

Susan Duncan
Filtering the Muddy Waters of ALM, Team Development, Database and Oracle ADF in JDeveloper
Updated: 3 weeks 6 days ago
Fine tuning your logical to physical DB transform
When you use JDeveloper's class modeler to design your logical database you are able to run the DB Transform to get a physical DB model. But have you ever been frustrated at the limitations of the transform? for instance -
There is a section in Part2 of the tutorial Using Logical Models in UML for Database Development that details using the DB Profile, so I will not repeat the whole story here, but give you a flavour of the capabilities. Once you've applied the profile to the UML package of your class diagram you can set stereotypes against any element in your diagram. In the image below you are looking at the stereotype properties of the empno attribute - that will become a column in the database. Note that this column is to be used as the primary key on the table. Also note the list of Oracle and non-Oracle datatypes listed. Here you can specify exactly how empno should be transformed when multiple physical databases may be required. If the property for any of these is not set then the default transform will be applied.
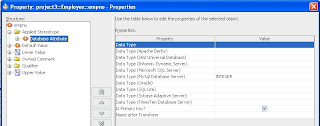 You could say that having this ability as part of the class model bridges the gap between this model (being used as a logical DB model) and the tranformed physical database model - it provides some form of relative model capability.
You could say that having this ability as part of the class model bridges the gap between this model (being used as a logical DB model) and the tranformed physical database model - it provides some form of relative model capability.
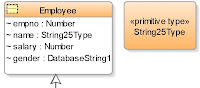 Looking at another new feature in 11.1.2.0, the extract right shows other elements on the class diagram. I've created a primitive type (String25Type) and using the stereotype have specified how this type should be transformed. Now I can use that type on different classes in my diagram and the transformer will use it as necessary.
Looking at another new feature in 11.1.2.0, the extract right shows other elements on the class diagram. I've created a primitive type (String25Type) and using the stereotype have specified how this type should be transformed. Now I can use that type on different classes in my diagram and the transformer will use it as necessary.
There are many other ways to fine tune your transform, run through the tutorial and try them for yourself
- name to be used for the physical table
- attribute to be used as the PK column
- datatype and settings to be applied to a specific attribute
- foreign key or intersection column names
- different datatypes to be created for different database types
There is a section in Part2 of the tutorial Using Logical Models in UML for Database Development that details using the DB Profile, so I will not repeat the whole story here, but give you a flavour of the capabilities. Once you've applied the profile to the UML package of your class diagram you can set stereotypes against any element in your diagram. In the image below you are looking at the stereotype properties of the empno attribute - that will become a column in the database. Note that this column is to be used as the primary key on the table. Also note the list of Oracle and non-Oracle datatypes listed. Here you can specify exactly how empno should be transformed when multiple physical databases may be required. If the property for any of these is not set then the default transform will be applied.
 You could say that having this ability as part of the class model bridges the gap between this model (being used as a logical DB model) and the tranformed physical database model - it provides some form of relative model capability.
You could say that having this ability as part of the class model bridges the gap between this model (being used as a logical DB model) and the tranformed physical database model - it provides some form of relative model capability.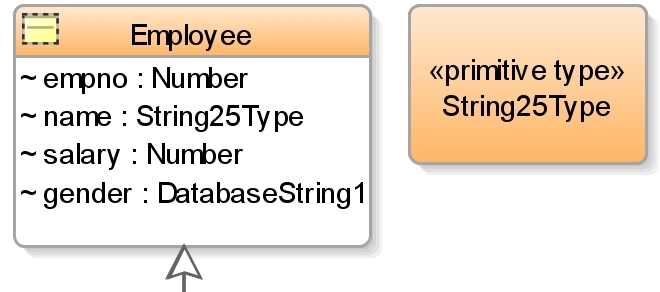 Looking at another new feature in 11.1.2.0, the extract right shows other elements on the class diagram. I've created a primitive type (String25Type) and using the stereotype have specified how this type should be transformed. Now I can use that type on different classes in my diagram and the transformer will use it as necessary.
Looking at another new feature in 11.1.2.0, the extract right shows other elements on the class diagram. I've created a primitive type (String25Type) and using the stereotype have specified how this type should be transformed. Now I can use that type on different classes in my diagram and the transformer will use it as necessary.There are many other ways to fine tune your transform, run through the tutorial and try them for yourself
Hudson and me!
Over the past months I've been working more and more with Hudson, the continuous integration server. If you're familiar with Hudson then no doubt you are familiar with the changes that faced it in that time. If you're not - well, it's a long, well-documented story in the press and I will not bore you with it here!
But the most important thing is that Hudson is a great (free) continuous integration tool and continues to grow in popularity and status. Oracle became its supported from Sun's original open source project. As well as its community of users and developers Oracle has a full-time team working on it, including me as Product Manager, and it recently started the process of moving to the Eclipse Foundation as a top-level project.
Internally we use Hudson across the organization for all manner of build and test jobs and I know that many of you do too.
In JDeveloper 11.1.2 we've added new features to Team Productivity Center (TPC) to integrate Hudson (or Cruise Control) build/test results into the IDE and relate those to code checkins via the TPC work items. You can see a quick demo of that here
If you use Hudson I'd like to hear from you - in fact, I'd like to hear from you anyway! So please contact me at the usual Oracle address. Other ways to keep up with Hudson are through its mailing lists, wiki and of course twitter - @hudsonci
But the most important thing is that Hudson is a great (free) continuous integration tool and continues to grow in popularity and status. Oracle became its supported from Sun's original open source project. As well as its community of users and developers Oracle has a full-time team working on it, including me as Product Manager, and it recently started the process of moving to the Eclipse Foundation as a top-level project.
Internally we use Hudson across the organization for all manner of build and test jobs and I know that many of you do too.
In JDeveloper 11.1.2 we've added new features to Team Productivity Center (TPC) to integrate Hudson (or Cruise Control) build/test results into the IDE and relate those to code checkins via the TPC work items. You can see a quick demo of that here
If you use Hudson I'd like to hear from you - in fact, I'd like to hear from you anyway! So please contact me at the usual Oracle address. Other ways to keep up with Hudson are through its mailing lists, wiki and of course twitter - @hudsonci
After all these years I've finally got
After all these years I've finally got my first major article published in the ODTUG Technical Journal. I'm really excited as it's about Database Design Using JDeveloper - from Logical to Physical modeling and more. This is not a topic that normally attracts that much attention outside of those of us who know all about its merits so I'm especially happy.
And just like buses, you wait ages for one and then two come at once (if you're outside the UK this might not mean much to you!) I'm now writing a second deep dive into JDeveloper's Logical modeling, and some fantastic new features that are coming your way, for the next quarterly issue due out around the time of Kaleidoscope, the ODTUG conference. Unfortunately I am not able to attend this year, but if you happen to be Long Beach Way in June - you should try and make it.
And just like buses, you wait ages for one and then two come at once (if you're outside the UK this might not mean much to you!) I'm now writing a second deep dive into JDeveloper's Logical modeling, and some fantastic new features that are coming your way, for the next quarterly issue due out around the time of Kaleidoscope, the ODTUG conference. Unfortunately I am not able to attend this year, but if you happen to be Long Beach Way in June - you should try and make it.
Converting a CVS repository to SVN
I've recently gone through this with an old CVS repository we have. We wanted to keep the history but not the CVS repository. I used cvs2svn from tigris.org with great success.
This converter actually converts from CVS to many different repositories including git. It offers many options for conversion - I created an SVN dumpfile but you can also convert directly into an existing or a new SVN repository.
I chose to use the options file to run my conversion - so I could play with the different options, do dry-runs, adjust what output I needed etc. Here are some of the settings I used from the cvs2svn-example.options file that comes with the converter
ctx.output_option = DumpfileOutputOption(
dumpfile_path=r'/cvs2svn-susan-output/cvs2svn-dump1', # Name of dumpfile to create
#author_transforms=author_transforms,
)
### to output conversion to a dump file
ctx.dry_run = False ### always a good idea to do a dry run!
ctx.trunk_only ####I decided not to bring over any branches and tags
run_options.add_project(
r'/cvs-copy', ##### to specify the repos project to be converted
trunk_path='trunk',
branches_path='branches',
tags_path='tags',
.........)
For my conversion I didn't need to use many of the other possible options such as mapping author names and symbol handling. I was confident that, as I had used JDeveloper to populate my CVS repository, this had been handled for me. For instance, I didn't need to do a lot of prepping of my CVS repository to ensure that my binary files had been correctly added to the repository. This can be a problem as CVS and SVN handle them differently. The documentation at Tigris and the options file are very detailed in how to handle these potential issues.
and that's really all there was - just run the converter and point to the options file
This converter actually converts from CVS to many different repositories including git. It offers many options for conversion - I created an SVN dumpfile but you can also convert directly into an existing or a new SVN repository.
I chose to use the options file to run my conversion - so I could play with the different options, do dry-runs, adjust what output I needed etc. Here are some of the settings I used from the cvs2svn-example.options file that comes with the converter
ctx.output_option = DumpfileOutputOption(
dumpfile_path=r'/cvs2svn-susan-output/cvs2svn-dump1', # Name of dumpfile to create
#author_transforms=author_transforms,
)
### to output conversion to a dump file
ctx.dry_run = False ### always a good idea to do a dry run!
ctx.trunk_only ####I decided not to bring over any branches and tags
run_options.add_project(
r'/cvs-copy', ##### to specify the repos project to be converted
trunk_path='trunk',
branches_path='branches',
tags_path='tags',
.........)
For my conversion I didn't need to use many of the other possible options such as mapping author names and symbol handling. I was confident that, as I had used JDeveloper to populate my CVS repository, this had been handled for me. For instance, I didn't need to do a lot of prepping of my CVS repository to ensure that my binary files had been correctly added to the repository. This can be a problem as CVS and SVN handle them differently. The documentation at Tigris and the options file are very detailed in how to handle these potential issues.
and that's really all there was - just run the converter and point to the options file
cvs2svn --options=MYOPTIONSFILEI then created a new Remote Directory in my target SVN repository using JDeveloper's Versioning Navigator and ran the standard load utility on the command line to add my converted CVS repository to my existing SVN repository.
svnadmin load /svn/mySVNrepository/ --parent-dir mynewSVN_dir < /cvs2svn-dump1A check that my workspaces checked out correctly and that I could see my image files and I was done (sorry to all my QA colleagues who want more testing mentioned than this!)
Tortoise and JDeveloper
Recently I discovered a new setting that could trip you up if you are using both TortoiseSVN and JDeveloper to access your SVN repository from an OTN forum post.
If you are finding that you can't see the overlays on your JDeveloper project files or that some of the menu items are not enabled - make sure that in your TortoiseSVN settings you have unchecked Use "_svn" instead of ".svn"
Anyone got any other tips for using both tools?
If you are finding that you can't see the overlays on your JDeveloper project files or that some of the menu items are not enabled - make sure that in your TortoiseSVN settings you have unchecked Use "_svn" instead of ".svn"
Anyone got any other tips for using both tools?
Filtering Your DB Objects in the Application Navigator
I'm working with a customer who is using JDeveloper to manage his database object defintions. He has created an offline database by reverse engineering his very large database and uses our built-in integration with SCM systems (Perforce in this case) to version those objects and manage them at the object level.
Because he has such a large number of objects I've been thinking of ways for him to view the objects he wants to see and work with more quickly.
To illustrate this post I'm using an offline database I'm working on at the moment. And as you know me (read the post - 8 Things You Didn't Know About Me) you wont be surprised to see that Blues features strongly!
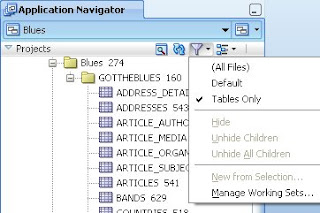
So, how can I view my offline database objects? First, utilising the Navigator Display Options. I can quickly go from an alpha- listing of my objects to listing them by object type by simply deselecting the Sort by Type option.
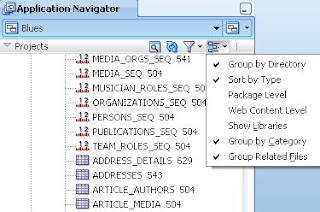
Alternatively I can use Working Sets to filter out object types. In this example I'm hiding sequences and triggers by adding a File Filter to hide the other database object types (in my example I only have tables, sequences and triggers currently). With this in place I can see that the files to be displayed are as I want them.
to filter out object types. In this example I'm hiding sequences and triggers by adding a File Filter to hide the other database object types (in my example I only have tables, sequences and triggers currently). With this in place I can see that the files to be displayed are as I want them.
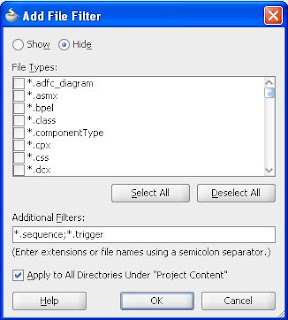
 Finally, I've saved this working set as 'Tables Only'. I can now go on and develop my Working Sets to cover other listing that are appropriate to my model. This could mean filtering files by name, folder or by type.
Finally, I've saved this working set as 'Tables Only'. I can now go on and develop my Working Sets to cover other listing that are appropriate to my model. This could mean filtering files by name, folder or by type.
Working sets were initially developed for filtering large Java EE applications, but work equally well in the database domain
Because he has such a large number of objects I've been thinking of ways for him to view the objects he wants to see and work with more quickly.
To illustrate this post I'm using an offline database I'm working on at the moment. And as you know me (read the post - 8 Things You Didn't Know About Me) you wont be surprised to see that Blues features strongly!
So, how can I view my offline database objects? First, utilising the Navigator Display Options. I can quickly go from an alpha- listing of my objects to listing them by object type by simply deselecting the Sort by Type option.

Alternatively I can use Working Sets
 to filter out object types. In this example I'm hiding sequences and triggers by adding a File Filter to hide the other database object types (in my example I only have tables, sequences and triggers currently). With this in place I can see that the files to be displayed are as I want them.
to filter out object types. In this example I'm hiding sequences and triggers by adding a File Filter to hide the other database object types (in my example I only have tables, sequences and triggers currently). With this in place I can see that the files to be displayed are as I want them.
 Finally, I've saved this working set as 'Tables Only'. I can now go on and develop my Working Sets to cover other listing that are appropriate to my model. This could mean filtering files by name, folder or by type.
Finally, I've saved this working set as 'Tables Only'. I can now go on and develop my Working Sets to cover other listing that are appropriate to my model. This could mean filtering files by name, folder or by type.Working sets were initially developed for filtering large Java EE applications, but work equally well in the database domain
Making Merge, Revert and Branching Easier with SVN
In the latest release of JDeveloper (11.1.1.2.0) we've added new declarative UIs to help simplify those most crucial and complex of SVN tasks - Merging and Branching. These SVN operations can be tricky. They involve ensuring that you pick the correct location in your repository, the correct revision, and mistakes can be costly and time consuming to fix.
Take a look at the wizard below. This is available whether you choose Merge Working Copy or if you want to Merge a single file. My top tip is that you should almost always use Merge Working Copy, especially if you are working with ADF (Application Development Framework) as many of the XML metadata files for your application will have dependencies on Java files and ending up with missed or out of sync files on a merge of any sort can lead to problems.

In previous releases we simply gave you the ability to enter your URLs and revisions, almost as you would if using the command line to access SVN. But in JDeveloper we pride ourselves on providing declarative help for developers. This wizard is invoked from a checked out application context - so you are always working within your working copy.
In this first step you choose the type of merge you are undertaking, for instance Merge Selected Revision Range is used if you want to update a branch with changes from the trunk. Let's take a common scenario: User 1 is working on Branch 123_susan. She knows that primarily her work will not cause any conflict with other work on other branches or the trunk so she has not worried too much about merging the latest trunk code into her branch. However, she comes across a problem and asks User 2 to fix something in the trunk so she can progress. She is told the revision that contains the specific fix she needs so she uses Merge Selected Revision Range to get that revision into her branch. The dialog below shows the path to trunk/blues as the source and her working copy - her branch - is the destination for the merge.

The revision to be merged - 275 - was picked using the List Revisions dialog. This dialog is used whenever revisions need to be browsed or selected. Notice that selecting 275 in the top panel shows the details of that revision - the comments, the files, the action and the author
 Now the user can complete move to step 3 of the wizard, choose other merge options and carry out a test merge to check her work and finally complete the merge of that one revision into her working copy. Finally, she will commit her working copy back to its branch on the repository as normal.
Now the user can complete move to step 3 of the wizard, choose other merge options and carry out a test merge to check her work and finally complete the merge of that one revision into her working copy. Finally, she will commit her working copy back to its branch on the repository as normal.
Once she has completed the work on her branch she will be ready to use the Re-integrate A Branch merge to get it back into the trunk of the development. As always, the way to do this is to carry out any merge into a local working copy and then commit. So the first step for the user is to do a final commit of her branch. At this stage she can remove her branched working copy as it is finished with. She checks out the latest trunk revision and now she is ready to merge her branch to her new (trunk) working copy. Let's look at that another way:
 1. A branch is created from trunk
1. A branch is created from trunk
2. User 1 checks out working copy from branch and edits code
3. Commits back to branch periodically
4. User 2 commits revision 200 to trunk and User 1 merges that revision to the working copy
5. Finishes coding working copy and commits to branch
6. Checks out new working copy from trunk
7. Merges branch into working copy
8. Commits working copy back to trunk
Before Subversion 1.5 the merge of a single revision in step 4 would have caused problems when the final merge of the branch back to the trunk was done (step 7). But SVN now has merge tracking so it keeps track of the revisions that have already been merged so that the final merge of all revisions goes ahead without error.
The third merge option is Merge Two Different Trees. This allows you to compare two different branches and merge and differences back into your working copy. This is the most complicated and, I would say, the least used of the merges.
One final tip - what if you want to revert your working copy to a specific revision? Use the Merge Selected Revision Range option. In List Revisions select the range of revisions from the latest to the revision you want to revert to and click OK. This will enter the range. But the range list will be ascending - eg 258-359. To revert to revision 258 simply reverse the range order and hey presto! a revert back rather than a merge up will be done - try it out in the test merge panel to check it - and you're done!
Take a look at the wizard below. This is available whether you choose Merge Working Copy or if you want to Merge a single file. My top tip is that you should almost always use Merge Working Copy, especially if you are working with ADF (Application Development Framework) as many of the XML metadata files for your application will have dependencies on Java files and ending up with missed or out of sync files on a merge of any sort can lead to problems.

In previous releases we simply gave you the ability to enter your URLs and revisions, almost as you would if using the command line to access SVN. But in JDeveloper we pride ourselves on providing declarative help for developers. This wizard is invoked from a checked out application context - so you are always working within your working copy.
In this first step you choose the type of merge you are undertaking, for instance Merge Selected Revision Range is used if you want to update a branch with changes from the trunk. Let's take a common scenario: User 1 is working on Branch 123_susan. She knows that primarily her work will not cause any conflict with other work on other branches or the trunk so she has not worried too much about merging the latest trunk code into her branch. However, she comes across a problem and asks User 2 to fix something in the trunk so she can progress. She is told the revision that contains the specific fix she needs so she uses Merge Selected Revision Range to get that revision into her branch. The dialog below shows the path to trunk/blues as the source and her working copy - her branch - is the destination for the merge.

The revision to be merged - 275 - was picked using the List Revisions dialog. This dialog is used whenever revisions need to be browsed or selected. Notice that selecting 275 in the top panel shows the details of that revision - the comments, the files, the action and the author
 Now the user can complete move to step 3 of the wizard, choose other merge options and carry out a test merge to check her work and finally complete the merge of that one revision into her working copy. Finally, she will commit her working copy back to its branch on the repository as normal.
Now the user can complete move to step 3 of the wizard, choose other merge options and carry out a test merge to check her work and finally complete the merge of that one revision into her working copy. Finally, she will commit her working copy back to its branch on the repository as normal.Once she has completed the work on her branch she will be ready to use the Re-integrate A Branch merge to get it back into the trunk of the development. As always, the way to do this is to carry out any merge into a local working copy and then commit. So the first step for the user is to do a final commit of her branch. At this stage she can remove her branched working copy as it is finished with. She checks out the latest trunk revision and now she is ready to merge her branch to her new (trunk) working copy. Let's look at that another way:
 1. A branch is created from trunk
1. A branch is created from trunk2. User 1 checks out working copy from branch and edits code
3. Commits back to branch periodically
4. User 2 commits revision 200 to trunk and User 1 merges that revision to the working copy
5. Finishes coding working copy and commits to branch
6. Checks out new working copy from trunk
7. Merges branch into working copy
8. Commits working copy back to trunk
Before Subversion 1.5 the merge of a single revision in step 4 would have caused problems when the final merge of the branch back to the trunk was done (step 7). But SVN now has merge tracking so it keeps track of the revisions that have already been merged so that the final merge of all revisions goes ahead without error.
The third merge option is Merge Two Different Trees. This allows you to compare two different branches and merge and differences back into your working copy. This is the most complicated and, I would say, the least used of the merges.
One final tip - what if you want to revert your working copy to a specific revision? Use the Merge Selected Revision Range option. In List Revisions select the range of revisions from the latest to the revision you want to revert to and click OK. This will enter the range. But the range list will be ascending - eg 258-359. To revert to revision 258 simply reverse the range order and hey presto! a revert back rather than a merge up will be done - try it out in the test merge panel to check it - and you're done!
Working with Versioned Database Models
What? 3 posts in 2 days? After months of silence? Isn't it amazing how time flies. Here in the JDeveloper Product Management group we've been busy all year with releases and conferences and many opportunities to get out and talk to people about the great features in our tool. But as the year draws nearer to a close and all the traveling is over I've finally got time to get out on my blog some of the things that I've been evangelizing about all year. As you'll have noticed, one of those is the great new functionality that we've introduced in database modeling.
Periodically I'm asked why we don't introduce a database repository to store database models. One that can be queried and can store versions of the modeled objects? We've been down that road (those of you who've been around for a while know what I'm talking about!) but think that what we have now in JDeveloper is much more flexible. What is it that you want from a repository? Amongst the most important answers to that question is the ability to store multiple versions of your database objects, to query and to compare them.
In previous posts I've demonstrated how you can use our Database Reporting to query your database models and output the results. In this post I want to show you how you can use JDeveloper's integrated versioning system capabilities not only to maintain multiple versions of your database model but how you can resolve any conflicts that arise when multiple users update the model, using a declarative interface.
In this example I am using Subversion (SVN), one of the versioning systems that is integrated in JDeveloper. It is an open source system, widely used in the application development world. I am not going to step through a complete process for versioning in this post, there are various tutorials, how-to, demos. white papers available on OTN and if you want more information on SVN there is a very good online book.

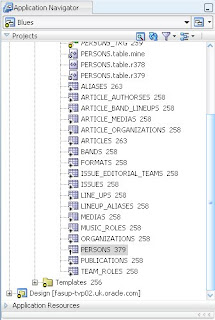
Here is a part of my application. Note that it contains an offline database model (Blues) and one schema (GOTTHEBLUES) containing a number of database objects. This is a project that I'm currently working on. It is stored in an SVN repository - each of the objects has a revision number next to it. Notice that the PERSONS table is at version 378. In SVN the repository revision number is advanced each time a check in of files is done. So this does not mean that the PERSONS table has been checked in 378 times, it shows that the last time PERSONS was checked in the repository moved to version 378. Likewise the last revision of PUBLICATIONS is 258, so PUBLICATIONS has not been changed since revision 258.
If I open PERSONS from the navigator - I get the declarative UI that allows me to edit that object. But that is not how the information is stored. JDeveloper stores its database models by object - in XML. Below is an extract of what you would see if you opened the underlying file PERSONS.table in a browser.
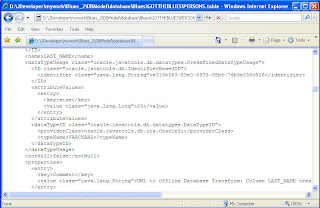
It's not impossible to read - the extract shows the detail for column LAST_NAME, a VARCHAR2 of length 25, with a comment that it was created via a DB Transform (from a class model). However, the declarative UI abstracts you from the raw XML.
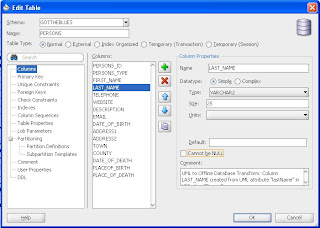
But imagine if you needed to compare two versions of the PERSONS table - or you had two users who were both working on the PERSONS table and checked in their changes to the SVN repository? Comparing the raw XML files is possible, and JDeveloper does recognize XML formating, but in the latest version of JDeveloper (11.1.1.2.0) there is a new declarative UI for that too.
Imagine this scenario: two users have checked out the latest version of the application. SVN uses a copy-modify-merge versioning approach. This means that when an application is checked out a copy of that application is created on the user's local machine. SVN does not keep a record of who and where copies are checked out. It is only interested when something is commited back to the repository. So, as a user I can check out a working copy, make changes to it and if I never commit those changes back to the repository, so be it. I could do some 'what if' type coding and then decide to discard the whole copy.
In my scenario the two users have been discussing the PERSONS table and agree that the length of the LAST_NAME column is too short at 25. Unfortunately, they both decided to modify the column length in their working copy. User 1 happens to be the first to commit her changes back to the repository - so it now has LAST_NAME with a length of 50.
Now user 2 modifies her working copy, editing LAST_NAME to length 40. As good practice dictates, she Updates her working copy with the latest revision from the repository - so she can resolve any code conflicts in her working copy prior to merging her copy back in.
In this case she finds that she has a conflict between her code and the repository that JDeveloper cannot resolve automatically. She sees this in her Application Navigator. It shows the PERSON table with a conflict overlay and the differing versions of the table are also listed (see below)
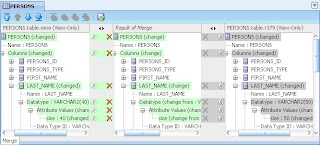
But help is at hand. Double-clicking on PERSONS 379 opens the three-panel Merge window. On the left is her local version of PERSONS - with length 40, on the right is the repository version with length 50. After reviewing this she has shuffled her version into the middle Result of Merge panel. As that was the only conflict in the two files the Save and Complete Merge icon is enabled in the toolbar.
 Once she saves this merge and refreshes the Application Navigator the extra conflict files will disappear and the updates will be applied to her working copy. Now she is ready to commit her working copy back to the repository so that it reflects the latest code position.
Once she saves this merge and refreshes the Application Navigator the extra conflict files will disappear and the updates will be applied to her working copy. Now she is ready to commit her working copy back to the repository so that it reflects the latest code position.
Not all changes made by multiple users cause conflicts. If the changes are complimentary - for instance one user adds a new column LOCATION and another uses changes the type of PERSONS_TYPE these changes will be added to the repository as SVN and JDeveloper recognize that there is no conflict. This is how SVN works by default, copy-modfy-merge in action. Many systems work this way, and others use the lock-modify-unlock paradigm.
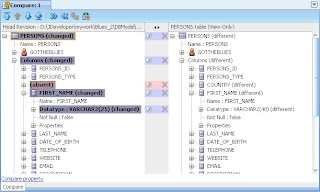
If you want to review changes to a database object prior to updating your working copy, you can use one of the Compare options (Compare with Latest, with Previous, with Other Revision) before you update your working copy with the repository contents. In the example below, user 1 has used Compare with Latest to check her changes: A change to the size of FIRST_NAME and a new column COUNTRY - as shown in the right hand panel with the latest version in the repository (as shown in the left hand panel).
Finally, in this post, a short list of other tips
Periodically I'm asked why we don't introduce a database repository to store database models. One that can be queried and can store versions of the modeled objects? We've been down that road (those of you who've been around for a while know what I'm talking about!) but think that what we have now in JDeveloper is much more flexible. What is it that you want from a repository? Amongst the most important answers to that question is the ability to store multiple versions of your database objects, to query and to compare them.
In previous posts I've demonstrated how you can use our Database Reporting to query your database models and output the results. In this post I want to show you how you can use JDeveloper's integrated versioning system capabilities not only to maintain multiple versions of your database model but how you can resolve any conflicts that arise when multiple users update the model, using a declarative interface.
In this example I am using Subversion (SVN), one of the versioning systems that is integrated in JDeveloper. It is an open source system, widely used in the application development world. I am not going to step through a complete process for versioning in this post, there are various tutorials, how-to, demos. white papers available on OTN and if you want more information on SVN there is a very good online book.

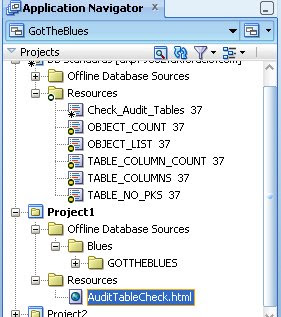
Here is a part of my application. Note that it contains an offline database model (Blues) and one schema (GOTTHEBLUES) containing a number of database objects. This is a project that I'm currently working on. It is stored in an SVN repository - each of the objects has a revision number next to it. Notice that the PERSONS table is at version 378. In SVN the repository revision number is advanced each time a check in of files is done. So this does not mean that the PERSONS table has been checked in 378 times, it shows that the last time PERSONS was checked in the repository moved to version 378. Likewise the last revision of PUBLICATIONS is 258, so PUBLICATIONS has not been changed since revision 258.
If I open PERSONS from the navigator - I get the declarative UI that allows me to edit that object. But that is not how the information is stored. JDeveloper stores its database models by object - in XML. Below is an extract of what you would see if you opened the underlying file PERSONS.table in a browser.

It's not impossible to read - the extract shows the detail for column LAST_NAME, a VARCHAR2 of length 25, with a comment that it was created via a DB Transform (from a class model). However, the declarative UI abstracts you from the raw XML.

But imagine if you needed to compare two versions of the PERSONS table - or you had two users who were both working on the PERSONS table and checked in their changes to the SVN repository? Comparing the raw XML files is possible, and JDeveloper does recognize XML formating, but in the latest version of JDeveloper (11.1.1.2.0) there is a new declarative UI for that too.
Imagine this scenario: two users have checked out the latest version of the application. SVN uses a copy-modify-merge versioning approach. This means that when an application is checked out a copy of that application is created on the user's local machine. SVN does not keep a record of who and where copies are checked out. It is only interested when something is commited back to the repository. So, as a user I can check out a working copy, make changes to it and if I never commit those changes back to the repository, so be it. I could do some 'what if' type coding and then decide to discard the whole copy.
In my scenario the two users have been discussing the PERSONS table and agree that the length of the LAST_NAME column is too short at 25. Unfortunately, they both decided to modify the column length in their working copy. User 1 happens to be the first to commit her changes back to the repository - so it now has LAST_NAME with a length of 50.
Now user 2 modifies her working copy, editing LAST_NAME to length 40. As good practice dictates, she Updates her working copy with the latest revision from the repository - so she can resolve any code conflicts in her working copy prior to merging her copy back in.
In this case she finds that she has a conflict between her code and the repository that JDeveloper cannot resolve automatically. She sees this in her Application Navigator. It shows the PERSON table with a conflict overlay and the differing versions of the table are also listed (see below)

But help is at hand. Double-clicking on PERSONS 379 opens the three-panel Merge window. On the left is her local version of PERSONS - with length 40, on the right is the repository version with length 50. After reviewing this she has shuffled her version into the middle Result of Merge panel. As that was the only conflict in the two files the Save and Complete Merge icon is enabled in the toolbar.
 Once she saves this merge and refreshes the Application Navigator the extra conflict files will disappear and the updates will be applied to her working copy. Now she is ready to commit her working copy back to the repository so that it reflects the latest code position.
Once she saves this merge and refreshes the Application Navigator the extra conflict files will disappear and the updates will be applied to her working copy. Now she is ready to commit her working copy back to the repository so that it reflects the latest code position.Not all changes made by multiple users cause conflicts. If the changes are complimentary - for instance one user adds a new column LOCATION and another uses changes the type of PERSONS_TYPE these changes will be added to the repository as SVN and JDeveloper recognize that there is no conflict. This is how SVN works by default, copy-modfy-merge in action. Many systems work this way, and others use the lock-modify-unlock paradigm.
If you want to review changes to a database object prior to updating your working copy, you can use one of the Compare options (Compare with Latest, with Previous, with Other Revision) before you update your working copy with the repository contents. In the example below, user 1 has used Compare with Latest to check her changes: A change to the size of FIRST_NAME and a new column COUNTRY - as shown in the right hand panel with the latest version in the repository (as shown in the left hand panel).

Finally, in this post, a short list of other tips
- Using Compare with Other Revision don't forget to scroll to the right - and see not only revision numbers but the commit notes. Also use the filters optimize the revisions listed

- If you make changes to a file but want to revert back to the version you checked out from the repository - use menu Versioning - Revert
- Use the graphical Version Tree to review branches and versions of your objects



Visualizing the DB Reporting Metamodel
In my last post I gave examples of using both the pre-built reports and building custom reports on your database models.
As a P.S. to that post I want to point you to the JDeveloper Help system that comes with diagrams to help you define and understand the Database Reporting metamodel. Below is the JDEV table of contents - open at Working with Database Reports

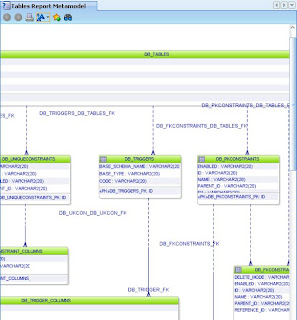
and one small part of the Tables Report Metamodel to give you the idea. Have fun!
As a P.S. to that post I want to point you to the JDeveloper Help system that comes with diagrams to help you define and understand the Database Reporting metamodel. Below is the JDEV table of contents - open at Working with Database Reports

and one small part of the Tables Report Metamodel to give you the idea. Have fun!

Using Database Reporting to Ensure Standards Compliance
In JDeveloper 11gR1 we introduced a SQL-like interface for reporting on your database models. Watch this demo to review the basic functionality. In the latest release we've added a set of pre-built reports. These reports not only get you started with reporting but also illustrate how you can use database reporting to ensure that the objects in your offline database model comply with your team's naming standards.
I say SQL-like interface because the database model you develop offline in JDeveloper is stored in XML. However, we took the decision that as most database developers are familiar with SQL it made perfect sense to provide a familiar way to interrogate the model. For instance, the pre-built report to list all tables with no Primary Key is:
SELECT
T.SCHEMA '.' T.NAME "Table"
FROM
DB_PKCONSTRAINTS C RIGHT JOIN DB_TABLES T ON C.PARENT_ID = T.ID
WHERE
C.NAME IS NULL
As you get more familiar with the meta-model you might write your own SQL queries, but there is also a declarative UI to help you traverse the model and develop the query you want.
Below is an image of the wizard, showing how the FROM clause for the above query is selected. You can also select the objects, apply different JOINs, add a WHERE, GROUP BY and aliases using the declarative UI.

Here is an example of a more complex SQL query - to report on any tables that do not have the audit column CREATION_DATE*
SELECT T.NAME FROM DB_TABLES T
WHERE NOT EXISTS
SELECT 1 FROM DB_COLUMNS C WHERE C.PARENT_ID = T.ID
AND C.NAME = 'CREATION_DATE')
Now the world is your reporting oyster - how about creating a series of reports in a Standards Project - and distributing that project to every team that is doing database development? Here is one approach:
- Check the Standards Project out of source control into the required application
- In the Standards Project open the Project Properties, in Project Source Paths select the Offline Database node
- Add the projects containing your database model project(s) - see image below
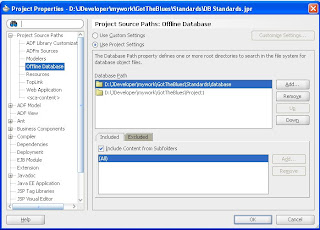
- Open each report (double-click) and select the offline database you want to run against
- Go to the Publish tab and enter the details of how and where you want the report to be save. In the example below I've chosen to save the report in the project that contains the database - so my audit reports can be shown to represent my offline DB Model.

- Use the context menu of the report format to Run the report. In my example the HTML version of the report (AuditTableCheck) is now stored in Project1 along with the database, the report format (Check_Audit_Tables) is stored in the Standards project along with the other report formats.



Let me know how you get on - it would be good to build up a list of reports written by you that could be shared with others.
*For a full example of using this in a tutorial see this Oracle By Example
<h2 class="bTitle">Announcing new
Announcing new Oracle Development SIG in the UK
On the 27th of October, the UKOUG are launching a new Development SIG aimed at any developer who is developing using Oracle tools and technology. The first special interest group (SIG) will have a "modernization" theme to it and covers topics as including Apex, SOA, Forms, Designer and JDeveloper.
A full SIG agenda is published here.
As usual with these events, space is limited and given the wealth of experienced presenters and topics, it should serve as a great learning opportunity as well as the chance to exchange ideas and meet with fellow developers.
Team Productivity Center Tutorial Published
There is now an Oracle By Example (OBE) tutorial available for TPC. It takes you through a number of topics including, on the admin side, setting up teams and integrating with repositories and, as a TPC user, querying repositories and creating relationships and tagging items across repositories.
It assumes that you have already installed or have access to TPC on the server. If not, here are instructions on doing that. The OBE includes images and examples using JIRA and MS Project Server but for a tutorial on the Rally Software integration, explore their site
And, as always, give me your feedback!
It assumes that you have already installed or have access to TPC on the server. If not, here are instructions on doing that. The OBE includes images and examples using JIRA and MS Project Server but for a tutorial on the Rally Software integration, explore their site
And, as always, give me your feedback!
Connecting with Team Productivity Center
Well, it's been quite a couple of weeks. TPC was featured in the developer tools section of the Fusion Middleware 11g launch and got some good press coverage (for instance eWeek) and the bloggers were our in force. You can watch the launch and see Duncan Mills use TPC in his demo. He has also recorded an Oracle Videocast and Podcast introducing TPC.
My aim is to get as many users to download and use it as possible (actually, that is every Product Manager's aim for their product!) That is going well, but I could do with your help to get the news out there. The ALM repositories we integrate with currently are all leaders in their field. The JIRA integration is a great productivity booster and the more I work with JIRA the more I realise how flexible it is. Microsoft Project Server is widely used in enterprise organisations and Rally Software is a world leader in agile development.
We are working on additional connectors (more news on that when I can divulge more) but there is always room for more. I'd love to hear from you on what ALM repositories you would like to see TPC integrate with. I'd love to hear from you if you have an internal system you would like to write a connector to integrate it with TPC. In fact, I'd love to hear from you in any capacity concerning TPC - and that, of course, includes those of you who have reported bugs too ;-)
John Stegeman, an Oracle Ace Director, is interested in creating a connector to TRAC. He announced this with a JDeveloper forum post saying, " I've been thinking about writing a connector for an issue management system that I use (of course, there had to be a selfish reason), TRAC. I think an ideal way to do this would be with a small team of developers working together on the new sample code site hosted by Oracle (http://www.samplecode.oracle.com). "
I think this is a great idea. It would be about a month of effort and you would get the opportunity not only to get to know our connector framework but to work as part of a small team and gain experience to perhaps go on to creating a connector for something within your own organisation. You can contact John through the forum post. I would highly recommend it (well, I would, wouldn't I?)
So, download, use, report, connect, and code - yep, that about covers it!
My aim is to get as many users to download and use it as possible (actually, that is every Product Manager's aim for their product!) That is going well, but I could do with your help to get the news out there. The ALM repositories we integrate with currently are all leaders in their field. The JIRA integration is a great productivity booster and the more I work with JIRA the more I realise how flexible it is. Microsoft Project Server is widely used in enterprise organisations and Rally Software is a world leader in agile development.
We are working on additional connectors (more news on that when I can divulge more) but there is always room for more. I'd love to hear from you on what ALM repositories you would like to see TPC integrate with. I'd love to hear from you if you have an internal system you would like to write a connector to integrate it with TPC. In fact, I'd love to hear from you in any capacity concerning TPC - and that, of course, includes those of you who have reported bugs too ;-)
John Stegeman, an Oracle Ace Director, is interested in creating a connector to TRAC. He announced this with a JDeveloper forum post saying, " I've been thinking about writing a connector for an issue management system that I use (of course, there had to be a selfish reason), TRAC. I think an ideal way to do this would be with a small team of developers working together on the new sample code site hosted by Oracle (http://www.samplecode.oracle.com). "
I think this is a great idea. It would be about a month of effort and you would get the opportunity not only to get to know our connector framework but to work as part of a small team and gain experience to perhaps go on to creating a connector for something within your own organisation. You can contact John through the forum post. I would highly recommend it (well, I would, wouldn't I?)
So, download, use, report, connect, and code - yep, that about covers it!
Introducing Oracle Team Productivity Center
Today is an exciting day for me. It's the launch of Oracle Fusion Middleware 11g in the USA and tomorrow the launch event comes to London. Included in this launch is, of course, Oracle JDeveloper 11gR1.
For some time I've been working on a new aspect of JDeveloper - Oracle Team Productivity Center. It is our first release of functionality to enable better Application Lifecycle Management for JDeveloper users and it is included in Oracle JDeveloper 11gR1.
TPC introduces the Team Navigator to JDeveloper. Through this navigator I can set up my team and user structure, applying team roles to users in teams/projects. I can connect to my existing ALM repositories and query/update artifacts in those repositories while working in JDeveloper.
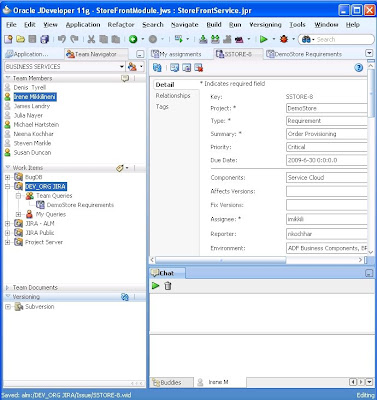
In addition I can contextually link artifacts from different ALM repositories together - so I can create a relationship between a requirement defined in JIRA and a task in MS Project Server and I can tag items (needs a use case, ready for code review etc.) that are either visible to me or to all the members of my team. And I can be a member of multiple teams too. If I'm working on one task and am asked to switch to some other piece of code I can save the state of my development files open in the IDE against a specific work item. Work item is the generic term we give to any ALM artifact queried from an integrated ALM repository. So in the example below, I am working on a JIRA issue - SSTORE-23. If I Save Context I will save the Business Component files open in the editor along with the position and sizing of all the other JDeveloper windows. Then when I come back to this piece of work I can re-open SSTORE and Restore Context - to return my IDE to the saved state. Another great productivity booster!

A database is used to store queries, relationships, tags etc and managed by a small JEE application. This is set up by the installer and the client-side workings are downloaded through the normal Check For Updates Center in JDeveloper.
In this first release, in addition to the adaptors developed by us to connect to JIRA and MS Project Server I'm really pleased that we have partnered with Rally Software.
Rally is the leader in Agile application lifecycle management (ALM) dedicated to making distributed development organizations faster and leaner by dramatically cutting the time, cost and effort needed to deliver high quality applications. Rally's products were honored with four consecutive Jolt awards (the software industry's equivalent of the Oscar® award) in 2006, 2007, 2008 and 2009. The company's end-to-end solutions for Agile development also include Agile University, the largest source for Agile training, and Agile Commons, the largest collaborative Web 2.0 community dedicated to advancing software agility. Using the Rally Connector JDeveloper users can view and update their Rally tasks and defects directly from JDeveloper.
This release of TPC concentrates on enabling JDeveloper users, but Application Lifecycle Management is about more than just developers - it has a role in breaking down functional silos (development, QA, Doc, PM....) and it's our aim to push TPC out to more than developers going forward - both in terms of increased services provided by TPC and increasing the number of connectors available to differing ALM repositories (requirements, task, defects, testing etc)
One step towards that goal is the provision of a Connector Developers Guide and a sample connector to allow other third parties to create connectors to their existing ALM tools - be those commercial products or in-house systems.
But that's not all - JDeveloper users can also integrate their XMPP chat system into JDeveloper - even more productivity for developers without the need to leave their IDE! I can who of my team mates is connected to chat and also chat with all my buddies - whether they are working with TPC or not.
This is just a very brief introduction to Team Productivity Center. Browse the link above for more information, download, install and try it out - and let me know what you think ;-)
For some time I've been working on a new aspect of JDeveloper - Oracle Team Productivity Center. It is our first release of functionality to enable better Application Lifecycle Management for JDeveloper users and it is included in Oracle JDeveloper 11gR1.
TPC introduces the Team Navigator to JDeveloper. Through this navigator I can set up my team and user structure, applying team roles to users in teams/projects. I can connect to my existing ALM repositories and query/update artifacts in those repositories while working in JDeveloper.

In addition I can contextually link artifacts from different ALM repositories together - so I can create a relationship between a requirement defined in JIRA and a task in MS Project Server and I can tag items (needs a use case, ready for code review etc.) that are either visible to me or to all the members of my team. And I can be a member of multiple teams too. If I'm working on one task and am asked to switch to some other piece of code I can save the state of my development files open in the IDE against a specific work item. Work item is the generic term we give to any ALM artifact queried from an integrated ALM repository. So in the example below, I am working on a JIRA issue - SSTORE-23. If I Save Context I will save the Business Component files open in the editor along with the position and sizing of all the other JDeveloper windows. Then when I come back to this piece of work I can re-open SSTORE and Restore Context - to return my IDE to the saved state. Another great productivity booster!

A database is used to store queries, relationships, tags etc and managed by a small JEE application. This is set up by the installer and the client-side workings are downloaded through the normal Check For Updates Center in JDeveloper.
In this first release, in addition to the adaptors developed by us to connect to JIRA and MS Project Server I'm really pleased that we have partnered with Rally Software.
Rally is the leader in Agile application lifecycle management (ALM) dedicated to making distributed development organizations faster and leaner by dramatically cutting the time, cost and effort needed to deliver high quality applications. Rally's products were honored with four consecutive Jolt awards (the software industry's equivalent of the Oscar® award) in 2006, 2007, 2008 and 2009. The company's end-to-end solutions for Agile development also include Agile University, the largest source for Agile training, and Agile Commons, the largest collaborative Web 2.0 community dedicated to advancing software agility. Using the Rally Connector JDeveloper users can view and update their Rally tasks and defects directly from JDeveloper.
This release of TPC concentrates on enabling JDeveloper users, but Application Lifecycle Management is about more than just developers - it has a role in breaking down functional silos (development, QA, Doc, PM....) and it's our aim to push TPC out to more than developers going forward - both in terms of increased services provided by TPC and increasing the number of connectors available to differing ALM repositories (requirements, task, defects, testing etc)
One step towards that goal is the provision of a Connector Developers Guide and a sample connector to allow other third parties to create connectors to their existing ALM tools - be those commercial products or in-house systems.
But that's not all - JDeveloper users can also integrate their XMPP chat system into JDeveloper - even more productivity for developers without the need to leave their IDE! I can who of my team mates is connected to chat and also chat with all my buddies - whether they are working with TPC or not.
This is just a very brief introduction to Team Productivity Center. Browse the link above for more information, download, install and try it out - and let me know what you think ;-)
ODTUG 2009
I can hardly believe it's another year (of few posts to my blog) and another ODTUG Kaleidoscope conference is almost upon us. This year the conference is in Monterey so I'm packing my bags and off to Oracle Headquarters in San Francisco tomorrow - then down to the conference on June 20th
If you have the opportunity I'd urge you to try and make it there too. The 'fun' starts off on Saturday when there is a community service day. Last year we painted school classrooms in New Orleans, this year we are helping to restore habitat at Martin Dunes, California’s largest and most intact dune ecosystem. So I'm packing plenty of sunscreen as my pale English skin isn't used to the California sun! More fun after the first day of sessions Sunday - with the second ODTUG Jam Session. Those of you who know Grant Ronald and I know that we are much too shy and retiring to join in that ;-)
But of course, that's not all the fun. The conference is full of interesting and diverse sessions - and I should know, I was part of the panel reviewing papers for the Editor's Choice award - I spent a few evenings reading papers on everything from project management to Oracle to the Holy Grail.
As for me, I'm really excited to be doing two sessions -
5000 tables, 100 schemas, 2000 developers: This will showcase some of the team-working features such as standards and version management, and reporting and impact analysis and the highly usable and scalable data modeling in JDeveloper. I've got some great new functionality to reveal - reporting on your data models, user defined validation and declarative compare of versioned database objects
Tooling up for ALM 2.0 with Oracle Team Productivity Center: If you were lucky enough to be at Oracle World or the UK Oracle User Group conference last year you might have seen a very early incarnation of this project that I've been working on. At ODTUG I'm going to be demoing the very latest code and showing you how to use your ALM repositories from within JDeveloper and how to integrate artifacts from those (maybe) disparate repositories together through Oracle Team Productivity Center. All this and team management too!
Another goal I have for the conference week is to talk to as many JDeveloper users as possible about team working, ALM and SDLC - and to ensure that I get feedback to take back and work on more functionality in JDeveloper to compliment the great application development tool we have
I look forward to seeing you there - or if not, finding other ways to talk to you!
If you have the opportunity I'd urge you to try and make it there too. The 'fun' starts off on Saturday when there is a community service day. Last year we painted school classrooms in New Orleans, this year we are helping to restore habitat at Martin Dunes, California’s largest and most intact dune ecosystem. So I'm packing plenty of sunscreen as my pale English skin isn't used to the California sun! More fun after the first day of sessions Sunday - with the second ODTUG Jam Session. Those of you who know Grant Ronald and I know that we are much too shy and retiring to join in that ;-)
But of course, that's not all the fun. The conference is full of interesting and diverse sessions - and I should know, I was part of the panel reviewing papers for the Editor's Choice award - I spent a few evenings reading papers on everything from project management to Oracle to the Holy Grail.
As for me, I'm really excited to be doing two sessions -
5000 tables, 100 schemas, 2000 developers: This will showcase some of the team-working features such as standards and version management, and reporting and impact analysis and the highly usable and scalable data modeling in JDeveloper. I've got some great new functionality to reveal - reporting on your data models, user defined validation and declarative compare of versioned database objects
Tooling up for ALM 2.0 with Oracle Team Productivity Center: If you were lucky enough to be at Oracle World or the UK Oracle User Group conference last year you might have seen a very early incarnation of this project that I've been working on. At ODTUG I'm going to be demoing the very latest code and showing you how to use your ALM repositories from within JDeveloper and how to integrate artifacts from those (maybe) disparate repositories together through Oracle Team Productivity Center. All this and team management too!
Another goal I have for the conference week is to talk to as many JDeveloper users as possible about team working, ALM and SDLC - and to ensure that I get feedback to take back and work on more functionality in JDeveloper to compliment the great application development tool we have
I look forward to seeing you there - or if not, finding other ways to talk to you!
DD Tips and Techniques - 2 Displaying Shapes
When I said occasional in the last blog - I didn't specify the time interval - so here is a second post in as many minutes!
There are a number of ways to tidy a cluttered diagram. Sometimes you don't want to see all the columns/constraints in the table shape, or perhaps you only want to see some of the columns - the keys or the most important columns:
View As -> Compact
Select shapes in a diagram and use this context menu to completely remove any columns or constraints from the shape
Hide Selected Shapes
If you want to show only some of the members of your shape (for instance only the keys and major columns in a table) select members you want to hide and use this context menu. The members are cut from the diagram but are still available to you through the shape editor. To see all the members again use Show All Hidden Members
Tools -> Preferences -> Diagrams -> Database
Under this node you will find many different options for your database diagram - you can change font, shape colors for many different database shapes. For instance - select Table from the dropdown list and uncheck Show Constraints if you want to exclude them from the diagram. Note that changes made in this way only apply to new shapes added to a diagram. So it's good practice to check your preferences before you start work on a diagram
There are a number of ways to tidy a cluttered diagram. Sometimes you don't want to see all the columns/constraints in the table shape, or perhaps you only want to see some of the columns - the keys or the most important columns:
View As -> Compact
Select shapes in a diagram and use this context menu to completely remove any columns or constraints from the shape
Hide Selected Shapes
If you want to show only some of the members of your shape (for instance only the keys and major columns in a table) select members you want to hide and use this context menu. The members are cut from the diagram but are still available to you through the shape editor. To see all the members again use Show All Hidden Members
Tools -> Preferences -> Diagrams -> Database
Under this node you will find many different options for your database diagram - you can change font, shape colors for many different database shapes. For instance - select Table from the dropdown list and uncheck Show Constraints if you want to exclude them from the diagram. Note that changes made in this way only apply to new shapes added to a diagram. So it's good practice to check your preferences before you start work on a diagram
Database Diagramming Tips and Techniques - 1 Keyboard Accelerators
I'm working on a new database design and thought I'd pass on some of the tips that I use to aid my work. As always with my blog entries, this will be an occasional series.
Keyboard Accelerators - diagram cleaning aid
I often create new offline database tables using a database diagram. I can visualize and edit objects in-place easily and often. But having to resize the shapes and tidy up the relationship lines can be very frustrating! So I do the following:
First the setup -
Go into Tools -> Preferences -> Accelerators
Scroll down the Actions list and select Height and Width
Add a new accelerator (if none set) - I use Ctrl H
Scroll to Select All and check what accelerator is set - default is Ctrl A
Scroll to Straighten Lines and add an accelerator - say Ctrl L
Now, in my diagram whenever I can't see all the info in my table shapes I either select the specific tables and do Ctrl H or do Ctrl A + Ctrl H to resize all my shapes followed by Ctrl L to straighten the lines.
Easy Tip No1!
Keyboard Accelerators - diagram cleaning aid
I often create new offline database tables using a database diagram. I can visualize and edit objects in-place easily and often. But having to resize the shapes and tidy up the relationship lines can be very frustrating! So I do the following:
First the setup -
Go into Tools -> Preferences -> Accelerators
Scroll down the Actions list and select Height and Width
Add a new accelerator (if none set) - I use Ctrl H
Scroll to Select All and check what accelerator is set - default is Ctrl A
Scroll to Straighten Lines and add an accelerator - say Ctrl L
Now, in my diagram whenever I can't see all the info in my table shapes I either select the specific tables and do Ctrl H or do Ctrl A + Ctrl H to resize all my shapes followed by Ctrl L to straighten the lines.
Easy Tip No1!
Checking who else has checked out?
A comment on an earlier post has prompted me to clarify the way that Subversion handles certain tasks. The commenter is using SQLDeveloper, that uses JDeveloper's SVN implementation, and wants-
1. Subversion navigator to indicate if others are working on the same code
Subversion uses the copy-modify-merge paradigm. This means that any user with the correct authorization can check out a copy of the code from the repository to a local file system. This local copy can be manipulated (using JDEV, Tortoise, command line etc) so that updates and commits can be carried out from it. However, the Subversion repository does not have any understanding of how many users are working on or have checked out the same code. Updates and Commits are instigated from the local copy. This also means that any local copy checked out from Subversion may never be checked back in.
2.When double clicking on a package in the database or in the versioning tree and have the option to load the local copy (linked to subversion).
With respect to the request to double click on the versioning tree this comes back to Subversion having no knowledge of the local copies. I think that he is asking that the local copy be updated through using the Subversion navigator - but updates are driven from the local copy, not the repository.
As for the database package, that would be another level of complexity. Presumably the single point of truth is the package definition held in the SVN repository. To ensure that the database holds the latest version the user would have to checkout a the latest version as a local copy from the repository and update the DB. I'm not sure that somehow automating this process would be desirable - it would need links from the DB to the tool to the correct local copy location and through this to the SVN repository - sounds error prone to me.
3. Be able to do a compile and see the log window
This is a SQL Developer question, rather than SVN oriented, so I'll leave that to my colleagues with SQLDeveloper to answer.
1. Subversion navigator to indicate if others are working on the same code
Subversion uses the copy-modify-merge paradigm. This means that any user with the correct authorization can check out a copy of the code from the repository to a local file system. This local copy can be manipulated (using JDEV, Tortoise, command line etc) so that updates and commits can be carried out from it. However, the Subversion repository does not have any understanding of how many users are working on or have checked out the same code. Updates and Commits are instigated from the local copy. This also means that any local copy checked out from Subversion may never be checked back in.
2.When double clicking on a package in the database or in the versioning tree and have the option to load the local copy (linked to subversion).
With respect to the request to double click on the versioning tree this comes back to Subversion having no knowledge of the local copies. I think that he is asking that the local copy be updated through using the Subversion navigator - but updates are driven from the local copy, not the repository.
As for the database package, that would be another level of complexity. Presumably the single point of truth is the package definition held in the SVN repository. To ensure that the database holds the latest version the user would have to checkout a the latest version as a local copy from the repository and update the DB. I'm not sure that somehow automating this process would be desirable - it would need links from the DB to the tool to the correct local copy location and through this to the SVN repository - sounds error prone to me.
3. Be able to do a compile and see the log window
This is a SQL Developer question, rather than SVN oriented, so I'll leave that to my colleagues with SQLDeveloper to answer.
Going To New Orleans - ODTUG Kalaidoscope 2008
I've traveled and spoken on Oracle all around the world at many events but this year will be my first at ODTUG (June 15th-19th). I'm looking forward to both the technical and the non-technical aspects of the conference. New Orleans is somewhere that I haven't visited in 15 years and I'm happy to be one of the nearly-75 strong ODTUG Brigade volunteering for a day of community service work to give back to the city that has given so much to music lovers and so many others like me.
The conference is packed with keynotes and sessions, I'm going to be presenting two:
Who Moved My Code? - Team Development in Oracle JDeveloper on Wednesday 8.00-9.00am
Seven Secrets (and more) of Successful JDeveloper Database Designers on Wednesday 2.45-3.45pm
Both of these will be predominantly demo driven sessions. In the first Lynn Munsinger will be joining me so we can demo multi-developer tips and tricks using Subversion. The Seven Secrets will focus on existing and new features for database development and visualization for application developers. I'm hoping also to squeeze in a sneak preview of a project I'm working on around Application Lifecycle Management. Please join me if you are at ODTUG as I would welcome your feedback.
Our Usability Research Team is running some feedback sessions that Lynn, Grant Ronald and myself will be attending, be sure and sign up for one of those. Plus, if you want to talk to us about any aspect of JDeveloper we will be in the exhibit halls ready and willing to demo and discuss.
Finally, I hear there is a ODTUG Jam Session and I'm pretty sure I wont be able to resist!
The conference is packed with keynotes and sessions, I'm going to be presenting two:
Who Moved My Code? - Team Development in Oracle JDeveloper on Wednesday 8.00-9.00am
Seven Secrets (and more) of Successful JDeveloper Database Designers on Wednesday 2.45-3.45pm
Both of these will be predominantly demo driven sessions. In the first Lynn Munsinger will be joining me so we can demo multi-developer tips and tricks using Subversion. The Seven Secrets will focus on existing and new features for database development and visualization for application developers. I'm hoping also to squeeze in a sneak preview of a project I'm working on around Application Lifecycle Management. Please join me if you are at ODTUG as I would welcome your feedback.
Our Usability Research Team is running some feedback sessions that Lynn, Grant Ronald and myself will be attending, be sure and sign up for one of those. Plus, if you want to talk to us about any aspect of JDeveloper we will be in the exhibit halls ready and willing to demo and discuss.
Finally, I hear there is a ODTUG Jam Session and I'm pretty sure I wont be able to resist!
New Best Practices Paper for Subversion and JDeveloper
I've finally got around to pulling together some of the information and best practices that I've blogged about into a document. You can view it here on Oracle Technology Network. Let me know what you think