postgres - 0LOG: connection authorized: user=postgres database=postgres application_name=psql
As you can see, there are three stages logged: Connection received, authenticated and authorized. This gives you an idea of how long each of the stages took to complete by comparing the timestamps logged. A consequence of this is, that it can generate quite some noise in the log file if you have many connections.
With PostgreSQL 18 this will change, log_connections is not anymore a simple boolean but a list of supported values. The valid options are:
- receipt
- authentication
- authorization
- [empty string]
This list should already tell you what changed. You now have the option to enable logging of specific stages only, and not all of them at once if you don’t need them. An empty string disables connection logging.
So, e.g. if you are only interested in the authorization stage you can now configure that:
postgres@pgbox:/home/postgres/ [pgdev] psql
psql (18devel)
Type "help" for help.
postgres=# select version();
version
--------------------------------------------------------------------
PostgreSQL 18devel on x86_64-linux, compiled by gcc-14.2.1, 64-bit
(1 row)
postgres=# alter system set log_connections = 'authorization';
ALTER SYSTEM
postgres=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
From now on only the “authorization” stage is logged into the log file:
2025-03-13 09:10:41.710 CET - 1 - 6617 - [local] - postgres@postgres - 0LOG: connection authorized: user=postgres database=postgres application_name=psql
This reduces the amount of logging quite a bit, if you are only interested in that stage. Adding all stages will restore the old behavior of logging all stages:
postgres=# alter system set log_connections = 'authorization','receipt','authentication';
ALTER SYSTEM
postgres=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
With this setting, it looks exactly like before:
2025-03-13 09:14:19.520 CET - 1 - 6629 - [local] - [unknown]@[unknown] - 0LOG: connection received: host=[local]
2025-03-13 09:14:19.521 CET - 2 - 6629 - [local] - postgres@postgres - 0LOG: connection authenticated: user="postgres" method=trust (/u02/pgdata/PGDEV/pg_hba.conf:117)
2025-03-13 09:14:19.521 CET - 3 - 6629 - [local] - postgres@postgres - 0LOG: connection authorized: user=postgres database=postgres application_name=psql
Nice, all details here, and as usual, thank you to all involved in this.
L’article PostgreSQL 18: More granular log_connections est apparu en premier sur dbi Blog.
Why Metadata Matters?

In today’s digital landscape, efficient Content Management is crucial for business productivity. While many organizations still rely on traditional folder-based file management. Modern solutions like M-Files offer a smarter way to store, organize, and retrieve information.
The key differentiator? Metadata. In this blog post, we’ll explore the limitations of traditional file management, the advantages of metadata-driven organization, and why M-Files is the best choice for businesses.
Traditional File ManagementMost of the Document Management Systems (DMS) relies on a hierarchical folder structure where documents are manually placed in specific locations. While this approach is familiar and simple to use, that is not the best way for some reasons:
- Difficult to Locate Files: Searching for documents requires navigating multiple nested folders, leading to wasted time and frustration.
- File Duplication: The same document may be stored in different locations, increasing redundancy and the risk of outdated versions.
- Limited Search Capabilities: Keyword searches often yield inaccurate results since traditional systems rely on file names rather than properties.
- Rigid Structure: A document can only reside in one location, making it difficult to classify files that belong to multiple categories.
- Version Control Issues: Without proper versioning, employees may work on outdated files, leading to errors and inefficiencies.
Unlike traditional file systems, M-Files eliminates reliance on folders by organizing documents based on metadata—descriptive properties that define a document’s content, purpose, and relationships. Here’s why this approach is transformative:
- Faster and Smarter Search: With M-Files, users can quickly find documents by searching for metadata fields such as document type, author, project name, or approval status. No more clicking through endless folders, simply enter relevant terms and get instant results.
- Eliminates Duplication and Redundancy: Since documents are classified based on properties rather than locations, there’s no need for multiple copies stored across different folders. Users access the latest version from a single source of truth.
- Dynamic Organization: Documents can be viewed in multiple ways without duplication. For example, a contract can appear under “Legal,” “Finance,” and “Project X” based on its metadata while existing as a single file.
- Automated Workflows and Compliance: M-Files allows businesses to automate document workflows based on metadata. For instance, an invoice marked “Pending Approval” can be automatically routed to the finance team, ensuring compliance and efficiency.
- Version Control: Every document change is automatically saved with a full version history, preventing accidental overwrites and ensuring teams always work with the most recent file.
If your business is still struggling with traditional file structures, it’s time to rethink how you manage information. M-Files provides a smarter, faster, and more flexible solution that aligns with modern business needs.
Moving your document to M-Files may look a huge amount of work, but fortunately it is not so!
Why? two main reasons:
- M-Files provides solutions to smoothly move your data (see my other post here).
- We are here to help you revolutionizing your document management
L’article Why Metadata Matters? est apparu en premier sur dbi Blog.
pgvector, a guide for DBA – Part2 indexes
In the last blog post we did setup a LAB with a DVDRental database mixed with Netflix data on top which we created some embeddings hosted on the same tables thanks to pgvector. In this second part, we will start to look at improving query execution time with some indexes before extending on the rest of the AI workflow.
But first let’s talk about why developing those skills is so important.
Rollback 40 years ago. Back then we had applications storing data on ISAM databases. Basically flat files. Then we created this thing called SQL and the RDBMS with ACID properties to make it run. This moved the logic from the application only to have a bit in both sides. If you are a DBA with “some experience” you might remember the days when producing stored procedures, triggers with complex logic was complementary to the application code that DEVs couldn’t or wouldn’t change… the issue being that the code on the database side was harder to maintain.
Then 15-20 years ago we started to use ORMs everywhere and moved the logic from the RDBMS side to the ORM or app. This enabled to partially decouple the app from its backend database server and allow for having more sources (NOSQL DBMS) but also migrate easier from one system to another. This is why the lasts years we have a lot of migrations towards other RDBMS, it is today more easy than ever, “you just” have to add a new connector without changing the app. As DBA we went from tuning a lot of SQL code to almost fraction of it because the ORMs became better and better.
Where do I go with all of that ?
Well, with AI, the logic is going to leave the ORMs and app part and only be in the AI model tuned for your business. What does that mean ? It means that you will have an easier access to all of your data. You won’t have to wait for a team of developer to develop the panel of dashboards and reports you want in the app, you just going to ask the AI the data in the way you want it and it will just know of to connect to your database and build the query.
My point : consequence of that is that the databases are going to be hammered more than ever and most of the limitations that your going to have is the design choice of your database backend and your AI workflow. Not the app anymore. Learning how to optimize AI workflow and data retrieval will be key for the future.
So after this intro, let’s dive into those new PostgreSQL vector indexes a bit…
Index types in pgvectorpgvector supports natively two types of indexes that are approximate nearest neighbor (ANN) indexes. Unlike other indexes in PostgreSQL like B-tree or GiST, the ANN indexes trade some recall accuracy for query speed. What does it mean? It means that index searches with ANN won’t necessarily return the same return as a sequential scan.
The Hierarchical Navigable Small World (HNSW) index builds a multi‐layer graph where each node (a vector) is connected to a fixed number of neighbors. During a search, the algorithm starts at the top (sparse) layer and “zooms in” through lower layers to quickly converge on the nearest neighbors.
- Key parameters:
- m: Maximum number of links per node (default is 16).
- ef_construction: Candidate list size during index build (default is 64).
- ef_search: Size of the dynamic candidate list during query (default is 40; can be tuned per query).
- Characteristics & Use Cases:
- Excellent query speed and high recall.
- Suitable for workloads where fast similarity search is critical—even if build time and memory consumption are higher.
Here is an example of a query and some index to support it.
CREATE INDEX film_embedding_idx
ON public.film USING hnsw (embedding vector_l2_ops)
CREATE INDEX netflix_shows_embedding_idx
ON public.netflix_shows USING hnsw (embedding vector_l2_ops)Here is the execution plan of this query :
-- (Using existing HNSW index on film.embedding)
EXPLAIN ANALYZE
SELECT film_id, title
FROM film
ORDER BY embedding <-> '[-0.0060701305,-0.008093507...]' --choose any embedding from the table
LIMIT 5;
Limit (cost=133.11..133.12 rows=5 width=27) (actual time=7.498..7.500 rows=5 loops=1)
-> Sort (cost=133.11..135.61 rows=1000 width=27) (actual time=7.497..7.497 rows=5 loops=1)
Sort Key: ((embedding <-> '[-0.0060701305,-0.008093507,-0.0019467601,0.015574081,0.012467623,0.032596912,-0.0284>
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on film (cost=0.00..116.50 rows=1000 width=27) (actual time=0.034..7.243 rows=1000 loops=1)
Planning Time: 0.115 ms
Execution Time: 7.521 ms
(7 rows)
IVFFlat (Inverted File with Flat compression) first partitions the vector space into clusters (lists) by running a clustering algorithm (typically k-means). Each vector is assigned to the nearest cluster (centroid). At query time, only a subset (controlled by the number of probes) of the closest clusters are scanned rather than the entire dataset
- Key parameters:
- lists: Number of clusters created at index build time (a good starting point is rows/1000 for up to 1M rows or sqrt(rows) for larger datasets).
- probes: Number of clusters to search during a query (default is 1; higher values improve recall at the cost of speed).
- Characteristics & Use Cases:
- Faster index build and smaller index size compared to HNSW.
- May yield slightly lower recall or slower query performance if too few probes are used.
- Best used when the dataset is relatively static (since the clusters are built only once).
CREATE INDEX film_embedding_ivfflat_idx
ON film USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
With the same query as before we have now this execution plan :
Limit (cost=27.60..43.40 rows=5 width=27) (actual time=0.288..0.335 rows=5 loops=1)
-> Index Scan using film_embedding_ivfflat_idx on film (cost=27.60..3188.50 rows=1000 width=27) (actual time=0.286..>
Order By: (embedding <-> '[-0.0060701305,-0.008093507,-0.0019467601,0.015574081,0.012467623,0.032596912,-0.02841>
Planning Time: 0.565 ms
Execution Time: 0.375 ms
(5 rows)- Example Query:
After setting the number of probes, you can run:
SET ivfflat.probes = 5;
-- New execution plan
Limit (cost=133.11..133.12 rows=5 width=27) (actual time=7.270..7.272 rows=5 loops=1)
-> Sort (cost=133.11..135.61 rows=1000 width=27) (actual time=7.268..7.269 rows=5 loops=1)
Sort Key: ((embedding <-> '[-0.0060701305,-0.008093507,-0.0019467601,0.015574081,0.012467623,0.032596912,-0.0284>
Sort Method: top-N heapsort Memory: 25kB
-> Seq Scan on film (cost=0.00..116.50 rows=1000 width=27) (actual time=0.054..6.984 rows=1000 loops=1)
Planning Time: 0.140 ms
Execution Time: 7.293 ms
(7 rows)By changing the number of probes :
SET ivfflat.probes = 10;
-- New execution plan
Limit (cost=104.75..120.17 rows=5 width=27) (actual time=0.459..0.499 rows=5 loops=1)
-> Index Scan using film_embedding_ivfflat_idx on film (cost=104.75..3188.50 rows=1000 width=27) (actual time=0.458.>
Order By: (embedding <-> '[-0.0060701305,-0.008093507,-0.0019467601,0.015574081,0.012467623,0.032596912,-0.02841>
Planning Time: 0.153 ms
Execution Time: 0.524 ms
(5 rows)When you create an IVFFlat index, you specify a parameter called lists. This parameter determines how many clusters (or “lists”) the index will divide your entire dataset into. Essentially, during index build time, the algorithm runs a clustering process (commonly using k-means) on your vectors and assigns each vector to the nearest cluster centroid.
For example, if you set lists = 100 during index creation, the entire dataset is divided into 100 clusters. Then at query time, setting probes = 1 means only the single cluster whose centroid is closest to the query vector is examined. Increasing probes (say, to 10) instructs PostgreSQL to examine 10 clusters—improving recall by reducing the chance of missing the true nearest neighbors at the cost of extra computation. Lists define the overall structure of the index, while probes control the breadth of search within that structure at runtime. They are related but serve different purposes: one is fixed at build time, and the other is adjustable at query time.
A higher number of lists means that each cluster is smaller. This can lead to faster candidate comparisons because fewer vectors lie in any one cluster, but if you over-partition the data, you might risk missing close vectors that fall on the boundary between clusters.
The probes parameter is a query-time setting that tells the index how many of these pre-computed clusters to search when processing a query.
- HNSW:
- Query time: Adjust
hnsw.ef_searchto trade-off between speed and recall. Higher values improve recall (more candidate vectors examined) but slow down queries. - Build time: Increasing
moref_constructioncan improve the quality (recall) of the index, but also increase build time and memory consumption.
- Query time: Adjust
- IVFFlat:
- Lists: Choosing the right number of clusters is essential. Use rules like rows/1000 for smaller datasets or sqrt(rows) for larger ones.
- Probes: Increase the number of probes (using
SET ivfflat.probes = value;) if recall is too low. This will widen the search among clusters at the cost of increased query time.
DiskANN was originally a research project from Microsoft Research and is open-sourced on GitHub. It uses a graph (like HNSW) but optimized for disk access patterns (paging neighbors in and out). Based on Microsoft research the team from Timescale produced pgvectorscale which is an open-source PostgreSQL extension that builds on top of the pgvector extension to provide DiskANN-based indexing for high-performance vector similarity search.
It introduces a new StreamingDiskANN index inspired by Microsoft’s DiskANN algorithm, along with Statistical Binary Quantization (SBQ) for compressing vector data.
What is the big deal with DiskANN and StreamingDiskANN ? Well, the main idea behind it is to avoid having all the information in memory (like with HNSW and IVFFlat) and store the bulk of the index on disk and only load small, relevant parts into memory when needed. This eliminates the memory bottleneck with massive datasets and provide a sub-linear scaling with RAM usage. DiskANN can handle billion‐scale datasets without demanding terabytes of memory.
These innovations significantly improve query speed and storage efficiency for embedding (vector) data in Postgres. In practice, PostgreSQL with pgvector + pgvectorscale has been shown to achieve dramatically lower query latencies and higher throughput compared to specialized vector databases!
Building from Source: pgvectorscale is written in Rust (using the PGRX framework) and can be compiled and installed into an existing PostgreSQL instance (GitHub – timescale/pgvectorscale: A complement to pgvector for high performance, cost efficient vector search on large workloads.) (GitHub – timescale/pgvectorscale: A complement to pgvector for high performance, cost efficient vector search on large workloads.).
For my setup, I adapted the installation procedure provided to be able to install the pgvectorscale extension on my custom setup :
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
cargo install --force --locked cargo-pgrx --version 0.12.5
cargo pgrx init --pg17 /u01/app/postgres/product/17/db_2/bin/pg_config
cd /tmp
git clone --branch 0.6.0 https://github.com/timescale/pgvectorscale
cd pgvectorscale/pgvectorscale
cargo pgrx install --release
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;CREATE INDEX netflix_embedding_idx
ON netflix_shows
USING diskann (embedding vector_l2_ops);
I am planning to perform a full benchmark comparison with different solutions and with a AI/LLM as client in order to measure the real impact on performance. In the meantime, you might wanna check the Timescale benchmark on the matter compared to Pinecone: Pgvector vs. Pinecone: Vector Database Comparison | Timescale
To make a quick summary of the characteristics of each index types :
Selectivity/AccuracyDiskANN (pgvectorscale)FastFastestLow (uses disk)Updatable (no rebuild)High (approximate, tuned)HNSW (pgvector)FastFastHigh (in-memory)Updatable (no rebuild)High (approximate)IVFFlat (pgvector)FastestSlowestLow/ModerateRebuild required after bulk changeModerat-high (tuning dependant)B-TREE Very fastSmalllownoneExact
If you are familiar with RDBMS query tuning optimizations, you might already understand the importance of the selectivity of your data.

In the RDBMS world, if we index the color of the tree, “yellow” is selective, “green” is not. It is not the index that matters it’s the selectivity of the data you’re looking for to the optimizer’s eyes (yes an optimizer has eyes, and he sees everything!).
When performing and hybrid SQL/similarity search we will typically try to filter a subset of rows on top of which we will execute a similarity vector search. I kind of didn’t talk about that but it is one of the most important parts of having vectors in a database! You can look for similarities! What does it mean ?!
It allows you to run an approximate search against a table. That’s it. When you are looking for something that kind of reassembles what input you provide… In the first part of this blog series, I briefly explain the fact that embeddings encapsulate meanings into numbers in the form of a vector. The closer two vectors in that context, the more they are the same. In my example, we use text embedding to look for similarities but you have models that work with videos, sound, or images as well.
For example, Deezer is using “FLOW” which is looking for your music taste of the playlist you saved and is proposing similar songs in addition to the ones you already like. In addition, it can compare your taste profile with your mood (inputs or events of you skipping songs fast).
Contrary to the classic indexes in PostgreSQL, vector indexes are by definition non-deterministic.
They use approximations to narrow down the search space. In the index search process, the Recall measures the fraction of the data that is returned to be true. Higher recall means better precision at the cost of speed and index size. Running the same vector multiple times might slightly return different rankings or even different subset of the nearest neighbors. This means that DBAs have to play with some index parameters like ef_search, ef_construction, m ( for HNSW ) or lists and probes ( for IVFFlat).
Playing with those parameters will help find the balance between speed and recall.
One advice would be to start with the default and combine with deterministic filters before touching any parameters. In most cases having 99% or 98% of recall is really fine. But like in the deterministic world, understanding your data is key.
Here in my LAB example, I use the description field in both netflix_shows and film tables. Although the methodology I am using is good enough I would say, the results generated might be completely off because the film table of the dvdrental database are not real movies and their description are not reliable which is not the case for the netflix_shows table. So when I am looking at the user average embedding on their top movies rented… I am going to compare things that might not be comparable, which will provide an output that is probably not meaningful.
Quick reminder, when looking for similarities you can use two operators in your SQL query : <-> (Euclidean): is Sensitive to magnitude differences. <=> (Cosine): Focuses on the angle of vectors, often yielding more semantically relevant results for text embeddings.
Which one should you use and when ?
Well, initially embedding are created by embedding models, they define the usage of the magnitude in the vector or not. If your model is not using the magnitude parameter to encompass additional characteristics, then only the angle > Cosine operator makes sense. The Euclidean operator would work but is suboptimal since you try to compute something that isn’t there. You should rely on the embedding model documentation to make your choice or just test if the results you are having differ in meaning.
In my example, I use text-embedding-ada-002 model, where the direction (angle) is the primary carrier of semantic meaning.
Note that those operators are used to define your indexes ! Like for JSONB queries in PostgreSQL, not using the proper operator can make the optimizer not choose the index and use a sequential scan instead.
One other important aspect a DBA has to take into consideration is that the PostgreSQL optimizer is still being used and has still the same behaviour which is one of the strength of using pgvector. You already know the beast !
For example depending on the query and the data set size, the optimizer would find more cost-effective to run a sequential scan than using an index, my sample dvdrental data set is not really taking advantage of the indexes benefits in most cases. The tables have only 1000 and 8000 rows.
Let’s look at some interesting cases. This first query is not using an index. Here we are looking for the top 5 Netflix shows whose vector embeddings are most similar to a customer profile embedding which is calculated be the average of film embeddings the customer 524 has rented.
postgres=# \c dvdrental
You are now connected to database "dvdrental" as user "postgres".
dvdrental=# WITH customer_profile AS (
SELECT AVG(f.embedding) AS profile_embedding
FROM rental r
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
WHERE r.customer_id = 524
)
SELECT n.title,
n.description,
n.embedding <-> cp.profile_embedding AS distance
FROM netflix_shows n, customer_profile cp
WHERE n.embedding IS NOT NULL
ORDER BY n.embedding <=> cp.profile_embedding
LIMIT 5;
title | description | distance
------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------
Alarmoty in the Land of Fire | While vacationing at a resort, an ornery and outspoken man is held captive by a criminal organization. | 0.4504742864770678
Baaghi | A martial artist faces his biggest test when he has to travel to Bangkok to rescue the woman he loves from the clutches of his romantic rival. | 0.4517695114131648
Into the Badlands | Dreaming of escaping to a distant city, a ferocious warrior and a mysterious boy tangle with territorial warlords and their highly trained killers. | 0.45256925901147355
Antidote | A tough-as-nails treasure hunter protects a humanitarian doctor as she tries to cure a supernatural disease caused by a mysterious witch. | 0.4526900472984078
Duplicate | Hilarious mix-ups and deadly encounters ensue when a convict seeks to escape authorities by assuming the identity of his doppelgänger, a perky chef. | 0.45530040371443564
(5 rows)
dvdrental=# explain analyze WITH customer_profile AS (
SELECT AVG(f.embedding) AS profile_embedding
FROM rental r
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
WHERE r.customer_id = 524
)
SELECT n.title,
n.description,
n.embedding <=> cp.profile_embedding AS distance
FROM netflix_shows n, customer_profile cp
WHERE n.embedding IS NOT NULL
ORDER BY n.embedding <=> cp.profile_embedding
LIMIT 5;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1457.26..1457.27 rows=5 width=173) (actual time=40.076..40.081 rows=5 loops=1)
-> Sort (cost=1457.26..1479.27 rows=8807 width=173) (actual time=40.075..40.079 rows=5 loops=1)
Sort Key: ((n.embedding <-> (avg(f.embedding))))
Sort Method: top-N heapsort Memory: 27kB
-> Nested Loop (cost=471.81..1310.97 rows=8807 width=173) (actual time=1.822..38.620 rows=8807 loops=1)
-> Aggregate (cost=471.81..471.82 rows=1 width=32) (actual time=1.808..1.812 rows=1 loops=1)
-> Nested Loop (cost=351.14..471.74 rows=25 width=18) (actual time=0.938..1.479 rows=19 loops=1)
-> Hash Join (cost=350.86..462.01 rows=25 width=2) (actual time=0.927..1.431 rows=19 loops=1)
Hash Cond: (i.inventory_id = r.inventory_id)
-> Seq Scan on inventory i (cost=0.00..70.81 rows=4581 width=6) (actual time=0.006..0.262 rows=4581 loops=1)
-> Hash (cost=350.55..350.55 rows=25 width=4) (actual time=0.863..0.864 rows=19 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on rental r (cost=0.00..350.55 rows=25 width=4) (actual time=0.011..0.858 rows=19 loops=1)
Filter: (customer_id = 524)
Rows Removed by Filter: 16025
-> Index Scan using film_pkey on film f (cost=0.28..0.39 rows=1 width=22) (actual time=0.002..0.002 rows=1 loops=19)
Index Cond: (film_id = i.film_id)
-> Seq Scan on netflix_shows n (cost=0.00..729.07 rows=8807 width=183) (actual time=0.004..3.301 rows=8807 loops=1)
Filter: (embedding IS NOT NULL)
Planning Time: 0.348 ms
Execution Time: 40.135 ms
(21 rows)The optimizer is not taking advantage for several reasons. First, the data set size is small enough so that a sequential scan and an in-memory sort are in expensive compare to the overhead of using the index.
The second reason being that the predicate is not a constant value. The complexity of having “n.embedding <=> cp.profile_embedding” being computed for each row prevents the optimizer from “pushing down” the distance calculation into the index scan. Indexes are most effective to the optimizer’s eyes when the search key is “sargable”. Modifying a bit some parameters and the query is forcing the index usage :
SET enable_seqscan = off;
SET enable_bitmapscan = off;
SET enable_indexscan = on;
SET random_page_cost = 0.1;
SET seq_page_cost = 100;
dvdrental=# EXPLAIN ANALYZE
WITH customer_profile AS (
SELECT AVG(f.embedding) AS profile_embedding
FROM rental r
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
WHERE r.customer_id = 524
)
SELECT n.title,
n.description,
n.embedding <=> (SELECT profile_embedding FROM customer_profile) AS distance
FROM netflix_shows n
WHERE n.embedding IS NOT NULL
AND n.embedding <=> (SELECT profile_embedding FROM customer_profile) < 0.5
ORDER BY n.embedding <=> (SELECT profile_embedding FROM customer_profile)
LIMIT 5;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=146.81..147.16 rows=5 width=173) (actual time=2.450..2.605 rows=5 loops=1)
CTE customer_profile
-> Aggregate (cost=145.30..145.31 rows=1 width=32) (actual time=0.829..0.830 rows=1 loops=1)
-> Nested Loop (cost=0.84..145.24 rows=25 width=18) (actual time=0.021..0.509 rows=19 loops=1)
-> Nested Loop (cost=0.57..137.87 rows=25 width=2) (actual time=0.017..0.466 rows=19 loops=1)
-> Index Only Scan using idx_unq_rental_rental_date_inventory_id_customer_id on rental r (cost=0.29..127.27 rows=25 width=4) (actual time=0.010..0.417 rows=19 loops=1)
Index Cond: (customer_id = 524)
Heap Fetches: 0
-> Index Scan using inventory_pkey on inventory i (cost=0.28..0.42 rows=1 width=6) (actual time=0.002..0.002 rows=1 loops=19)
Index Cond: (inventory_id = r.inventory_id)
-> Index Scan using film_pkey on film f (cost=0.28..0.29 rows=1 width=22) (actual time=0.002..0.002 rows=1 loops=19)
Index Cond: (film_id = i.film_id)
InitPlan 2
-> CTE Scan on customer_profile (cost=0.00..0.02 rows=1 width=32) (actual time=0.832..0.832 rows=1 loops=1)
InitPlan 3
-> CTE Scan on customer_profile customer_profile_1 (cost=0.00..0.02 rows=1 width=32) (actual time=0.001..0.001 rows=1 loops=1)
-> Index Scan using netflix_embedding_cosine_idx on netflix_shows n (cost=1.46..205.01 rows=2936 width=173) (actual time=2.449..2.601 rows=5 loops=1)
Order By: (embedding <=> (InitPlan 2).col1)
Filter: ((embedding IS NOT NULL) AND ((embedding <=> (InitPlan 3).col1) < '0.5'::double precision))
Planning Time: 0.354 ms
Execution Time: 2.643 ms
(21 rows)
Here we can observe that the query cost went down to 146 from 1457. By resetting the parameters of the session we can see that the index is still used and the query cost is now 504 which is still lower than the original query.
dvdrental=# RESET ALL;
RESET
dvdrental=# EXPLAIN ANALYZE
WITH customer_profile AS (
SELECT AVG(f.embedding) AS profile_embedding
FROM rental r
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
WHERE r.customer_id = 524
)
SELECT n.title,
n.description,
n.embedding <=> (SELECT profile_embedding FROM customer_profile) AS distance
FROM netflix_shows n
WHERE n.embedding IS NOT NULL
AND n.embedding <=> (SELECT profile_embedding FROM customer_profile) < 0.5
ORDER BY n.embedding <=> (SELECT profile_embedding FROM customer_profile)
LIMIT 5;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=504.52..509.12 rows=5 width=173) (actual time=3.769..3.941 rows=5 loops=1)
CTE customer_profile
-> Aggregate (cost=471.81..471.82 rows=1 width=32) (actual time=2.129..2.131 rows=1 loops=1)
-> Nested Loop (cost=351.14..471.74 rows=25 width=18) (actual time=1.286..1.825 rows=19 loops=1)
-> Hash Join (cost=350.86..462.01 rows=25 width=2) (actual time=1.279..1.781 rows=19 loops=1)
Hash Cond: (i.inventory_id = r.inventory_id)
-> Seq Scan on inventory i (cost=0.00..70.81 rows=4581 width=6) (actual time=0.008..0.271 rows=4581 loops=1)
-> Hash (cost=350.55..350.55 rows=25 width=4) (actual time=1.212..1.213 rows=19 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on rental r (cost=0.00..350.55 rows=25 width=4) (actual time=0.017..1.208 rows=19 loops=1)
Filter: (customer_id = 524)
Rows Removed by Filter: 16025
-> Index Scan using film_pkey on film f (cost=0.28..0.39 rows=1 width=22) (actual time=0.002..0.002 rows=1 loops=19)
Index Cond: (film_id = i.film_id)
InitPlan 2
-> CTE Scan on customer_profile (cost=0.00..0.02 rows=1 width=32) (actual time=2.133..2.133 rows=1 loops=1)
InitPlan 3
-> CTE Scan on customer_profile customer_profile_1 (cost=0.00..0.02 rows=1 width=32) (actual time=0.001..0.001 rows=1 loops=1)
-> Index Scan using netflix_embedding_cosine_idx on netflix_shows n (cost=32.66..2736.11 rows=2936 width=173) (actual time=3.768..3.937 rows=5 loops=1)
Order By: (embedding <=> (InitPlan 2).col1)
Filter: ((embedding IS NOT NULL) AND ((embedding <=> (InitPlan 3).col1) < '0.5'::double precision))
Planning Time: 0.448 ms
Execution Time: 4.017 ms
(23 rows)DO NOT PLAY AROUND WITH SESSION PARAMETERS ON PRODUCTION ENVIRONMENT TO PROVE A POINT.
Test environments are made for this and most likely session parameters or not the root cause of your issue.
If embeddings are still a bit hard to understand you might want to check this visualization of vector embeddings through this URL :
Embedding projector – visualization of high-dimensional data
That’s it for now. In the coming part 3 of this series we will talk about AI agents and workflows and how they relate to a DBA. For the part 4 we will discuss AI workflows Best practices. We will see if there is a need for a part 5.
pgvector/pgvector: Open-source vector similarity search for Postgres
DiskANN Vector Index in Azure Database for PostgreSQL
microsoft/DiskANN: Graph-structured Indices for Scalable, Fast, Fresh and Filtered Approximate Nearest Neighbor Search
timescale/pgvectorscale: A complement to pgvector for high performance, cost efficient vector search on large workloads.
Timescale Documentation | SQL inteface for pgvector and pgvectorscale
Debunking 6 common pgvector myths
Vector Indexes in Postgres using pgvector: IVFFlat vs HNSW | Tembo
Optimizing vector search performance with pgvector – Neon
L’article pgvector, a guide for DBA – Part2 indexes est apparu en premier sur dbi Blog.
Oracle Technology Roundtable for Digital Natives – Let’s have a look at AI, Cloud and HeatWave
Yesterday I participated to the Oracle Technology Roundtable for Digital Natives in Zurich.

It was a good opportunity to learn more about AI, Cloud and HeatWave with the focus on very trendy features of this product: generative AI, machine learning, vector processing, analytics and transaction processing across data in Data Lake and MySQL databases.

It was also great to share moments with the Oracle and MySQL teams and meet customers which gave feedback and tips about their solutions already in place in this area.

I’ll try to summarize below some key take-away of each session.
Unlocking Innovation: How Oracle AI is Shaping the Future of Business (by Jürgen Wirtgen)
AI is not a new topic. But how do we use it today and where are we in the process, early or advanced?
To answer this question, you can have a look to the stages of adoption:
- Consume (AI embedded in your applications) -> SaaS applications
- Extend (models via Data Retrieval, RAG) -> AI services
- Fine tune -> Data
- Build models from scratch -> Infrastructure
AI is not AI. The best AI starts with the best data, securely managed. Which can be translated back into a simple equation: Best Data + Best Technology = Best AI.

Innovations in HeatWave & MySQL – The Present and the Future (by Cagri Balkesen)
HeatWave is an in-memory query processing accelerator for data in MySQL transactional RDBMS or data in Object Store in different format.
Normally you need to put in place and maintain ETL processes to produce data that can be used effectively by analytics. This brings several drawbacks:
- Complexity
- You have to maintain different systems, on which you’ll have security issues to handle and costs to assume.
Using HeatWave, you don’t need that anymore, because it’s a single platform which allows you to manage together all your OLTP, OLAP, Machine Learning and GenAI workloads.
Which are the advantages of using HeatWave?
- You current SQL syntax doesn’t need to change
- Changes to data are automatically propagated to HeatWave
- Best performances for your queries
- Efficient processing for Data Lake
- Best platform for MySQL workloads
- Built-in GenAI & Vector Store
- Available in multi cloud (natively on OCI, it can run inside AWS, you can setup a private interconnection for Microsoft Azure, and there are works in progress for Google Cloud).
HeatWave is based on a massively parallel architecture which uses partitioning of data: each CPU core within a node processes the partitioned data in parallel.
Driven by Machine Learning algorithms, HeatWave Autopilot offers several features such as:
- Improvements in terms of performance and scalability
- Provisioning, data loading, query execution and fault management automation, to reduce human errors.
Finally, according to Oracle, with HeatWave you will have best performances and lowest costs rather than competitors: Snowflake, Amazon Redshift, Google BigQuery and Databricks.

Building Next-Gen Applications with Generative AI & Vector Store (by Adi Hochmann)
As we said, Oracle HeatWave allows you to manage together all your OLTP, OLAP, Machine Learning and GenAI workloads.
Steps to build a GenAI application are the following ones:
- Create a vector store
- Use vector store with LLMs
And this is performed using the following routines:
call sys.HEATWAVE_LOAD (…);
call sys.ML_RAG(@query,@output,@options);
But how to train data for Machine Learning? The process and tasks done by a data analyst could be complex and this is replaced here by the AutoML:
CALL sys.ML_TRAIN(‘data_source’, ‘model_type’, JSON_OBJECT(‘task’, ‘classification’), @result_model);
This is useful for some use-cases such as classification, anomalies detection, recommendations, predictive maintenance, …
Additional tip: Adi used MySQL Shell for VS Code to run his demo. This extension enables interactive editing and execution of SQL for MySQL databases and MySQL Database Service. It integrates the MySQL shell directly into VS Code development workflows and it’s pretty nice!

Oracle Cloud for Digital Natives: Supporting Innovation and Growth (by Claire Binder)
Which are the 5 reasons why Digital Natives picked OCI?
- Developer-First openness and flexibility, to speed acquisition
- Advanced Data & AI Services, to achieve innovation and agility
- Technical and global reach, to achieve scalability
- Security, compliance and resilience, to control risks
- Cost efficiency and TCO, to achieve optimized spending.
Linked to the point 4, there are several services in OCI to avoid data breaches in terms of prevention, monitoring, mitigation, protection, encryption and access.
To select a Cloud provider, the recommendation would be to choose a solution which allows you to run converged open SQL databases, instead of single-use proprietary databases.
And finally, Oracle brings AI to your data with his new 23ai release and some of its features, such as Property Graphs and AI Vector Search.

Analytics at the speed of thoughts with HeatWave Lakehouse (by Nitin Kunal)
What is a Data Lake? It’s a cost efficient, scalable, online storage of data as file (for instance, Object Store). Data are not structured and non-transactional and can be sourced from Big Data frameworks.
Again, you could have 4 different platforms to maintain:
- Your RDBMS
- A DWH system for analytics processing
- A Data Lake
- A ML & Gen-AI system.
Instead of that, your can merge everything in only one platform: HeatWave. And you can query near real time data with HeatWave Lakehouse because new data is available in seconds: that’s great!

Conclusion
- If you have mixed workloads, if you start to work with AI and if you want to improve your performances, it is really worth taking a look at Oracle HeatWave. You can try it here for free.
- We all know that AI is the future. These next years, we’ll be more and more challenged on GenAI, ML, vector processing and so on. With all this innovation, we must not lose sight of topics that remain crucial (and perhaps become even more important) such as security, reliability, availability, and best practices. With dbi services and Sequotech we can for sure help you with this transition.
L’article Oracle Technology Roundtable for Digital Natives – Let’s have a look at AI, Cloud and HeatWave est apparu en premier sur dbi Blog.
M-Files Property Calculator

M-Files is a powerful product in itself, that enables businesses to organize, manage, and track documents efficiently.
But we can even make it more powerful by extending the out of the box capabilities with Property Calculator, a really useful tool.
Previously available unofficially (community tools) we can now find it in the M-Files catalog (here) and it’s free of charge!
As M-Files always focuses on automate knowledge work, it makes clearly sense to extend the capabilities thought PC (Property Calculator).
M-Files Property Calculator allows users to automate property values and enhance metadata consistency within the system. It provides a way to manipulate objects based on rules without writing any line of code.
With this tool, users can perform calculations, concatenate text fields, extract values, and even apply conditional logic to metadata properties. This functionality is particularly useful in scenarios where document classification, numbering, or status updates need to be automated.
- Automated Property Calculations
The Property Calculator allows users to define formulas that automatically populate metadata fields based on predefined criteria. For example, an invoice document can have its total amount calculated based on line items and tax rates. - Concatenation and String Manipulation
Users can combine multiple metadata fields into a single property. This is useful for creating standardized naming conventions or reference numbers. - Conditional Logic for Metadata
With the ability to implement IF-THEN conditions, users can dynamically adjust property values. For example, if a document is marked as “Approved,” the status property can automatically update to “Final.” - Date and Time Calculations
Organizations can set up date-based calculations, such as automatically setting an expiration date based on the document creation date. - Reference-Based Updates
The calculator can pull information from related objects, ensuring consistency across interlinked documents and reducing manual updates.
You know, I’m in love with M-Files, but with PC we bring again more advantages, reduce manual actions and automatically decrease the potential human errors. But also save time for the users and avoid repetitive metadata filling. Without forgetting, increasing consistency and compliance ensuring that all the necessary document properties are properly populated and up to date.

The M-Files Property Calculator is an indispensable tool for organizations looking to enhance their document management processes through automation. By leveraging its capabilities, businesses can improve efficiency, maintain data accuracy, and streamline compliance efforts.
If you’re not yet using this feature, now is the time to explore its potential and transform how your organization handles metadata within M-Files.
For more information feel free to contact us
L’article M-Files Property Calculator est apparu en premier sur dbi Blog.
PostgreSQL: Unlogged tables and backups
Recently we faced the following situation and have been asked to analyze the issue: A dump was loaded into a primary instance of PostgreSQL, but the data did not reach the replica. Tables which have been added after the dump was loaded, however made it to the replica. After going through the logs it quickly became clear that the reason for this was, that the tables were create as unlogged.
To demonstrate what happens in that case we can easily create a simple test case:
postgres=# create unlogged table t ( a int );
CREATE TABLE
postgres=# insert into t select * from generate_series(1,1000000);
INSERT 0 1000000
postgres=# select count(*) from t;
count
---------
1000000
(1 row)
This is one simple unlogged table containing one million row. Let’s create a backup of that and start a new instance from that backup:
postgres@pgbox:/home/postgres/ [pgdev] mkdir /var/tmp/xx
postgres@pgbox:/home/postgres/ [pgdev] pg_basebackup --checkpoint=fast --pgdata=/var/tmp/xx
postgres@pgbox:/home/postgres/ [pgdev] echo "port=8888" >> /var/tmp/xx/postgresql.auto.conf
postgres@pgbox:/home/postgres/ [pgdev] chmod 700 /var/tmp/xx/
postgres@pgbox:/home/postgres/ [pgdev] pg_ctl --pgdata=/var/tmp/xx/ start
Now we have a new instance which should be an exact copy of the source instance. The surprise comes once we check the table we’ve created:
postgres@pgbox:/home/postgres/ [pgdev] psql -p 8888
psql (18devel)
Type "help" for help.
postgres=# select count(*) from t;
count
-------
0
(1 row)
The table is there, but it does not contain any rows. Exactly the same happens when you have a replica. This is also clearly stated in the documentation. When you go for unlogged tables, you must be aware of the consequences. If you skip WAL logging this makes those tables faster than ordinary tables, but this also comes with downsides.
If you dump those tables, you’ll have the data:
postgres@pgbox:/home/postgres/ [pgdev] pg_dump > a.sql
postgres@pgbox:/home/postgres/ [pgdev] grep -A 2 COPY a.sql
COPY public.t (a) FROM stdin;
1
2
But please keep in mind: A dump is not a real backup and you cannot use it for point in time recovery.
L’article PostgreSQL: Unlogged tables and backups est apparu en premier sur dbi Blog.
Starting with PowerShell 7 and parallelization
For the time being Windows PowerShell 5.1 is installed with Windows Server. It means that if you want to use or even test PowerShell 7 you need to install it by your own.
To be honest, even if I’m using PowerShell as a DBA more or less every day, I did not take too much care of PowerShell 7 until I used it at a customer place with a new parallelization functionality that we will discuss later on.
For reminder, PowerShell 7 is an open-source and cross-platform edition of PowerShell. It means that it can be used on Windows platforms but also on MacOS or Linux.
The good point is that you can install it without removing Windows PowerShell 5.1. Both version can cohabit because of:
- Separate installation path and executable name
- path with 5.1 like $env:WINDIR\System32\WindowsPowerShell\v1.0
- path with 7 like $env:ProgramFiles\PowerShell\7
- executable with PowerShell 5.1 is powershell.exe and with PowerShell 7 is pwsh.exe
- Separate PSModulePath
- Separate profiles for each version
- path with 5.1 is $HOME\Documents\WindowsPowerShell
- path with 7 is $HOME\Documents\PowerShell
- Improved module compatibility
- New remoting endpoints
- Group policy support
- Separate Event logs
To install PowerShell 7 on Windows Servers the easiest way is to use a MSI package. The last version to download is the 7.5.0. Once downloaded, double click the msi file and follow the installation:
By default and as mentioned previously, PowerShell 7 will be installed on C:\Program Files\PowerShell\ :
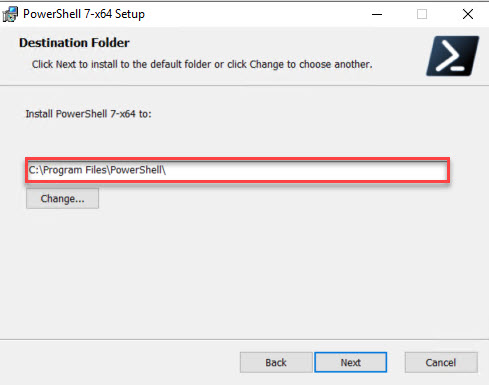
Some customization are possible, we will keep the default selections:
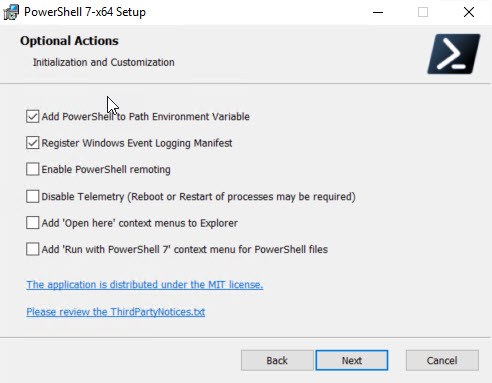
Starting with PowerShell 7.2, it is possible to update PowerShell 7 with traditional Microsoft Update:
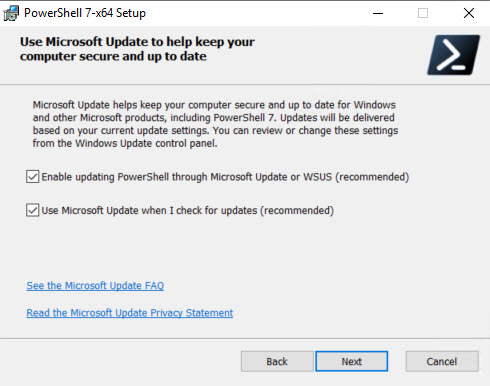
After some seconds installation is done:
We can start the PowerShell 7 with the cmd pwsh.exe. As we can see below both versions coexist on my Windows Server:
 New features
New features
PowerShell 7 introduces some interesting new features compare to PowerShell 5.
- ForEach-Object with parallel execution
Execute the script block in parallel for each object. A parameter ThrottleLimit limits the number of script blocks running at the same time, default value is 5.
Here we search the instance properties by server and limit the parallelization to 2 server at the same time.
$computers = ‘thor90′,’thor91′,’thor10′,’thor11’
$InstanceProperties = $computers | ForEach-Object -Parallel {
$instances = (Find-DbaInstance -ComputerName $_).SqlInstance;
Get-DbaInstanceProperty -SqlInstance $instances
} -ThrottleLimit 2 - Ternary operator
A simplified if-else statement with <condition> ? <condition true> : <condition false> - Pipeline chain operators
The && operator executes the right-hand pipeline, if the left-hand pipeline succeeded. Reverse, the || operator executes the right-hand pipeline if the left-hand pipeline failed. - coalescence, assignment and conditional operators
PowerShell 7 includes Null coalescing operator ??, Null conditional assignment ??=, and Null conditional member access operators ?. and ?[] - New management of error message and new cmdlet Get-Error
This new cmdlet Get-Error displays the full detailed of the last error with inner exceptions.
A parameter Newest allows to select the number of error you would like to display
On this blog, post I would to concentrate to the parallelization with the ForEach-Object -Parallel
PowerShell 7 parallelizationThis new feature comes with the know ForEach-Object cmdlet which performs an operation on each item in a collection of input objects.
Starting with PowerShell 7.0 a new parameter set, called “Parallel”, gives the possibility to run each script block in parallel instead of sequentially. The “ThrottleLimit” parameter, if used, limits the number of script blocks which will run at the same time, if it is not specified the default value is 5.
ForEach-Object -Parallel <scriptblock> -ThrottleLimit
We can test this new feature with a small example.
If we execute the following script as before, the script block is executed sequentially:
PS C:\Users\administrator.ADSTS> 1..16 | ForEach-Object { Get-Date; sleep 10 }
Friday, February 14, 2025 9:00:02 AM
Friday, February 14, 2025 9:00:12 AM
Friday, February 14, 2025 9:00:22 AM
Friday, February 14, 2025 9:00:32 AM
Friday, February 14, 2025 9:00:42 AM
Friday, February 14, 2025 9:00:52 AM
Friday, February 14, 2025 9:01:02 AM
Friday, February 14, 2025 9:01:12 AM
Friday, February 14, 2025 9:01:22 AM
Friday, February 14, 2025 9:01:32 AM
Friday, February 14, 2025 9:01:42 AM
Friday, February 14, 2025 9:01:52 AM
Friday, February 14, 2025 9:02:02 AM
Friday, February 14, 2025 9:02:12 AM
Friday, February 14, 2025 9:02:22 AM
Friday, February 14, 2025 9:02:32 AMEach line as 10 seconds more than the previous one.
But, if we execute this script with the new parameter Parallel and use a throttle limit of 4 we have:
PS C:\Users\administrator.ADSTS> 1..16 | ForEach-Object -Parallel { Get-Date; sleep 10 } -ThrottleLimit 4
Friday, February 14, 2025 8:59:01 AM
Friday, February 14, 2025 8:59:01 AM
Friday, February 14, 2025 8:59:01 AM
Friday, February 14, 2025 8:59:01 AM
Friday, February 14, 2025 8:59:11 AM
Friday, February 14, 2025 8:59:11 AM
Friday, February 14, 2025 8:59:11 AM
Friday, February 14, 2025 8:59:11 AM
Friday, February 14, 2025 8:59:21 AM
Friday, February 14, 2025 8:59:21 AM
Friday, February 14, 2025 8:59:21 AM
Friday, February 14, 2025 8:59:21 AM
Friday, February 14, 2025 8:59:31 AM
Friday, February 14, 2025 8:59:31 AM
Friday, February 14, 2025 8:59:31 AM
Friday, February 14, 2025 8:59:31 AMHere we have 4 groups of 4 lines with the same time as we executed the script block in parallel with limitation of the parallelization to 4.
Of course, the different commands included in the script block are executed sequentially.
This feature uses the PowerShell runspaces to execute script blocks in parallel.
Variables can be passed into the script block with the $using: keyword, the only variable automatically passed is the pipe object.
Each runspace will execute a script block in a thread, so the ThrottleLimit parameter needs to be set according to the number of core of the server where you are running. If you VM has 2 cores, it makes no sense to put the limit to 4…
This new script will execute a maintenance job on different instances of the same server, passing the job name in the block script with the $using: keyword:
PS C:\Users\administrator.ADSTS> $ThrottleLimit = 2
PS C:\Users\administrator.ADSTS> $JobName = 'DBI_MAINTENANCE_MAINTENANCE_USER_DATABASES'
PS C:\Users\administrator.ADSTS> $computers = 'thor90'
PS C:\Users\administrator.ADSTS> $SqlInstances = Find-DbaInstance -ComputerName $computers -EnableException
PS C:\Users\administrator.ADSTS> $SqlInstances
ComputerName InstanceName SqlInstance Port Availability Confidence ScanTypes
------------ ------------ ----------- ---- ------------ ---------- ---------
thor90 CMS thor90\CMS 50074 Available High Default
thor90 SQL16_1 thor90\SQL16_1 62919 Available High Default
thor90 SQL19_1 thor90\SQL19_1 1433 Available High Default
thor90 SQL22_1 thor90\SQL22_1 50210 Available High Default
thor90 MSSQLSERVER thor90 1434 Available High Default
PS C:\Users\administrator.ADSTS> $SqlInstances | ForEach-Object -Parallel {
>> $Out = "Starting Job on $using:JobName [" + $_.SqlInstance + "]"
>> Write-Host $Out
>> $res = Start-DbaAgentJob -SqlInstance $_.SqlInstance -Job $using:JobName -Wait
>> } -ThrottleLimit $ThrottleLimit
Starting Job on DBI_MAINTENANCE_MAINTENANCE_USER_DATABASES [thor90\CMS]
Starting Job on DBI_MAINTENANCE_MAINTENANCE_USER_DATABASES [thor90\SQL16_1]
Starting Job on DBI_MAINTENANCE_MAINTENANCE_USER_DATABASES [thor90\SQL19_1]
Starting Job on DBI_MAINTENANCE_MAINTENANCE_USER_DATABASES [thor90\SQL22_1]
Starting Job on DBI_MAINTENANCE_MAINTENANCE_USER_DATABASES [thor90]
PS C:\Users\administrator.ADSTS>We use this kind of script at a customer place to execute SQL Server Agent Jobs in parallel on instances of a big physical servers with more than 10 instances.
ConclusionThis PowerShell 7 parallelization feature can improve performance in lots of different scenarios. But test it and don’t think that because of parallelization all your scripts will be executed quickly as running a script in parallel adds some overhead which will decrease execution of trivial script.
L’article Starting with PowerShell 7 and parallelization est apparu en premier sur dbi Blog.
pg_mooncake: (another) Columnar storage for PostgreSQL
A very, very long time ago I’ve written a blog about cstore_fdw, which brings columnar storage to PostgreSQL. This is now part of Citus and does not anymore come as a separate extension. While this still can be used there is another option if you’re looking for columnar storage in PostgreSQL, and this is pg_mooncake. The goal of this extension is to optimize PostgreSQL for analytics and stores the tables in Iceberg or Delta Lake format, either on local disk or on cloud storage such as s3.
Getting the extension onto the system is pretty simple and straight forward (as you can see below it uses DuckDB in the background), but it will take some time to compile and you need to have Cargo installed for this to succeed:
postgres@pgbox:/home/postgres/ [172] which pg_config
/u01/app/postgres/product/17/db_2/bin/pg_config
postgres@pgbox:/home/postgres/ [172] git clone https://github.com/Mooncake-Labs/pg_mooncake.git
Cloning into 'pg_mooncake'...
remote: Enumerating objects: 1085, done.
remote: Counting objects: 100% (533/533), done.
remote: Compressing objects: 100% (250/250), done.
remote: Total 1085 (delta 406), reused 284 (delta 283), pack-reused 552 (from 2)
Receiving objects: 100% (1085/1085), 728.27 KiB | 3.98 MiB/s, done.
Resolving deltas: 100% (631/631), done.
postgres@pgbox:/home/postgres/ [172] cd pg_mooncake/
postgres@pgbox:/home/postgres/pg_mooncake/ [172] git submodule update --init --recursive
Submodule 'third_party/duckdb' (https://github.com/duckdb/duckdb.git) registered for path 'third_party/duckdb'
Cloning into '/home/postgres/pg_mooncake/third_party/duckdb'...
Submodule path 'third_party/duckdb': checked out '19864453f7d0ed095256d848b46e7b8630989bac'
postgres@pgbox:/home/postgres/pg_mooncake/ [172] make release -j2
...
[ 23%] Building CXX object src/common/types/column/CMakeFiles/duckdb_common_types_column.dir/ub_duckdb_common_types_column.cpp.o
[ 23%] Built target duckdb_common_types_column
[ 23%] Building CXX object src/common/types/row/CMakeFiles/duckdb_common_types_row.dir/ub_duckdb_common_types_row.cpp.o
[ 23%] Built target duckdb_common_types_row
[ 23%] Building CXX object src/common/value_operations/CMakeFiles/duckdb_value_operations.dir/ub_duckdb_value_operations.cpp.o
[ 23%] Built target duckdb_common_types
...
postgres@pgbox:/home/postgres/pg_mooncake/ [172] make install
/usr/bin/mkdir -p '/u01/app/postgres/product/17/db_2/lib'
/usr/bin/mkdir -p '/u01/app/postgres/product/17/db_2/share/extension'
/usr/bin/mkdir -p '/u01/app/postgres/product/17/db_2/share/extension'
/usr/bin/mkdir -p '/u01/app/postgres/product/17/db_2/lib'
/usr/bin/install -c -m 755 pg_mooncake.so '/u01/app/postgres/product/17/db_2/lib/pg_mooncake.so'
/usr/bin/install -c -m 644 .//../../pg_mooncake.control '/u01/app/postgres/product/17/db_2/share/extension/'
/usr/bin/install -c -m 644 .//../../sql/pg_mooncake--0.1.0.sql .//../../sql/pg_mooncake--0.1.0--0.1.1.sql .//../../sql/pg_mooncake--0.1.1--0.1.2.sql '/u01/app/postgres/product/17/db_2/share/extension/'
/usr/bin/install -c -m 755 libduckdb.so '/u01/app/postgres/product/17/db_2/lib/'
On this is compiled and installed simply add the extension to a database:
postgres=$ create extension pg_mooncake;
CREATE EXTENSION
postgres=$ \dx
List of installed extensions
Name | Version | Schema | Description
--------------------+---------+------------+------------------------------------------------------------------------
pg_mooncake | 0.1.2 | public | Columnstore Table in Postgres
pg_stat_statements | 1.11 | public | track planning and execution statistics of all SQL statements executed
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(3 rows)
To compare this table layout against the standard PostgreSQL layout, let’s create two tables, one of them using the column store format:
postgres=# create table t1 ( a int, b text );
CREATE TABLE
postgres=# create table t2 ( a int, b text ) using columnstore;
CREATE TABLE
postgres=# \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+---------+-----------+----------+---------+----------+-------------+--------------+-------------
a | integer | | | | plain | | |
b | text | | | | extended | | |
Access method: heap
postgres=# \d+ t2
Table "public.t2"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+---------+-----------+----------+---------+----------+-------------+--------------+-------------
a | integer | | | | plain | | |
b | text | | | | extended | | |
Access method: columnstore
Adding a millions rows to both of the tables:
postgres=# insert into t1 select i, md5(i::text) from generate_series(1,1000000) i;
INSERT 0 1000000
postgres=# insert into t2 select i, md5(i::text) from generate_series(1,1000000) i;
INSERT 0 1000000
Looking at the disk we can see the first surprise:
postgres=# select pg_relation_filepath('t1');
pg_relation_filepath
----------------------
base/5/24715
(1 row)
postgres=# select pg_relation_filepath('t2');
pg_relation_filepath
----------------------
base/5/24718
(1 row)
postgres=# select pg_size_pretty ( pg_relation_size ( 't1' ));
pg_size_pretty
----------------
65 MB
(1 row)
postgres=# select pg_size_pretty ( pg_relation_size ( 't2' ));
pg_size_pretty
----------------
0 bytes
(1 row)
The table in columnar format reports a size of zero bytes, and indeed there is not even a file on disk which corresponds to 24718:
postgres=# \! ls -la $PGDATA/base/5/24715
-rw-------. 1 postgres postgres 68272128 Feb 24 14:19 /u02/pgdata/17/base/5/24715
postgres=# \! ls -la $PGDATA/base/5/24718
ls: cannot access '/u02/pgdata/17/base/5/24718': No such file or directory
Instead the table is stored here as Parquet files:
postgres@pgbox:/u02/pgdata/17/ [172] ls -la $PGDATA/mooncake_local_tables/mooncake_postgres_t2_24708/
total 107224
drwx------. 3 postgres postgres 180 Feb 24 14:31 .
drwx------. 3 postgres postgres 40 Feb 24 14:15 ..
-rw-------. 1 postgres postgres 36596064 Feb 24 14:19 560c6efe-1226-4a76-985f-1301169bcc44.parquet
-rw-------. 1 postgres postgres 36596064 Feb 24 14:18 ca0550d6-bd84-4bf9-b8cf-6ce85a65346b.parquet
drwx------. 2 postgres postgres 4096 Feb 24 14:19 _delta_log
-rw-------. 1 postgres postgres 36596064 Feb 24 14:19 fba0eff4-3c57-4dbb-bd9b-469f6622ab92.parquet
Here is more detailed blog about the design decisions.
The difference is also visible when you look at the explain plans against both tables:
postgres=# explain (analyze) select * from t1 where a = 1;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..14542.43 rows=1 width=37) (actual time=1.591..41.014 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on t1 (cost=0.00..13542.33 rows=1 width=37) (actual time=0.022..11.067 rows=0 loops=3)
Filter: (a = 1)
Rows Removed by Filter: 333333
Planning Time: 0.861 ms
Execution Time: 41.086 ms
(8 rows)
postgres=# explain (analyze) select * from t2 where a = 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Custom Scan (MooncakeDuckDBScan) (cost=0.00..0.00 rows=0 width=0) (actual time=7.797..7.816 rows=1 loops=1)
DuckDB Execution Plan:
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Query Profiling Information ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
EXPLAIN ANALYZE SELECT a, b FROM pgmooncake.public.t2 WHERE (a = 1)
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 0.0043s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ EXPLAIN_ANALYZE │
│ ──────────────────── │
│ 0 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ COLUMNSTORE_SCAN │
│ │
│ Projections: │
│ a │
│ b │
│ │
│ Filters: │
│ a=1 AND a IS NOT NULL │
│ │
│ 1 Rows │
│ (0.00s) │
└───────────────────────────┘
Planning Time: 1.693 ms
Execution Time: 8.584 ms
(43 rows)
As usual with columnar data storage, is is best when you have data which can be compressed well on a columnar basis, e.g.:
postgres=# truncate t1,t2;
TRUNCATE TABLE
postgres=# insert into t1 select 1, md5(i::text) from generate_series(1,1000000) i;
INSERT 0 1000000
Time: 852.812 ms
postgres=# insert into t2 select 1, md5(i::text) from generate_series(1,1000000) i;
INSERT 0 1000000
Time: 243.532 ms
The insert into the t2 is consistently faster than the insert into the standard tables (just repeat the inserts multiple times to get an idea). The same happens when you read columns which are compressed well (same here, just repeat the query multiple times to get an idea):
postgres=# select count(a) from t1;
count
---------
2000000
(1 row)
Time: 60.463 ms
postgres=# select count(a) from t2;
count
---------
2000000
(1 row)
Time: 10.272 ms
This might be an option if you have use cases for this.
L’article pg_mooncake: (another) Columnar storage for PostgreSQL est apparu en premier sur dbi Blog.