

Jeremy Schneider

How Blocking-Lock Brownouts Can Escalate from Row-Level to Complete System Outages
This article is a shortened version. For the full writeup, go to https://github.com/ardentperf/pg-idle-test/tree/main/conn_exhaustion
This test suite demonstrates a failure mode when application bugs which poison connection pools collide with PgBouncers that are missing peer config and positioned behind a load balancer. PgBouncer’s peering feature (added with v1.19 in 2023) should be configured if multiple PgBouncers are being used with a load balancer – this feature prevents the escalation demonstrated here.
The failures described here are based on real-world experiences. While uncommon, this failure mode has been seen multiple times in the field.
Along the way, we discover unexpected behaviors (bugs?) in Go’s database/sql (or sqlx) connection pooler with the pgx client and in Postgres itself.
Sample output: https://github.com/ardentperf/pg-idle-test/actions/workflows/test.yml
The Problem in BriefGo’s database/sql allows connection pools to become poisoned by returning connections with open transactions for re-use. Transactions opened with db.BeginTx() will be cleaned up, but – for example – conn.ExecContext(..., "BEGIN") will not be cleaned up. PR #2481 proposes some cleanup logic in pgx for database/sql connection pools (not yet merged); I tested the PR with this test suite. The PR relies on the TxStatus indicator in the ReadyForStatus message which Postgres sends back to the client as part of its network protocol.
A poisoned connection pool can cause an application brownout since other sessions updating the same row wait indefinitely for the blocking transaction to commit or rollback its own update. On a high-activity or critical table, this can quickly lead to significant pile-ups of connections waiting to update the same locked row. With Go this means context deadline timeouts and retries and connection thrashing by all of the threads and processes that are trying to update the row. Backoff logic is often lacking in these code paths. When there is a currently running SQL (hung – waiting for a lock), pgx first tries to send a cancel request and then will proceed to a hard socket close.
If PgBouncer’s peering feature is not enabled, then cancel requests load-balanced across multiple PgBouncers will fail because the cancel key only exists on the PgBouncer that created the original connection. The peering feature solves the cancel routing problem by allowing PgBouncers to forward cancel requests to the correct peer that holds the cancel key. This feature should be enabled – the test suite demonstrates what happens when it is not.
Postgres immediately cleans up connections when it receives a cancel request. However, Postgres does not clean up connections when their TCP sockets are hard closed, if the connection is waiting for a lock. As a result, Postgres connection usage climbs while PgBouncer continually opens new connection that block on the same row. The app’s poisoned connection pool quickly leads to complete connection exhaustion in the Postgres server.
Existing connections will continue to work, as long as they don’t try to update the row which is locked. But the row-level brownout now becomes a database-level brownout – or perhaps a complete system outage (once the Go database/sql connection pool is exhausted) – because postgres rejects all new connection attempts from the application.
Result: Failed cancels → client closes socket → backends keep running → CLOSE_WAIT accumulates → Postgres hits max_connections → system outage
- The Problem in Brief
- Table of Contents
- Architecture
- The Test Scenarios
- Test Results
- Detection and Prevention
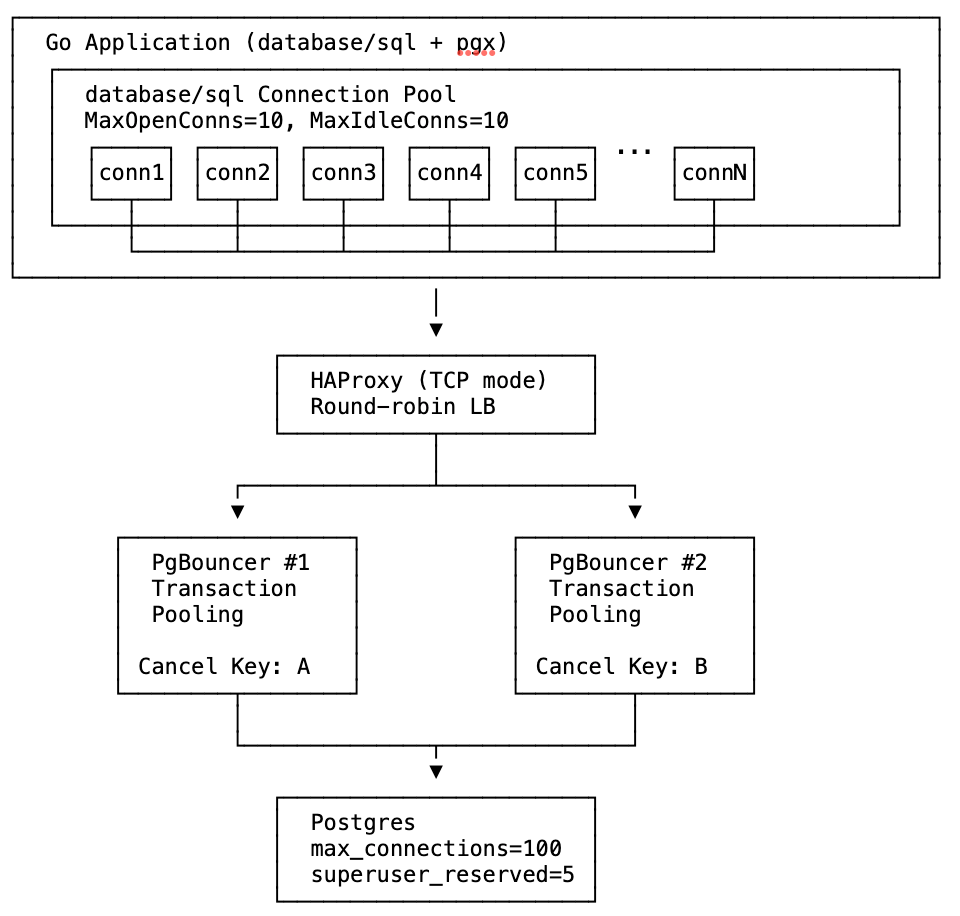
The test uses Docker Compose to create this infrastructure with configurable number of PgBouncer instances.
The Test Scenariostest_poisoned_connpool_exhaustion.sh accepts three parameters: <num_pgbouncers> <poison|sleep> <peers|nopeers>
In this test suite:
- The failure is injected 20 seconds after the test starts.
- Idle connections are aborted and rolled back after 20 seconds.
- Postgres is configured to abort and rollback any and all transactions if they are not completed within 40 seconds. Note that the
transaction_timeoutsetting (for total transaction time) should be used cautiously, and is available in Postgres v17 and newer.
TPS is the best indicator of actual application impact. It’s important to notice that PgBouncer peering does not prevent application impact from either poisoned connection pools or sleeping sessions. The section below titled “Detection and Prevention” has ideas which address the actual root cause and truly prevent application impact.

After the lock is acquired at t=20, TPS drops from ~700 to near zero in all cases as workers block on the locked row held by the open transaction.
Sleep mode (orange/green lines): Around t=40, Postgres’s idle_in_transaction_session_timeout (20s) fires and kills the blocking session. TPS recovers to ~600-700.
Poison mode (red/purple/blue lines): The lock-holding connection is never idle—it’s constantly being picked up by workers attempting queries—so the idle timeout never fires. TPS remains near zero until Postgres’s transaction_timeout (40s) fires at t=60, finally terminating the long-running transaction and releasing the lock.
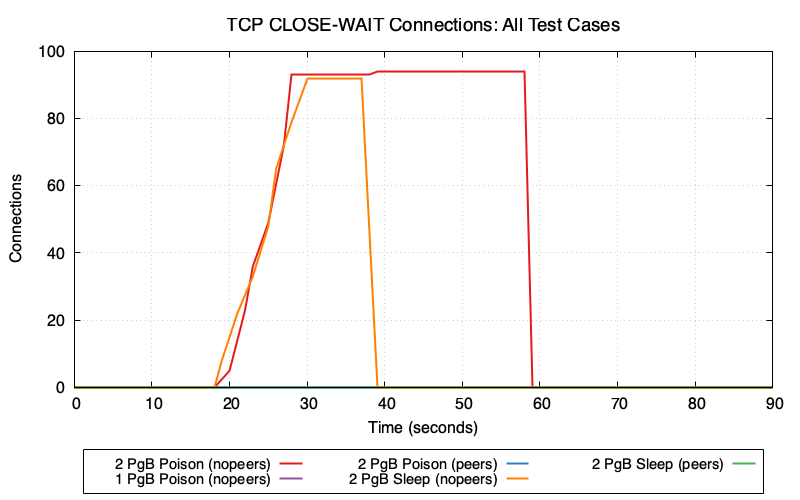
2 PgBouncers (nopeers) (red/orange lines): CLOSE_WAIT connections accumulate rapidly because:
- Cancel request goes to wrong PgBouncer → fails
- Client gives up and closes socket
- Server backend is still blocked on lock, hasn’t read the TCP close
- Connection enters CLOSE_WAIT state on Postgres
In poison mode (red), CLOSE_WAIT remains at ~95 until transaction_timeout fires at t=60. In sleep mode (orange), CLOSE_WAIT clears around t=40 when idle_in_transaction_session_timeout fires.
1 PgBouncer and peers modes (purple/blue/green lines): Minimal or zero CLOSE_WAIT because cancel requests succeed—either routing to the single PgBouncer or being forwarded to the correct peer.
Connection Pool Wait Time vs PgBouncer Client WaitGo’s database/sql pool tracks how long goroutines wait to acquire a connection (db.Stats().WaitDuration). PgBouncer tracks cl_waiting—clients waiting for a server connection. These metrics measure wait time at different layers of the stack.
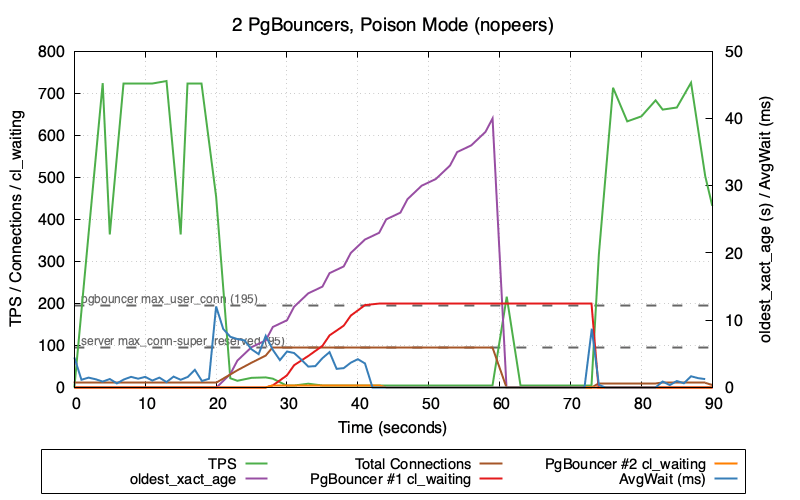
This graph shows 2 PgBouncers in poison mode (nopeers)—the worst-case scenario:
- TPS (green) crashes to near zero and stays there until
transaction_timeoutfires at t=60 - oldest_xact_age (purple) climbs steadily from 0 to 40 seconds
- Total Connections (brown) climb rapidly after poison injection at t=20 as failed cancels leave backends in CLOSE_WAIT
- Once Postgres hits
max_connections - superuser_reserved_connections (95), new connections are refused - PgBouncer #1 cl_waiting (red) and PgBouncer #2 cl_waiting (orange) then spike as clients queue up waiting for available connections
Note the gap between when transaction_timeout fires (t=60, visible as oldest_xact_age dropping to 0) and when TPS fully recovers. TPS recovery correlates with cl_waiting dropping back to zero—PgBouncer needs time to clear the queue of waiting clients and re-establish healthy connection flow. This recovery gap only occurs in nopeers mode; the TPS comparison graph shows that peers mode recovers immediately when the lock is released because connections never exhaust and cl_waiting stays at zero.
Why is AvgWait (blue) so low despite the system being in distress? The poisoned connection (holding the lock) continues executing transactions without blocking—it already holds the lock, so its queries succeed immediately. This one connection cycling rapidly through the pool with sub-millisecond wait times heavily skews the average lower, masking the fact that other connections are blocked.
The cl_waiting metric is collected as cnpg_pgbouncer_pools_cl_waiting from CloudNativePG. See CNPG PgBouncer metrics.
Monitoring and Alerting:
Alert on:
- Most Important:
cnpg_backends_max_tx_duration_secondsshowing transactions open for longer than some threshold cnpg_backends_totalshowing established connections at a high percentage ofmax_connections- Number of backends waiting on locks over some threshold
-- Count backends waiting on locks
SELECT count(*) FROM pg_stat_activity WHERE wait_event_type = 'Lock';
Prevention Options:
Options to prevent the root cause (connection pool poisoning):
- Find and fix connection leaks in the application – ensure all transactions are properly committed or rolled back
- Use
OptionResetSessioncallback – automatically discard leaked connections (see below) - Fix at the driver level – PR #2481 proposes automatic detection in pgx (not yet merged)
Options to prevent the escalation from row-level brownout to system outage:
- Enable PgBouncer peering – if using multiple PgBouncers behind a load balancer, configure the
peer_idand[peers]section so cancel requests are forwarded to the correct instance (see PgBouncer documentation). This prevents connection exhaustion but does not prevent the TPS drop from lock contention. - Use session affinity (sticky sessions) in the load balancer based on client IP – ensures cancel requests route to the same PgBouncer as the original connection (see HAProxy Session Affinity example below)
Options to limit the duration/impact:
- Set appropriate timeout defaults – configure system-wide timeouts to automatically terminate problematic sessions:
idle_in_transaction_session_timeout– terminates sessions idle in a transaction (e.g.,5min)transaction_timeout(Postgres 17+) – use caution; limits total transaction duration regardless of activity (e.g.,30min)
Potential Postgres Enhancement:
This would not address the root cause, but Postgres could better handle CLOSE_WAIT accumulation by checking socket status while waiting for locks. Since Postgres already checks for interrupts periodically (which is why cancels work), it’s possible that similar logic could detect forcibly closed sockets and clean up blocked backends sooner.
Results Summary, Understanding the Layers Leading to the System Outage, Unique Problems, and more - available in the full writeup at https://github.com/ardentperf/pg-idle-test/tree/main/conn_exhaustion
Postgres Booth at PASS Data Community Summit
PASS Data Community Summit 2025 wrapped up last week. This conference originated 25 years ago with the independent, user-led, not-for-profit “Professional Association for SQL Server (PASS)” and the annual summit in Seattle continues to attract thousands of database professionals each year. After the pandemic it was reorganized and broadened as a “Data Community” event, including a Postgres track.
Starting in 2023, volunteers from the Seattle Postgres User Group have staffed a postgres community booth on the exhibition floor. We provide information about Postgres User Groups around the world and do our best to answer all kinds of questions people have about Postgres. The booth consistently gets lots of traffic and questions.
The United States PostgreSQL Association has generously supplied one of their booth kits each year, which has a banner/background and some booth materials like stickers and a map with many user groups and a “welcome to postgres” handout and postgres major version handouts. We supplement with extra pins and stickers and printouts like the happiness hints I’ve put together, a list of common extensions that Rox made, and a list of Postgres events that Lloyd made. Every year, we also bring leftover Halloween candy that we want to get rid of and we put it in a big bowl on the table.
One of the top questions people ask is how and where they can learn more about Postgres. Next year I might just print out the Links section from my blog, which has a bunch of useful free resources. Another idea I have is for Redgate and EnterpriseDB – I think both of these companies have paid training but also give free access to a few introductory classes – it would be nice if they made a small card with a link to their free training. I think we could have a stack of these cards at our user groups and at the PASS booth. The company can promote paid training, but the free content can benefit anyone even if they aren’t interested in the paid training. I might also reach out to other companies who have paid training and see if they’d be willing to open up a bit of pre-recorded introductory content for free. (Data Egret? Creston Jamison?) Come to think of it, a list of weekly newsletters and podcasts might also be a great thing to print on a handout or a card – Postgres Weekly, postgres.fm, Talking Postgres, Scaling Postgres, etc.
The disk in the picture below is not from our booth; it’s an original SQL server installation disk and the crew over at Fortified apparently found a whole box of them on eBay and were handing them out over at their booth. As a result, I overheard someone explaining to another conference attendee what is a “floppy disk” and why does the bottom open. (In the background, on our booth table, you can see that I “fixed” the DocumentDB sticker…)

This year, I took my home office white board and drove it down to the convention center along with a bunch of magnets. Rick Lowe’s wife Becka picked up two wall-mount metal mesh file organizers and four S-hooks, which we hung on the white board and filled with handouts that Ben Chobot printed on his home printer. Thank you! This worked really well and you can see it in the picture below. It freed up space on the table for other things like pins and stickers, the raffle, and a very cool elephant that Lloyd brought.

As always: a huge shout-out to our local volunteers! From the left in the picture below: Lloyd Albin, me, Ben Chobot, Deon Gill, Rick Lowe, and… Pavlo Golub who is not technically local but joined us for our volunteer dinner/hangout! Harry Pierson missed our volunteer dinner but he’s on the right side in the booth picture above.

We raffled off a signed copy of Ryan Booz and Grant Fritchey’s new book: Introduction to PostgreSQL for the data professional. Congratulations to our winner – Tomi from Croatia!

Most of my time was at the booth. I had one speaking session on Friday, and spoke about CloudNativePG Quorum Failover. I originally intended to just expand the talk from KubeCon the week before. But I ended up heavily re-writing after realizing that out of 242 sessions at PASS there were only 6 that even mentioned Kubernetes. I ended up spending the first half of the talk with a simple introduction to containers and Kubernetes – a couple slides and then a terminal window with docker and kind to demonstrate the basics.
Finally, it was great fun to catch up with some old Oracle friends like Kellyn Gorman, Gustavo René Antúnez, Shane Borden and Gleb Otochkin. And of course it was great to see Lukas Fitl and Ryan Booz and Grant Fritchey. These are all solid, amazing people and if you ever see them at a conference then don’t hesitate to introduce yourself and strike up a conversation!
I enjoy traveling for conferences but I’m still in a season of limited travel for family reasons (and probably will be for awhile) – so I look forward to any time Postgres people visit Seattle. Helping organize the Postgres booth for PASS is a bit of work, but it’s worthwhile for the chance to connect. I look forward to seeing the Postgres track grow at PASS Data Community Summit!
KubeCon 2025: Bookmarks on Memory and Postgres
Just got home from KubeCon.
One of my big goals for the trip was to make some progress in a few areas of postgres and kubernetes – primarily around allowing more flexible use of the linux page cache and avoiding OOM kills with less hardware overprovisioning. When I look at Postgres on Kubernetes, I think there are idle resources (both memory and CPU) on the table with the current Postgres deployment models that generally use guaranteed QoS.
Ultimately this is about cost savings. I think we can still run more databases on less hardware without compromising the availability and reliability of our database services.
The trip was a success, because I came home with lots of reading material and homework!
Putting a few bookmarks here, mostly for myself to come back to later:
- key place for discussion is sig-node
- documentation on node-pressure eviction https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/
- eviction signal thresholds can be customized
- it looks like priority classes give a lot of control over the order in which pods are evicted
- documentation on priority classes https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/
- cgroups v2 memory controller documentation https://docs.kernel.org/admin-guide/cgroup-v2.html#memory
- long running github issue about pod evictions due to kubernetes (incorrectly?) interpreting active page cache as working memory that won’t be reclaimed https://github.com/kubernetes/kubernetes/issues/43916
- new feature MemoryQOS – still alpha (feature gate off-by-default)
- KEP https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2570-memory-qos/
- currently stalled – related message from Linux Kernel Mailing Lists https://lkml.org/lkml/2023/6/1/1300
- “Future: memory.high can be used to implement kill policies in for userspace OOMs, together with Pressure Stall Information (PSI). When the workloads are in stuck after their memory usage levels reach memory.high, high PSI can be used by userspace OOM policy to kill such workload(s).”
- Nov 2021 blog https://kubernetes.io/blog/2021/11/26/qos-memory-resources/
- May 2023 blog https://kubernetes.io/blog/2023/05/05/qos-memory-resources/
- Brief mention in docs https://kubernetes.io/docs/concepts/workloads/pods/pod-qos/#memory-qos-with-cgroup-v2
- KEP https://github.com/kubernetes/enhancements/tree/master/keps/sig-node/2570-memory-qos/
- metrics added to CAdvisor for both active and inactive page cache https://github.com/google/cadvisor/pull/3445
- metric added for PSI https://kubernetes.io/blog/2025/09/04/kubernetes-v1-34-introducing-psi-metrics-beta/
- homework – taking a closer look at anonymous memory and page cache metrics (both active and inactive) for real postgres databases on kubernetes
- homework – set up tests that emulate the diagram below and demonstrate the eviction behavior that i think will happen
I still have a lot of catching up to do. I sketched out the diagram below, but please take this with a large grain of salt – this aspect of kubernetes is complex and linux memory management is complex:

I tried to summarize some thoughts in a comment on the long-running github issue, but this might be wrong – it’s just what I’ve managed to piece together so far.
.
My “user story” is that (1) I’d like higher limit and more memory over-commit for page cache specifically – letting linux use available/unused memory as needed for page cache and (2) I’d like lower request to get scheduling closer to actual anonymous memory needs. I’m running Postgres. In the current state, I have to simultaneously set an artificially low limit on per-pod page cache (to avoid eviction) and artificially high request on per-pod anonymous memory (to avoid OOM by getting oom_score_adj). I’d like individual pods able to burst anonymous memory usage (eg. an unexpected SQL query that hogs memory), if we can steal from page cache of other pods beyond their request – avoiding OOM. The linux kernel can do this; I think it should be possible with the right cgroup settings?
It seems like the new Memory QOS feature might be assigning a static calculated value to memory.high – but for page cache usage, I wonder if we actually want kubernetes to dynamically adjust memory.high eventually as low as request in an attempt to reclaim node-level resources – before evicting end-user pods – when the memory.available eviction signal has exceeded the threshold?
Anyway it’s also worth pointing out that the postgres problems are likely accentuated by higher concentrations of postgres on nodes; if databases are spread across large multi-tenant clusters that likely mitigates things a bit.
Edit 11/29: Alexey Demidov replied on the github issue and pointed out the problem; the linux kernel throttles CPU of processes when we use memory.high so this probably makes my idea above ineffective.
Explaining IPC:SyncRep – Postgres Sync Replication is Not Actually Sync Replication
Postgres database-level “synchronous replication” does not actually mean the replication is synchronous. It’s a bit of a lie really. The replication is actually – always – asynchronous. What it actually means is “when the client issues a COMMIT then pause until we know the transaction is replicated.” In fact the primary writer database doesn’t need to wait for the replicas to catch up UNTIL the client issues a COMMIT …and even then it’s only a single individual connection which waits. This has many interesting properties.
One benefit is throughput and performance. It means that much of the database workload is actually asynchronous – which tends to work pretty well. The replication stream operates in parallel to the primary workload.
But an interesting drawback is that you can get into situations where the primary can speed ahead of the replica quite a bit before that COMMIT statement hits and then the specific client who issued the COMMIT will need to sit and wait for awhile. It also means that bulk operations like pg_repack or VACUUM FULL or REFRESH MATERIALIZED VIEW or COPY do not have anything to throttle them. They will generate WAL basically as fast as it can be written to the local disk. In the mean time, everybody else on the system will see their COMMIT operations start to exhibit dramatic hangs and will see apparent sudden performance drops – while they wait for their commit record to eventually get replicated by a lagging replication stream. It can be non-obvious that this performance degradation is completely unrelated to the queries that appear to be slowing down. This is the infamous IPC:SyncRep wait event.
Another drawback: as the replication stream begins to lag, the amount of disk needed for WAL storage balloons. This makes it challenging to predict the required size of a dedicated volume for WAL. A system might seem to have lots of headroom, and then a pg_repack on a large table might fill the WAL volume without warning.
This is a bit different from storage-level synchronous replication. With storage-level replication, each IO operation performing a write to the disk needs to be replicated. Postgres has a single WAL stream – so if any connection issues a COMMIT then postgres will immediately fsync the entire WAL stream up to that point – including all of the WAL for the bulk operation. In this way, the fsync works a little bit like the IPC:SyncRep wait – however I have a sense that fsync somehow introduces more backpressure into the system as a whole and likely provides at least a small amount of healthy throttling for large bulk operations.
When your workload consists ONLY of small short transactions, Postgres database-level replication can work really well and there’s back-pressure that keeps the database system in equilibrium. This Postgres database won’t lag because each individual transaction pauses. The problem is when you start injecting those big bulk operations with no back-pressure to throttle them.
This is also the reason why autovacuum_vacuum_cost_delay of zero can cause chaos and is a bad idea; it unleashes a vacuum running at full speed and generates massive & bursty amounts of WAL for large busy tables, as fast as it can write to the disk.
If you’re seeing the IPC:SyncRep wait event then one of the first things you should do is analyze your WAL activity. Something along these lines might be useful, if you’re debugging in real time (or add something similar to your monitoring system):
psql --csv -Xtc "create extension pg_walinspect"
psql --csv -Xtc "select now(),pg_current_wal_lsn()" >>wal-data.csv
while true; do
NEXTWAL=$(grep ^2025 wal-data.csv|tail -1|cut -d, -f2)
psql --csv -c "SELECT now(),pg_current_wal_lsn(),*
FROM pg_get_wal_stats('$NEXTWAL', pg_current_wal_lsn())" >>wal-data.csv
echo $(date) - $NEXTWAL
sleep 1
done
One potential idea for fixing this would be to add code into postgres vacuum and refresh materialized view and repack and copy which checks the value of the synchronous_commit parameter and performs periodic pauses according to how it’s set. This is a bit like the idea of doing “batch commits” during large bulk data loads, but we don’t need a real commit – we just need to periodically wait for the remote LSN to catch up, according to the value of synchronous_commit. This would provide a bit more healthy back-pressure to throttle those bulk operations, and might protect the rest of the system from such dramatic negative impact.
It might also be good to come up with some monitoring queries which can make it clear when a single connection is flooding the WAL stream with one bulk operation, versus an aggregate total across many write-heavy connections.
.

Sanitized SQL
A couple times within the past month, I’ve had people send me a message asking if I have any suggestions about where to learn postgres. I like to share the collection of links that I’ve accumulated (and please send me more, if you have good ones!) but another thing I always say is that the public postgres slack is a nice place to see people asking questions (Discord, Telegram and IRC also have thriving Postgres user communities). Trying to answer questions and help people out can be a great way to learn!
Last month there was a brief thread on the public postgres slack about the idea of sanitizing SQL and this has been stuck in my head for awhile.

The topic of sensitive data and SQL is actually pretty nuanced.
First, I think it’s important to directly address the question about how to treat databases schemas – table and column names, function names, etc. We can take our cue from the many industry vendors with data catalog, data lineage and data masking products. Schemas should be internal and confidential to a company – but they are not sensitive in the same way that PII or PCI data is. It’s generally okay to share schema information with vendors (for example, while working together on a support ticket for database performance). Within a company, it’s desirable for most schemas to be discoverable by engineers across multiple development teams – this is worth the benefits of better collaboration and better architecture of internal software.
General Principle: Schema = Source Code
Unfortunately, the versatile SQL language does not cleanly separate things. A SQL statement is a string that can mix keywords and schema and data all together. As Benoit points out in the slack thread – there are prepared (parameterized) statements, but you can easily miss a spot and end up with literal strings in queries. And I would add that most enterprises have the occasional need for manual “data fixes” which often involve simple scripts where literal values are common.
Benoit’s suggestion was to run a full parse of the query text. This is a good idea – in fact PgAnalyze already maintains a standalone open-source library which can be used to directly leverage Postgres’ query parser in many languages. This is really the best solution. However it is worth noting that I’m interested in cases of post-processing query texts from pg_stat_activity and pg_stat_statements, both of which have maximum lengths and will truncate text that’s longer. So query parsing would need to still work with truncated texts that throw syntax errors.
The PgAnalyze library approach is interesting, but I think a simple regex-based approach actually has a lot of merit. This can give very useful sanitized SQL for developers to debug, it has very low risk of exposing sensitive data, and the code is incredibly simple… especially compared with importing the entire postgres parser and trying to link to compiled C libraries in other languages!
Tonight I finally got around to a POC for this.
My design choices here were very intentional:
- I’m stripping out comments because libraries like sqlcommenter will add unique values via comments which break any ability to aggregate and summarize and report top queries or problem queries.
- I would always include the query_id alongside the sanitized SQL text. A user can always go back to the database later and look directly at pg_stat_statements to get the full query text as long as they have the Query ID.
- My decision to include the first three words (excluding comments) and two words following every occurrence of FROM is very strategic. In most cases (CTEs being the exception), the first three words will tell what kind of command is being executed – SELECT or DML or DDL or some utility/misc statement. By including two words after the command, we will generally see the table name for inserts and updates. By including words after FROM, we’ll know at least one of the tables being operated on for queries and deletes. This means we always know at a glance “it’s updating table X” or “it’s querying table Y”.
- When wait events indicate lock contention or increasing IO time, it’s extremely useful to see which tables are being operated on.
- There may be a few cases where this algorithm’s sanitized SQL isn’t as useful as it could be. But that’s why we include the Query ID for retrieving the full query text if needed – and my main goal here is just to have something that’s cheap/easy and helpful most of the time and that we can ensure is safe for developers and operators without requiring PII/PCI data controls.
- The likelihood of this algorithm emitting sensitive data is next-to-zero. We shouldn’t get literals from INSERTs or UPDATEs. Function and procedure calls must always include parentheses, so that’s mitigated with a simple regex to nuke anything after an open-parenthesis.
- If the string ‘FROM’ occurs in a string literal, then we aren’t going to distinguish that from a keyword. This is worth consideration; there is an injection vector here if you can spot it. But I don’t think it’s worthwhile to get fancy and attempt to parse SQL via regex. (As fun as that would be, simplicity/readability/maintainability wins here.) The SQL language is insanely sophisticated and if we’re going to parse then it’s the PgAnalyze way. But in practice, the actual surface area and exposure/leak risk with this regex-based function is very small and likely can be mitigated.
- This does not lessen the importance of good coding practices like parameterized SQL. This is just an additional layer of defense on top of that. Values correctly passed through parameterized SQL will never appear in a query text in the first place.
https://gist.github.com/ardentperf/44e94ac484e53ff8353f6c1dc0b8f272
Here’s what the code looks like:
CREATE OR REPLACE FUNCTION sanitize_sql(sql_text text)
RETURNS text AS $$
DECLARE
cleaned_text text;
first_part_regex_3words text := '([^[:space:]]+)[[:space:]]+([^[:space:]]+)[[:space:]]+([^[:space:]]+)';
first_part_regex_2words text := '([^[:space:]]+)[[:space:]]+([^[:space:]]+)';
first_part_regex_1words text := '([^[:space:]]+)';
first_part text;
match_array text;
from_parts_regex_3words text := '(FROM)[[:space:]]+([^[:space:]]+)[[:space:]]*([^[:space:]]*)';
from_parts text := '';
BEGIN
-- Remove multi-line comments (/* ... */)
cleaned_text := regexp_replace(sql_text, '/\*.*?\*/', '', 'g');
-- Remove single-line comments (-- to end of line)
cleaned_text := regexp_replace(cleaned_text, '--.*?(\n|$)', '', 'g');
-- Extract the first keyword and up to two words after it
first_part := array_to_string(regexp_match(cleaned_text,first_part_regex_3words),' ');
if first_part is null or first_part ILIKE '% FROM %' or first_part ILIKE '% FROM' then
first_part := array_to_string(regexp_match(cleaned_text,first_part_regex_2words),' ');
if first_part is null or first_part ILIKE '% FROM' then
first_part := array_to_string(regexp_match(cleaned_text,first_part_regex_1words),' ');
end if;
end if;
first_part := regexp_replace(first_part, '\(.*','(...)');
-- Find all occurrences of FROM and two words after each
FOR match_array IN
SELECT array_to_string(regexp_matches(cleaned_text,from_parts_regex_3words,'gi'),' ')
LOOP
match_array := regexp_replace(match_array, '\(.*','(...)');
from_parts := from_parts || '...' || match_array;
END LOOP;
-- Return combined result
RETURN first_part || from_parts;
END;
$$ LANGUAGE plpgsql;
postgres=# SELECT sanitize_sql($test$
SELECT pgp_sym_encrypt('123-45-6789', 'my_secret_key') AS encrypted_ssn;
$test$);
sanitize_sql
-----------------------------
SELECT pgp_sym_encrypt(...)
(1 row)
postgres=# SELECT sanitize_sql($test$
-- Fetch active users only
SELECT id, name -- user info
FROM users /* main table */
WHERE active = TRUE; /* status flag */
$test$);
sanitize_sql
------------------------------------
SELECT id, name...FROM users WHERE
(1 row)
postgres=# SELECT sanitize_sql($test$
SELECT id, name
FROM users
WHERE id IN (
/* subquery for high-value customers */
SELECT user_id -- link to users.id
FROM orders
WHERE total > 100 -- filter expensive orders
);
-- end of query
$test$);
sanitize_sql
--------------------------------------------------------
SELECT id, name...FROM users WHERE...FROM orders WHERE
(1 row)
postgres=# SELECT sanitize_sql($test$
-- recent orders per user
WITH recent_orders AS (
SELECT user_id, MAX(created_at) AS last_order
FROM orders
GROUP BY user_id /* aggregation */
)
SELECT u.name, r.last_order
FROM users u
JOIN recent_orders r ON u.id = r.user_id; -- join results
$test$);
sanitize_sql
----------------------------------------------------------
WITH recent_orders AS...FROM orders GROUP...FROM users u
(1 row)
postgres=# SELECT sanitize_sql($test$
INSERT INTO users (name, email, created_at)
VALUES (
'Alice', -- first name
'alice@example.com', /* email */
NOW() /* timestamp */
);
-- new user inserted
$test$);
sanitize_sql
-------------------
INSERT INTO users
(1 row)
postgres=# SELECT sanitize_sql($test$
UPDATE users
SET last_login = NOW() -- set current time
WHERE id = 42 /* target specific user */; -- done
$test$);
sanitize_sql
------------------
UPDATE users SET
(1 row)
postgres=# SELECT sanitize_sql($test$
/*
* Delete old sessions.
* Keep data from the last 30 days.
* Be careful: irreversible.
*/
DELETE FROM sessions
WHERE last_access < NOW() - INTERVAL '30 days';
$test$);
sanitize_sql
------------------------------
DELETE...FROM sessions WHERE
(1 row)
postgres=# SELECT sanitize_sql($test$
-- Upsert settings
INSERT INTO user_settings (user_id, theme, notifications)
VALUES (
1, /* user id */
'dark', -- theme
TRUE -- notifications on
)
ON CONFLICT (user_id)
DO UPDATE
SET theme = EXCLUDED.theme, -- overwrite
notifications = EXCLUDED.notifications;
$test$);
sanitize_sql
---------------------------
INSERT INTO user_settings
(1 row)
postgres=# SELECT sanitize_sql($test$
-- mark inactive users
WITH inactive_users AS (
SELECT id
FROM users
WHERE last_login < NOW() - INTERVAL '1 year' /* cutoff */
)
UPDATE users
SET active = FALSE
WHERE id IN (
SELECT id FROM inactive_users -- CTE reference
);
$test$);
sanitize_sql
--------------------------------------------------------------------
WITH inactive_users AS...FROM users WHERE...FROM inactive_users );
(1 row)
postgres=# SELECT sanitize_sql($test$
-- create table if missing
CREATE TABLE IF NOT EXISTS audit_log ( /* audit records */
id SERIAL PRIMARY KEY, -- identity column
user_id INT REFERENCES users(id), /* FK */
action TEXT NOT NULL, -- what happened
created_at TIMESTAMP DEFAULT NOW() /* timestamp */
);
$test$);
sanitize_sql
-----------------
CREATE TABLE IF
(1 row)
postgres=# SELECT sanitize_sql($test$
/*
This query finds top customers.
It uses multiple CTEs and subqueries.
*/
WITH order_totals AS (
SELECT user_id, SUM(total) AS lifetime_value
FROM orders
GROUP BY user_id -- one row per user
),
top_customers AS (
SELECT user_id
FROM order_totals
WHERE lifetime_value > 10000 /* threshold */
)
SELECT u.id, u.name, o.lifetime_value -- main output
FROM users u
JOIN order_totals o ON u.id = o.user_id
WHERE u.id IN (SELECT user_id FROM top_customers)
ORDER BY o.lifetime_value DESC /* high to low */
LIMIT 10; -- top 10
$test$);
sanitize_sql
---------------------------------------------------------------------------------------------------------------
WITH order_totals AS...FROM orders GROUP...FROM order_totals WHERE...FROM users u...FROM top_customers) ORDER
(1 row)
postgres=# SELECT sanitize_sql($test$
SELECT * FROM generate_series(1,10);
$test$);
sanitize_sql
--------------------------------------
SELECT *...FROM generate_series(...)
(1 row)
postgres=# SELECT sanitize_sql($test$
DO $$
DECLARE
tbl RECORD;
BEGIN
OPEN table_cursor;
LOOP
FETCH table_cursor INTO tbl;
EXIT WHEN NOT FOUND;
EXECUTE 'VACUUM ' || tbl.tablename;
END LOOP;
CLOSE table_cursor;
END $$;
$test$);
sanitize_sql
---------------
DO $$ DECLARE
(1 row)
postgres=# SELECT sanitize_sql($test$
-- Declare a cursor for employees in Engineering
DECLARE emp_cursor CURSOR FOR
SELECT id, name, salary
FROM employees
WHERE department = 'Engineering';
$test$);
sanitize_sql
--------------------------------------------------
DECLARE emp_cursor CURSOR...FROM employees WHERE
(1 row)
postgres=# SELECT sanitize_sql($test$
SELECT
c.name AS customer_name,
o.order_id,
o.order_date,
oi.product_name,
oi.quantity,
'Orders coming from customers are listed below' AS description
FROM customers c, orders o, order_items oi
WHERE c.customer_id = o.customer_id
AND o.order_id = oi.order_id
ORDER BY c.name, o.order_date;
$test$);
sanitize_sql
-----------------------------------------------------------
SELECT c.name AS...from customers are...FROM customers c,
(1 row)
.
Seattle Postgres User Group Video Library
Are you in the Pacific Northwest?
- Thursday Nov 6 at 6pm Bohan Zhang – a member of the technical staff at OpenAI – is returning to speak again at the Seattle Postgres User Group! This time, Bohan will be talking about how OpenAI runs Postgres – challenges faced, lessons learned from outages, and strategies implemented to scale PostgreSQL to handle millions of queries per second (QPS).
- Seattle Systems meetup still needs meetup locations to host us. If you are a company in the Seattle area with space for an in-depth technical talk and 50-100 people, then please reach out to Sitesh (I can help get you in touch).
Since January 2024 we’ve been recording the presentations at Seattle Postgres User Group. After some light editing and an opportunity for the speaker to take a final pass, we post them to YouTube. I’m perpetually behind (I do the editing myself) so you won’t find the videos from this fall yet – but we do have quite a few videos online! Many of these are talks that you can’t find anywhere else. We definitely love out-of-town speakers – but an explicit goal of the user group is also to be an easy place for folks here in Seattle to share what we know with each other, and to be an easy place for people to try out speaking with a small friendly group if they never have before.
https://www.youtube.com/@seattle-postgres
DateSpeakerTitleJune 12 2025Noah BaculiFrom Side Projects: Why We Chose Rust for Postgres + AI (YouTube)May 7 2025Gwen ShapiraRe-engineering Postgres for Millions of Tenants (YouTube)April 10 2025Jonathan KatzVectors: Best practices for a nasty data type (YouTube)March 6 2025Harry PiersonTime Travel Queries with Postgres (YouTube)February 6 2025Rishu BaggaManaging Transaction Metadata in PostgreSQL (YouTube)December 5 2024Kellyn GormanBenchmarking PostgreSQL-Compatible DBs with HammerDB (YouTube)October 10 2024Saraj MunjalDDL Schema Migrations: Navigating the High-Scale Seas (YouTube)September 5 2024Ben ChobotSecure pgBouncer: Break Up With Passwords and Hook Up with AWS Aurora (YouTube)June 6 2024Deon GillSo You Want to Build a Postgres Server (YouTube)May 2 2024Eric LendvaiDatawharf and Wharf Systems (YouTube)April 4 2024Jerry SievertDeveloping Your Own Postgres Database Extensions (YouTube)March 7 2024Bohan ZhangThe Part Of PostgreSQL I Hate The Most: MVCC and How To Optimize It (YouTube)January 18 2024Chelsea DoleIt’s Not You, It’s Me: “Breaking Up” With Massive Tables via Partitioning (YouTube)March 2 2023—Thoughts & Opportunities – Seattle PostgreSQL User Group (intro) (YouTube)By the way – if you’re wondering why our logo is a giant pink elephant, it’s because this is actually a well-known real historical landmark in Seattle!
https://www.meetup.com/seattle-postgres/

A couple people have noticed that we haven’t taken down the old website (which predated the meetup.com site) at https://seapug.org/ … we’ve been talking for several years now about updating this site but we’re all so busy that nothing has happened yet. Regardless, this site is an interesting window into Seattle Postgres User Group meetups all the way back to 2009 (!!)
Testing CloudNativePG Preferred Data Durability
This is the third post about running Jepsen against CloudNativePG. Earlier posts:
- Run Jepsen against CloudNativePG to see sync replication prevent data loss
- Losing Data is Harder Than I Expected
First: shout out to whoever first came up with Oracle Data Guard Protection Modes. Designing it to be explained as a choice between performance, availability and protection was a great idea.
Yesterday’s blog post described how the core of all data safety is copies of the data, and the importance of efficient architectures to meet data safety requirements.
With Postgres, three-node clusters ensure the highest level of availability if one host fails. But two-node clusters are often worth the cost savings in exchange for a few seconds of unavailability during cluster reconfigurations. Similar to Oracle, Postgres two-node clusters can be configured to maximize performance or availability or protection.
Oracle Data Guard modeBehaviorPatroni configurationCloudNativePG configurationMax Performanceoracle defaultAsync; fastest commits; possible data loss on failoverpatroni defaultcnpg defaultMax Availability (NOAFFIRM)Sync when standby available; acknowledge after standby write (not flush); if none available, don’t block
synchronous_mode: truesynchronous_commit: remote_writemethod: anynumber: 1dataDurability: preferredsynchronous_commit: remote_writeMax Availability (AFFIRM)Sync when standby available; acknowledge after standby flush; if none available, don’t blocksynchronous_mode: truemethod: anynumber: 1dataDurability: preferredMax ProtectionAlways sync; if no sync standby, block commits (no data loss)synchronous_mode: truesynchronous_mode_strict: truemethod: anynumber: 1
Automated failovers can involve a small amount of data loss with maximum performance and maximum availability configurations. With Oracle Fast-Start Failover, the FastStartFailoverLagLimit configuration property indicates the maximum amount of data loss that is permissible in order for an automatic failover to occur.
The previous blog post in this series compared CloudNativePG Max Performance and Max Protection modes. Now I want to take a look at Max Availability. In CloudNativePG, the key setting here is spec.postgresql.synchronous.dataDurability. When dataDurability is set to preferred, the required number of synchronous instances adjusts based on the number of available standbys. PostgreSQL will attempt to replicate WAL records to the designated number of synchronous standbys, but write operations will continue even if fewer than the requested number of standbys are available.
All of these experiments were executed on my HP EliteBook (Ryzen Pro 5) with two CNPG Lab VMs via Hyper‑V and the tests ran in a loop for 12–24 hours to aggregate failure rates across the runs.
Experiment 1Using the same test harness as before to indice rapid failures. The test harness waits for all replicas to be READY (per k8s) and then immediately kills the writer.
Hypothesis: in max protection mode we won’t see any data loss, but we will see data loss in max availability mode. Adding a third node to the cluster should reduce the likelihood of data loss.
dataDurabilityinstancesruns showing data lossrequired20% [results]preferred248% [results]preferred34% [results]Findings: Setting dataDurability: preferred in CloudNativePG allows for higher availability but can result in data loss during failover, especially in smaller clusters. I was surprised how much the third node helped.
Hypothesis A: I was seeing a high failure rate specifically because the rapid failures were triggering a failover before CloudNativePG had enough time to restart synchronous replication after the last failure. If there are 60 seconds between each failure, then we shouldn’t see any data loss.
Hypothesis B: CloudNativePG has a failoverDelay setting which can inject a delay before the CNPG reconciliation loop triggers a failover when the primary is unhealthy. If we set this to 60 seconds then we shouldn’t see any data loss.
nb. I also switched to running the latest development build from the trunk of CloudNativePG. (Separately, I had wanted to test some code that was checked in the day before I ran these tests.)
seconds between killsfailoverDelayruns showing data loss0040% [results]6004% [results]0600% [results]Findings: Introducing a delay – either by spacing out failures or by configuring failoverDelay – dramatically reduced or eliminated data loss in preferred mode. When failures occurred back-to-back with no delay, data loss was frequent. However, waiting 60 seconds between failures, or setting a 60-second failoverDelay, allowed CloudNativePG enough time to reestablish synchronous replication, resulting in little or no data loss.
CloudNativePG’s preferred data durability mode offers data safety and high availability with lower-cost two-node clusters by allowing commits to proceed even if the synchronous standby is temporarily unavailable. However, this flexibility comes with a small risk of data loss during failover, especially when failures happen in rapid succession. Introducing delays via the failoverDelay setting minimizes risk. For environments where data durability is paramount, three-node clusters in required mode remain the safest choice, but for those willing to trade a small risk of data loss for improved availability, two-node clusters in preferred mode can be a practical option. Consider setting failoverDelay alongside preferred durability for extra safety.
Data Safety on a Budget
Many experienced DBAs joke that you can boil down the entire job to a single rule of thumb: Don’t lose your data. It’s simple, memorable, and absolutely true – albeit a little oversimplified.
Mark Porter’s Cultural Hint “The Onion of our Requirements” conveys the same idea with a lot more accuracy:
We need to always make sure we prioritize our requirements correctly. In order, we think about Security, Durability, Correctness, Availability, Scalability via Scale-out, Operability, Features, Performance via Scaleup, and Efficiency. What this means is that for each item on the left side, it is more important than the items on the right side.
But this does not tell the whole story. If we’re honest, there is one critical principle of equal importance to everything on this list: Don’t lose all your money.
Every adult who’s managed their own finances knows we don’t have infinite money. Yes we want to keep the data safe. We also want to be smart about spending our money.
Relational databases are one of the most powerful and versatile places to store your data – and they are also one of the most expensive places to store your data. Just look at the per-GB pricing of block storage with provisioned IOPS and low latency, then compare with the pricing of object storage. No contest. Any time a SQL database is beginning to approach the TB range, we definitely should be looking at the largest tables and asking whether significant portions of that data can be moved to cheaper storage – for example parquet files on S3. (Or F3 files?)
Of course, sometimes we need fast powerful SQL and joins and transactions. So relational databases also should run as efficiently as possible. This has direct implications around how we keep the data safe.
From personal photos to enterprise databases, the core of all data safety is copies of the data. Logs and row-store/column-store files (and indexes) are data copies in different formats. You could almost parse the entire database industry through a lense that compares how each technology is just a unique way to replicate data between different formats and places. The revered and time-honored “3-2-1 Backup Rule” is all about copies of the data. From an information theory standpoint, it can be argued that even RAID5 parity, checksums, CRCs, and hashes are a shadow or fingerprint “copy” of the original – even though they aren’t literal full copies of the data.
One of my favorite cultural hints from Mark is: Don’t Let Entropy Win.
In the absence of people making things better, they will get worse. It’s just a fact.
This isn’t Mark’s point, but I think it’s a related concept: at every business that’s successful enough to grow large, there is a natural gravitation toward forming silos of technology. I think of this as a kind of entropy that we need to actively counteract in every large business. Lets look at an example where an enterprise business team building a public API needs a 600GB write-intensive database. Suppose we can buy enterprise grade high-endurance NVMe SSDs (handling write-intensive database workloads) for $1000 each. How much will the storage cost to “keep the data safe” for this public API?
- The business team provisions three environments: one for production and two more for development and testing.
- For business continuity in case of regional problems, the database team creates primary and replica CloudNativePG clusters, so that we are able to run from either of our two regions.
- To maintain high availability, the database team configures CloudNativePG with three instance within each region and they configure preferred anti-affinity so that kubernetes will attempt to schedule the three instances in different buildings or availability zones.
- Persistent storage is provided by the storage team who configures ceph volumes backed by two mirror copies.
- Object storage for backups uses two mirror copies.
- Servers are built by the infrastructure team who configure RAID 1 (mirroring).
In the worst case, we can easily end up spending $96,000 on disks alone – for a database that can fit on a single $1000 enterprise drive! Now that is some crazy storage amplification.

In order to take a smarter approach, lets work backwards from the problems we’re solving. When we say “keep the data safe” – what are some specific situations we want to protect the data from?
- Unavailability during maintenance & deployments at all levels of the stack
- Operational mistakes
- Software bugs at all levels of the stack, from business app to firmware
- Hardware failures of disks
- Hardware failures of servers/compute which can make good disks temporarily inaccessable
- External threats from direct attacks, malware, social engineering, supply chain attacks, etc
- Insider threats arising from situations like personal grievances or personal financial pressures
- Natural disasters (and perhaps political disasters…)
Armed with a list, we can now ask ourselves: what is an economical solution that addresses everything here? There isn’t one right answer but we probably don’t need 12 physical copies of each database per data center. A few ideas:
- Three CNPG instances that use local SSD storage directly (no hardware RAID), for a total of three copies in the primary data center.
- Two or three CNPG instances that use either ceph block storage or local SSD with hardware RAID (but not both) for a total of four or six copies in the primary data center.
- A single CNPG instance in the second data center, with the capability to dynamically add instances on switchovers/failovers.
- Slower, less expensive disks for development databases.
- No CNPG instance for immediate switchover/failover of development databases in second data center.
- Testing tier that matches production config but can be provisioned on demand from backups for load testing, and deprovisioned when unused for some period of time. Development tier also provisioned on demand and deprovisioned when unused for some period of time.
There are many ways to keep data safe on a reasonable budget – these are just a few ideas.
Postgres Replication Links
Our platform team has a regular meeting where we often use ops issues as a springboard to dig into Postgres internals. Great meeting today – we ended up talking about the internal architecture of Postgres replication. Sharing a few high-quality links from our discussion:
Alexander Kukushkin’s conference talk earlier this year, which includes a great explanation of how replication works
- https://posetteconf.com/speakers/alexander-kukushkin/
- https://www.youtube.com/watch?v=PFn9qRGzTMc
- https://www.postgresql.eu/events/pgconfde2025/sessions/session/ 6559-myths-and-truths-about-synchronous-replication-in-postgresql/
- https://www.postgresql.eu/events/pgconfde2025/sessions/session/ 6559/slides/663/Myths%20and%20Truths%20about%20 Synchronous%20Replication%20in%20PostgreSQL.pdf
Alexander’s interview on PostgresTV with Nik Samokhvalov
PostgresFM episode about synchronous_commit
Postgres Documentation for pg_stat_replication system catalog (most important source of replication monitoring data)
CloudNativePG source code that translates pg_stat_replication data into prometheus metrics
- https://github.com/cloudnative-pg/cloudnative-pg/blob/main/config/manager/default-monitoring.yaml#L385
Chapter about streaming replication in Hironobu Suzuki’s book, Internals of PostgreSQL
Here is very helpful diagram from Alexander’s slide deck, which we referenced heavily during our discussion.
Can you identify exactly where in this diagram the three lag metrics come from? (write lag, flush lag and replay lag)

Losing Data is Harder Than I Expected
This is a follow‑up to the last article: Run Jepsen against CloudNativePG to see sync replication prevent data loss. In that post, we set up a Jepsen lab to make data loss visible when synchronous replication was disabled — and to show that enabling synchronous replication prevents it under crash‑induced failovers.
Since then, I’ve been trying to make data loss happen more reliably in the “async” configuration so students can observe it on their own hardware and in the cloud. Along the way, I learned that losing data on purpose is trickier than I expected.
Methodology and a Kubernetes caveatTo simulate an abrupt primary crash, the lab uses a forced pod deletion, which is effectively a kill -9 for Postgres:
kubectl delete pod -l role=primary --grace-period=0 --force --wait=false
This mirrors the very first sanity check I used to run on Oracle RAC clusters about 15 years ago: “unplug the server.” It isn’t a perfect simulation, but it’s a simple, repeatable crash model that’s easy to reason about.
I should note that the label role is deprecated by CNPG and will be removed. I originally used it for brevity, but I will update the labs and scripts to use the label cnpg.io/instanceRole instead.
After publishing my original blog post, someone pointed out an important Kubernetes caveat with forced deletions:
Irrespective of whether a force deletion is successful in killing a Pod, it will immediately free up the name from the apiserver. This would let the StatefulSet controller create a replacement Pod with that same identity; this can lead to the duplication of a still-running Pod
https://kubernetes.io/docs/tasks/run-application/force-delete-stateful-set-pod/
This caveat would apply to the CNPG controller just like a StatefulSet controller. In practice, for my tests, this caveat did not undermine the goal of demonstrating that synchronous replication prevents data loss. The lab includes an automation script (Exercise 3) to run the 5‑minute Jepsen test in a loop for many hours and collect results automatically.
Hardware used included an inexpensive HP EliteBook (Ryzen Pro 5, $299 on Amazon) with two CNPG Lab VMs via Hyper‑V, plus multiple cloud instance types. I ran long‑burner loops (8–20 hours) and aggregated failure rates across configurations.
I’m considering bringing Chaos Mesh into the lab in the future, but for now I’m sticking with the explicit crash model above because it’s easy for folks to see exactly what it does.
High‑level results:
- With synchronous replication: 1,061 five‑minute runs, 0 data‑loss failures.
- With asynchronous replication: 1,448 runs, 478 data‑loss failures.
These are the total counts across all runs from three different sets of experiments.
Experiment 1: Checkpoints and replica countHypothesis A: Increase replication traffic (shorter checkpoints which causes more FPWs) to raise odds of “unshipped” WAL at crash ⇒ more losses with async.
Hypothesis B: Fewer replicas (2 instances total instead of 3) might make losses more likely.
Each row below shows the fraction of async runs that showed data loss.
I also ran two of the configurations with sync replication enabled. No data loss was observed in either of the runs with sync replication.
Checkpoint3 instances2 instances5 min (default)5% [async results] / 0% [sync]24% [async results]30 second5% [async results]15% [async results] / 0% [sync]Findings: Hypothesis B was right—2 instances amplified data loss. Hypothesis A was wrong—shorter checkpoints did not increase loss rates here and even correlated with slightly fewer losses.
Experiment 2: Jepsen rate and thread countI varied the transaction rate and the number of client threads. My intuition was that higher rates would increase the chance of a commit landing during a crash window, and that fewer threads might improve per‑thread throughput (given CPU saturation).
Rate50 threads20 threads100024% [cf. experiment 1]8% [results]200051% [results]38% [results]300080% [results]39% [results]4000N/A [results]N/AFindings: Higher rates increased loss frequency (as expected). Reducing thread count lowered CPU pressure and but surprisingly it also reduced loss frequency—even when achieving similar rates. The “4000” rate did not complete successfully; Jepsen analysis stalled and timed out.
The most reliable async configuration for provoking visible loss so far: 2 instances total, rate 3000, 50 threads.
 Experiment 3: Hardware differences
Experiment 3: Hardware differences
To ensure reproducibility beyond my laptop, I repeated runs on several cloud instance types.
HardwareasyncsyncAWS m7g26% [results]0% [results]AWS m6g23% [results]0% [results]Azure Dpsv651% [results]0% [results]HP Elitebook (Ryzen 5675U)75% [results]0% [results]I didn’t expect the spread in async failure rates. My current guess is that some combination of CPU and/or IO saturation characteristics change the window for unreplicated commits. The takeaway for teachers and students: if you want to reliably see data loss, Azure Dpsv6 performed best in my runs (about half of iterations saw data loss).
What this means- Synchronous replication remains the guardrail. Across thousands of minutes of testing, I did not observe a single instance of data loss with sync enabled under these test configurations.
- Topology matters. Two instances (one replica) increases the chance of async loss versus three instances.
- Workload shape matters. Higher rates raise loss frequency; fewer client threads can reduce it even at similar throughput.
- Hardware matters. Different CPU/IO profiles change how often you’ll catch an in‑flight commit during a crash.
Use the CloudNativePG LAB and Exercise 3 to run the Jepsen “append” workload and induce rapid primary failures. The looped test and automatic report upload are included. If your goal is to demonstrate loss in async mode, start with:
- 2 instances
- rate 3000
- 50 threads
If Jepsen analysis is stalling and timing out then try reducing the rate to 2000. And if you have the option, try Azure Dpsv6 for the highest chance of observing loss quickly.
Waiting for Postgres 18 – Docker Containers 34% Smaller
On February 25, 2025 Christoph Berg committed the patch:
Subject: [PATCH] Move JIT to new postgresql-18-jit package. (Closes: #927182)
Make LLVM architectures a inclusion list so it works in the Architecture field.
This closed Debian bug 927182 which had been opened in April 2019 by Laurence Parry. That bug had raised concerns over the significant size increase of adding LLVM as a requirement to support Postgres JIT functionality.
Postgres supports packaging LLVM as a separate optional package without needing to recompile database binaries. Postgres is compiled once, and it performs a runtime check whether LLVM libraries are present. It gracefully disables JIT functionality in the database if LLVM libraries are not installed.
From: Andres Freund
Subject: Re: llvm dependency and space concerns
Date: 2025-01-12 00:03:43
Lists: pgsql-hackers
Hi,
On 2025-01-11 13:22:39 -0800, Jeremy Schneider wrote:
> It's a cleaner solution if JIT works more like an extension, and we can
> run a single build and split JIT into a separate package.
It does work like that. Only llvmjit.so has the llvm dependency, the main
postgres binary doesn't link to llvm. If llvmjit.so isn't available, jit is
silently disabled.
Andres
In the official community Postgres RPM/yum repository LLVM was split out to a separate package – but it had never been prioritized in the official community Debian repositories to make these code updates until now.
Christoph noted on the mailing lists that the work is not yet finished – there is still a little more that needs to be done:
From: Christoph Berg
Cc: pgsql-pkg-debian@lists.postgresql.org
Subject: Re: pg18 patch: separate package for llvm/jit
Date: Fri, 28 Feb 2025 16:02:42 +0100
Re: Jeremy Schneider
> I would like to propose this change for Postgres 18.
Hi,
I committed a change to the PG18 packaging that implements that split.
The new package is called postgresql-18-jit.
There is more work to do on each of the extension packages currently
depending on "postgresql-18-jit-llvm (= llvmversion)", that needs to be
converted to "Breaks: postgresql-18-jit-llvm (<< llvmversion)". (This
is also the reason the jit package is not called like that because the
version number there is not the PG version number.)
This will likely happen when extensions are moved to PG18 in
September.
I'm unsure if the split should be backported to PG 17 and earlier
since it will affect production systems in some way.
Christoph
CloudNativePG running on Kubernetes is a fully automated control plane that uses container images and keeps your Postgres databases running reliably, backed up, simple to patch/update and able to recover on their own if something goes wrong. The official container images provided by CloudNativePG directly use the official “PGDG” Postgres community Debian packages on top of the official docker-provided “slim” debian base image. This has the benefit that CNPG users are part of the “herd” using the same binaries which are used by Debian Postgres users globally; we’re not going to hit any corner cases from compilation flags or configure options that aren’t widely used. Another commonly used container is the Docker “official image” that you get when you type docker run postgres – these images also directly use the official Postgres community Debian packages by default.
Generally speaking, the size of docker containers can vary widely. Minimizing dependencies and reducing container size has many benefits: less stuff to patch and update over time, fewer things that can get CVEs, fewer unnecessary utilities that can be leveraged by attackers, faster build times, less disk space usage, reduced network consumption and faster startup times in environments where containers are often migrated and rescheduled across fleets (moving to new hardware where those containers had never previously run, and thus images need to be downloaded).
Let’s take a look at the sizes of common Postgres containers:
# docker images
REPOSITORY TAG SIZE
ghcr.io/cloudnative-pg/postgresql 17.4-standard-bookworm 641MB
ghcr.io/cloudnative-pg/postgresql 17.4-minimal-bookworm 413MB
postgres 17.4-bookworm 438MB
postgres 17.4-alpine3.21 278MB
Docker provides an official Postgres image based on Alpine (a Linux distribution designed to be small, simple and secure). Postgres is built from source for the Alpine container. Alpine uses the musl C library which doesn’t have the same adoption level in the general public and test coverage in the postgres community build farm as the GNU C library. Nonetheless, we see above that Docker’s official Alpine postgres image is 36% smaller than Docker’s official Debian Bookworm image. (From 438MB down to 278MB.)
Interestingly, LLVM alone seems responsible for half of the Alpine image’s size!
# docker run -it postgres:17.4-alpine3.21 apk info llvm19-libs
WARNING: opening from cache https://dl-cdn.alpinelinux.org/alpine/v3.21/main: No such file or directory
WARNING: opening from cache https://dl-cdn.alpinelinux.org/alpine/v3.21/community: No such file or directory
llvm19-libs-19.1.4-r0 description:
LLVM 19 runtime library
llvm19-libs-19.1.4-r0 webpage:
https://llvm.org/
llvm19-libs-19.1.4-r0 installed size:
153 MiB
The Alpine build might be useful for use cases where every byte matters – but it’s lacking in one of Postgres greatest strengths: extensibility. Another significant advantage of leveraging the community Debian packages is that we get free access to all of the Postgres Extensions that are already packaged for Debian. Adding a supported extension to a container is a one-liner change to the Dockerfile!
CloudNativePG builds and provides their own images on the Github Container Registry. At present there are two flavors of CNPG images: “minimal” and “standard”.
The CNPG minimal image is 413MB – about the same size as the docker image without any extensions or extras.
The CNPG standard image 641MB and includes three default extensions (pgvector, pgaudit and pg-failover-slots) as well as all Debian-supported glibc locales. The locales are responsible for 99% of the size increase.
# docker run -it ghcr.io/cloudnative-pg/postgresql:17.4-standard-bookworm dpkg-query --show --showformat='${Package}\t${Installed-Size} KB\n' locales-all postgresql-17-pgvector postgresql-17-pgaudit postgresql-17-pg-failover-slots
locales-all 227366 KB
postgresql-17-pg-failover-slots 101 KB
postgresql-17-pgaudit 106 KB
postgresql-17-pgvector 767 KB
Most users should not need these Debian glibc locales, especially since these images include ICU (which interestingly is much smaller than the Debian locales-all package). Most of us should be starting with the minimal image and customizing it with only the extensions we need.
But what about LLVM? Christoph’s commit should make JIT an optional install instead of a required install; how will this impact the minimal image size?
It took me a little work to get the syntax right, but it turns out this wasn’t too hard to test by tweaking the CNPG Dockerfile to use the official postgres community pg18 debian package snapshots.
https://github.com/ardentperf/postgres-containers/commit/6388113b36824e3a88f47faabf0ddd386b96e41a
Author: Jeremy Schneider <schneider@ardentperf.com>
Date: Sun Apr 6 21:58:45 2025 -0700
test pg18 development snapshots https://wiki.postgresql.org/wiki/Apt/FAQ#Development_snapshots
diff --git a/Dockerfile b/Dockerfile
index d4f02b7..8a03349 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -8,7 +8,12 @@ ENV PATH=$PATH:/usr/lib/postgresql/$PG_MAJOR/bin
RUN apt-get update && \
apt-get install -y --no-install-recommends postgresql-common ca-certificates gnupg && \
- /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh -y && \
+ true
+
+COPY pg18snapshot.pref /etc/apt/preferences.d/
+COPY pg18snapshot.list /etc/apt/sources.list.d/
+
+RUN apt-get update && \
apt-get install -y --no-install-recommends -o Dpkg::::="--force-confdef" -o Dpkg::::="--force-confold" postgresql-common && \
sed -ri 's/#(create_main_cluster) .*$/\1 = false/' /etc/postgresql-common/createcluster.conf && \
apt-get install -y --no-install-recommends \
diff --git a/pg18snapshot.list b/pg18snapshot.list
+deb [signed-by=/usr/share/postgresql-common/pgdg/apt.postgresql.org.asc] http://apt.postgresql.org/pub/repos/apt/ bookworm-pgdg-snapshot main 18
diff --git a/pg18snapshot.pref b/pg18snapshot.pref
+Package: *
+Pin: origin apt.postgresql.org
+Pin-Priority: 1001
First I built version 17.4 locally to confirm that I would get the same size container as what’s in the official registry. Then I used the modified Dockerfile to build version 18.
# git checkout main
Switched to branch 'main'
Your branch is up to date with 'origin/main'.
# docker build . --target minimal --tag minimal17 --build-arg PG_VERSION=17.4
[+] Building 0.1s (7/7) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 1.35kB 0.0s
=> [internal] load metadata for docker.io/library/debian:bookworm-slim 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [minimal 1/3] FROM docker.io/library/debian:bookworm-slim 0.0s
=> CACHED [minimal 2/3] RUN apt-get update && apt-get install -y --no-install-recommends postgresql-common ca-certificate 0.0s
=> CACHED [minimal 3/3] RUN usermod -u 26 postgres 0.0s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:d2d9baf4d2384dbfe58cd14bd0adc5aaca2beff95a4a7e37712ddc26f14a3a7d 0.0s
=> => naming to docker.io/library/minimal17 0.0s
# git checkout test18
Switched to branch 'test18'
Your branch is up to date with 'ardent/test18'.
# docker build . --target minimal --tag minimal18 --build-arg PG_VERSION=18
[+] Building 0.1s (11/11) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 1.42kB 0.0s
=> [internal] load metadata for docker.io/library/debian:bookworm-slim 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [minimal 1/6] FROM docker.io/library/debian:bookworm-slim 0.0s
=> [internal] load build context 0.0s
=> => transferring context: 298B 0.0s
=> CACHED [minimal 2/6] RUN apt-get update && apt-get install -y --no-install-recommends postgresql-common ca-certificate 0.0s
=> CACHED [minimal 3/6] COPY pg18snapshot.pref /etc/apt/preferences.d/ 0.0s
=> CACHED [minimal 4/6] COPY pg18snapshot.list /etc/apt/sources.list.d/ 0.0s
=> CACHED [minimal 5/6] RUN apt-get update && apt-get install -y --no-install-recommends -o Dpkg::::="--force-confdef" -o 0.0s
=> CACHED [minimal 6/6] RUN usermod -u 26 postgres 0.0s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:c2471c9180750c1983177693ef21b609443c4b5aa89f9f5ffe9cb8e159ebe00d 0.0s
=> => naming to docker.io/library/minimal18 0.0s
# docker images
REPOSITORY TAG SIZE
minimal18 latest 262MB
minimal17 latest 413MB
ghcr.io/cloudnative-pg/postgresql 17.4-standard-bookworm 641MB
ghcr.io/cloudnative-pg/postgresql 17.4-minimal-bookworm 413MB
postgres 17.4-bookworm 438MB
postgres 17.4-alpine3.21 278MB
The minimal CNPG image for Postgres 18 is 262MB – that’s 34% smaller than the minimal CNPG image for Postgres 17 of 413MB.
This is great news – another reason to look forward to Postgres 18!
Testing loadBalancerSourceRanges with CloudNativePG on Azure Kubernetes
This option didn’t seem super widely documented from my initial searches online; it should be able to basically enforce layer 4 ingress/firewall rules at the individual service level. This is a quick test to check if it works.
Steps were generated with ChatGPT, and mostly worked. It missed Azure provider registration, but I figure that out easily from the Azure error message. GPT was creating the VMs after the CNPG cluster … I had to reverse that so I’d know the IP for loadBalancerSourceRanges. I had to switch the VMs to the “westus” region because of quota limits. There were a couple more tweaks but overall I got this done in an hour or two – couldn’t have done that with just google.
I used an Azure free account; never had to set up a credit card with Azure. Note that free accounts are limited to 30 days and only available for new users. This blog post happened to be the first time I’d used azure with my personal account so it qualified. I’ll need to use a pay-as-you-go account in the future.
Step 1: Create an AKS ClusterCreate resource group
az group create --name myResourceGroup --location eastus
{
"id": "/subscriptions/7460cc93-ed07-42e7-a246-3b87e52a3ad7/resourceGroups/myResourceGroup",
"location": "eastus",
"managedBy": null,
"name": "myResourceGroup",
"properties": {
"provisioningState": "Succeeded"
},
"tags": null,
"type": "Microsoft.Resources/resourceGroups"
}
Register the provider
az provider register --namespace Microsoft.ContainerService
Registering is still on-going. You can monitor using 'az provider show -n Microsoft.ContainerService'
Create AKS cluster
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--network-plugin kubenet \
--network-policy calico \
--load-balancer-sku standard \
--node-count 2 \
--enable-managed-identity \
--generate-ssh-keys
{
"aadProfile": null,
"addonProfiles": null,
"agentPoolProfiles": [
{
"availabilityZones": null,
"capacityReservationGroupId": null,
"count": 2,
...
"upgradeSettings": null,
"windowsProfile": null,
"workloadAutoScalerProfile": {
"keda": null,
"verticalPodAutoscaler": null
}
}
get cluster credentials
az aks get-credentials --resource-group myResourceGroup --name myAKSCluster
Merged "myAKSCluster" as current context in /home/jeremy/code/cnpg-playground/k8s/kube-config.yaml
Installing CNPG with helm
helm repo add cnpg https://cloudnative-pg.github.io/charts
helm repo update
helm install cnpg cnpg/cloudnative-pg --namespace cnpg-system --create-namespace
NAME: cnpg
LAST DEPLOYED: Fri Mar 14 00:01:16 2025
NAMESPACE: cnpg-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CloudNativePG operator should be installed in namespace "cnpg-system".
You can now create a PostgreSQL cluster with 3 nodes as follows:
cat <<EOF | kubectl apply -f -
# Example of PostgreSQL cluster
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example
spec:
instances: 3
storage:
size: 1Gi
EOF
kubectl get -A cluster
Verifying install
kubectl get pods -n cnpg-system
NAME READY STATUS RESTARTS AGE
cnpg-cloudnative-pg-847b949f48-d4clp 1/1 Running 0 118s
Create Ubuntu client VMs
az vm create \
--resource-group myResourceGroup \
--name VM1 \
--location westus \
--image Ubuntu2404 \
--admin-username azureuser \
--generate-ssh-keys \
--public-ip-address VM1PublicIP
{
"fqdns": "",
"id": "/subscriptions/7460cc93-ed07-42e7-a246-3b87e52a3ad7/resourceGroups/myResourceGroup/providers/Microsoft.Compute/virtualMachines/VM1",
"location": "westus",
"macAddress": "60-45-BD-09-BD-FA",
"powerState": "VM running",
"privateIpAddress": "10.0.0.4",
"publicIpAddress": "104.42.23.20",
"resourceGroup": "myResourceGroup",
"zones": ""
}
az vm create \
--resource-group myResourceGroup \
--name VM2 \
--location westus \
--image Ubuntu2404 \
--admin-username azureuser \
--generate-ssh-keys \
--public-ip-address VM2PublicIP
{
"fqdns": "",
"id": "/subscriptions/7460cc93-ed07-42e7-a246-3b87e52a3ad7/resourceGroups/myResourceGroup/providers/Microsoft.Compute/virtualMachines/VM2",
"location": "westus",
"macAddress": "00-0D-3A-33-8C-32",
"powerState": "VM running",
"privateIpAddress": "10.0.0.5",
"publicIpAddress": "104.42.13.179",
"resourceGroup": "myResourceGroup",
"zones": ""
}
Verify the public IPs
az vm list-ip-addresses --resource-group myResourceGroup --output table
VirtualMachine PublicIPAddresses PrivateIPAddresses
---------------- ------------------- --------------------
VM1 104.42.23.20 10.0.0.4
VM2 104.42.13.179 10.0.0.5
ssh azureuser@104.42.23.20
The authenticity of host '104.42.23.20 (104.42.23.20)' can't be established.
ED25519 key fingerprint is SHA256:glEquFeCDVHDsA8x6KK3E3yhkeIBwMwl1p+1Wq51AFw.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '104.42.23.20' (ED25519) to the list of known hosts.
Welcome to Ubuntu 24.04.2 LTS (GNU/Linux 6.8.0-1021-azure x86_64)
...
azureuser@VM1:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 24.04.2 LTS
Release: 24.04
Codename: noble
generate and store the password
export POSTGRES_PASSWORD=$(openssl rand -base64 16) && echo "Generated Password: $POSTGRES_PASSWORD"
Generated Password: R0L0W056xZdykI/GoAW0lQ==
kubectl create secret generic mydb-secret \
--from-literal=username=myuser \
--from-literal=password=$POSTGRES_PASSWORD
secret/mydb-secret created
kubectl get secrets mydb-secret -o yaml
apiVersion: v1
data:
password: UjBMMFcwNTZ4WmR5a0kvR29BVzBsUT09
username: bXl1c2Vy
kind: Secret
metadata:
creationTimestamp: "2025-03-14T07:35:06Z"
name: mydb-secret
namespace: default
resourceVersion: "13805"
uid: f62e732a-95de-4b54-be9e-734db5dedb9e
type: Opaque
create the cluster
cat >cnpg-cluster.yaml <<EOF
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cnpg-cluster
spec:
instances: 2
imageName: ghcr.io/cloudnative-pg/postgresql:17
storage:
size: 1Gi
bootstrap:
initdb:
database: mydb
owner: myuser
secret:
name: mydb-secret
postgresql:
synchronous:
method: any
number: 1
dataDurability: preferred
managed:
services:
## disable the default services
disabledDefaultServices: ["ro", "r"]
additional:
- selectorType: rw
serviceTemplate:
metadata:
name: "test-rw"
spec:
type: LoadBalancer
loadBalancerSourceRanges:
- 104.42.23.20/32 # VM1's public IP
EOF
kubectl apply -f cnpg-cluster.yaml
cluster.postgresql.cnpg.io/cnpg-cluster created
kubectl cnpg status cnpg-cluster
Cluster Summary
Name default/cnpg-cluster
System ID: 7481566161465909268
PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:17
Primary instance: cnpg-cluster-1
Primary start time: 2025-03-14 07:38:01 +0000 UTC (uptime 4m17s)
Status: Cluster in healthy state
Instances: 2
Ready instances: 2
Size: 94M
Current Write LSN: 0/4055A58 (Timeline: 1 - WAL File: 000000010000000000000004)
Continuous Backup status
Not configured
Streaming Replication status
Replication Slots Enabled
Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority Replication Slot
---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- ------------- ----------------
cnpg-cluster-2 0/4055A58 0/4055A58 0/4055A58 0/4055A58 00:00:00 00:00:00 00:00:00 streaming quorum 1 active
Instances status
Name Current LSN Replication role Status QoS Manager Version Node
---- ----------- ---------------- ------ --- --------------- ----
cnpg-cluster-1 0/4055A58 Primary OK BestEffort 1.25.1 aks-nodepool1-30726688-vmss000001
cnpg-cluster-2 0/4055A58 Standby (sync) OK BestEffort 1.25.1 aks-nodepool1-30726688-vmss000000
kubectl get svc test-rw
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test-rw LoadBalancer 10.0.126.67 57.152.72.113 5432:31291/TCP 16m
Test from VM1
ssh azureuser@104.42.23.20
azureuser@VM1:~$ sudo apt update; sudo apt install postgresql-client-common postgresql-client-16
...
The following additional packages will be installed:
libpq5
Suggested packages:
postgresql-16 postgresql-doc-16
The following NEW packages will be installed:
libpq5 postgresql-client-16 postgresql-client-common
0 upgraded, 3 newly installed, 0 to remove and 43 not upgraded.
Need to get 1471 kB of archives.
After this operation, 4922 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
...
azureuser@VM1:~$ psql -h 57.152.72.113 -U myuser -d mydb
Password for user myuser:
psql (16.8 (Ubuntu 16.8-0ubuntu0.24.04.1), server 17.4 (Debian 17.4-1.pgdg110+2))
WARNING: psql major version 16, server major version 17.
Some psql features might not work.
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
Type "help" for help.
mydb=> select version();
version
-----------------------------------------------------------------------------------------------------------------------------
PostgreSQL 17.4 (Debian 17.4-1.pgdg110+2) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
(1 row)
mydb=> \q
azureuser@VM1:~$ exit
logout
Connection to 104.42.23.20 closed.
Test from VM2
ssh azureuser@104.42.13.179
azureuser@VM2:~$ sudo apt update; sudo apt install postgresql-client-common postgresql-client-16
...
The following additional packages will be installed:
libpq5
Suggested packages:
postgresql-16 postgresql-doc-16
The following NEW packages will be installed:
libpq5 postgresql-client-16 postgresql-client-common
0 upgraded, 3 newly installed, 0 to remove and 43 not upgraded.
Need to get 1471 kB of archives.
After this operation, 4922 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
...
azureuser@VM2:~$ time psql -h 57.152.72.113 -U myuser -d mydb
^Z
[1]+ Stopped psql -h 57.152.72.113 -U myuser -d mydb
real 0m40.947s
user 0m0.001s
sys 0m0.000s
azureuser@VM2:~$ exit
logout
Connection to 104.42.13.179 closed.
Delete VMs
az vm delete --name VM1 --resource-group myResourceGroup --yes
az vm delete --name VM2 --resource-group myResourceGroup --yes
az disk delete --name VM1_OSDisk --resource-group myResourceGroup --yes
az disk delete --name VM2_OSDisk --resource-group myResourceGroup --yes
az network nic list --output table
AuxiliaryMode AuxiliarySku DisableTcpStateTracking EnableIPForwarding Location MacAddress Name NicType ProvisioningState ResourceGroup ResourceGuid VnetEncryptionSupported
--------------- -------------- ------------------------- -------------------- ---------- ----------------- -------- --------- ------------------- --------------- ------------------------------------ -------------------------
None None False False westus 60-45-BD-09-BD-FA VM1VMNic Standard Succeeded myResourceGroup 185c9f84-bef6-4f45-b53e-bd40a72dd3f8 False
None None False False westus 00-0D-3A-33-8C-32 VM2VMNic Standard Succeeded myResourceGroup 293a72b4-70ab-44ce-bc04-2dc42c2e0591 False
az network nic delete --name VM1VMNic --resource-group myResourceGroup
az network nic delete --name VM2VMNic --resource-group myResourceGroup
az network public-ip delete --name VM1PublicIP --resource-group myResourceGroup
az network public-ip delete --name VM2PublicIP --resource-group myResourceGroup
Delete AKS cluster
az aks delete --name myAKSCluster --resource-group myResourceGroup --yes
Delete resource group
az group delete --name myResourceGroup --yes --no-wait
Check they are gone
az aks list --output table
az vm list --output table
az group list --output table
Name Location Status
---------------- ---------- ---------
myResourceGroup eastus Deleting
NetworkWatcherRG eastus Succeeded
QED. Works as advertised.
Postgres Per-Connection Statistics
I’ve had a wish list for a few years now of observability-related things I’d love to see someday in community/open-source Postgres. A few items from my wish list:
- Wait event counters and cumulative time
- Wait event arguments (like object, block, etc – specific argument depends on the wait event)
- Comprehensive tracking of CPU time (ie. capture/track POSIX rusage data and expose the kernel’s perspective on per-connection CPU usage as a metric)
- Stop putting “COMMIT/END” in pg_stat_activity when it’s the currently executing statement. It is endlessly frustrating because for 99% of applications you will have no way to know which transactions are committing – and what part of your application code is triggering this – when you get a pile-up of sessions running COMMIT/END at the same time. It would be more useful to just leave the previous SQL in pg_stat_activity, and expose the fact that it’s a commit elsewhere (eg. state==commit or state==active_commit instead of state==active). It’s also usually pretty clear from the current wait events when you’re committing. To troubleshoot, you usually also want to know what you’re committing – not just when you’re committing.
- On-CPU state
- SQL execution stage (parse/plan/execute/fetch)
- SQL execution plan identifier in pg_stat_statements and pg_stat_activity (there are some promising patches and discussions on the hackers email list about this right now!)
- Currently executing node of the execution plan in pg_stat_activity
- Progress on long operations (eg. a large seqscan) – there have been improvements here in recent years
- Better runtime visibility into procedural languages
- Ability to better detect plan flips, probably via some kind of plan ID or plan hash in pg_stat_activity (i’ve done this by looking for big changes in per-exec logical IO, but that’s far less effective than what could be done with some improvements in core)
- Per-connection statistics (almost all stats today are at the instance or database level) – I wrote a tool to snapshot statistics before and after a query so that you could get a report on exactly what the query did, and a lot of the stats are only useful if you run the tool on an otherwise idle system.
As I’ve noted in a few places, there has been slow and steady progress in Postgres over recent years. There’s also plenty of good discussion continuing on mailing lists now.
One long running topic is better instrumentation for detecting plan changes – the thing we need is some kind of plan hash – and Lukas Fittl is keeping the discussion going with a fresh patch and proposal on the lists last week. It hasn’t gotten much discussion just yet – this would be a great patch for any newcomers interested in PG observability to test and give feedback on!
Another interesting mailing list discussion right now (which wasn’t on my list above) is about capturing page fault information. Postgres today does all IO through the page cache, so Postgres can tell us if a page wasn’t in the database cache but it can’t tell us if the page actually required a read from storage (ie. wasn’t in the OS page cache either). The most common Postgres configuration today is 25% of memory as database cache, and relying on the OS page cache beyond that, but it’s impossible to calculate a real buffer cache hit ratio with this configuration today! However the operating system does track reads from storage at a per-process level as “major page faults”. The extension pg_stat_kcache has been around for awhile and partly fills the gap by tracking and exposing major page faults within Postgres. This mailing list thread started by Atsushi Torikoshi is about the idea of bringing some of this functionality into core Postgres. I personally think it’s a great idea, and likely will prove valuable in both EXPLAIN output and also in pg_stat_database.
But a commit last month from Bertrand Drouvot is what I’m most excited about. I think it represents a really important step forward and I think it’s easy to miss the significance of this, so I wanted to briefly highlight it.
Bertrand’s commit adds per-connection I/O statistics, and Bertrand did a short blog about it at https://bdrouvot.github.io/2025/01/07/postgres-backend-statistics-part-1/
But I think the really important thing here is something that isn’t obvious at first: this commit lays the groundwork for per-connection statistics in general. This email on the lists yesterday illustrates the point:

The thing I’m most excited about is how the December commit lays important groundwork toward better observability for Postgres in general. Maybe we could get that “major page fault” information in postgres at a per-connection level!
It looks like we’re knocking another item off my wish list. A big thank you to Bertrand, Michael, and everyone who provided reviews and feedback on the mailing lists about this patch!
And go have a look at Bertrand’s blog, if you didn’t already read it. Exciting stuff.
Challenges of Postgres Containers
Many enterprise workloads are being migrated from commercial databases like Oracle and SQL Server to Postgres, which brings anxiety and challenges for mature operational teams. Learning a new database like Postgres sounds intimidating. In practice, most of the concepts directly transfer from databases like SQL Server and Oracle. Transactions, SQL syntax, explain plans, connection management, redo (aka transaction/write-ahead logging), backup and recovery – all have direct parallels. The two biggest differences in Postgres are: (1) vacuum and (2) the whole “open source” and decentralized development paradigm… once you learn those, the rest is gravy. Get a commercial support contract if you need to, try out some training; there are several companies offering these. Re-kindle the curiosity that got us into databases originally, take your time learning day-by-day, connect with other Postgres people online where you can ask questions, and you’ll be fine!
Nonetheless: the anxiety is compounded when you’re learning two new things: both Postgres and containers. I pivoted to Postgres in 2017, and I’m learning containers now. (I know I’m 10 years late getting off the sidelines and into the containers game, but I was doing lots of other interesting things!)
Postgres was already one of the most-pulled images on Docker Hub back in 2019 (10M+) and unsurprisingly it continues to be among the most-pulled images today (1B+). Local development and testing with Postgres has never been easier. For many developers, docker run postgres -e POSTGRES_PASSWORD=mysecret has replaced installers and package managers and desktop GUIs in their local dev & test workflows.
With the widespread adoption of kubernetes, the maturing of its support for stateful workloads, and the growing availability of Postgres operators – containers are increasingly being used throughout the full lifecycle of the database. They aren’t just for dev & test: they’re for production too.
Containers will dominate the future of Postgres, if only because I bear the scars of managing 15-year-old servers where the package manager database never matched reality and there were 20 different copies of python and 30 different copies of java installed under various root and user directories.
But what exactly is a container? What is inside that thing? In fact, a lot more than I first thought. Six months ago I was convinced there’s no possible way glibc was in that container. You can’t just take a glibc from 2024 and run it on a kernel from 2016. Right?
$ docker run --interactive --tty debian:bookworm-slim
root@27234bdf966e:/# dpkg -l libc6
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-==============-==============-============-=================================
ii libc6:amd64 2.36-9+deb12u9 amd64 GNU C Library: Shared libraries
root@27234bdf966e:/# dpkg -l|grep " lib"|wc -l
51
root@27234bdf966e:/# dpkg -l|grep -v " lib"|wc -l
42
root@27234bdf966e:/# exit

Basically, there can be a whole operating system inside that container! (Minus the kernel.) In practice there are a range of “base operating systems” from hyper-slim alpine (a la busybox) to containers that run a full copy of systemd and provide a full operating system experience. Docker’s official Debian-based Postgres containers use the “slim” debian OS container as a base (88 packages and 74MB) and are customized with additional packages from PGDG and the Debian universe (total 146 packages and 434MB).
The glibc-to-kernel cross-compatability is magic to me. It’s not by chance. Libraries like glibc are pretty tightly coupled to the kernel, and it’s an intentional effort by both linux kernel maintainers and glibc maintainers to maintain cross-compatibility. Like the intentional effort by Postgres maintainers to maintain ABI compatibility across Postgres “minor release” bugfix versions.
Combined with a good kubernetes operator, Postgres containers are production ready today.
But containers have a few rough edges. It’s important to know about them if you’re going to move toward production operations with Postgres containers.
Security and IsolationContainers are secure enough for the vast majority of companies and use cases. The underlying technology is well maintained, new vulnerabilities are addressed promptly, fixes are made available quickly, and designs are thoroughly reviewed. Kernel isolation capabilities have been tested by world-class pen testers and red teams.
However there is a meaningful difference between kernel isolation and hardware VM-based isolation. The firecracker paper presented at Usenix 2020 is the best writeup that I’ve seen on the topic so far.
 Firecracker: Lightweight virtualization for serverless applications. Amazon Science (2020).
Firecracker: Lightweight virtualization for serverless applications. Amazon Science (2020).Fundamentally it’s about attack surface area within the boundary between unprivileged and privileged execution. At the end of the day, a general-purpose operating system kernel’s syscall interface is composed of hundreds of critical functions with complex implementations. Virtual Machine Monitors (VMMs) and processor instruction sets are comparatively simpler with better-understood abstractions. Virtualization is not immune from attack – recent incidents like Meltdown and Spectre and other side-channel/speculative-execution attacks have proven the point – but reducing attack surface area is fundamental in very-high-security environments.
The vast majority of companies should not be disabling SMT on their processors or avoiding containers. There is sometimes a trade-off between security and cost/performance. Hyperscalers and SAAS companies have use cases where they have to opt for virtualization even when it’s less cost-effective.
Most readers here can deploy with traditional containers. Just understand the reasoning and be cognizant of the choice.
Host/Node Operating System CompatibilityYou can’t just take a glibc from 2024 and run it on a kernel from 2016. Right?
The answer is actually a little more nuanced than you’d expect.
The terminology used by Scott McCarty on the Red Hat blog around 2019-2020 is portability, compatibility and supportability. Scott’s a product manager who is particularly concerned about commercial contracts between Red Hat and its customers. The term supportability is an explicit reference to “scope of what Red Hat fully <contractually?> commits to debug and fix, as part of what you are paying for”.
But I think the terms are helpful even for people who just want to run their business on containers and are not Red Hat customers.
The standardized file format of containers makes them highly portable across systems and software. OCI-compliant containers can be copied and understood by tooling anywhere, but that doesn’t mean they can run anywhere.
Compatibility is about where containers will run. Naturally, if you compile for ARM then it’s not going to run on x86. I don’t fully understand yet how compatibility works across operating systems (linux, mac and windows)… I think there has been some clever engineering in recent years to create more compatibility here than what used to exist.
Things seem to get more interesting across different versions of the linux kernel.
Internet forums are full of people pointing out that the Linux kernel APIs are decades old and change rarely so your containers will probably run fine on any Linux. But you also don’t need to go far to find examples of things that break, like centos:6 bash crashing on Ubuntu 18.04 or useradd failing when the host is upgraded to RHEL 7 (and continuing to work fine on RHEL 6).
Even if you don’t have any intentions of becoming a Red Hat customer, I think it’s informative to read their official container support policy and their official container compatibility matrix. In particular: their “workload-specific” guidelines for container compatibility:
- Run as an unprivileged container (ie. don’t pass the
--privilegedflag) - Do not interact directly with kernel-version-specific data structures (ioctl, /proc, /sys, routing, iptables, nftables, eBPF, etc) or kernel-version-specific modules (KVM, OVS, SystemTap, etc.)
That’s good advice. It should mostly keep you out of trouble. Don’t forget it’s not just about your code, but also about your dependencies – even debian packages & binaries you pull into your container.
I think Postgres and most Postgres extensions should be fairly safe. They may not always strictly follow the rules above, but I think if any problems are found in core postgres (or a widely used extension) they’re likely to be taken seriously. The Postgres community generally tends to value portability & compatibility.
Red Hat generally recommends building containers with the same base OS major version as the host where they run. My own opinion is to stay “close”. Stick with major distro versions released within a few years of each other. Just my opinion – but I would probably look at distro release date over linux kernel version, given how aggressively kernels are sometimes patched by distros.
Container Versioning and Change Management
Lies. Containers don’t actually have versions. They have tags.
In Postgres, and for that matter any major linux distribution, if I ask for a specific version today – and then I ask for the same version next week – I will get the same bits. In fact, the official Debian Policy Manual section 3.2.2 codifies what I thought was common sense:
The part of the version number after the epoch must not be reused for a version of the package with different contents once the package has been accepted into the archive, even if the version of the package previously using that part of the version number is no longer present in any archive suites.
Containers don’t work like this at all. Practically every example on the internet makes it look like you can ask for a specific version of Postgres with docker run postgres:17.2 – but it turns out that 17.2 is just an arbitrary tag and not really a version number.
The docs are clear that it’s just a tag, but it’s all very confusing to newcomers – and there are dangers lurking here with Postgres.
The biggest danger is around the now-infamous glibc collation problems.
As early as 2017, a user of containerized Postgres 9.5 switched from tag 9.5 to tag 9.5-alpine and their data seemed to disappear. I suspect this was likely related to collation.
Debian v10/Buster was released in 2019 (with the big scary glibc change), and the docker community hit the brakes on updating their images due to the known problems. Finally in 2021 they caved in and added a bunch of complexity to their build scripts, in order to start building for two major debian versions at once. And thus was born the tags 10-stretch and 10-buster. The community instituted a policy of supporting only the two most recent major versions of debian (stable and oldstable). The “default” tags where no OS is specified (eg 17 or 17.2) change which major OS they are pointing to. This has resulted in a steady stream of problem reports, every time a new debian major was released.
Debian v11/Bullseye was released Aug 14, 2021. On Nov 10 a GitHub issue was opened from a user seeing incorrect sort order in Russian. Debian v12/Bookworm was released on June 10, 2023. On June 15 GitHub issue was opened by a user getting collation version mismatch warnings, and the torture test scan indicates this jump (2.31 to 2.36) likely includes changes in the Oriya and Kurdish languages (in 2.32). I haven’t yet checked if ICU has changes in bookworm.
The takeaway is summarized well in the GitHub Issue:

It is possible to completely avoid surprise changes when deploying containers: image digests can be used instead of image tags. But I think in most cases, using the tags as described above is the best solution. The tag postgres:15-bookworm is locked onto the Debian and Postgres stable releases, so you’ll automatically get security and critical updates by using a tag like this. Just make sure to include the operating system part!
And remember that you can’t just switch the tag to a new Operating System version unless you want to risk corruption. If you want to be 100% safe then you need to logically pg_dump-and-load, or use logical replication to move your data to the new operating system container image, or set your default provider to the new pg17 builtin C collation and use linguistic collation at a query or table level when needed and rebuild /all/ dependent objects on OS changes.
Memory Managementhttps://github.com/kubernetes/kubernetes/issues/43916 has now been open for 7 years and has 141 comments. Still going strong this month.
A few folks referenced https://github.com/linchpiner/cgroup-memory-manager as a workaround, but I’m not sure whether I’d use this with Postgres… at present I think the safest option with postgres remains the request==limit configuration.
An engineer from Bucharest named Mihai Albert wrote a very interesting blog post a few years ago that digs into detail on the behavior. I think his blog might be based on cgroups v1. I hadn’t seen it before, but it’s referenced from that GutHub issue. https://mihai-albert.com/2022/02/13/out-of-memory-oom-in-kubernetes-part-4-pod-evictions-oom-scenarios-and-flows-leading-to-them
I took my first swing at consolidating, organizing and writing what I learned back in September: Kubernetes Requests and Limits for Postgres … still a lot I don’t know or haven’t dug into yet.
Overall, I can’t quite tell whether there are any actual kubernetes code improvements on the horizon yet. We might still be in the “digging and discussing” stage.
SummaryCombined with a good kubernetes operator, Postgres containers are production ready today. I’m not sure whether I’d go learn kubernetes just to run Postgres but the reality is that kubernetes is already in use at many companies for application workloads. If kubernetes is already being deployed, then learning and leveraging it for Postgres makes sense.
2024 has been an exciting year for me and I’m very happy for the opportunity to begin really digging into Postgres containers. My four main concerns are outlined here, and they aren’t dampening my enthusiasm.
TLDR (I’m relatively new to containers, so hopefully I’m getting these right):
- don’t be intimidated to learn postgres if you’re a DBA for another database – it’s easier than you think
- set your database default collation to the new v17 builtin C collation, and use ICU at a table or query level in cases where you need linguistic collation. rebuild only those objects on OS changes.
- include the OS in your container “version” tags when deploying postgres containers
- deploy on a host/node with an OS major version released within a few years of your base container image (if the same OS major version, then all the better)
- for now, stick with request==limit for kubernetes memory allocations.
Postgres containers solve problems that have haunted us for decades, and they are here to stay.
Did Postgres Lose My Data?
Hello, let me introduce myself. Today, we’ll pretend that I’m a linguistics researcher. I don’t know much about databases, but I do know a lot about the Balti language of northern Pakistan. That’s why I’m excited about my current translation project.
The most interesting part of this translation project is that I’m doing some computer-driven analysis of a large body of text in the Balti language. For that, I’m going to need a database. You – dear friend – will help me with this! (Because you are an expert with databases!)
Our favorite database is PostgreSQL, so we should use it for my analysis work. You create an EC2 instance running an LTS release of Ubuntu and you create a database for me on the instance:
aws ec2 run-instances --key-name mac --instance-type t2.micro --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=research-db}]' --image-id ami-0172070f66a8ebe63 --region us-east-1
sudo apt install postgresql-common
sudo sh /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
sudo apt install postgresql-15
create database research_texts template=template0 locale_provider=icu icu_locale="en-US"Pretty easy!
Now I expect to be loading a very large amount of data for analysis. With a little help, I got DBeaver running on my computer and a connection to our “research_texts” database. After some discussion we decide that I should partition the main table, which has a huge list of Balti words along with cross-references and notes for each one.
As the wikipedia page for Balti explains, most people in this region of Pakistan use a Perso-Arabic alphabet which has between 40 and 50 characters. We’ll divide my table into four partitions, with about a quarter of the alphabet each. (And just to be safe we’ll add a default partition as well.)
create table arabic_dictionary_research (
word text,
crossreferences text,
notes text
) partition by range (word);
create table arabic_dictionary_research_p1 partition of arabic_dictionary_research
for values from ('ا') to ('ح');
create table arabic_dictionary_research_p2 partition of arabic_dictionary_research
for values from ('ح') to ('س');
create table arabic_dictionary_research_p3 partition of arabic_dictionary_research
for values from ('س') to ('ل');
create table arabic_dictionary_research_p4 partition of arabic_dictionary_research
for values from ('ل') to ('ے');
create table arabic_dictionary_research_p5 partition of arabic_dictionary_research
default;And finally my work begins! This isn’t my real research, but lets put some example data into the table to get an idea what it might look like.
insert into arabic_dictionary_research
select 'ب'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'د'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'م'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'ࣈ'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'ق'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
union all
select 'ٶ'||generate_series(1,1000), repeat('important cross-references!',100), 'notes'
;
select word,length(crossreferences),notes from arabic_dictionary_research where word='د100';
select word,length(crossreferences),notes from arabic_dictionary_research where word='ࣈ100';
Update 27-Mar-2023: I published this article over the weekend using my personal computer at home. When I got to work this morning I glanced at the article and saw a square box appearing in many SQL queries where I expected to see the Perso-Arabic letter Graf. That character displays correctly from my home computer (macOS 13 Ventura) and my iPhone (iOS 16) but not on my work laptop (macOS 12 Monterey). I now realize that many readers of this article will also see the box, depending on how up-to-date your mobile or computer operating system is. I’ve added a thumbnail here which links to the image from my phone, so that readers can see how the text is intended to appear. If you are following along with this article by copying and pasting commands, feel free to exclude the lines with a box character if you’d prefer. The examples still work without those lines.

Note: since Arabic Unicode characters have the “right-to-left” attribute set, these words are rendered right-to-left in DBeaver on my Mac.
Well let me tell you: linguistics is hard work. After a month I’ve made a lot of progress. However, my Machine Learning jobs are now using lots of resources on the database server and it slows down my ad-hoc SQL analysis a lot. Separately, I have a growing concern about making extra sure we don’t lose all the work I’ve done so far.
After some discussion we realize the obvious answer is to create a hot standby. This is an extra copy of the database on a separate server which receives a stream of changes from the current database so that it’s always up-to-date. Furthermore, I can open a read-only connection to this hot standby to run my analysis queries. A perfect solution!
You get right to work – again using Ubuntu LTS and PostgreSQL version 15.
aws ec2 run-instances --key-name mac --instance-type t2.micro --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=research-db-hotstandby}]' --image-id ami-0fd2c44049dd805b8 --region us-east-1
sudo apt install postgresql-common
sudo sh /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
sudo apt install postgresql-15
# cut and paste instructions from https://ubuntu.com/server/docs/databases-postgresql to easily set up the hot standby databaseIn no time at all, I’m creating a new connection in DBeaver and running my analysis SQL on the new hot standby.
At first everything is great. My queries are running much faster now. But after a little while I run into my first problem. I am retrieving the cross references for a word that begins with the arabic letter Graf (code point U+08C8) but no record is returned by the database. I check a few more words and I’m horrified to discover that the Postgres hot standby seems to have lost a huge amount of my data.
select count(*) from arabic_dictionary_research where word between 'ࣈ1' and 'ࣈ9';
-- zero records found, we lost at least 890 records!
select count(*) from arabic_dictionary_research where word between 'ٶ1' and 'ٶ9';
-- zero records found, we lost at least 890 more records!Except for one thing: when I run the same queries over on the main read-write server, everything looks fine. The servers give different results. We immediately stop using the hot standby server… and I feel relieved that we hadn’t performed a failover or somehow lost the main server.
Note: You can try this for yourself by running the commands above. You’ll replicate the missing data on the hot standby, and the different results on different servers.
 Diagnosis
Diagnosis
So what happened? The root cause was the operating system we used for the hot standby.
===== PRIMARY DATABASE "research-db" =====
ami-0172070f66a8ebe63 (us-east-1)
ubuntu@ip-10-0-0-210:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.5 LTS
Release: 20.04
Codename: focal
===== HOT STANDBY DATABASE "research-db-hotstandby" =====
ami-0fd2c44049dd805b8 (us-east-1)
ubuntu@ip-10-0-0-117:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.2 LTS
Release: 22.04
Codename: jammyAnd while no messages were ever actively displayed to either the admin who created the hot standby or the researcher who was running SQL in DBeaver, there was a warning message buried in the database log on the hot standby server:
ubuntu@ip-10-0-0-117:~$ tail /var/log/postgresql/postgresql-15-main.log
2023-03-26 07:39:47.656 UTC [5053] LOG: restartpoint complete: wrote 71 buffers (0.4%); 0 WAL file(s) added, 0 removed, 0 recycled; write=7.026 s, sync=0.004 s, total=7.039 s; sync files=51, longest=0.003 s, average=0.001 s; distance=266 kB, estimate=14772 kB
2023-03-26 07:39:47.656 UTC [5053] LOG: recovery restart point at 0/3042B20
2023-03-26 07:39:47.656 UTC [5053] DETAIL: Last completed transaction was at log time 2023-03-26 07:36:32.138932+00.
2023-03-26 07:44:55.770 UTC [5053] LOG: restartpoint starting: time
2023-03-26 07:45:09.811 UTC [5053] LOG: restartpoint complete: wrote 141 buffers (0.9%); 0 WAL file(s) added, 0 removed, 0 recycled; write=14.031 s, sync=0.003 s, total=14.042 s; sync files=22, longest=0.002 s, average=0.001 s; distance=1309 kB, estimate=13425 kB
2023-03-26 07:45:09.811 UTC [5053] LOG: recovery restart point at 0/3189F90
2023-03-26 07:45:09.811 UTC [5053] DETAIL: Last completed transaction was at log time 2023-03-26 07:41:50.782267+00.
2023-03-26 09:20:06.353 UTC [5498] ubuntu@research_texts WARNING: database "research_texts" has a collation version mismatch
2023-03-26 09:20:06.353 UTC [5498] ubuntu@research_texts DETAIL: The database was created using collation version 153.14, but the operating system provides version 153.112.
2023-03-26 09:20:06.353 UTC [5498] ubuntu@research_texts HINT: Rebuild all objects in this database that use the default collation and run ALTER DATABASE research_texts REFRESH COLLATION VERSION, or build PostgreSQL with the right library version.Collation.
A topic that has been discussed quite a bit over the past few years among the PostgreSQL development community.
“Collation” basically means “putting words in the right order”. In programming terms, you can think of it as sorting strings – usually by following the rules of local languages. As such, it falls under the broad computer science category of internationalization and localization. The basic problem for PostgreSQL is that unlike most other mature relational databases, PostgreSQL does not lock down collation versioning in its own code & build process. Instead, PostgreSQL out-sources management of collation versioning (via either the GNU C Library or the International Components for Unicode) to the operating system administrator – who manages these libraries as part of the operating system, separately from the database software itself. When these external libraries are upgraded, their ordering rules change. That introduces inconsistency between the new ordering and what’s on disk. While rare in practice (so far), in the worst cases this has caused all kinds of failures like wrong query results, duplicate data violating unique constraints, and even unavailability due to WAL replay failure during crash recovery. A lot of quality articles have already been written, delving into this challenge that PostgreSQL is facing. I’ve listed some of my favorite starting points in the “Related Reading” section at the bottom of this article.
Lets review a few things about this particular example:
- This is using ICU (not the GNU C Library)
- This is using partitions (can’t fix this with an index rebuild; needs a full dump/load of the table)
- This is a hot standby (can’t fix it anyway, because primary read-write server still uses the other version of ICU)
- This is using the en-US locale for sort ordering (the most common default)
- No warning or problem indication of any kind was displayed to a user or operator. Software was installed, hot standby configured and started, with no visible warnings to the admin. In DBeaver, a connection was made and queries ran and wrong results were returned (missing data). The user saw nothing indicating any concern. We only looked for problems because the user knew that the results of one particular query were wrong.
On a side note, be wary of the ALTER ... REFRESH COLLATION VERSION commands that are suggested. It’s very important to understand that this does not fix any inconsistencies between persisted data and collation libraries – all it does is instruct PostgreSQL to make the error message go away indefinitely without changing anything. It’s assumed that you’ve manually fixed any problems yourself, and that you’re 100% sure you’ve verified there isn’t any problematic data remaining.
Operating systems need to be upgraded over time. A database with a smart phone app in front of it can end up storing any unicode character typed on the phone. Smart phones can switch their keyboards to support any local language. If you have a couple users originally from northern Pakistan who enter their names or addresses from their phones with Balti characters, then you might only have three safe options when it comes time to upgrade your operating system:
- Dump and load the full database (which will be a long downtime window if your database is large)
- Use logical replication with dump & load to reduce downtime (which is a very expensive project and far more time-consuming for your staff than dump-and-load)
- Find someone to build your old version of ICU on each new release of your operating system
It will be interesting to see how this plays out. There are so many operating systems where PostgreSQL runs: Linuxes, BSDs, Windows, Mac, etc. Each has its own matrix of ICU versions shipped with major OS versions. How many different old versions of ICU will be maintained on each operating system and distribution? Who will do the work?
ICU has dependencies on programming language features that need compiler support. Last month, ICU maintainers started a discussion about moving ICU to C++17 (it has required C++11 since v59 in 2017). What if you have the reverse problem of this discussion, where your future operating system compiler has difficulty with your old version of ICU? What if a future new compiler optimization technique or a change of default compilation options somehow impacted ordering? I think this is unlikely to be an issue anytime soon and wouldn’t be insurmountable, but things probably won’t be maintenance-free either.
String comparisons are used in a lot of places by the database. Besides indexes (of all kinds) and partitions and constraints, what else is impacted that we haven’t thought of yet? How about something like joins across FDWs – do they assume rows come back in sorted order? What about extensions like PostGIS and Timescale and others – do they have their own datatypes or storage formats that involve string comparisons?
But Surely, Sort Order Changes Are Uncommon, Right?Nobody is about to change the order of the english alphabet. The Balti example above involves a new unicode character that was added in Unicode in version 14.0 (2021) to support translation work (it’s probably not common in names or addresses), and a fix to sort order for alif, wow and yah only with a high hamza (my Arabic is rusty; I’m not 100% sure but I think it was CLDR-11112 [String start with letter alif (ا) should not be indexed under hamza (ء) when using both locale ur and ar]).
But sort order changes are probably more common than you think.
- New characters (including emojis) are continually added to Unicode. Those characters can be entered into your existing database. The existing database accepts the code point and sorts with default rules for the unassigned code point. When you upgrade your collation library next year, you’ll get the “correct” sort order for that new code point.
- Incorrect sorting rules are corrected. For example: CLDR-9895 [Collation rules improvement for Tibetan] and CLDR-9748 [Update Kurdish (ku) seed collation]
- Unclear rules are clarified by governments, universities, or others. For example: CLDR-1035 [Collation rules for sv: now to separate v and w at first level] and CLDR-7088 [Swedish collation] and CLDR-2905 [Drop backwards-secondary sorting from French collation]
- Maintainers and developers make general improvements. For example: CLDR-15603 [Align Swedish (sv) collation naming with other (non-zh) languages] and CLDR-15910 [Inclusion of COLON in word break MidLetter class should be moved to tailoring for fi,sv]
- My favorite… code changes entirely unrelated to official language rules which change the way some “equal” strings are compared. In 2014, a 300-line commit to the GNU C Library refactored an internal cache for performance reasons and it changed string comparison results for at least 22,743 code points (largely CJK characters). This is not the infamous glibc 2.28 change – this was before that, back in Ubuntu 15.04.
In order to get a sense of how common these changes are, I came up with a test.
You might think that all you need to do is make a list of the characters and sort it – but unfortunately it’s more complicated than that. Humans have a knack for coming up with complicated rules about their languages. Do you remember your college writing class?! Accurate linguistic sort algorithms capture all of those rules by looking at groups of glyphs, not individual glyphs. And there are even cases where multiple code points together (a base and modifiers) make a single glyph. (On a related note, your language’s “string-length” functions might not be telling you what you think they are telling you…) Between glibc 2.26 and glibc 2.27 the characters Ò (U+D3) and Ô (U+D4) and Õ (U+D5) and Ö (U+D6) did not change their order relative to any other individual characters. But strings combining one of those characters with the letter “O” did change relative to other strings.
The test that I’ve come up with involves taking each Unicode code point and plugging it into a list of 91 patterns. This is not comprehensive but I think it gives some coverage. Unicode version 15 has 286,654 valid code points, not including control or surrogate code points. That results in a list of about 26 million strings. I wrote some bash and perl and SQL code to mostly automate the process of creating & sorting this list of 26 million strings across 10 years of historical versions of Ubuntu and RHEL. I tested glibc versions on both operating systems and I tested ICU versions on Ubuntu.
For glibc I performed a sort in en-US which catches changes to default sorting, and then I directly compared the Operating System locale data files between versions to find the remaining changes. For ICU, I only did the sort – however I tested the sort in seven different locales: en-US, ja-JP, zh-Hans-CN, ru-RU, fr-FR, de-DE, and es-ES. English, French, German and Spanish have identical counts. Chinese, Japanese and Russian seem to have some very small differences from the others.
Finally, I generated a table summarizing the results with links for drill-down into the data. This is published on GitHub. The column labeled “Total” tells the number of unicode blocks impacted by any changes and you can click it to see a summary. For each impacted unicode block, the summary tells which patterns appeared in the “diff” output for this operating system version and how many distinct code points appeared for that pattern and block. The column labeled “Blocks” tells the total number of distinct code points impacted. Clicking on that will open a list of each string that appeared in the diff, along with the pattern number and code point. For any given version of glibc or ICU this will tell you every individual code point that appeared in the “diff” of two sorted lists. Finally, the link labeled “Full Diff” is just what it says – the direct output of “diff” between the old sorted list of strings and the new sorted list of strings.
In summary: both glibc and ICU have regular collation changes. Both have had at least one release with very large numbers of changes.
You can see the summary table and drill-down data at https://github.com/ardentperf/glibc-unicode-sorting
Want to try it yourself? I did the ICU comparisons right inside PostgreSQL. The full list of strings is stored in a table and generated by a simple snippet of PL/pgSQL – you can copy the code and then try sorting this particular set of strings on as many locales and operating systems as you’d like, with both ICU and glibc. Just remember to remove the extra backslashes that are there for quoting, and replace the variable ${UNICODE_VERS} with the literal value 15 (or a different version if you want).
 ICU results table on GitHub
Related Reading
ICU results table on GitHub
Related Reading
I have still only scratched the surface of collation and PostgreSQL. Work continues and there is a lot of additional great material to read, if you’re interested in getting into the weeds. Here are a few starting points:
- The official PostgreSQL wiki page for collations is the best starting point. It’s concise and brief and it already summarizes everything I’ve mentioned in this article. https://wiki.postgresql.org/wiki/Collations
- Just two weeks ago, Peter Eisenstraut published an article about how collation works. I think it’s one of the best articles I’ve read so far on this topic. http://peter.eisentraut.org/blog/2023/03/14/how-collation-works
- About two years ago, Thomas Munro published an article on the Azure database blog about index corruption from collation changes. Another one of my favorites that stands the test of time – especially since Thomas includes so many great links back into the official Unicode specs as he explains things. https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/don-t-let-collation-versions-corrupt-your-postgresql-indexes/ba-p/1978394
- About a month ago, Jonathan Katz published an article on the AWS database blog about managing collation changes on RDS Open Source PostgreSQL and Aurora. This has a lot of useful SQL queries for people who are worried about impact from collation changes, and it has a little nugget tucked at the bottom about AWS freezing their glibc collation behavior at version 2.26-59 – which is pretty remarkable. https://aws.amazon.com/blogs/database/manage-collation-changes-in-postgresql-on-amazon-aurora-and-amazon-rds/
- Collation was discussed at the FOSDEM 2023 PGDay Developers Meeting and the notes are online. Joe Conway talked about some work that he’s done. There are some interesting tidbits here. https://wiki.postgresql.org/wiki/FOSDEM/PGDay_2023_Developer_Meeting#ICU_.2F_Collations
- Jeff Davis has been very involved with recent contributions around ICU and PostgreSQL, including a finding about ICU 55 that’s very interesting alongside the test results of my GitHub scripts on this version [pgsql-hackers mailing list thread “ICU 54 and earlier are too dangerous”]. https://www.postgresql.org/search/?m=1&q=davis+icu&l=1&d=365&s=d and https://commitfest.postgresql.org/41/3956/
- If you want to heckle me sometime, you can point out that I literally spent a year and a half writing this. November 2021 was when I promised this article to Robert Haas in a comment over on his blog. Yeah… this took a LOT longer than it should have!! http://rhaas.blogspot.com/2021/11/collation-stability.html
Among PostgreSQL installations globally, the problems we’re talking about here are serious but in practice they have occurred very rarely (so far). The largest risk is people who self-manage their databases and use libc linguistic collation and upgrade to RHEL 8 or Ubuntu 20.04 LTS or Ubuntu 18.10 non-LTS or Debian 10 without doing a dump & load; those OS upgrades include the glibc 2.28 changes. Of course C/POSIX/ucs_basic and ICU collation are not impacted by this. Enormous progress has been made. But some hard questions aren’t answered yet and the PostgreSQL community still has work to do.
Nonetheless, one thing you can’t help noticing is the ongoing investment and open collaboration of very smart engineers across multiple companies and geographies. This is open source at its best, and it’s one of the reasons that I know PostgreSQL is here to stay.
Paranoid SQL Execution on Postgres
Suppose that you want to be completely over-the-top paranoid about making sure that when you execute some particular SQL statement on your Postgres database, you’re doing it in the safest and least risky way?
For example, suppose it’s the production database behind your successful startup’s main commercial website. If anything even causes queries to block/pause for a few minutes then people will quickly be tweeting about how they can’t place orders and it hurt both your company’s revenue and reputation.
You know that it’s really important to save regular snapshots and keep a history of important metrics. You’re writing some of your own code to capture a few specific stats like the physical size of your most important application tables or maybe the number of outstanding orders over time. Maybe you’re writing some java code that gets scheduled by quartz, or maybe some python code that you’ll run with cron.
Or another situation might be that you’re planning to make an update to your schema – adding a new table, adding a new column to an existing table, modifying a constraint, etc. You plan to execute this change as an online operation during the weekly period of lowest activity on the system – maybe it’s very late Monday night, if you’re in an industry that’s busiest over weekends.
How can you make sure that your SQL is executed on the database in the safest possible way?
Here are a few ideas I’ve come up with:
- Setting
connect_timeoutto something short, for example 2 seconds. - Setting
lock_timeoutto something appropriate. For example, 2ms on queries that shouldn’t be doing any locking. (I’ve seen entire systems brown-out because a “quick” DDL had to get in line behind an app transaction, and then all the new app transactions piled up behind the DDL that was waiting!) - Setting
statement_timeoutto something reasonable for the query you’re running – thus putting an upper bound on execution time. - Using an appropriate client-side timeout, for cases when the server fails to kill the query using
statement_timeout. For example, in Java the Statement class has native support for this. - When writing SQL, fully qualify names of tables and functions with the schema/namespace. (This can be a security feature; I have heard of attacks where someone manages to change the search_path for connections.)
- Check at least one explain plan and make sure it’s doing what you would expect it to be doing, and that it seems likely to be the most efficient way to get the information you need.
- Don’t use system views that join in unneeded data sources; go direct to needed raw relation or a raw function.
- Access each data source exactly once, never more than once. In that single pass, get all data that will be needed. Analytic or window functions are very useful for avoiding self-joins.
- Restrict the user to minimum needed privileges. For example, the
pg_read_all_statsrole on an otherwise unprivileged user might be useful. - Make sure your code has back-off logic for retries when failures or unexpected results are encountered.
- Prevent connection pile-ups resulting from database slowdowns or hangs. For example, by using a dedicated client-side connection pool with dynamic sizing entirely disabled or with a small max pool size.
- Run the query against a physical replica/hot standby (e.g. pulling a metric for the physical size of important tables) or logical copy (e.g. any query against application data), instead of running the query against the primary production database. (However, note that when
hot_standby_feedbackis enabled, long-running transactions on the PostgreSQL hot standby can still impact the primary system.) - For all DDL, carefully check the level of locking that it will require and test to get a feel for possible execution time. Watch out for table rewrites. Many DDLs that used to require a rewrite no longer do in current versions of PostgreSQL, but there are still a few out there. ALTER TABLE statements must be evaluated very carefully. Frankly ALTER TABLE is a bit notorious for being unclear about which incantations cause table rewrites and which ones don’t. (I have a friend who just tests every specific ALTER TABLE operation first on an empty table and then checks if pg_class changes show that a rewrite happened.)
What am I missing? What other ideas are out there for executing SQL in Postgres with a “paranoid” level of safety?
Note: see also Column And Table Redefinition With Minimal Locking
PostgreSQL Invalid Page and Checksum Verification Failed
At the Seattle PostgreSQL User Group meetup this past Tuesday, we got onto the topic of invalid pages in PostgreSQL. It was a fun discussion and it made me realize that it’d be worth writing down a bunch of the stuff we talked about – it might be interesting to a few more people too!
Invalid Page In BlockYou see an error message that looks like this:
ERROR: invalid page in block 1226710 of relation base/16750/27244First and foremost – what does this error mean? I like to think of PostgreSQL as having a fairly strong “boundary” between (1) the database itself and (2) the operating system [and by extension everything else… firmware, disks, network, remote storage, etc]. PostgreSQL maintains page validity primarily on the way in and out of its buffer cache.
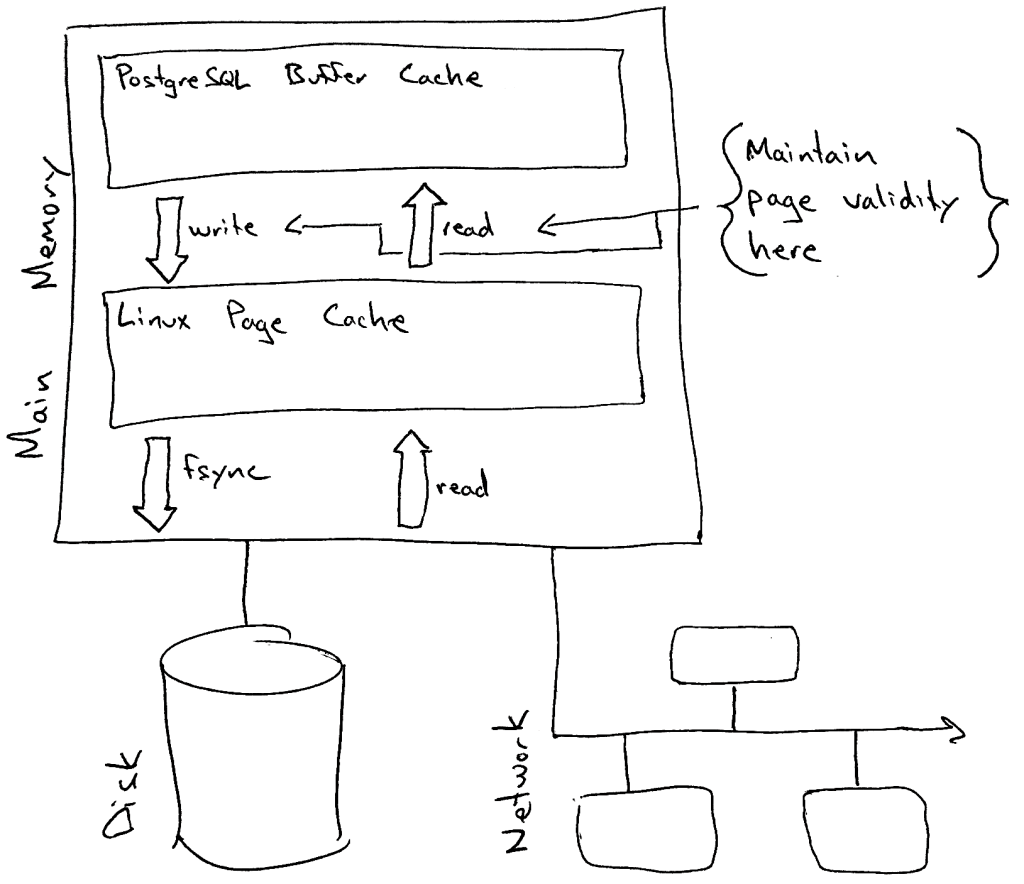
What does this mean in practice? Suppose there’s a physical memory failure and somehow the ECC parity is unable to detect it. This means that a little bit of physical memory on the server now has incorrect garbage and the correct data from that memory is lost.
- If the garbage bytes map to part of the kernel page cache, then when PostgreSQL tries to copy the page into it’s buffer cache then it will (if possible) detect that something is wrong, refuse to poison its buffer cache with this invalid 8k page, and error out any queries that require this page for processing with the ERROR message above.
- If the garbage bytes map to part of PostgreSQL’s database buffer cache, then PostgreSQL will quite happily assume nothing is wrong and attempt to process the data on the page. Results are unpredictable; probably all sorts of ERROR messages, crashes and failure modes could result – or maybe even incorrect data returned with no ERROR message at all. (Note that this is probably the case for nearly all software… and also note that ECC is pretty good.)
PostgreSQL has two main “validity checks” that it performs on pages. You can read the code in the function PageIsVerified() but I’ll summarize here. You can tell from your error message which validity check failed. It depends on whether you see a second additional WARNING right before the ERROR. The warning would look like this:
WARNING: page verification failed, calculated checksum 3482 but expected 32232- If the above warning is not present, this means the page header failed a basic sanity check. This could conceivably be caused by both problems inside and outside of PostgreSQL.
- If you see the above warning (page verification failed), this means the checksum recorded in the block did not match the checksum calculated for the block. This most likely indicates that there was a problem outside of (underneath) the database – operating system, memory, networking, storage, etc.
As of when I’m writing this article in 2019, the following basic sanity checks are performed on the page header:
- There are 32 bits reserved for page flag bits; at present only three are used and the other 29 bits should always be zero/off.
- Every page is divided into four parts (header, free space, tuples, special space). Offsets for the divisions are stored as 16-bit numbers in the page header; the offsets should go in order and should not have a value pointing off the page.
- The offset of the special space should always be aligned.
PostgreSQL version 9.3 (released in 2013) added the ability to calculate a checksum on data pages and store the checksum in the page. There are two inputs to the checksum: (1) every single byte of the data page, with zeros in the four bytes where the checksum will be stored later and (2) the page offset/address. This means that PostgreSQL doesn’t just detect if a byte is changed in the page – it also detects if a perfectly valid page gets somehow dropped into the wrong place.
Checksums are not maintained for blocks while they are in the shared buffers – so if you look at a buffer in the PostgreSQL page cache with pageinspect and you see a checksum value, note that it’s probably just leftover from the last read but wouldn’t have been maintained when the page was changed. The checksum is calculated and stamped onto the page when the page is written out of the buffer cache into the operating system page cache (remember the pages get flushed to disk later by a separate fsync call).
The checksum algorithm is specifically designed to take advantage of SIMD instructions. The slowest part of the algorithm is multiplication, so if possible PostgreSQL will be compiled to perform 32 multiplications at a time in parallel. In 2013 there were two platforms specifically documented to support this: x86 SSE4.1 and ARM NEON. The implementation is specifically tuned for optimal performance on x86 SSE. This is an important point actually – particularly for folks running PostgreSQL on embedded devices – PostgreSQL certainly compiles and works well on a lot of platforms, but evidently the checksum implementation is explicitly optimized to run the fastest on Intel. (To be clear… I think everyone should use checksums on every platform unless you have a really really good reason not to – just don’t be surprised if you start comparing benchmarks with Intel and you see a difference!)
For folks interested in digging a little more into the history… here’s the original commit using a CRC algorithm which never shipped in an actual PostgreSQL release (Simon Riggs, Jeff Davis and Greg Smith), here’s the subsequent commit introducing the FNV-1a algorithm instead of CRC which is what we still use today (Ants Aasma), and here’s the commit doing the major refactor which moved the algorithm into a header file for easier external use (Tom Lane).
More Ways To Check ValidityAt the SEAPUG meetup this led to a discussion about checking validity. Do checksums cover everything? (hint: no) Are there more ways we can validate our databases? (hint: yes)
I haven’t yet made a full list of which files are covered by checksums and which ones aren’t, but I know that not everything is. For example: I’m pretty sure that the visiblity map and SLRU files aren’t covered with checksums. But for what it’s worth, there are two extra tools we can use verification in PostgreSQL databases:
- The amcheck extension can scan a B-Tree index for a number of logical problems – for example, verifying that all B-Tree pages have items in “logical” order. (This could be useful, for example, if you’re not specifying ICU collation and you recently upgraded your operating system collation libraries… since PostgreSQL uses OS collation by default.)
- The pg_visibility_map extension includes two functions to check for corruption in the visibility map – pg_check_frozen() and pg_check_visible().
Finally, what if you actually run into a checksum failure? What should you do, and are there any additional tools you should know about?
First of all – on any database – there are a few things you should always do immediately when you see something indicating that a data corruption may have occurred:
- Verify that your backup retention and your log file retention are sufficiently long – I recommend at least a month (this is a Happiness Hint). You never know how long the investigation might take, or how long ago something important might have happened.
- Take a moment to articulate and write out the impact to the business. (Are important queries failing right now? Is this causing an application outage?) This seems small but it can be very useful in making decisions later. Don’t exaggerate the impact but don’t understate it either. It can also be helpful to note important timelines that you already know about. For example: management is willing to use yesterday’s backup and take a day of data loss to avoid an 12 hour outage, but not to avoid a 4 hour outage …or… management needs a status update at 11:00am Eastern Time.
- If there’s a larger team working on the system in question, communicate a freeze on changes until things are resolved.
- Make a list or inventory of all copies of the data. Backups, physical replicas or hot standbys, logical replicas, copies, etc. Sometimes the very process of making this list can immediately give you ideas for simple solutions (like checking if a hot standby has the block intact). The next thing you probably want to do is check all items in this list to see if they have a valid copy of the data in question. Do not take any actions to remediate the problem right away, collect all of the information first. The data you collect now might useful during RCA investigation after you’re back online.
- If there was one checksum failure, then you probably want to make sure there aren’t more.
- If it’s a small database, consider whether you can scan the whole thing and verify the checksum on every single block.
- If it’s a large database, consider whether you can at least scan all of the system/catalog tables and perhaps scan the tables which are throwing errors in their entirety. (PostgreSQL stops on the first error, so there isn’t an easy way to check if other blocks in the same table also have checksum problems.)
- A few general best practices… (1) have a second person glance at your screen before you execute any actual changes, (2) never delete anything but always rename/move instead, (3) when investigating individual blocks, also look at the block before and the block after to verify they look like what you’d normally expect, (4) test the remediation plan before running it in production, and (5) document everything. If you’ve never seen Paul Vallée’s FIT-ACER checklist then it’s worth reviewing.
There’s no single prescriptive process for diagnosing the scope of the problem and finding the right path forward for you. It involves learning what you need to know about PostgreSQL, a little creative thinking about possible resolutions, and balancing the needs of the business (for example, how long can you be down and how much data loss can you tolerate).
That being said, there are a few tools I know about which can be very useful in the process. (And there are probably more that I don’t know about; please let me know and I can add them to this list!)
Data investigation:Unix/Linux CommandsYou might be surprised at what you can do with the tools already installed on your operating system. I’ve never been on a unix system that didn’t have dd and od installed, and I find that many Linux systems have hexdump and md5sum installed as well. A few examples of how useful these tools are: dd can extract the individual block with invalid data on the primary server and extract the same block on the hot standby, then od/hexdump can be used to create a human-readable textual dump of the binary data. You can even use diff to find the differences between the blocks. If you have a standby cluster with storage-level replication then you could use md5sum to see at a glance if the blocks match. (Quick word of caution on comparing hot standbys: last I checked, PostgreSQL doesn’t seem to maintain the free space identically on hot standbys, so the checksums might differ on perfectly healthy blocks. You can still look at the diff and verify whether free space is the only difference.) Drawbacks: low-level utilities can only do binary dumps but cannot interpret the data. Also, utilities like dd are “sharp knives” – powerful tools which can cause damage if misused!
For a great example of using dd and od, read the code in Bertrand Drouvot‘s pg_toolkit script collection.Data investigation and checksum verification:
pg_filedumpThis is a crazy awesome utility and I have no idea why it’s not in core PostgreSQL. It makes an easy-to-read textual dump of the binary contents of PostgreSQL data blocks. You can process a whole file or just specify a range of blocks to dump. It can verify checksums and it can even decode the contents of the tuples. As far as I can tell, it was originally written by Patrick Macdonald at Red Hat some time in the 2000’s and then turned over to the PostgreSQL Global Development Group for stewardship around 2011. It’s now in a dedicated repository at git.postgresql.org and it seems that Tom Lane, Christoph Berg and Teodor Sigaev keep it alive but don’t invest heavily in it. Drawbacks: be aware that it doesn’t address the race condition with a running server (see Credativ pg_checksums below). For dumping only a block with a checksum problem, this is not an issue since the server won’t let the block into its buffer cache anyway.Checksum verification:
PostgreSQL pg_checksumsPostgreSQL itself starting in version 11 has a command-line utility to scan one relation or everything and verify the checksum on every single block. It’s called pg_verify_checksums in v11 and pg_checksums in v12. Drawbacks: first, this utility requires you to shut down the database before it will run. It will throw an error and refuse to run if the database is up. Second, you can scan a single relation but you can’t say which database it’s in… so if the OID exists in multiple databases, there’s no way to just scan the one you care about.Checksum verification:
Credativ pg_checksumsThe fine engineers of Credativ have published an enhanced version of pg_checksums which can verify checksums on a running database. It looks to me like the main case they needed to protect against was the race condition between pg_checksum reading blocks while the running PostgreSQL server was writing those same blocks. Linux of course work on a 4k page size; so if an 8k database page is half written when pg_checksum reads it then we will get a false positive. The version from credativ however is smart enough to deal with this. Drawbacks: check the github issues; there are a couple notable drawbacks but this project was only announced last week and all the drawbacks might be addressed by the time you read this article. Also, being based on the utility in PostgreSQL, the same limitation about scanning a single relation applies.
Note that both Credativ’s and PostgreSQL’s pg_checksums utilities access the control file, even when just verifying checksums. As a result, you need to make sure you compile against the same version of PostgreSQL code as the target database you’re scanning.Checksum verification:
Satoshi Nagayasu postgres-toolkitI’m not sure if this is still being maintained, but Satoshi Nagayasu wrote postgres-toolkit quite a long time ago which includes a checksum verification utility. It’s the oldest one I have seen so far – and it still compiles and works! (Though if you want to compile it on PostgreSQL 11 or newer then you need to use the patch in this pull request.) Satoshi’s utility also has the very useful capability of scanning an arbitrary file that you pass in – like pg_filedump but stripped down to just do the checksum verification. It’s clever enough to infer the segment number from the filename and scan the file, even if the file isn’t part of a PostgreSQL installation. This would be useful, for example, if you were on a backup server and wanted to extract a single file from your backup and check if the damaged block has valid checksum in the backup. Drawbacks: be aware that it doesn’t address the race condition with a running server.Checksum verification:
Google pg_page_verificationSimple program; you pass in a data directory and it will scan every file in the data directory to verify the checksums on all blocks. Published to Github in early 2018. Drawbacks: be aware that it doesn’t address the race condition with a running server. Probably superseded by the built-in PostgreSQL utilities.Mitigation:
PostgreSQL Developer OptionsPostgreSQL has hundreds of “parameters” – knobs and button you can use to configure how it runs. There are 294 entries in the pg_settings table on version 11. Buried in these parameters are a handful of “Developer Options” providing powerful (and dangerous) tools for mitigating data problems – such as ignore_checksum_failure, zero_damaged_pages and ignore_system_indexes. Read very carefully and exercise great care with these options – when not fully understood, they can have unexpected side effects including unintended data loss. Exercise particular care with the ignore_checksum_failure option – even if you set that in an individual session, the page will be readable to all connections… think of it as poisoning the buffer cache. That being said, sometimes an option like zero_damaged_pages is the fastest way to get back up and running. (Just make sure you’ve saved a copy of that block!) By the way… a trick to trigger a read of one specific block is to
SELECT * FROM table WHERE ctid='(blockno,1)'Mitigation:Unix/Linux CommandsI would discourage the use of dd to mitigate invalid data problems. It’s dangerous even for experienced engineers; simple mistakes can compound the problem. I can’t imagine a situation where this is a better approach than the zero_damaged_pages developer option and a query to read a specific block. That said, I have seen cases where dd was used to zero out a page. More About Data Investigation
In order to put some of this together, I’ll just do a quick example session. I’m running PostgreSQL 11.5 an on EC2 instance and I used dd to write a few evil bytes into a couple blocks of my database.
First, lets start by just capturing the information from the log files:
$ grep "invalid page" ../log/postgresql.log|sed 's/UTC.*ERROR//'
2019-10-15 19:53:37 : invalid page in block 0 of relation base/16385/16493
2019-10-16 22:26:30 : invalid page in block 394216 of relation base/16385/16502
2019-10-16 22:43:24 : invalid page in block 394216 of relation base/16385/16502
2019-11-05 23:55:33 : invalid page in block 394216 of relation base/16385/16502
2019-11-05 23:57:58 : invalid page in block 394216 of relation base/16385/16502
2019-11-05 23:59:14 : invalid page in block 262644 of relation base/16385/16502
2019-11-05 23:59:21 : invalid page in block 262644 of relation base/16385/16502
2019-11-05 23:59:22 : invalid page in block 262644 of relation base/16385/16502
2019-11-05 23:59:23 : invalid page in block 262644 of relation base/16385/16502
2019-11-06 00:01:12 : invalid page in block 262644 of relation base/16385/16502
2019-11-06 00:01:16 : invalid page in block 0 of relation base/16385/16493
2019-11-06 00:02:05 : invalid page in block 250 of relation base/16385/16492With a little command-line karate we can list each distinct block and see the first time we got an error on that block:
$ grep "invalid page" ../log/postgresql.log |
sed 's/UTC.*ERROR//' |
awk '{print $1" "$2" "$11" invalid_8k_block "$8" segment "int($8/131072)" offset "($8%131072)}' |
sort -k3,5 -k1,2 |
uniq -f2
2019-11-06 00:02:05 base/16385/16492 invalid_8k_block 250 segment 0 offset 250
2019-10-15 19:53:37 base/16385/16493 invalid_8k_block 0 segment 0 offset 0
2019-11-05 23:59:14 base/16385/16502 invalid_8k_block 262644 segment 2 offset 500
2019-10-16 22:26:30 base/16385/16502 invalid_8k_block 394216 segment 3 offset 1000 So we know that there are at least 4 blocks corrupt. Lets scan the whole data directory using Credativ’s pg_checksum (without shutting down the database) to see if there are any more blocks with bad checksums:
$ pg_checksums -D /var/lib/pgsql/11.5/data |& fold -s
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16502.3", block 1000: calculated checksum
2ED4 but block contains 4EDF
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16502.3", block 1010: calculated checksum
9ECF but block contains ACBE
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16502.2", block 500: calculated checksum
5D6 but block contains E459
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16493", block 0: calculated checksum E7E4
but block contains 78F9
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16492", block 250: calculated checksum
44BA but block contains 3ABA
Checksum operation completed
Files scanned: 1551
Blocks scanned: 624158
Bad checksums: 5
Data checksum version: 1Ah-ha… there was one more bad checksum which didn’t show up in the logs! Next lets choose one of the bad blocks and dump the contents using unix command line tools.
$ dd status=none if=base/16385/16492 bs=8192 count=1 skip=250 | od -A d -t x1z -w16
0000000 00 00 00 00 e0 df 6b b0 ba 3a 04 00 0c 01 80 01 >......k..:......<
0000016 00 20 04 20 00 00 00 00 80 9f f2 00 00 9f f2 00 >. . ............<
0000032 80 9e f2 00 00 9e f2 00 80 9d f2 00 00 9d f2 00 >................<
0000048 80 9c f2 00 00 9c f2 00 80 9b f2 00 00 9b f2 00 >................<
0000064 80 9a f2 00 00 9a f2 00 80 99 f2 00 00 99 f2 00 >................<
0000080 80 98 f2 00 00 98 f2 00 80 97 f2 00 00 97 f2 00 >................<Here we see the page header and the beginning of the line pointers. One thing I think it’s easy to remember is that the first 8 bytes are the page LSN and the next 2 bytes are the page checksum. Notice that the page checksum bytes contain “ba 3a” which matches the error message from the scan above (3ABA). Sometimes it can be useful to know just the very top of the page even if you don’t remember anything else!
This is useful, but lets try the pg_filedump utility next. This utility takes a lot of options. In this example I’m going to ask it to verify the checksum (-k), only scan one block at offset 250 (-R 250 250) and even to decode the tuples (table row data) to a human-readable format (-D int,int,int,charN). There’s another argument (-f) that can even tell pg_filedump to show hexdump/od style raw data inline but I won’t demonstrate that here.
$ pg_filedump -k -R 250 250 -D int,int,int,charN base/16385/16492
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility - Version 11.0
*
* File: base/16385/16492
* Options used: -k -R 250 250 -D int,int,int,charN
*
* Dump created on: Fri Nov 8 21:48:38 2019
*******************************************************************
Block 250 ********************************************************
<Header> -----
Block Offset: 0x001f4000 Offsets: Lower 268 (0x010c)
Block: Size 8192 Version 4 Upper 384 (0x0180)
LSN: logid 0 recoff 0xb06bdfe0 Special 8192 (0x2000)
Items: 61 Free Space: 116
Checksum: 0x3aba Prune XID: 0x00000000 Flags: 0x0004 (ALL_VISIBLE)
Length (including item array): 268
Error: checksum failure: calculated 0x44ba.
<Data> ------
Item 1 -- Length: 121 Offset: 8064 (0x1f80) Flags: NORMAL
COPY: 15251 1 0
Item 2 -- Length: 121 Offset: 7936 (0x1f00) Flags: NORMAL
COPY: 15252 1 0
Item 3 -- Length: 121 Offset: 7808 (0x1e80) Flags: NORMAL
COPY: 15253 1 0That was the block header and the first few item. (Item pointer data is displayed first, then the table row data itself is displayed on the following line after the word COPY.) Looking down a little bit, we can even see where I wrote the bytes “budstuff” into a random location in this block – it turns out those bytes landed in the middle of a character field. This means that without checksums, PostgreSQL would not have thrown any errors at all but just returned an incorrect string the next time that row was queried!
COPY: 15297 1 0
Item 48 -- Length: 121 Offset: 2048 (0x0800) Flags: NORMAL
COPY: 15298 1 0
Item 49 -- Length: 121 Offset: 1920 (0x0780) Flags: NORMAL
COPY: 15299 1 0 badstuff
Item 50 -- Length: 121 Offset: 1792 (0x0700) Flags: NORMAL
COPY: 15300 1 0It’s immediately clear how useful this is (and easier to read <g>). The part where it decodes the table row data into a human readable form is an especially cool trick. Two notes about this.
- First, the lines are prefixed with the word COPY for a reason – they are actually intended to be formatted so you can grep on the word COPY and then use the “copy” command (or it’s psql cousin) to feed the data directly back into a staging table in the database for cleanup. How cool is that!
- Second, it can decode only a set of fairly standard data types and relation types.
$ pg_filedump -h
Version 11.0 (for PostgreSQL 11.x)
Copyright (c) 2002-2010 Red Hat, Inc.
Copyright (c) 2011-2018, PostgreSQL Global Development Group
Usage: pg_filedump [-abcdfhikxy] [-R startblock [endblock]]
[-D attrlist] [-S blocksize] [-s segsize] [-n segnumber] file
Display formatted contents of a PostgreSQL heap/index/control file
Defaults are: relative addressing, range of the entire file, block
size as listed on block 0 in the file
The following options are valid for heap and index files:
...
...
...
-D Decode tuples using given comma separated list of types
Supported types:
bigint bigserial bool char charN date float float4 float8 int
json macaddr name oid real serial smallint smallserial text
time timestamp timetz uuid varchar varcharN xid xml
~ ignores all attributes left in a tupleNow you see what happens when I start having fun… a quick update about our SEAPUG meetup this past Tuesday turned into a blog article that’s way too long. :) Hope it’s useful, and as always let me know what I can improve!
Update 9/16/21 – It was an oversight that I didn’t link it when I first published this post – but the PostgreSQL community wiki has a page on corruption. That page has a ton of good information and is definitely worth referencing.
Seattle PostgreSQL Meetup This Thursday: New Location
I’m looking forward to the Seattle PostgreSQL User Group meetup this Thursday (June 20, 2019) at 5:30pm! We’re going to get an early sneak peek at what’s coming later this year in PostgreSQL’s next major release. The current velocity of development in this open source community is staggering and this is an exciting and valuable opportunity to keep up with where PostgreSQL is going next.
One thing that’s a bit unusual about this meetup is the new location and late timing of the announcement. I think it’s worth a quick blog post to mention the location: for some people this new location might be a little more accessible than the normal spot (over at the Fred Hutch).
The meetup this week will be closer to downtown at 2201 6th Avenue (the building says “Blanchard Plaza” above the entrance): right next to the Spheres, easily accessible from public transportation and free parking across the street.

If you live or work in Seattle and you’re interested in databases but you don’t normally attend the Seattle PostgreSQL User Group, it’s worth checking if this location might be more convenient and make the visit worthwhile.
Bring any database question you have – there are people here who know PostgreSQL well enough to answer anything you can throw at them! Also, as always, some pizza and drinks will be provided. Hope to see you there!
PostgresConf 2019 Training Days
 It feels like PostgresConf in New York is in full swing, even though the main tracks haven’t even started yet!
It feels like PostgresConf in New York is in full swing, even though the main tracks haven’t even started yet!
(Oh, and by the way, as of this morning I heard there are still day-passes available for those who haven’t yet registered for the conference… and then you can come hear a great session about Wait Events in PostgreSQL this Thursday at 4:20pm!)
The first two days of PostgresConf are summits, tutorials and training sessions. A good chunk of my day today was helping out with Scott Mead’s intensive 3 hour hands-on lab Setting up PostgreSQL for Production in AWS – but outside of that I’ve managed to drop in to a number of other sessions that sounded interesting. I did my best to take down some notes so I could share a few highlights.
Monday March 18Personally, my favorite session on Monday was Brent Bigonger’s session. He’s a database engineer at Amazon who was involved in migrating their Inventory Management System to Aurora PostgreSQL. I always love hearing good stories (part of why I’ve always been a fan of user groups) – this presentation gave a nice high level overview of the business, a review of the planning and execution process for the migration, and lots of practical lessons learned.
- Some of the tips were things people are generally familiar with – like NULLs behaving differently and the importance of performance management with a tool like Performance Insights.
- My favorite tip is getting better telemetry by instrumenting SQL with comments (SELECT /* my-service-call-1234 */ …) which reminded me of something I also read in Baron Schwartz’s recently updated e-book on observable systems: “including implicit data in SQL.”
- A great new tip (to me) was the idea of creating a heartbeat table as one more safety check in a replication process. You can get a sense for lag by querying the table and you can also use it during a cutover to get an extra degree of assurance that no data was missed.
- Another general point I really resonated with: Brent gave a nice reminder that a simple solution which meets the business requirements is better than a sophisticated or complex solution that goes beyond what the business really needs. I feel tempted on occasion to leverage architectures because they are interesting – and I always appreciate hearing this reiterated!
On the AWS track, aside from Brent’s session, I caught a few others: Jim Mlodgenski giving a deep dive on Aurora PostgreSQL architecture and Jim Finnerty giving a great talk on Aurora PostgreSQL performance tuning and query plan management. It’s funny, but I think my favorite slide from Finnerty’s talk was actually one of the simplest and most basic; he had a slide that just had high-level list of steps for performance tuning. I don’t remember the exact list on that slide at the moment, but the essential process: (1) identify to top SQL (2) EXPLAIN to get the plan (3) make improvements to the SQL and (4) test and verify whether the improvements actually had the intended effect.
Other sessions I dropped into:
- Alvaro Hernandez giving an Oracle to PostgreSQL Migration Tutorial. I love live demos (goes along with loving hands on labs) and so this session was a hit with me – I wasn’t able to catch the whole thing but I did catch a walk-through of ora2pg.
- Avinash Vallarapu giving an Introduction to PostgreSQL for Oracle and MySQL DBAs. When I slipped in, he was just wrapping up a section on hot physical backups in PostgreSQL with the pg_basebackup utility. After that, Avi launched into a section on MVCC in PostgreSQL – digging into transaction IDs and vacuum, illustrated with block dumps and the pageinspect extension. The part of this session I found most interesting was actually a few of the participant discussions – I heard lively discussions about what extensions are and about comparisons with RMAN and older versions of Oracle.
As I said before, a good chunk of my morning was in Scott’s hands-on lab. If you ever do a hands-on lab with Scott then you’d better look out… he did something clever there: somewhere toward the beginning, if you followed the instructions correctly, then you would be unable to connect to your database! Turns out this was on purpose (and the instructions actually tell you this) – since people often have this particular problem connecting when they first start on out RDS, Scott figured he’d just teach everyone how to fix it. I won’t tell you what the problem actually is though – you’ll have to sign up for a lab sometime and learn for yourself. :)
As always, we had a lot of really interesting discussions with participants in the hands-on lab. We talked about the DBA role and the shared responsibility model, about new tools used to administer RDS databases in lieu of shell access (like Performance Insights and Enhanced Monitoring), and about how RDS helps implement industry best practices like standardization and automation. On a more technical level, people were interested to learn about the “pgbench” tool provided with postgresql.
In addition to the lab, I also managed to catch part of Simon Riggs’ session Essential PostgreSQL11 Database Administration – in particular, the part about PostgreSQL 11 new features. One interesting new thing I learned was about some work done specifically around the performance of indexes on monotonically increasing keys.
Interesting Conversations Of course I learned just as much outside of the sessions as I learned in the sessions. I ended up eating lunch with Alexander Kukushkin who helped facilitate a 3 hour hands-on session today about Understanding and implementing PostgreSQL High Availability with Patroni and enjoyed hearing a bit more about PostgreSQL at Zalando. Talked with a few people from a government organization who were a long-time PostgreSQL shop and interested to hear more about Aurora PostgreSQL. Talked with a guy from a large financial and media company about flashback query, bloat and vacuum, pg_repack, parallel query and partitioning in PostgreSQL.
Of course I learned just as much outside of the sessions as I learned in the sessions. I ended up eating lunch with Alexander Kukushkin who helped facilitate a 3 hour hands-on session today about Understanding and implementing PostgreSQL High Availability with Patroni and enjoyed hearing a bit more about PostgreSQL at Zalando. Talked with a few people from a government organization who were a long-time PostgreSQL shop and interested to hear more about Aurora PostgreSQL. Talked with a guy from a large financial and media company about flashback query, bloat and vacuum, pg_repack, parallel query and partitioning in PostgreSQL.
And of course lots of discussions about the professional community. Met PostgresConf conference volunteers from California to South Africa and talked about how they got involved in the community. Saw Lloyd and chatted about the Seattle PostgreSQL User Group.
The training and summit days are wrapping up and now it’s time to get ready for the next three days: keynotes, breakout sessions, exposition, a career fair and more! I can’t wait. :)
Column And Table Redefinition With Minimal Locking
TLDR: Note to future self… (1) Read this before you modify a table on a live PostgreSQL database. If you do it wrong then your app might totally hang. There is a right way to do it which avoids that. (2) Especially remember the lock_timeout step. Many blog posts around the ‘net are missing this and it’s very important.
Yesterday I was talking to some PostgreSQL users (who, BTW, were doing rather large-scale cool stuff in PG) and they asked a question about making schema changes with minimal impact to the running application. They were specifically curious about changing a primary key from INT to BIGINT. (Oh, you are making all your new PK fields BIGINT right?)
And then, low and behold, I discovered a chat today on the very same topic. Seemed useful enough to file away on my blog so that I can find it later. BTW I got permission from Jim Nasby, Jim F and Robins Tharakan to blame them for this… ;)
Most useful part of the chat was how to think about doing table definition changes in PostgreSQL with minimal application impact due to locking:
- Use lock_timeout.
- Can be set at the session level.
- For changes that do more than just a quick metadata update, work with copies.
- Create a new column & drop old column instead of modifying.
- Or create a new table & drop old table.
- Use triggers to keep data in sync.
- Carefully leverage transactional DDL (PostgreSQL rocks here!) to make changes with no windows for missing data.
We can follow this line of thought even for a primary key – creating a unique index on the new column, using existing index to update table constraints, then dropping old column.
One of the important points here is making sure that operations which require locks are metadata-only. That is, they don’t need to actually modify any data (while holding said lock) for example rewriting or scanning the table. We want these ops to run very very fast, and even time out if they still can’t run fast enough.
A few minutes on google yields proof that Jim Nasby was right: lots of people have already written up some really good advice about this topic. Note that (as always) you should be careful about dates and versions in stuff you find yourself. Anything pre-2014 should be scrutinized very carefully (PostgreSQL has change a lot since then); and for the record, PostgreSQL 11 changes this specific list again (and none of these articles seem to be updated for pg11 yet). And should go without saying, but test test test…
- This article from BrainTree is my favorite of what I saw this morning. Concise yet clear list of green-light and red-light scenarios, with workaround for all the red lights.
- Add a new column, Drop a column, Add an index concurrently, Drop a constraint (for example, non-nullable), Add a default value to an existing column, Add an index, Change the type of a column, Add a column with a default, Add a column that is non-nullable, Add a column with a unique constraint, VACUUM FULL
- Citus has a practical tips article that’s linked pretty widely.
- adding a column with a default value, using lock timeouts, Create indexes, Taking aggressive locks, Adding a primary key, VACUUM FULL, ordering commands
- assembled a list in 2016 which is worth reviewing.
- Add a new column, Add a column with a default, Add a column that is non-nullable, Drop a column, Change the type of a column, Add a default value to an existing column, Add an index, Add a column with a unique constraint, Drop a constraint, VACUUM FULL, ALTER TABLE SET TABLESPACE
- Joshua Kehn put together a good article in late 2017 that especially illustrates the importance of using lock_timeout (though he doesn’t mention it in the article)
- Default values for new columns, Adding a default value on an existing column, Concurrent index creation, ALTER TABLE, importance of typical transaction length
For fun and posterity, here’s the original chat (which has a little more detail) where they gave me these silly ideas:
[11/08/18 09:01] Colleague1: I have a question with regard to APG. How can we make DDL modifications to a table with minimalistic locking (downtime)?
[11/08/18 09:31] Jim N: It depends on the modification you're trying to make. Many forms of ALTER TABLE are very fast. Some don't even require an exclusive lock.
[11/08/18 09:32] Jim N: What you have to be careful of are alters that will force a rewrite of the entire table. Common examples of that are adding a new column that has a default value, or altering the type of an existing column.
[11/08/18 09:33] Jim N: What I've done in the past for those scenarios is to create a new field (that's null), put a before insert or update trigger on the table to maintain that field.
[11/08/18 09:33] Jim N: Then run a "backfill" that processes a few hundred / thousand rows per transaction, with a delay between each batch.
[11/08/18 09:34] Jim N: Once I know that all rows in the table have been properly updated, drop the old row, and maybe mark the new row as NOT NULL.
[11/08/18 09:43] Jim N: btw, I know there's been a talk about this at a conference in the last year or two...
[11/08/18 09:49] Jim F: What happens at the page level if the default value of an ALTER TABLE ADD COLUMN is null? Once upon a time when I worked at [a commercialized fork of PostgreSQL], which was built on a version of PostgreSQL circa 2000, I recall that the table would be versioned. This was a pure metadata change, but the added columns would be created for older-version rows on read, and probably updated on write. Is that how it currently works?
[11/08/18 09:55] Jim N: Jim F in essence, yes.
[11/08/18 09:56] Jim N: Though I wouldn't describe it as being "versioned"
[11/08/18 09:57] Jim N: But because columns are always added to the end of the tuple (and we never delete from pg_attribute), heap_deform_tuple can detect if a tuple is "missing" columns at the end of the tuple and just treat them as being null.
[11/08/18 09:57] Jim N: At least I'm pretty sure that's what's going on, without actually re-reading the code right now. 😉
[11/08/18 10:08] Jim F: does it work that way for non-null defaults as well? that would create a need for versioning, if the defaults changed at different points in time
[11/08/18 10:08] Robins: While at that topic.... Postgres v11 now has the feature to do what Jim F was talking about (even for non-NULLs). Although as Jim Nasby said, you still need to be careful about which (other) kind of ALTERs force a rewrite and use the Trigger workaround. "Many other useful performance improvements, including the ability to avoid a table rewrite for ALTER TABLE ... ADD COLUMN with a non-null column default"
[11/08/18 10:08] Jim F: exactly...
Did we get anything wrong here? Do you disagree? Feel free to comment. :)