

Duncan Mein
All views, comments and posts are my own and not that of Oracle.Duncanhttp://www.blogger.com/profile/07134700830240982976noreply@blogger.comBlogger39125
Updated: 6 hours 20 min ago
Clear Cache for all Pages within a Page Group
Most client sites I have been on tend to love wizards that hold the users hand through often complex business process / workflows.
As a general rule, if I have a 10 step wizard (I generally use 1 page per step) I like to ensure that all 10 pages have their cache cleared as the user enters the wizard to ensure no values from a previous attempt to complete the process are hanging around. This is typically done by enter a comma delimited string of all the page numbers you wish to clear the cache of upon branching from page to page.
In an ideal world, what I wanted to do was take advantage of the fact that I had taken to time to put all 10 pages into a page group and clear the cache of ALL pages contained within. Furthermore, using this logic, pages can come and go from the page group without the need to worry about how this effect my clearing of session state. Pretty cool huh, but wait, "APEX only allows you to enter page numbers and not page group names into the clear cache text box" I hear you say.
Not a problem. This can be achieved very simply by using an Application Item, A Single Application Process and Page Groups. Here is how:
Solution.
1. Create a Page Group with a name the logically describes the functional area it servers. In this example I will use the name: "CREDIT_CARD_APPLICATION".
2. Edit the definition of all pages (10 in my case) and them to this newly created group.
3. Create an Application Item called the same name as your group created in step 1 i.e. my Application Item was named: "CREDIT_CARD_APPLICATION".
4. Create an Application Process called: "Get CRETID_CARD_APPLICATION_PAGES" and of Process Type: "On New Instance (new session)" and add the following code to the Process Text region:
BEGIN
select LISTAGG(page_id,',') WITHIN GROUP (ORDER BY page_id)
into :CREDIT_CARD_APPLICATION_PAGES
from apex_application_pages where application_id = :APP_ID
and page_group = 'CREDIT_CARD_APPLICATION';
EXCEPTION
WHEN NO_DATA_FOUND
THEN
:CREDIT_CARD_APPLICATION_PAGES := NULL;
WHEN OTHERS
THEN
RAISE;
END;
5. Finally, in the branch that you want to clear the cache for all pages within the page group, simply place a substitution string reference to &CREDIT_CARD_APPLICATION_PAGES. in the clear cache text box and viola!!!
Explanation.
This very simply queries the APEX Data Dictionary to work out all the pages within your names Page Group.
It then uses the XMLAGG aggregation function native to 11gR2 (I blogged about this here) to build a comma delimited string of all these pages and assigns the output to your application item. (Not is done once per session for performance reasons).
Now that you have a list of all the pages in your page group as a value in session, you can substitute this into any branch using the standard substitution syntax. Simple really but ideally, it would be nice if Oracle provided this out of the tin. Until then, this seems to be a pretty good workaround.
As a general rule, if I have a 10 step wizard (I generally use 1 page per step) I like to ensure that all 10 pages have their cache cleared as the user enters the wizard to ensure no values from a previous attempt to complete the process are hanging around. This is typically done by enter a comma delimited string of all the page numbers you wish to clear the cache of upon branching from page to page.
In an ideal world, what I wanted to do was take advantage of the fact that I had taken to time to put all 10 pages into a page group and clear the cache of ALL pages contained within. Furthermore, using this logic, pages can come and go from the page group without the need to worry about how this effect my clearing of session state. Pretty cool huh, but wait, "APEX only allows you to enter page numbers and not page group names into the clear cache text box" I hear you say.
Not a problem. This can be achieved very simply by using an Application Item, A Single Application Process and Page Groups. Here is how:
Solution.
1. Create a Page Group with a name the logically describes the functional area it servers. In this example I will use the name: "CREDIT_CARD_APPLICATION".
2. Edit the definition of all pages (10 in my case) and them to this newly created group.
3. Create an Application Item called the same name as your group created in step 1 i.e. my Application Item was named: "CREDIT_CARD_APPLICATION".
4. Create an Application Process called: "Get CRETID_CARD_APPLICATION_PAGES" and of Process Type: "On New Instance (new session)" and add the following code to the Process Text region:
BEGIN
select LISTAGG(page_id,',') WITHIN GROUP (ORDER BY page_id)
into :CREDIT_CARD_APPLICATION_PAGES
from apex_application_pages where application_id = :APP_ID
and page_group = 'CREDIT_CARD_APPLICATION';
EXCEPTION
WHEN NO_DATA_FOUND
THEN
:CREDIT_CARD_APPLICATION_PAGES := NULL;
WHEN OTHERS
THEN
RAISE;
END;
5. Finally, in the branch that you want to clear the cache for all pages within the page group, simply place a substitution string reference to &CREDIT_CARD_APPLICATION_PAGES. in the clear cache text box and viola!!!
Explanation.
This very simply queries the APEX Data Dictionary to work out all the pages within your names Page Group.
It then uses the XMLAGG aggregation function native to 11gR2 (I blogged about this here) to build a comma delimited string of all these pages and assigns the output to your application item. (Not is done once per session for performance reasons).
Now that you have a list of all the pages in your page group as a value in session, you can substitute this into any branch using the standard substitution syntax. Simple really but ideally, it would be nice if Oracle provided this out of the tin. Until then, this seems to be a pretty good workaround.
Oracle VirtualBox... a good thing.
Now as anyone who knows me me will confirm, I have always been a long admirer of VMWare and their suite of excellent virtualisation products. I started with Workstation before switching to Fusion on OS X and finally made the jump to the way cool ESXi a few years back (I blogged about this here).
Recently however, I am finding less and less time to install guest linux OS, configuring it for use with an Oracle Database (or Application Server), making sure all the RPM's, kernel values are correct etc. Yes you can use the Oracle Validated Packages to help simplify this (see Tims comments below for how to obtain these) but what I really value these days is the simplest configuration for home / home office use that is pretty much turn on and play.
After a quick trawl of the Virtual Appliances section of the VM Market Place, I was left wanting until I remembered that Oracle were now dabbling in the Virtual Machine space. After a quick dl of VirtualBox (their virtualisation offering) and a pre-built development database, I was up an running within 30 mins. Firthermore I have it running on 2G of memory and 1 CPU locally on my MacBook Pro.
I must say I was very impressed with the build of the VM itself, the interface of VirtualBox and just how simple it was to get a "throw away" vm running that covers 99% of my day to day needs.
I have to admit, I am struggling to justify moving back to a costed option of VMWare and can only see the number of pre-built virtual machines increasing, plus it's the best price... free (however if you want to run this outside of a lab environment, I would strongly recommend joining the Oracle Premier Support program).
Good job Oracle.
Recently however, I am finding less and less time to install guest linux OS, configuring it for use with an Oracle Database (or Application Server), making sure all the RPM's, kernel values are correct etc. Yes you can use the Oracle Validated Packages to help simplify this (see Tims comments below for how to obtain these) but what I really value these days is the simplest configuration for home / home office use that is pretty much turn on and play.
After a quick trawl of the Virtual Appliances section of the VM Market Place, I was left wanting until I remembered that Oracle were now dabbling in the Virtual Machine space. After a quick dl of VirtualBox (their virtualisation offering) and a pre-built development database, I was up an running within 30 mins. Firthermore I have it running on 2G of memory and 1 CPU locally on my MacBook Pro.
I must say I was very impressed with the build of the VM itself, the interface of VirtualBox and just how simple it was to get a "throw away" vm running that covers 99% of my day to day needs.
I have to admit, I am struggling to justify moving back to a costed option of VMWare and can only see the number of pre-built virtual machines increasing, plus it's the best price... free (however if you want to run this outside of a lab environment, I would strongly recommend joining the Oracle Premier Support program).
Good job Oracle.
Oracle, APEX and Longevity!
I have just read the latest Statement of Direction from Oracle (download here) and there are some comforting statements from Oracle about there long term commitment to Application Express.
For those like me who have been using APEX since the early days, this is good news as it represents a very clear intent that Oracle are very serious about APEX as key development framework.
Nice read!
Cheers Oracle.
For those like me who have been using APEX since the early days, this is good news as it represents a very clear intent that Oracle are very serious about APEX as key development framework.
Nice read!
Cheers Oracle.
We're Hiring
We are looking for an APEX developer for an initial 3 month contract with definite scope for long term extension for a role in Hampshire (UK).
Candidates must be SC cleared or willing to undergo clearance to work on a UK MoD site.
Any interested parties, please send me an up to date copy of your CV with availability and rate to: duncanmein@gmail.com
Candidates must be SC cleared or willing to undergo clearance to work on a UK MoD site.
Any interested parties, please send me an up to date copy of your CV with availability and rate to: duncanmein@gmail.com
Native String Aggregation in 11gR2
A fairly recent requirement meant that we had to send a bulk email to all users of each department from within our APEX application. We have 5000 records in our users table and the last thing we wanted to do was send 5000 distinct emails (one email per user) for both performance and to be kind on the mail queue / server.
In essence, I wanted to to perform a type of string aggregation where I could group by department and produce a comma delimited sting of all email address of users within that department. With a firm understanding of the requirement, so began the hunt for a solution. Depending on what version of the database you are running, the desired result can be achieved in a couple of ways.
Firstly, the example objects.
If you are using 11gR2, you can expose the new LISTAGG function as follows to perform your string aggregation natively:
If running 11g or earlier, you can achieve the same result using XMLAGG as follows:
The introduction of native string aggregation into 11gR2 is a real bonus and a function that has already proved to have had huge utility within our applications.
In essence, I wanted to to perform a type of string aggregation where I could group by department and produce a comma delimited sting of all email address of users within that department. With a firm understanding of the requirement, so began the hunt for a solution. Depending on what version of the database you are running, the desired result can be achieved in a couple of ways.
Firstly, the example objects.
CREATE TABLE app_user
(id NUMBER
,dept VARCHAR2 (255)
,username VARCHAR2(255)
,email VARCHAR2(255)
);
INSERT INTO app_user (id, dept, username, email)
VALUES (1,'IT','FRED','fred@mycompany.com');
INSERT INTO app_user (id, dept, username, email)
VALUES (2,'IT','JOE','joe@mycompany.com');
INSERT INTO app_user (id, dept, username, email)
VALUES (3,'SALES','GILL','gill@mycompany.com');
INSERT INTO app_user (id, dept, username, email)
VALUES (4,'HR','EMILY','emily@mycompany.com');
INSERT INTO app_user (id, dept, username, email)
VALUES (5,'HR','BILL','bill@mycompany.com');
INSERT INTO app_user (id, dept, username, email)
VALUES (6,'HR','GUS','gus@mycompany.com');
COMMIT;
If you are using 11gR2, you can expose the new LISTAGG function as follows to perform your string aggregation natively:
SELECT dept
,LISTAGG(email,',') WITHIN GROUP (ORDER BY dept) email_list
FROM app_user
GROUP BY dept;
DEPT EMAIL_LIST
-----------------------------------------------------------------
HR emily@mycompany.com,bill@mycompany.com,gus@mycompany.com
IT fred@mycompany.com,joe@mycompany.com
SALES gill@mycompany.com
If running 11g or earlier, you can achieve the same result using XMLAGG as follows:
SELECT au.dept
,LTRIM
(EXTRACT
(XMLAGG
(XMLELEMENT
("EMAIL",',' || email)),'/EMAIL/text()'), ','
) email_list
FROM app_user au
GROUP BY au.dept;
DEPT EMAIL_LIST
-----------------------------------------------------------------
HR emily@mycompany.com,bill@mycompany.com,gus@mycompany.com
IT fred@mycompany.com,joe@mycompany.com
SALES gill@mycompany.com
The introduction of native string aggregation into 11gR2 is a real bonus and a function that has already proved to have had huge utility within our applications.
A Right Pig's Ear of a Circular Reference
If you have ever used a self referencing table within Oracle to store hierarchical data (e.g. an organisations structure), you will have undoubtedly used CONNECT BY PRIOR to build your results tree. This is something we use on pretty much every project as the organisation is very hierarchy based.
Recently, the support cell sent the details of a recent call they received asking me to take a look. Looking down the call, I noticed that the following Oracle Error Message was logged:
"ORA-01436: CONNECT BY loop in user data"
A quick look at the explanation of -01436 and it was clear that there was a circular reference in the organisation table i.e. ORG_UNIT1 was the PARENT of ORG_UNIT2 and ORG_UNIT2 was the PARENT of ORG_UNIT1. In this example, both ORG_UNITS were the child and parent of each other. Clearly this was an issue which was quickly resolved by the addition of a application and server side validation to prevent this from re-occurring.
The outcome of this fix was a useful script that I keep to identify if there are any circular references within a self referencing table. The example below shows this script in action:
A quick tree walk query shows the visual representation of the hierarchy with no errors:
Now lets create a circular reference so that EUROPE is the parent of SALES:
Re-running the query from the very top of the tree completes but gives an incorrect
and incomplete result set:
If you running Oracle Database 9i and backwards, this Experts Exchange article provides a nice procedural solution and a quick mod to the PL/SQL gave me exactly the information I needed:
Any value > 0 in the ERR column indicates that the row is involved in a self referencing join. This is a much neater and more performant way to achieve to desired result. Thanks to Buzz for pointing out a much better way to original PL/SQL routine.
Recently, the support cell sent the details of a recent call they received asking me to take a look. Looking down the call, I noticed that the following Oracle Error Message was logged:
"ORA-01436: CONNECT BY loop in user data"
A quick look at the explanation of -01436 and it was clear that there was a circular reference in the organisation table i.e. ORG_UNIT1 was the PARENT of ORG_UNIT2 and ORG_UNIT2 was the PARENT of ORG_UNIT1. In this example, both ORG_UNITS were the child and parent of each other. Clearly this was an issue which was quickly resolved by the addition of a application and server side validation to prevent this from re-occurring.
The outcome of this fix was a useful script that I keep to identify if there are any circular references within a self referencing table. The example below shows this script in action:
CREATE TABLE ORGANISATIONS (ORG_ID NUMBER
, PARENT_ORG_ID NUMBER
, NAME VARCHAR2(100));
INSERT INTO ORGANISATIONS VALUES (1, NULL, 'HQ');
INSERT INTO ORGANISATIONS VALUES (2, 1, 'SALES');
INSERT INTO ORGANISATIONS VALUES (3, 1, 'RESEARCH');
INSERT INTO ORGANISATIONS VALUES (4, 1, 'IT');
INSERT INTO ORGANISATIONS VALUES (5, 2, 'EUROPE');
INSERT INTO ORGANISATIONS VALUES (6, 2, 'ASIA');
INSERT INTO ORGANISATIONS VALUES (7, 2, 'AMERICAS');
COMMIT;
A quick tree walk query shows the visual representation of the hierarchy with no errors:
SELECT LPAD ('*', LEVEL, '*') || name tree
,LEVEL lev
FROM organisations
START WITH org_id = 1
CONNECT BY PRIOR org_id = parent_org_id;
TREE LEV
---------------------
*HQ 1
**SALES 2
***EUROPE 3
***ASIA 3
***AMERICAS 3
**RESEARCH 2
**IT 2Now lets create a circular reference so that EUROPE is the parent of SALES:
UPDATE ORGANISATIONS SET parent_org_id = 5 WHERE NAME = 'SALES';
COMMIT;
Re-running the query from the very top of the tree completes but gives an incorrect
and incomplete result set:
TREE LEV
---------------------
*HQ 1
**RESEARCH 2
**IT 2
If you running Oracle Database 9i and backwards, this Experts Exchange article provides a nice procedural solution and a quick mod to the PL/SQL gave me exactly the information I needed:
SET serveroutput on size 20000As Buzz Killington pointed out in the comments section, Oracle Database 10g onwards introduces CONNECT BY NOCYCLE which will instruct Oracle to return rows even if it is involved in a self referencing loop. When used with the CONNECT_BY_ISCYCLE pseudocolumn, you can easily identify erroneous relationships via SQL without the need to switch to PL/SQL. An example of this can be seen by executing the following query:
DECLARE
l_n NUMBER;
BEGIN
FOR rec IN (SELECT org_id FROM organisations)
LOOP
BEGIN
SELECT COUNT ( * )
INTO l_n
FROM ( SELECT LPAD ('*', LEVEL, '*') || name tree
, LEVEL lev
FROM organisations
START WITH org_id = rec.org_id
CONNECT BY PRIOR org_id = parent_org_id);
EXCEPTION
WHEN OTHERS
THEN
IF SQLCODE = -1436
THEN
DBMS_OUTPUT.put_line
(
rec.org_id
|| ' is part of a Circular Reference'
);
END IF;
END;
END LOOP;
END;
/
WITH
my_data
AS
( SELECT ORG.PARENT_ORG_ID
,ORG.ORG_ID
,ORG.NAME org_name
FROM organisations org
)
SELECT
SYS_CONNECT_BY_PATH (org_name,'/') tree
,PARENT_ORG_ID
,ORG_ID
,CONNECT_BY_ISCYCLE err
FROM
my_data
CONNECT BY NOCYCLE PRIOR org_id = parent_org_id
ORDER BY 4 desc;
TREE PARENT_ORG_ID ORG_ID ERR
------------------------------------------------
/SALES/EUROPE 2 5 1
/EUROPE/SALES 5 2 1
/EUROPE 2 5 0
/EUROPE/SALES/ASIA 2 6 0
/EUROPE/SALES/AMERICAS 2 7 0
/ASIA 2 6 0
/AMERICAS 2 7 0
/SALES 5 2 0
/SALES/ASIA 2 6 0
/SALES/AMERICAS 2 7 0
/HQ 1 0
/HQ/RESEARCH 1 3 0
/HQ/IT 1 4 0
/RESEARCH 1 3 0
/IT 1 4 0
Any value > 0 in the ERR column indicates that the row is involved in a self referencing join. This is a much neater and more performant way to achieve to desired result. Thanks to Buzz for pointing out a much better way to original PL/SQL routine.
Pen Test Tool for APEX
Just a quick plug for a cool Penetration Test tool that we have been using on-site for a few months now. The application is called: Application Express Security Console and developed by a company called Recx Ltd
This can be used to identify areas of you APEX applications that are vulnerable to:
SQL Injection, XSS as well as inadequate access control etc. It kindly suggests ways in which the vulnerability can be addressed as well.
We have built the use of this into our formal release process now and has definitely proved value for money to organisation.
This can be used to identify areas of you APEX applications that are vulnerable to:
SQL Injection, XSS as well as inadequate access control etc. It kindly suggests ways in which the vulnerability can be addressed as well.
We have built the use of this into our formal release process now and has definitely proved value for money to organisation.
Beware of the Byte
Recently our test department raised a bug against one our applications that occurred when trying to insert a record into a table.
The error message encountered was a fairly innocuous "ORA-01704: string literal too long".
Following the test case to the letter, I successfully generated the same error and located the table that the APEX form was inserting into. A quick check of the Data Dictionary confirmed that the column in question was of type VARCHAR2(10). At this stage, I though the obvious cause was that there was no limit on the APEX form item (a Text Area) of 10 characters. Having checked the item in question, not only was there a “maxWidth” value of 10, the text area had been created with a “Character Counter”. Strange then how a form item accepting 10 characters was erroring whilst inserting into a column of VARCHAR2(10).
A little while later...... (after some head scratching and several discussions with our DBA’s and a colleague) the problem was all too clear. Somewhere between Database Character Sets, VARCHAR2 column definitions and non ASCII characters lay the answer.
Please forgive the rather verbose narrative but allow me to delve a little deeper.
Firstly the facts:
1. The character set of our database is set to AL32UTF8
2. Definition of table causing the error:
3. SQL Statement causing the error:
INSERT INTO nls_test VALUES ('““““““““““');
NB: 10 individual characters.
The character used in this insert is typical of a double quote produced by MS Word (it was in fact a copy and paste from a Word document into our Text Area that caused our error).
Explanation
The reason we encountered the error was all to do with the attempt to insert a 'Multi Byte' character (a double quote from word in our case) into our table as opposed to typical single byte characters (A-Z, 0-9 etc).
Performing a simple LENGTHB to return the number of bytes this character uses demonstrated this perfectly:
Because our column definition is of type VARCHAR2(10 BYTE), we are only permitted to store values that do not exceed 10 bytes in length.
Beware, 1 character in our case definitely does not = 1 byte. As already proved, our single character (a Word double quote) occupies 3 bytes so the maximum number of this Multi Byte Character we could possible insert according to our table definition is worked out simply as:
10 bytes (Column Definition) / 3 (length in bytes of our character) = 3
So whilst the APEX form item does not distinguish between single and multi byte characters and will allow you to input the full 10 characters, Oracle Database will bounce it back in our case as the total bytes in our string is 30 hence the error.
One solution suggested was to alter the Data Type to be of type VARCHAR2(10 CHAR) instead of BYTE. This in theory would force the database to respect the actual number of characters entered and not worry too much about single vs. multi byte occupancy. This would allow us resolve our immediate issue of 10 multi byte characters inserting into our table however there are further considerations.
As it turns out, even when you define your columns to use CHAR over BYTE, Oracle still enforces a hard limit of up to 4000 BYTES (given a mixed string of single and multi byte characters, it implicitly works out the total bytes of the string).
So beware that even if your column for example accepts only 3000 CHAR and you supply 2001 multi byte characters in an insert statement, it may still fail as it will convert your sting into BYTES enforcing an upper limit of 4000 BYTES.
Sorry for the really long post but it was a much for my own documentation as anything else.
The error message encountered was a fairly innocuous "ORA-01704: string literal too long".
Following the test case to the letter, I successfully generated the same error and located the table that the APEX form was inserting into. A quick check of the Data Dictionary confirmed that the column in question was of type VARCHAR2(10). At this stage, I though the obvious cause was that there was no limit on the APEX form item (a Text Area) of 10 characters. Having checked the item in question, not only was there a “maxWidth” value of 10, the text area had been created with a “Character Counter”. Strange then how a form item accepting 10 characters was erroring whilst inserting into a column of VARCHAR2(10).
A little while later...... (after some head scratching and several discussions with our DBA’s and a colleague) the problem was all too clear. Somewhere between Database Character Sets, VARCHAR2 column definitions and non ASCII characters lay the answer.
Please forgive the rather verbose narrative but allow me to delve a little deeper.
Firstly the facts:
1. The character set of our database is set to AL32UTF8
SELECT VALUE
FROM v$nls_parameters
WHERE parameter = 'NLS_CHARACTERSET';
2. Definition of table causing the error:
CREATE TABLE nls_test
(
col1 VARCHAR2(10 BYTE)
);
3. SQL Statement causing the error:
INSERT INTO nls_test VALUES ('““““““““““');
NB: 10 individual characters.
The character used in this insert is typical of a double quote produced by MS Word (it was in fact a copy and paste from a Word document into our Text Area that caused our error).
Explanation
The reason we encountered the error was all to do with the attempt to insert a 'Multi Byte' character (a double quote from word in our case) into our table as opposed to typical single byte characters (A-Z, 0-9 etc).
Performing a simple LENGTHB to return the number of bytes this character uses demonstrated this perfectly:
SELECT lengthb('“') from dual;
LENGTHB('“')
------------
3
Because our column definition is of type VARCHAR2(10 BYTE), we are only permitted to store values that do not exceed 10 bytes in length.
Beware, 1 character in our case definitely does not = 1 byte. As already proved, our single character (a Word double quote) occupies 3 bytes so the maximum number of this Multi Byte Character we could possible insert according to our table definition is worked out simply as:
10 bytes (Column Definition) / 3 (length in bytes of our character) = 3
So whilst the APEX form item does not distinguish between single and multi byte characters and will allow you to input the full 10 characters, Oracle Database will bounce it back in our case as the total bytes in our string is 30 hence the error.
One solution suggested was to alter the Data Type to be of type VARCHAR2(10 CHAR) instead of BYTE. This in theory would force the database to respect the actual number of characters entered and not worry too much about single vs. multi byte occupancy. This would allow us resolve our immediate issue of 10 multi byte characters inserting into our table however there are further considerations.
As it turns out, even when you define your columns to use CHAR over BYTE, Oracle still enforces a hard limit of up to 4000 BYTES (given a mixed string of single and multi byte characters, it implicitly works out the total bytes of the string).
So beware that even if your column for example accepts only 3000 CHAR and you supply 2001 multi byte characters in an insert statement, it may still fail as it will convert your sting into BYTES enforcing an upper limit of 4000 BYTES.
Sorry for the really long post but it was a much for my own documentation as anything else.
APEX - Identify Report Columns Vulnerable to XSS
The following query is a very simple way of identifying all report columns within your APEX application that may be exposed by Cross Site Scripting (XSS).
XSS allows an attacker to inject web script (JavaScript) into an application and when this is rendered in the report, the script is interpreted rather than rendered as text.
To safe guard against this attack, APEX provides a "Display as Text (escape special characters)" report column attribute that can be applied to classic and Interactive Reports. This causes the script text to be displayed as text rather than interpreted by the browser. If you have any markup (HTML) within your query that the report is based on, this markup will also be displayed as text and not interpreted. I personally think this is a good by product as you should not really be coding look and feel into your raw SQL.
Anyway I digress. Here is the query that will identify all vulnerable report columns within your APEX application:
Enjoy
XSS allows an attacker to inject web script (JavaScript) into an application and when this is rendered in the report, the script is interpreted rather than rendered as text.
To safe guard against this attack, APEX provides a "Display as Text (escape special characters)" report column attribute that can be applied to classic and Interactive Reports. This causes the script text to be displayed as text rather than interpreted by the browser. If you have any markup (HTML) within your query that the report is based on, this markup will also be displayed as text and not interpreted. I personally think this is a good by product as you should not really be coding look and feel into your raw SQL.
Anyway I digress. Here is the query that will identify all vulnerable report columns within your APEX application:
SELECT application_id,
application_name,
page_id,
region_name,
column_alias,
display_as
FROM apex_application_page_rpt_cols
WHERE display_as NOT IN
('Display as Text (escape special characters, does not save state)',
'CHECKBOX',
'Hidden',
'Text Field')
AND workspace != 'INTERNAL'
AND application_id = :APP_ID
ORDER BY 1, 2, 3;
Enjoy
Oracle SQL Developer on OS X Snow Leopard
I have been using Oracle SQL Developer Data Modeller for a while now within a Windows XP environment. It seems pretty good (albeit a little slow but hey show some an Oracle Java client application that is quick. Oracle Directory Manager?, OWB Design Centre? I shall labour this point no more) and I was looking forward to trying it out on my new 27" iMac.
I promptley downloaded the software from OTN and a quick read of the instructions suggested I need to do no more other than run the datamodeler.sh shell script since I already had Java SE 6 installed.
As it turns out, the datamodeler.sh script in the root location does little more than call another script called datamodeler.sh found in the /datamodeler/bin directory which is the once you actually need to execute to fire up SQL Data Modeler
When this script runs, it prompts you for a the full J2SE file path (which I had no idea where it was) before it will run. After a quick look around google and I came across the command: java_home which when executed like:
cd /usr/libexec
./java_home
prints the full path value that you need to open SQL Data Modeler
e.g. /System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home
Now we are armed with the full path needed, opening up SQL Data Modeller from a virgin command window goes like this:
cd Desktop/datamodeler/bin
. ./datamodeler.sh
Oracle SQL Developer Data Modeler
Copyright (c) 1997, 2009, Oracle and/or its affiliates.All rights reserved.
Type the full pathname of a J2SE installation (or Ctrl-C to quit), the path will be stored in ~/jdk.conf
/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home
and hey presto, SQL Data Modeller is up and running.
Once you have pointed the shell script at your J2SE installation, you wont have to do it again.
Now I can finally use Data Modeler on my 27" Screen :)
I promptley downloaded the software from OTN and a quick read of the instructions suggested I need to do no more other than run the datamodeler.sh shell script since I already had Java SE 6 installed.
As it turns out, the datamodeler.sh script in the root location does little more than call another script called datamodeler.sh found in the /datamodeler/bin directory which is the once you actually need to execute to fire up SQL Data Modeler
When this script runs, it prompts you for a the full J2SE file path (which I had no idea where it was) before it will run. After a quick look around google and I came across the command: java_home which when executed like:
cd /usr/libexec
./java_home
prints the full path value that you need to open SQL Data Modeler
e.g. /System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home
Now we are armed with the full path needed, opening up SQL Data Modeller from a virgin command window goes like this:
cd Desktop/datamodeler/bin
. ./datamodeler.sh
Oracle SQL Developer Data Modeler
Copyright (c) 1997, 2009, Oracle and/or its affiliates.All rights reserved.
Type the full pathname of a J2SE installation (or Ctrl-C to quit), the path will be stored in ~/jdk.conf
/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home
and hey presto, SQL Data Modeller is up and running.
Once you have pointed the shell script at your J2SE installation, you wont have to do it again.
Now I can finally use Data Modeler on my 27" Screen :)
Generate Days in Month (PIPELINED Functions)
This cool example is not one I can take the credit for but since it is used pretty heavily in our organisation, I thought I would share it as it's not only pretty cool buy also demonstrates how useful Oracle Pipelined functions can be.
In essence a Pipeline table function (introduced in 9i) allow you use a PL/SQL function as the source of a query rather than a physical table. This is really useful in our case to generate all the days in a calendar month via PL/SQL and query them back within our application.
To see this in operation, simply create the following objects:
Once your objects are successfully complied, you can generate all the days in a month by executing the following query:
I hope someone finds this example as useful as we do. The credits go to Simon Hunt on this one as it was "borrowed" from one of his apps. Since I offered to buy him a beer he has promised not to make too big a deal out it :)
As always, you can read up on this topic here
In essence a Pipeline table function (introduced in 9i) allow you use a PL/SQL function as the source of a query rather than a physical table. This is really useful in our case to generate all the days in a calendar month via PL/SQL and query them back within our application.
To see this in operation, simply create the following objects:
CREATE OR REPLACE TYPE TABLE_OF_DATES IS TABLE OF DATE;
CREATE OR REPLACE FUNCTION GET_DAYS_IN_MONTH
(
pv_start_date_i IN DATE
)
RETURN TABLE_OF_DATES PIPELINED
IS
lv_working_date DATE;
lv_days_in_month NUMBER;
lv_cnt NUMBER;
BEGIN
lv_working_date := TO_DATE(TO_CHAR(pv_start_date_i, 'RRRRMM') || '01', 'RRRRMMDD');
lv_days_in_month := TRUNC(LAST_DAY(lv_working_date)) - TRUNC(lv_working_date);
PIPE ROW(lv_working_date);
FOR lv_cnt IN 1..lv_days_in_month
LOOP
lv_working_date := lv_working_date + 1;
PIPE ROW (lv_working_date);
END LOOP;
RETURN;
END GET_DAYS_IN_MONTH;
/
Once your objects are successfully complied, you can generate all the days in a month by executing the following query:
SELECT column_value the_date
, TO_CHAR(column_value, 'DAY') the_day
FROM TABLE (get_days_in_month(sysdate));
THE_DATE THE_DAY
------------------------
01-AUG-09 SATURDAY
02-AUG-09 SUNDAY
03-AUG-09 MONDAY
04-AUG-09 TUESDAY
05-AUG-09 WEDNESDAY
06-AUG-09 THURSDAY
07-AUG-09 FRIDAY
08-AUG-09 SATURDAY
09-AUG-09 SUNDAY
10-AUG-09 MONDAY
11-AUG-09 TUESDAY
12-AUG-09 WEDNESDAY
13-AUG-09 THURSDAY
14-AUG-09 FRIDAY
15-AUG-09 SATURDAY
16-AUG-09 SUNDAY
17-AUG-09 MONDAY
18-AUG-09 TUESDAY
19-AUG-09 WEDNESDAY
20-AUG-09 THURSDAY
21-AUG-09 FRIDAY
22-AUG-09 SATURDAY
23-AUG-09 SUNDAY
24-AUG-09 MONDAY
25-AUG-09 TUESDAY
26-AUG-09 WEDNESDAY
27-AUG-09 THURSDAY
28-AUG-09 FRIDAY
29-AUG-09 SATURDAY
30-AUG-09 SUNDAY
31-AUG-09 MONDAY
I hope someone finds this example as useful as we do. The credits go to Simon Hunt on this one as it was "borrowed" from one of his apps. Since I offered to buy him a beer he has promised not to make too big a deal out it :)
As always, you can read up on this topic here
VMWare ESXi Hypervisor
Server virtualisation is something I have been using for a few years now both at work and at home. I mainly use VMWare Fusion on my MacBook Pro and VMWare Workstation / Player on an old Windows Laptop. For everyday tasks these products are amazing as i can run an XP VM on my MacBook Pro for all those times I need to open MS Project or run TOAD.
On my server at home, I didn't want to install a host OS and then install VMWare Workstation / Server to host several Linux VM's. Instead I explored the option of a "Bare Metal" hypervisor from VMWare (ESXi 3.5 Update 3). A hypervisor is a very small linux kernel that runs natively against your servers hardware without the burden of having to install a host OS. From here you can create and manage all your VM's remotely using the VMWare Client tool.
For more information in ESXi, check out VMWare's website here
Reading the documentation suggested that ESXi was very particular about the hardware it supports and so began the quest to build a "White Box" ESXi server at home. Whilst this is not supported by VMWare, I wanted to share the process and components utilised in case anyone else was thinking of building there own ESXi Server.
Step 1. Download the ESXi 3.5 ISO from the VMWare Website (You will need to register for an account)
Step 3. Create a Bootable USB Stick (yes you can boot the Hypervisor from a USB stick if your Motherboard supports it) by following this concise guide
Step 3. Plug your USB stick into your server and configure the IP Address, DNS Server, Hostname and Gateway.
Step 4. Open a Browser window on a client machine and navigate to: http://ip address to download the VMWare Client tool.
Step 5. Enjoy using ESXi
My Server Configuration:
CPU: Inter Core i7 920
MOBO: Gigabyte GA-EX58-UD5
Memory: 12GB of Corsair DDR3 XMS3 INTEL I7 PC10666 1333MHZ (3X2GB)
SATA Controller: Sweex PU102
NIC: 3Com 3c90x
The following sites list loads of compatible hardware with notes and issues encountered:
http://ultimatewhitebox.com/index.php
http://www.vm-help.com/esx/esx3.5/Whiteboxes_SATA_Controllers_for_ESX_3.5_3i.htm
With the setup outlined above, I can run 5 Linux machines running Oracle Database, Application Server, APEX and OBIEE without any issue.
If this is something you are interested in evaluating, i can recommend spending a few hundred pounds on the components as its beats spending thousands on a supported Server from HP.
On my server at home, I didn't want to install a host OS and then install VMWare Workstation / Server to host several Linux VM's. Instead I explored the option of a "Bare Metal" hypervisor from VMWare (ESXi 3.5 Update 3). A hypervisor is a very small linux kernel that runs natively against your servers hardware without the burden of having to install a host OS. From here you can create and manage all your VM's remotely using the VMWare Client tool.
For more information in ESXi, check out VMWare's website here
Reading the documentation suggested that ESXi was very particular about the hardware it supports and so began the quest to build a "White Box" ESXi server at home. Whilst this is not supported by VMWare, I wanted to share the process and components utilised in case anyone else was thinking of building there own ESXi Server.
Step 1. Download the ESXi 3.5 ISO from the VMWare Website (You will need to register for an account)
Step 3. Create a Bootable USB Stick (yes you can boot the Hypervisor from a USB stick if your Motherboard supports it) by following this concise guide
Step 3. Plug your USB stick into your server and configure the IP Address, DNS Server, Hostname and Gateway.
Step 4. Open a Browser window on a client machine and navigate to: http://ip address to download the VMWare Client tool.
Step 5. Enjoy using ESXi
My Server Configuration:
CPU: Inter Core i7 920
MOBO: Gigabyte GA-EX58-UD5
Memory: 12GB of Corsair DDR3 XMS3 INTEL I7 PC10666 1333MHZ (3X2GB)
SATA Controller: Sweex PU102
NIC: 3Com 3c90x
The following sites list loads of compatible hardware with notes and issues encountered:
http://ultimatewhitebox.com/index.php
http://www.vm-help.com/esx/esx3.5/Whiteboxes_SATA_Controllers_for_ESX_3.5_3i.htm
With the setup outlined above, I can run 5 Linux machines running Oracle Database, Application Server, APEX and OBIEE without any issue.
If this is something you are interested in evaluating, i can recommend spending a few hundred pounds on the components as its beats spending thousands on a supported Server from HP.
Sum to Parent Nodes in Hierarchy Queries: CONNECT_BY_ROOT
In one of our Applicaitons, the table DEPT contains a self referncing join (Pigs Ear) as it models our organsational department hierarchy.
For example:
We had a requirment to work out the total number of employees at each parent level in the Organisational Hierarchy. For example, the report sum up all employees in the parent node and all its children.
Taking the department TEST as an example, the report should sum the figures 25 (employees in the TEST department), 3 and 5 (employees in the Functional / Non Functional child departments) to give a figure of 33.
This can easily be achieved by using CONNECT_BY_ROOT. Straight from the Oracle Documentation:
"CONNECT_BY_ROOT is a unary operator that is valid only in hierarchical queries. When you qualify a column with this operator, Oracle returns the column value using data from the root row. This operator extends the functionality of the CONNECT BY [PRIOR] condition of hierarchical queries.
Restriction on CONNECT_BY_ROOT You cannot specify this operator in the START WITH condition or the CONNECT BY condition."
To meet our requirement, CONNECT_BY_ROOT was utilised as follows:
For example:
A quick tree walk using CONNECT BY PRIOR shows you the Parent / Child relationships between all departments and the number of employees in each department:
CREATE TABLE DEPT
(
DEPT_ID NUMBER NOT NULL
,PARENT_ID NUMBER
,DEPT_NAME VARCHAR2 (100) NOT NULL
,EMPLOYEES NUMBER NOT NULL
,CONSTRAINT DEPT_PK PRIMARY KEY (DEPT_ID)
,CONSTRAINT DEPT_FK01 FOREIGN KEY (PARENT_ID)
REFERENCES DEPT (DEPT_ID)
);
INSERT INTO DEPT VALUES (1,NULL,'IT', 100);
INSERT INTO DEPT VALUES (2,1,'DEVELOPMENT', 12);
INSERT INTO DEPT VALUES (3,1,'SUPPORT', 15);
INSERT INTO DEPT VALUES (4,1,'TEST', 25);
INSERT INTO DEPT VALUES (5,2,'PL/SQL', 2);
INSERT INTO DEPT VALUES (6,2,'Java', 1);
INSERT INTO DEPT VALUES (7,2,'SQL', 11);
INSERT INTO DEPT VALUES (8,2,'C++', 3);
INSERT INTO DEPT VALUES (9,4,'Functional', 3);
INSERT INTO DEPT VALUES (10,4,'Non Functional', 5);
COMMIT;
SELECT rpad( ' ', 1*level, ' ' ) || dept_name dept_name
,employees
FROM dept
START WITH parent_id is null
CONNECT BY PRIOR dept_id = parent_id;
DEPT_NAME EMPLOYEES
-------------------- ----------
IT 100
DEVELOPMENT 12
PL/SQL 2
Java 1
SQL 11
C++ 3
SUPPORT 15
TEST 25
Functional 3
Non Functional 5
We had a requirment to work out the total number of employees at each parent level in the Organisational Hierarchy. For example, the report sum up all employees in the parent node and all its children.
Taking the department TEST as an example, the report should sum the figures 25 (employees in the TEST department), 3 and 5 (employees in the Functional / Non Functional child departments) to give a figure of 33.
This can easily be achieved by using CONNECT_BY_ROOT. Straight from the Oracle Documentation:
"CONNECT_BY_ROOT is a unary operator that is valid only in hierarchical queries. When you qualify a column with this operator, Oracle returns the column value using data from the root row. This operator extends the functionality of the CONNECT BY [PRIOR] condition of hierarchical queries.
Restriction on CONNECT_BY_ROOT You cannot specify this operator in the START WITH condition or the CONNECT BY condition."
To meet our requirement, CONNECT_BY_ROOT was utilised as follows:
select dept_name, employees, tot_employees
from (select
employees,
dept_name,
level lev,
sum(employees) over(partition by connect_by_root
(dept_id)
) tot_employees
from dept
connect by prior dept_id = parent_id)
where lev=1;
DEPT_NAME EMPLOYEES TOT_EMPLOYEES
-------------------- ---------- -------------
IT 100 177
DEVELOPMENT 12 29
SUPPORT 15 15
TEST 25 33
PL/SQL 2 2
Java 1 1
SQL 11 11
C++ 3 3
Functional 3 3
Non Functional 5 5
Check All / Uncheck All Checkbox
There is a really cool JavaScript function in Apex called: $f_CheckFirstColumn that allows you to Check / Uncheck all checkboxes that exist in the 1st column position of a Tabular Form / Report.
To implement this, all you need do is add the following HTML to the Column Heading of the 1st Column in your Tabular Form (i.e. the Checkbox Column):
<input type="Checkbox" onclick="$f_CheckFirstColumn(this)">
Check out an example here
To implement this, all you need do is add the following HTML to the Column Heading of the 1st Column in your Tabular Form (i.e. the Checkbox Column):
<input type="Checkbox" onclick="$f_CheckFirstColumn(this)">
Check out an example here
Web Cache Compression and MOD_GZIP
Some of my colleagues are working on a project where bandwidth is massively limited (64k). One suggestion to increase application response time was to use MOD_GZIP (an open source compressor extension to Apache) to compress the outbound HTTP traffic. The only drawback is that MOD_GZIP is not supported by Oracle.
Since we are using Oracle Application Server, Web Cache achieves exactly the same by simply adding a compression rule to Web Cache for the URL Regular Expression /pls/apex/.*$
We noticed that without any compression of the HTTP outbound traffic, our test page took 30 seconds to fully render on a 64k link. Turning on compression reduced the rendering time to 7 seconds. Very impressive.
Navigating through an application with compression turned on was noticeably quicker than one without compression.
To test if your outbound HTTP traffic is compressed, I would grab the Live HTTP Headers extension to Firefox and you are looking for a line like: Content-Encoding: gzip in the outbound response.
I configured both APEX and Discoverer Viewer to use compression by following the metalink article: 452837.1
Since we are using Oracle Application Server, Web Cache achieves exactly the same by simply adding a compression rule to Web Cache for the URL Regular Expression /pls/apex/.*$
We noticed that without any compression of the HTTP outbound traffic, our test page took 30 seconds to fully render on a 64k link. Turning on compression reduced the rendering time to 7 seconds. Very impressive.
Navigating through an application with compression turned on was noticeably quicker than one without compression.
To test if your outbound HTTP traffic is compressed, I would grab the Live HTTP Headers extension to Firefox and you are looking for a line like: Content-Encoding: gzip in the outbound response.
I configured both APEX and Discoverer Viewer to use compression by following the metalink article: 452837.1
Reset the APEX internal password
I noticed in one of the comments of Dimitri Gielis articles that Jornica pointed out a script called apxXEpwd.sql
I ran this as the SYS user and sure enough, it allows you to reset the ADMIN password for the internal workspace.
This script can be found in the root apex directory that you download from OTN.
Very useful when you forget what that password is!
I ran this as the SYS user and sure enough, it allows you to reset the ADMIN password for the internal workspace.
This script can be found in the root apex directory that you download from OTN.
Very useful when you forget what that password is!
Import APEX application via SQL Developer
I will be honest and admit that I have not been SQL Developers biggest fan since it's release a few years ago. Having always used 3rd party products such as TOAD and PL/SQL Developer, I found certain things a little irritating and not overwhelmingly obvious when forced to use SQL Developer.
Recently however, I found an absolute god send of a feature in SQL Developer and that was the ability to import / export APEX applications. This means that the Web GUI for such actions is no longer required.
Very simply, you connect to your parsing schema's database account via SQL Developer, right click on the Application Express tree directory and select Import Application. This opens a simple wizard and off you go.
One other cool feature of this is that you can open the details window and see exactly what your import is doing, something that is not possible when using the web GUI.
Download SQL Developer from: OTN
Recently however, I found an absolute god send of a feature in SQL Developer and that was the ability to import / export APEX applications. This means that the Web GUI for such actions is no longer required.
Very simply, you connect to your parsing schema's database account via SQL Developer, right click on the Application Express tree directory and select Import Application. This opens a simple wizard and off you go.
One other cool feature of this is that you can open the details window and see exactly what your import is doing, something that is not possible when using the web GUI.
Download SQL Developer from: OTN
APEX 3.1.1 Released
Just upgraded from APEX 3.1 to 3.1.1 on an Oracle Enterpise Linux 4 Update 4 platform.
Intall took: 5:39 and termintaed without error.
The patch can be downloaded from metalink (patch number 7032837)
All in all, a very simple upgrade and now onto the task of regression testing our current 3.1 apps
Intall took: 5:39 and termintaed without error.
The patch can be downloaded from metalink (patch number 7032837)
All in all, a very simple upgrade and now onto the task of regression testing our current 3.1 apps
Hide Show Regions on an Apex Page
One of the really nice features of APEX is the ability to hide / show regions when editing item or page attributes. This is really useful if you have to update the same attribute for multiple items.
If you want to implement this type of approach on a page you simply need to:
Create a New Region Template
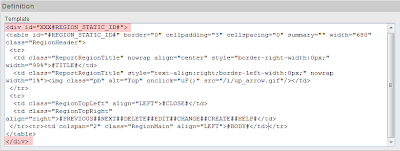
Either create a new region template (or copy an existing one) and add a DIV tag with the id="XXX#REGION_STATIC_ID#" around the Definition Template.
Don’t forget to close the DIV at the end of the template. In this example I copied our region called “Reports Region” and named it “Reports Region 680 Width (Static ID)”
Add the following JavaScript to your Page Header: view
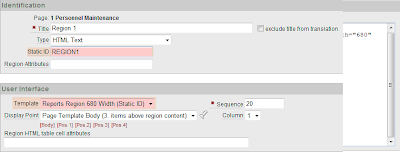
Create several regions on your page and assign a unique Static ID i.e. REGION1, REGION2 etc. Set the Region Template to the one you created in the 1.
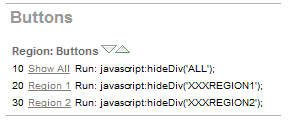
Create a button for each Region you defined in the previous stage and add the following JavaScript call as the URL target of each button:
javascript:hideDiv(‘XXXREGION1’); // For the button called Region 1
javascript:hideDiv(‘XXXREGION2’); // For the button called Region 2
javascript:hideDiv(‘ALL’); // For the button called Show All
Create a hidden item on the page called CURRENT_DIV
Finally edit the page attributes and place the following command in the “Page HTML Body Attributes” section:
onload="hideDiv('&CURRENT_DIV.')";
And that’s it. The key thing to note here is that once a region is hidden, all form items are still active in the DOM and will be submitted along with all the visible form items. This is a great way to break out long, complex forms and enhance the user experience.
An exmaple can be seen here
If you want to implement this type of approach on a page you simply need to:
Create a New Region Template
Either create a new region template (or copy an existing one) and add a DIV tag with the id="XXX#REGION_STATIC_ID#" around the Definition Template.
Don’t forget to close the DIV at the end of the template. In this example I copied our region called “Reports Region” and named it “Reports Region 680 Width (Static ID)”

Add the following JavaScript to your Page Header: view
Create several regions on your page and assign a unique Static ID i.e. REGION1, REGION2 etc. Set the Region Template to the one you created in the 1.

Create a button for each Region you defined in the previous stage and add the following JavaScript call as the URL target of each button:
javascript:hideDiv(‘XXXREGION1’); // For the button called Region 1
javascript:hideDiv(‘XXXREGION2’); // For the button called Region 2
javascript:hideDiv(‘ALL’); // For the button called Show All

Create a hidden item on the page called CURRENT_DIV
Finally edit the page attributes and place the following command in the “Page HTML Body Attributes” section:
onload="hideDiv('&CURRENT_DIV.')";
And that’s it. The key thing to note here is that once a region is hidden, all form items are still active in the DOM and will be submitted along with all the visible form items. This is a great way to break out long, complex forms and enhance the user experience.
An exmaple can be seen here
Tab Order of Elements on an APEX Page
To set the TAB order of your form, you simply need to add the attribute: TABINDEX="1" to the "HTML Form Element Attributes" of your items replacing the number with the desired sequence.
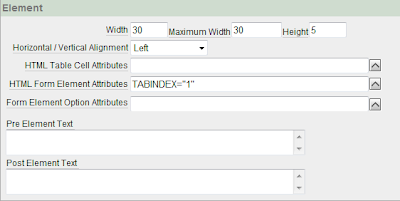
This is a great way of enhancing the usability of your forms.

This is a great way of enhancing the usability of your forms.