

Raimonds Simanovskis
7 things that can go wrong with Ruby 1.9 string encodings
Good news, I am back in blogging :) In recent years I have spent my time primarily on eazyBI business intelligence application development where I use JRuby, Ruby on Rails, mondrian-olap and many other technologies and libraries and have gathered new experience that I wanted to share with others.
Recently I did eazyBI migration from JRuby 1.6.8 to latest JRuby 1.7.3 version as well as finally migrated from Ruby 1.8 mode to Ruby 1.9 mode. Initial migration was not so difficult and was done in one day (thanks to unit tests which caught majority of differences between Ruby 1.8 and 1.9 syntax and behavior).
But then when I thought that everything is working fine I got quite many issues related to Ruby 1.9 string encodings which unfortunately were not identified by test suite and also not by my initial manual tests. Therefore I wanted to share these issues which might help you to avoid these issues in your Ruby 1.9 applications.
If you are new to Ruby 1.9 string encodings then at first read, for example, tutorials about Ruby 1.9 String and Ruby 1.9 Three Default Encodings, as well as Ruby 1.9 Encodings: A Primer and the Solution for Rails is useful.
1. Encoding header in source filesI will start with the easy one - if you use any Unicode characters in your Ruby source files then you need to add
# encoding: utf-8
magic comment line in the beginning of your source file. This was easy as it was caught by unit tests :)
2. Nokogiri XML generationThe next issues were with XML generation using Nokogiri gem when XML contains Unicode characters. For example,
require "nokogiri"
doc = Nokogiri::XML::Builder.new do |xml|
xml.dummy :name => "āčē"
end
puts doc.to_xml
will give the following result when using MRI 1.9:
<?xml version="1.0"?>
<dummy name="āčē"/>
which might not be what you expect if you would like to use UTF-8 encoding also for Unicode characters in generated XML file. If you execute the same ruby code in JRuby 1.7.3 in default Ruby 1.9 mode then you get:
<?xml version="1.0"?>
<dummy name="āčē"/>
which seems OK. But actually it is not OK if you look at generated string encoding:
doc.to_xml.encoding # => #<Encoding:US-ASCII>
doc.to_xml.inspect # => "<?xml version=\"1.0\"?>\n<dummy name=\"\xC4\x81\xC4\x8D\xC4\x93\"/>\n"
In case of JRuby you see that doc.to_xml encoding is US-ASCII (which is 7 bit encoding) but actual content is using UTF-8 8-bit encoded characters. As a result you might get ArgumentError: invalid byte sequence in US-ASCII exceptions later in your code.
Therefore it is better to tell Nokogiri explicitly that you would like to use UTF-8 encoding in generated XML:
doc = Nokogiri::XML::Builder.new(:encoding => "UTF-8") do |xml|
xml.dummy :name => "āčē"
end
doc.to_xml.encoding # => #<Encoding:UTF-8>
puts doc.to_xml
<?xml version="1.0" encoding="UTF-8"?>
<dummy name="āčē"/>
If you do CSV file parsing in your application then the first thing you have to do is to replace FasterCSV gem (that you probably used in Ruby 1.8 application) with standard Ruby 1.9 CSV library.
If you process user uploaded CSV files then typical problem is that even if you ask to upload files in UTF-8 encoding then quite often you will get files in different encodings (as Excel is quite bad at producing UTF-8 encoded CSV files).
If you used FasterCSV library with non-UTF-8 encoded strings then you get ugly result but nothing will blow up:
FasterCSV.parse "\xE2"
# => [["\342"]]
If you do the same in Ruby 1.9 with CSV library then you will get ArgumentError exception.
CSV.parse "\xE2"
# => ArgumentError: invalid byte sequence in UTF-8
It means that now you need to rescue and handle ArgumentError exceptions in all places where you try to parse user uploaded CSV files to be able to show user friendly error messages.
The problem with standard CSV library is that it is not handling ArgumentError exceptions and is not wrapping them in MalformedCSVError exception with information in which line this error happened (as it is done with other CSV format exceptions) which makes debugging very hard. Therefore I also "monkey patched" CSV#shift method to add ArgumentError exception handling.
ActiveRecord has standard way how to serialize more complex data types (like Array or Hash) in database text column. You use serialize method to declare serializable attributes in your ActiveRecord model class definition. By default YAML format (using YAML.dump method for serialization) is used to serialize Ruby object to text that is stored in database.
But you can get big problems if your data contains string with Unicode characters as YAML implementation significantly changed between Ruby 1.8 and 1.9 versions:
- Ruby 1.8 used so-called Syck library
- JRuby in 1.8 mode used Java based implementation that tried to ack like Syck
- Ruby 1.9 and JRuby in 1.9 mode use new Psych library
Lets try to see results what happens with YAML serialization of simple Hash with string value which contains Unicode characters.
On MRI 1.8:
YAML.dump({:name => "ace āčē"})
# => "--- \n:name: !binary |\n YWNlIMSBxI3Ekw==\n\n"
On JRuby 1.6.8 in Ruby 1.8 mode:
YAML.dump({:name => "ace āčē"})
# => "--- \n:name: \"ace \\xC4\\x81\\xC4\\x8D\\xC4\\x93\"\n"
On MRI 1.9 or JRuby 1.7.3 in Ruby 1.9 mode:
YAML.dump({:name => "ace āčē"})
# => "---\n:name: ace āčē\n"
So as we see all results are different. But now lets see what happens after we migrated our Rails application from Ruby 1.8 to Ruby 1.9. All our data in database is serialized using old YAML implementations but now when loaded in our application they are deserialized back using new Ruby 1.9 YAML implementation.
When using MRI 1.9:
YAML.load("--- \n:name: !binary |\n YWNlIMSBxI3Ekw==\n\n")
# => {:name=>"ace \xC4\x81\xC4\x8D\xC4\x93"}
YAML.load("--- \n:name: !binary |\n YWNlIMSBxI3Ekw==\n\n")[:name].encoding
# => #<Encoding:ASCII-8BIT>
So the string that we get back from database is no more in UTF-8 encoding but in ASCII-8BIT encoding and when we will try to concatenate it with UTF-8 encoded strings we will get Encoding::CompatibilityError: incompatible character encodings: ASCII-8BIT and UTF-8 exceptions.
When using JRuby 1.7.3 in Ruby 1.9 mode then result again will be different:
YAML.load("--- \n:name: \"ace \\xC4\\x81\\xC4\\x8D\\xC4\\x93\"\n")
# => {:name=>"ace Ä\u0081Ä\u008DÄ\u0093"}
YAML.load("--- \n:name: \"ace \\xC4\\x81\\xC4\\x8D\\xC4\\x93\"\n")[:name].encoding
# => #<Encoding:UTF-8>
So now result string has UTF-8 encoding but the actual string is damaged. It means that we will not even get exceptions when concatenating result with other UTF-8 strings, we will just notice some strange garbage instead of Unicode characters.
The problem is that there is no good solution how to convert your database data from old YAML serialization to new one. In MRI 1.9 at least it is possible to switch back YAML to old Syck implementation but in JRuby 1.7 when using Ruby 1.9 mode it is not possible to switch to old Syck implementation.
Current workaround that I did is that I made modified serialization class that I used in all model class definitions (this works in Rails 3.2 and maybe in earlier Rails 3.x versions as well):
serialize :some_column, YAMLColumn.new
YAMLColumn implementation is a copy from original ActiveRecord::Coders::YAMLColumn implementation. I modified load method to the following:
def load(yaml)
return object_class.new if object_class != Object && yaml.nil?
return yaml unless yaml.is_a?(String) && yaml =~ /^---/
begin
# if yaml sting contains old Syck-style encoded UTF-8 characters
# then replace them with corresponding UTF-8 characters
# FIXME: is there better alternative to eval?
if yaml =~ /\\x[0-9A-F]{2}/
yaml = yaml.gsub(/(\\x[0-9A-F]{2})+/){|m| eval "\"#{m}\""}.force_encoding("UTF-8")
end
obj = YAML.load(yaml)
unless obj.is_a?(object_class) || obj.nil?
raise SerializationTypeMismatch,
"Attribute was supposed to be a #{object_class}, but was a #{obj.class}"
end
obj ||= object_class.new if object_class != Object
obj
rescue *RESCUE_ERRORS
yaml
end
end
Currently this patched version will work on JRuby where just non-ASCII characters are replaced by \xNN style fragments (byte with hex code NN). When loading existing data from database we check if it has any such \xNN fragment and if yes then these fragments are replaced with corresponding UTF-8 encoded characters. If anyone has better suggestion for implementation without using eval then please let me know in comments :)
If you need to create something similar for MRI then you would probably need to search if database text contains !binary | fragment and if yes then somehow transform it to corresponding UTF-8 string. Anyone has some working example for this?
I am using spreadsheet gem to generate dynamic Excel export files. The following code was used to get generated spreadsheet as String:
book = Spreadsheet::Workbook.new
# ... generate spreadsheet ...
buffer = StringIO.new
book.write buffer
buffer.seek(0)
buffer.read
And then this string was sent back to browser using controller send_data method.
The problem was that in Ruby 1.9 mode by default StringIO will generate strings with UTF-8 encoding. But Excel format is binary format and as a result send_data failed with exceptions that UTF-8 encoded string contains non-UTF-8 byte sequences.
The fix was to set StringIO buffer encoding to ASCII-8BIT (or you can use alias BINARY):
buffer = StringIO.new
buffer.set_encoding('ASCII-8BIT')
So you need to remember that in all places where you handle binary data you cannot use strings with default UTF-8 encoding but need to specify ASCII-8BIT encoding.
6. JRuby Java file.encoding propertyLast two issues were JRuby and Java specific. Java has system property file.encoding which is not related just to file encoding but determines default character set and string encoding in many places.
If you do not specify file.encoding explicitly then Java VM on startup will try to determine its default value based on host operating system "locale". On Linux it might be that it will be set to UTF-8, on Mac OS X by default it will be MacRoman, on Windows it will depend on Windows default locale setting (which will not be UTF-8). Therefore it is always better to set explicitly file.encoding property for Java applications (e.g. using -Dfile.encoding=UTF-8 command line flag).
file.encoding will determine which default character set java.nio.charset.Charset.defaultCharset() method call will return. And even if you change file.encoding property during runtime it will not change java.nio.charset.Charset.defaultCharset() result which is cached during startup.
JRuby uses java.nio.charset.Charset.defaultCharset() in very many places to get default system encoding and uses it in many places when constructing Ruby strings. If java.nio.charset.Charset.defaultCharset() will not return UTF-8 character set then it might result in problems when using Ruby strings with UTF-8 encoding. Therefore in JRuby startup scripts (jruby, jirb and others) file.encoding property is always set to UTF-8.
So if you start your JRuby application in standard way using jruby script then you should have file.encoding set to UTF-8. You can check it in your application using ENV_JAVA['file.encoding'].
But if you start your JRuby application in non-standard way (e.g. you have JRuby based plugin for some other Java application) then you might not have file.encoding set to UTF-8 and then you need to worry about it :)
I got file.encoding related issue in eazyBI reports and charts plugin for JIRA. In this case eazyBI plugin is OSGi based plugin for JIRA issue tracking system and JRuby is running as a scripting container inside OSGi bundle.
JIRA startup scripts do not specify file.encoding default value and as a result it typically is set to operating system default value. For example, on my Windows test environment it is set to Windows-1252 character set.
If you call Java methods of Java objects from JRuby then it will automatically convert java.lang.String objects to Ruby String objects but Ruby strings in this case will use encoding based on java.nio.charset.Charset.defaultCharset(). So even when Java string (which internally uses UTF-16 character set for all strings) can contain any Unicode character it will be returned to Ruby not as string with UTF-8 encoding but in my case will return with Windows-1252 encoding. As a result all Unicode characters which are not in this Windows-1252 character set will be lost.
And this is very bad because everywhere else in JIRA it does not use java.nio.charset.Charset.defaultCharset() and can handle and store all Unicode characters even when file.encoding is not set to UTF-8.
Therefore I finally managed to create a workaround which forces that all Java strings are converted to Ruby strings using UTF-8 encoding.
I created custom Java string converter based on standard one in org.jruby.javasupport.JavaUtil class:
package com.eazybi.jira.plugins;
import org.jruby.javasupport.JavaUtil;
import org.jruby.Ruby;
import org.jruby.RubyString;
import org.jruby.runtime.builtin.IRubyObject;
public class RailsPluginJavaUtil {
public static final JavaUtil.JavaConverter JAVA_STRING_CONVERTER = new JavaUtil.JavaConverter(String.class) {
public IRubyObject convert(Ruby runtime, Object object) {
if (object == null) return runtime.getNil();
// PATCH: always convert Java string to Ruby string with UTF-8 encoding
// return RubyString.newString(runtime, (String)object);
return RubyString.newUnicodeString(runtime, (String)object);
}
public IRubyObject get(Ruby runtime, Object array, int i) {
return convert(runtime, ((String[]) array)[i]);
}
public void set(Ruby runtime, Object array, int i, IRubyObject value) {
((String[])array)[i] = (String)value.toJava(String.class);
}
};
}
Then in my plugin initialization Ruby code I dynamically replaced standard Java string converter to my customized converter:
java_converters_field = org.jruby.javasupport.JavaUtil.java_class.declared_field("JAVA_CONVERTERS")
java_converters_field.accessible = true
java_converters = java_converters_field.static_value.to_java
java_converters.put(java.lang.String.java_class, com.eazybi.jira.plugins.RailsPluginJavaUtil::JAVA_STRING_CONVERTER)
And as a result now all Java strings that were returned by Java methods were converted to Ruby strings using UTF-8 encoding and not using encoding from file.encoding Java property.
My main conclusions from solving all these string encoding issues are the following:
- Use UTF-8 encoding as much as possible. Handling conversions between different encodings will be much more harder than you will expect.
- Use example strings with Unicode characters in your tests. I didn't identify all these issues initially when running tests after migration because not all tests were using example strings with Unicode characters. So next time instead of using
"dummy"string in your test use"dummy āčē"everywhere :)
And please let me know (in comments) if you have better or alternative solutions for the issues that I described here.
Easy Business Intelligence with eazyBI
I have been interested in business intelligence and data warehouse solutions for quite a while. And I have seen that traditional data warehouse and business intelligence tool implementations take quite a long time and cost a lot to set up infrastructure, develop or implement business intelligence software and train users. And many business users are not using business intelligence tools because they are too hard to learn and use.
 Therefore some while ago a had an idea of developing easy-to-use business intelligence web application that you could implement and start to use right away and which would focus on ease-of-use and not on too much unnecessary features. And result of this idea is eazyBI which after couple months of beta testing now is launched in production.
Therefore some while ago a had an idea of developing easy-to-use business intelligence web application that you could implement and start to use right away and which would focus on ease-of-use and not on too much unnecessary features. And result of this idea is eazyBI which after couple months of beta testing now is launched in production.
One of the first issues in data warehousing is that you need to prepare / import / aggregate data that you would like to analyze. It's hard to create universal solution for this issue therefore I am building several predefined ways how to upload or prepare your data for analysis.
In the simplest case if you have source data in CSV (comma-separated values) format or you can export your data in CSV format then you can upload these files to eazyBI, map columns to dimensions and measures and start to analyze and create reports from uploaded data.
If you are already using some software-as-a-service web applications and would like to have better analysis tools to analyze your data in these applications then eazyBI will provide standard integrations for data import and will create initial sample reports. Currently the first integrations are with 37signals Basecamp project collaboration application as well as you can import and analyze your Twitter timeline. More standard integrations with other applications will follow (please let me know if you would be interested in some particular integration).
One of the main limiting factors for business intelligence as a service solutions is that many businesses are not ready to upload their data to service providers - both because of security concerns as well as uploading of big data volumes takes quite a long time. Remote eazyBI solution is unique solution which allows you to use eazyBI business intelligence as a service application with your existing data in your existing databases. You just need to download and set up remote eazyBI application and start to analyze your data. As a result you get the benefits of fast implementation of business intelligence as a service but without the risks of uploading your data to service provider.
Easy-to-useMany existing business intelligence tools suffer from too many features which make them complicated to use and you need special business intelligence tool consultants which will create reports and dashboards for business users.
Therefore my goal for eazyBI is to make it with less features but any feature that is added should be easy-to-use. With simple drag-and-drop and couple clicks you can select dimensions by which you want to analyze data and start with summaries and then drill into details. Results can be viewed as traditional tables or as different bar, line, pie, timeline or map charts. eazyBI is easy and fun to use as you play with your data.
Share reports with othersWhen you have created some report which you would like to share with other your colleagues, customers or partners then you can either send link to report or you can also embed report into other HTML pages. Here is example of embedded report from demo eazyBI account:
Embedded reports are fully dynamic and will show latest data when page will be refreshed. They can be embedded in company intranets, wikis or blogs or any other web pages.
Open web technologieseazyBI user interface is built with open HTML5/CSS3/JavaScript technologies which allows to use it both on desktop browsers as well as on mobile devices like iPad (you will be able to open reports even on mobile phones like iPhone or Android but of course because of screen size it will be harder to use). And if you will use modern browser like Chrome, Firefox, Safari or Internet Explorer 9 then eazyBI will be also very fast and responsive. I believe that speed should be one of the main features of any application therefore I am optimizing eazyBI to be as fast as possible.
In the backend eazyBI uses open source Mondrian OLAP engine and mondrian-olap JRuby library that I have created and open-sourced during eazyBI development.
No big initial investmentseazyBI pricing is based on monthly subscription starting from $20 per month. There is also free plan for single user as well as you can publish public data for free. And you don't need to make long-term commitments - you just pay for the service when you use it and you can cancel it anytime when you don't need it anymore.
Try it outIf this sounds interesting to you then please sign up for eazyBI and try to upload and analyze your data. And if you have any suggestions or questions about eazyBI then please let me know.
P.S. Also I wanted to mention that by subscribing to eazyBI you will also support my work on open-source. If you are user of my open-source libraries then I will appreciate if you will become eazyBI user as well :) But in case if you do not need solution like eazyBI you could support me by tweeting and blogging about eazyBI, will be thankful for that as well.
Oracle enhanced adapter 1.4.0 and Readme Driven Development
I just released Oracle enhanced adapter version 1.4.0 and here is the summary of main changes.
Rails 3.1 supportOracle enhanced adapter GitHub version was working with Rails 3.1 betas and release candidate versions already but it was not explicitly stated anywhere that you should use git version with Rails 3.1. Therefore I am releasing new version 1.4.0 which is passing all tests with latest Rails 3.1 release candidate. As I wrote before main changes in ActiveRecord 3.1 are that it using prepared statement cache and using bind variables in many statements (currently in select by primary key, insert and delete statements) which result in better performance and better database resources usage.
To follow up how Oracle enhanced adapter is working with different Rails versions and different Ruby implementations I have set up Continuous Integration server to run tests on different version combinations. At the moment of writing everything was green :)
Other bug fixes and improvementsMain fixes and improvements in this version are the following:
On JRuby I switched from using old
ojdbc14.jarJDBC driver to latestojdbc6.jar(on Java 6) orojdbc5.jar(on Java 5). And JDBC driver can be located in Rails application./libdirectory as well.RAWdata type is now supported (which is quite often used in legacy databases instead of nowadays recommendedCLOBandBLOBtypes).rake db:createandrake db:dropcan be used to create development or test database schemas.Support for virtual columns in improved (only working on Oracle 11g database).
Default table, index, CLOB and BLOB tablespaces can be specified (if your DBA is insisting on putting everything in separate tablespaces :)).
Several improvements for context index additional options and definition dump.
See list of all enhancements and bug fixes
If you want to have a new feature in Oracle enhanced adapter then the best way is to implement it by yourself and write some tests for that feature and send me pull request. In this release I have included commits from five new contributors and two existing contributors - so it is not so hard to start contributing to open source!
Readme Driven DevelopmentOne of the worst parts of Oracle enhanced adapter so far was that for new users it was quite hard to understand how to start to use it and what are all additional features that Oracle enhanced adapter provides. There were many blog posts in this blog, there were wiki pages, there were posts in discussion forums. But all this information was in different places and some posts were already outdated and therefore for new users it was hard to understand how to start.
After reading about Readme Driven Development and watching presentation about Readme Driven Development I knew that README of Oracle enhanced adapter was quite bad and should be improved (in my other projects I am already trying to be better but this was my first one :)).
Therefore I have written new README of Oracle enhanced adapter which includes main installation, configuration, usage and troubleshooting tasks which previously was scattered across different other posts. If you find that some important information is missing or outdated then please submit patches to README as well so that it stays up to date and with relevant information.
If you have any questions please use discussion group or report issues at GitHub or post comments here.
Recent conference presentations
Recently I has not posted any new posts as I was busy with some new projects as well as during May attended several conferences and in some I also did presentations. Here I will post slides from these conferences. If you are interested in some of these topics then ask me to come to you as well and talk about these topics :)
Agile Riga DayIn March I spoke at Agile Riga Day (organized by Agile Latvia) about my experience and recommendations how to adopt Agile practices in iterative style.
RailsConfIn May I travelled to RailsConf in Baltimore and I hosted traditional Rails on Oracle Birds of a Feather session there and gave overview about how to contribute to ActiveRecord Oracle enhanced adapter.
TAPOSTThen I participated in our local Theory and Practice of Software Testing conference and there I promoted use of Ruby as test scripting language.
RailsWayConAnd lastly I participated in Euruko and RailsWayCon conferences in Berlin. In RailsWayCon my first presentation was about multidimensional data analysis with JRuby and mondrian-olap gem. I also published mondrian-olap demo project that I used during presentation.
And second RailsWayCon presentation was about CoffeeScript, Backbone.js and Jasmine that I am recently using to build rich web user interfaces. This was quite successful presentation as there were many questions and also many participants were encouraged to try out CoffeeScript and Backbone.js. I also published my demo application that I used for code samples during presentation.
Next conferencesNow I will rest for some time from conferences :) But then I will attend FrozenRails in Helsinki and I will present at Oracle OpenWorld in San Francisco. See you there!
Oracle enhanced adapter 1.3.2 is released
I just released Oracle enhanced adapter version 1.3.2 with latest bug fixes and enhancements.
Bug fixes and improvementsMain fixes and improvements are the following:
- Previous version 1.3.1 was checking if environment variable TNS_NAME is set and only then used provided
databaseconnection parameter (indatabase.yml) as TNS connection alias and otherwise defaulted to connection tolocalhostwith provided database name. This was causing issues in many setups.
Therefore now it is simplified that if you provide onlydatabaseparameter indatabase.ymlthen it by default will be used as TNS connection alias or TNS connection string. - Numeric username and/or password in
database.ymlwill be automatically converted to string (previously you needed to quote them using"..."). - Database connection pool and JNDI connections are now better supported for JRuby on Tomcat and JBoss application servers.
- NLS connection parameters are supported via environment variables or in
database.yml. For example, if you need to haveNLS_DATE_FORMATin your database session to beDD-MON-YYYYthen either you specifynls_date_format: DD-MON-YYYYindatabase.ymlfor particular database connection or setENV['NLS_DATE_FORMAT'] = 'DD-MON-YYYY'in e.g.config/initializers/oracle.rb. You can see the list of all NLS parameters in source code.
It might be necessary to specify these NLS session parameters only if you work with some existing legacy database which has, for example, some stored procedures that require particular NLS settings. If this is new database just for Rails purposes then there is no need to change any settings. - If you have defined foreign key constraints then they are now correctly dumped in
db/schema.rbafter all table definitions. Previously they were dumped after corresponding table which sometimes caused that schema could not be recreated from schema dump because it tried to load constraint which referenced table which has not yet been defined. - If you are using
NCHARandNVARCHAR2data types then nowNCHARandNVARCHAR2type values are correctly quoted withN'...'in SQL statements.
Meanwhile Oracle enhanced adapter is updated to pass all ActiveRecord unit tests in Rails development master branch and also updated according to Arel changes. Arel library is responsible for all SQL statement generation in Rails 3.0.
Rails 3.0.3 is using Arel version 2.0 which was full rewrite of Arel 1.0 (that was used initial Rails 3.0 version) and as a result of this rewrite it is much faster and now Rails 3.0.3 ActiveRecord is already little bit faster than in ActiveRecord in Rails 2.3.
There are several improvements in Rails master branch which are planned for Rails 3.1 version which are already supported by Oracle enhanced adapter. One improvement is that ActiveRecord will support prepared statement caching (initially for standard simple queries like find by primary key) which will reduce SQL statement parsing time and memory usage (and probably Oracle DBAs will complain less about Rails dynamic SQL generation :)). The other improvement is that ActiveRecord will correctly load included associations with more than 1000 records (which currently fails with ORA-01795 error).
But I will write more about these improvements sometime later when Rails 3.1 will be released :)
InstallAs always you can install Oracle enhanced adapter on any Ruby platform (Ruby 1.8.7 or Ruby 1.9.2 or JRuby 1.5) with
gem install activerecord-oracle_enhanced-adapter
If you have any questions please use discussion group or report issues at GitHub or post comments here. And the best way how to contribute is to fix some issue or create some enhancement and send me pull request at GitHub.
ruby-plsql-spec upgraded to use RSpec 2.0
Initial version of ruby-plsql-spec gem was using RSpec version 1.3. But recently RSpec 2.0 was released which API is not compatible with previous RSpec 1.x API and as a result plsql-spec utility was failing if just RSpec was upgraded to version 2.0.
Therefore I updated also ruby-plsql-spec to use latest RSpec 2.0 gem and released ruby-plsql-spec gem version 0.2.1. You can install the latest version with
gem install ruby-plsql-specUpgrade from previous version
If you previously already installed initial ruby-plsql-spec version 0.1.0 then you need to update your spec/spec_helper.rb file to use RSpec 2.0. You can do it by running one more time
plsql-spec init
which will check which current files are different from the latest templates. You need to update just spec_helper.rb file. When you will be prompted to overwrite spec_helper.rb file then at first you can enter d to see differences between current file and new template. If you have not changed original spec_helper.rb file then you will see just one difference
- Spec::Runner.configure do |config| + RSpec.configure do |config|
You can then answer y and this file will be updated. When you will be prompted to overwrite other files then you can review the changes in the same way and decide if you want them to be overwritten or not (e.g. do not overwrite database.yml file as it has your specific database connection settings).
In addition plsql-spec utility now has --html option which will generate test results report as HTML report. It might be useful for usage in text editors where you can define which command line utility to run when pressing some shortcut key and then display generated HTML output report. If you will execute
plsql-spec run --html
then it will generate HTML report in test-results.html file. You can override this file name as well using --html output_file_name.html option.
If you have any other feature suggestions or questions about ruby-plsql-spec then please post comments here or report any bugs at GitHub issues page.
ruby-plsql-spec gem and code coverage reporting
During recent Oracle OpenWorld conference I presented session PL/SQL unit testing can be fun! where I demonstrated how to do PL/SQL unit testing with Ruby:
Audience was quite interested and had a lot of questions and therefore it motivated me to do some more improvements to ruby-plsql-spec to make it easier for newcomers.
ruby-plsql-spec gem and plsql-spec command line utilityInitially ruby-plsql-spec was just repository of sample tests and if you wanted to start to use it in your project you had to manually pick necessary files and copy them to your project directory.
Now ruby-plsql-spec is released as a gem which includes all necessary dependencies (except ruby-oci8 which you should install if using MRI Ruby implementation) and you can install it with
gem install ruby-plsql-spec
See more information about installation in README file or see specific installation instructions on Windows.
When you have installed ruby-plsql-spec gem and want to start to use it in your existing project then go to your project directory and from command line execute
plsql-spec init
It will create spec subdirectory in current directory where all initial supporting files will be created. The main configuration file which should be updated is spec/database.yml where you should specify username, password and database connection string that should be used when running tests:
default:
username: hr
password: hr
database: orcl
If you specify just database: name then it will be used as TNS connection string (and TNS_ADMIN environment variable should point to directory where tnsnames.ora file is located) or you can also provide hostname: and if necessary also port: parameters and then you can connect to database without tnsnames.ora file.
Now you can start to create your tests in spec directory and your tests file names should end with _spec.rb. You can see some examples at ruby-plsql-spec examples directory
To validate your installation you can try to create simple dummy test in spec/dummy_spec.rb:
require "spec_helper"
describe "test installation" do
it "should get SYSDATE" do
plsql.sysdate.should_not == NULL
end
end
And now from command line you can try to run your test with:
plsql-spec run
If everything is fine you should see something similar like this:
Running all specs from spec/ . Finished in 0.033782 seconds 1 example, 0 failuresCode coverage reporting
During my Oracle OpenWorld presentation I also showed how to get PL/SQL code coverage report (which shows which PL/SQL code lines were executed during tests run). It might be useful when you want to identify which existing PL/SQL code is not yet covered by unit tests.
Now code coverage reporting is even easier with new ruby-plsql-spec gem. It uses Oracle database DBMS_PROFILER package to collect code coverage information and I took rcov reports HTML and CSS files to present results (so that they would be very similar to Ruby code coverage reports).
To try code coverage reporting let’s create simple PL/SQL function:
CREATE OR REPLACE FUNCTION test_profiler RETURN VARCHAR2 IS
BEGIN
RETURN 'test_profiler';
EXCEPTION
WHEN OTHERS THEN
RETURN 'others';
END;
and simple test to verify code coverage reporting:
require "spec_helper"
describe "test code coverage" do
it "should get result" do
plsql.test_profiler.should == 'test_profiler'
end
end
And now you can run tests with --coverage option which will produce code coverage report:
plsql-spec run --coverage
As a result code coverage reports are created in coverage/ subdirectory. Open coverage/index.html in your browser and click on TEST_PROFILER function and you should see something similar like this report:

You can see that RETURN 'test_profiler'; line (with green background) was executed by test but RETURN 'others'; line (with red background) was not. Lines with light background are ignored by DBMS_PROFILER and I do not take them into account when calculating code coverage percentage (but they are taken into account when calculating total coverage percentage).
If you have any other questions about using ruby-plsql-spec for PL/SQL unit testing then please post comments here or if you find any issues when using ruby-plsql-spec then please report them at GitHub issues page.
Oracle enhanced adapter 1.3.1 and how to use it with Rails 3
Rails 3.0 was released recently and therefore I am releasing new Oracle enhanced adapter version 1.3.1 which is tested and updated against latest Rails 3.0.0 version. You can read about main changes in oracle_enhanced adapter for Rails 3 support in my previous blog post. Latest version 1.3.1 mainly contains several bug fixes (which you can find in change log as well as in detailed commit list) as well as several new features that I will describe here.
Usage with Rails 3I have improved a little bit configuration and loading of oracle_enhanced adapter in Rails 3 and here are the initial steps that you should do to use oracle_enhanced adapter in Rails 3 application. I assume that you are using latest Rails 3.0.0 version as well as latest Bundler 1.0.0 version.
At first you need to include necessary gems in Gemfile of your application:
gem 'ruby-oci8', '~> 2.0.4'
gem 'activerecord-oracle_enhanced-adapter', '~> 1.3.1'
It is recommended to use ~> version (requires specified version or later minor version update where only the last digit of version has changed) or = version in your Gemfile and not >= (which might include major version changes). In this way you ensure that your application will not break when major API changes will happen in gem that you are using.
If you want to run your application both on MRI and JRuby then you can specify
platforms :ruby do
gem 'ruby-oci8', '~> 2.0.4'
end
which will load ruby-oci8 gem only when using MRI 1.8 or 1.9 and not when using JRuby.
If you would like to use the latest development version of oracle_enhanced then change Gemfile to:
gem 'activerecord-oracle_enhanced-adapter', '~> 1.3.1', :git => 'git://github.com/rsim/oracle-enhanced.git'
If you will use also ruby-plsql gem in your application then include as well (and specify version as needed)
gem "ruby-plsql", "~> 0.4.3"
After these changes in Gemfile run bundle update to install necessary gems and generate corresponding Gemfile.lock.
If you want to use all default oracle_enhanced settings then you need just to specify your database connection in database.yml, for example, something like this:
development:
adapter: oracle_enhanced
database: orcl
username: user
password: secret
and you can start to use Rails with Oracle database. If you would like to change some oracle_enhanced adapter settings then it is recommended to create initializer file config/initializers/oracle.rb where you can specify necessary defaults, for example:
ActiveSupport.on_load(:active_record) do
ActiveRecord::ConnectionAdapters::OracleEnhancedAdapter.class_eval do
self.emulate_integers_by_column_name = true
self.emulate_dates_by_column_name = true
self.emulate_booleans_from_strings = true
# to ensure that sequences will start from 1 and without gaps
self.default_sequence_start_value = "1 NOCACHE INCREMENT BY 1"
# other settings ...
end
end
It is important to use ActiveSupport.on_load(:active_record) as Rails 3 does lazy loading of all components and we need to ensure that oracle_enhanced adapter defaults are set only after ActiveRecord is loaded.
You can take a look at sample Rails 3 application on Oracle to see sample configuration files that I mentioned here.
Database connection optionsThere are several ways how to specify database connection in database.yml file.
If you are using tnsnames.ora file with TNS names and connection descriptions then you need to set TNS_ADMIN environment variable to point to directory where tnsnames.ora file is located. If oracle_enhanced adapter will detect that ENV[‘TNS_ADMIN’] is not empty then it will try to use TNS name in :database parameter to connect to database. So in this case in database.yml you need to specify:
development:
adapter: oracle_enhanced
database: connection_name_from_tnsnames
username: user
password: secret
Connection using tnsnames is supported both for MRI with ruby-oci8 as well as for JRuby with JDBC. Use this option if you would not like to hardcode database server address, port and database name in your application and want to specify separately in tnsnames.ora file.
host, port and database option
If you do not want to create separate tnsnames.ora file and want to specify database server, port and database name directly in application, then you can specify these options separately in database.yml file, for example:
development:
adapter: oracle_enhanced
host: localhost
port: 1521
database: orcl
username: user
password: secret
port default value is 1521 and can be omitted. It is also possible to specify host, port and database name is Oracle specific format in database option:
development:
adapter: oracle_enhanced
database: //localhost:1521/orcl
username: user
password: secret
It is also possible to specify TNS connection description directly in database.yml file (if you do not want to create separate tnsnames.ora file), for example:
development:
adapter: oracle_enhanced
database: "(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521)))(CONNECT_DATA=(SERVICE_NAME=orcl)))"
username: user
password: secret
If you deploy your JRuby application in Java application server that supports JNDI connections then it is possible to specify also JNDI connection in database.yml file, for example:
production:
adapter: oracle_enhanced
jndi: "jdbc/jndi_connection_name"
I am not using this connection option but some oracle_enhanced users are using it.
Contributing to oracle_enhanced adapterIf you experience any issues with oracle_enhanced adapter then please report issues at GitHub issue tracker or discuss them at oracle_enhanced discussion group.
But even better if you want some new feature in oracle_enhanced adapter then fork oracle_enhanced git repository and make your changes and send me pull requests for review.
For all changes please add also RSpec tests as well as verify if all existing tests are passing after your changes. I added description how to set up environment for running tests – please let me know if something is missing there.
Big thanks to all contributors who have submitted patches so far :)
Moving blog from wordpress.com to Jekyll

This blog was hosted for several years on wordpress.com as it was the easiest way to host a blog when I started. But recently I was not very satisfied with it because of the following reasons:
- I include code snippets in my blog posts quite often and several times I had issues with code formatting on wordpress.com. I used MarsEdit to upload blog posts but when I read previous posts back then quite often my < and > symbols were replaced with < and >.
- I would prefer to write my posts in Textile and not in plain HTML (I think it could be possible also with wordpress.com but it was not obvious to me).
- I didn’t quite like CSS design of my site and wanted to improve it but I prefer minimalistic CSS stylesheets and didn’t want to learn how to do design CSS specific for Wordpress sites.
- Wordpress site was too mainstream, I wanted something more geeky :)
When I do web app development then I use TextMate for HTML / CSS and Ruby editing (sometime I use CSSEdit when I need to do more CSS editing), I use Textile for wiki-style content editing in my apps, I use git for version control, I use Ruby rake for build and deployment tasks. Wouldn’t it be great if I could use the same toolset for writing my blog?
What is Jekyll?I had heard about Jekyll blogging tool several times and now I decided that it is the time to start to use it. Jekyll was exactly matching my needs:
- You can write blog posts in Textile (or in Markdown)
- You can design HTML templates and CSS stylesheets as you want and use Liquid to embed dynamic content
- You can store all blog content in git repository (or in any other version control system that you like)
- And finally you use jekyll Ruby gem to generate static HTML files that can be hosted anywhere
So it sounds quite easy and cool therefore I started migration.
Migration Initial setupI started my new blog repository using canonical example site from Jekyll’s creator. You just need to remove posts from _posts directory and start to create your own.
Export from wordpress.comAt first I needed to export all my existing posts from wordpress.com. I found helpful script which processes wordpress.com export and creates Textile source files for Jekyll as well as comments import file for Disqus (more about that later). It did quite good job but I needed anyway to go manually through all posts to do the following changes:
- I needed to manually change HTML source for lists to Textile formatted lists (export file conversion script converted just headings to Textile formatting) as otherwise they were not looking good when parsed by Textile formatting.
- I needed to wrap all code snippets with Jekyll code highlighting tags (which uses Pygments tool to generate HTML) – as previously I had not used consistent formatting style I could not do that by global search & replace.
- I needed to download all uploaded images from wordpress.com and put them in
imagesdirectory.
As I wanted to create more simple and maintainable CSS stylesheets I didn’t just copy previous CSS files but manually picked just the parts I needed. And now as I had full control over CSS I spent a lot of time improving my previous design (font sizes, margins, paddings etc.) – but now at least I am more satisfied with it :)
TagsAs all final generated pages are static there is no standard way how to do typical dynamic pages like list of posts with selected tag. But the good thing is that I can create rake tasks that can re-generate all dynamic pages as static pages whenever I do some changes to original posts. I found some examples that I used to create my rake tasks for tag pages and tag cloud generation.
Previously wordpress.com was showing some automatically generated related posts for each post. Initially it was not quite obvious how to do it (as site.related_posts was always showing the latest posts). Then I found that I need to turn on lsi option and in addition install GSL library (I installed it with homebrew) and RubyGSL (as otherwise related posts generation was very slow).
The next issue is that in static HTML site you cannot store comments and you need to use some hosted commenting system. The most frequently commenting system in Jekyll sites is Disqus and therefore I decided to use it as well. It took some time to understand how it works but it provides all necessary HTML snippets that you need to include in your layout templates and then it just works.
Previously mentioned script also included possibility to import my existing comments from wordpress.com into Disqus. But that was not quite as easy as I hoped:
- Disqus API that allows to add comments to existing post that is found by URL is not creating new discussion threads if they do not exist. Therefore I needed at first to open all existing pages to create corresponding Disqus discussion threads.
- As in static HTML case I do not have any post identifiers that could be used as discussion thread identifiers I need to ensure that my new URLs of blog posts are exactly the same as the old ones (in my case I needed to add / at the end of URLs as URL without ending / will be considered as different URL by Disqus).
- There was issue that some comments in export file had wrong date in URL (it was in cases when draft of post was prepared earlier than post was published) and I needed to fix that in export file.
So be prepared that you will need to import and then delete imported comments several times :)
RSS / Atom feedsIf you have existing subscribers to your RSS or Atom feed then you either need to use the same URL for new feed as well or to redirect it to the new feed URL. In my case I created new Feedburner feed and redirected old feed URL to the new one in .htaccess file.
Other URL mappingsIn my case I renamed categories to tags in my blog posts and URLs but as these old category URLs were indexed by Google and were showing on to Google search results I redirected them as well in .htaccess file.
If you want to allow search in your blog then the easiest way is just to add Google search box with sitesearch parameter.
Previously I used standard wordpress.com analytics pages to review statistics, now I added Google Analytics for that purpose.
DeploymentFinally after all migration tasks I was ready to deploy my blog into production. As I had account at Dreamhost I decided that it is good enough for static HTML hosting.
I created rake tasks for deployment that use rsync for file transfer and now I can just do rake deploy to generate the latest version of site and transfer it to hosting server.
After that I needed to remap DNS name of blog.rayapps.com to new location and wait for several hours until this change propogated over Internet.
Additional HTML generation speed improvementsWhen I was doing regular HTML re-generation using jekyll I noticed that it started to get quite slow. After investigation I found out that the majority of time went on Pygments execution for code highlighting. To fix this issue I found jekyll patches that implemented Pygments results caching and I added it as ‘monkey patch’ to my repository (it stores cached results in _cache directory). After this patch my HTML re-generation happens instantly.
I published ‘source code’ of my blog on GitHub so you can use it as example if I convinced you to migrate to Jekyll as well :)
The whole process took several days but now I am happy with my new “geek blogging platform” and can recommend it to others as well.
Oracle enhanced adapter 1.3.0 is Rails 3 compatible
Rails 3 is in final finishing stage (currently in beta4) and therefore I released new Oracle enhanced adapter version 1.3.0 which I was working on during last months.
Rails 3 compatibility
The major enhancement is that Oracle enhanced adapter is now compatible with Rails 3. To achieve that I also developed Oracle SQL compiler for Arel gem which is used now by ActiveRecord to generate SQL statements. When using Oracle enhanced adapter with Rails 3 you will notice several major changes:
- Table and column names are always quoted and in uppercase to avoid the need for checking Oracle reserved words.
E.g. nowPost.allwill generate query
SELECT "POSTS".* FROM "POSTS"
- Better support for limit and offset options (when possible just ROWNUM condition in WHERE clause is used without using subqueries).
E.g.Post.first(orPost.limit(1)) will generate query
butSELECT "POSTS".* FROM "POSTS" WHERE ROWNUM <= 1Post.limit(1).offset(1)will generate
select * from (select raw_sql_.*, rownum raw_rnum_ from (SELECT "EMPLOYEES".* FROM "EMPLOYEES") raw_sql_ where rownum <= 2) where raw_rnum_ > 1
When using Oracle enhanced adapter with current version of Rails 3 and Arel it is necessary to turn on table and column caching option in all environments as otherwise Arel gem will cause very many SQL queries on data dictionary tables on each request. To achieve that you need to include in some initializer file:
ActiveRecord::ConnectionAdapters::OracleEnhancedAdapter.cache_columns = true
I have published simple Rails 3 demo application using Rails 3 and Oracle enhanced adapter. You can take a look at Gemfile and Oracle initializer file to see examples how to configure Oracle enhanced adapter with Rails 3.
Rails 2.3 compatibilityOracle enhanced adapter version 1.3.0 is still compatible with Rails 2.3 (I am testing it against Rails 2.3.5 and 2.3.8) and it is recommended to upgrade if you are on Rails 2.3 and plan to upgrade to Rails 3.0 later. But if you are still on Rails 2.2 or earlier then there might be issues with Oracle enhanced adapter 1.3.0 as I am using some Rails methods which appeared just in Rails 2.3 – so in this case it might be safer to stay on previous Oracle enhanced adapter version 1.2.4 until you upgrade to latest Rails version.
Oracle CONTEXT index supportEvery edition of Oracle database includes Oracle Text option for free which provides different full text indexing capabilities. Therefore in Oracle database case you don’t need external full text indexing and searching engines which can simplify your application deployment architecture.
The most commonly used index type is CONTEXT index which can be used for efficient full text search. Most of CONTEXT index creation examples show how to create simple full text index on one table and one column. But if you want to create more complex full text indexes on multiple columns or even on multiple tables and columns then you need to write your custom procedures and custom index refreshing logic.
Therefore to make creation of more complex full text indexes easier I have created additional add_context_index and remove_context_index methods that can be used in migrations and which creates additional stored procedures and triggers when needed in standardized way.
This is how you can create simple single column index:
add_context_index :posts, :title
And you can perform search using this index with
Post.contains(:title, 'word')
This is how you create index on several columns (which will generate additional stored procedure for providing XML document with specified columns to indexer):
add_context_index :posts, [:title, :body]
And you can search either in all columns or specify in which column you want to search (as first argument you need to specify first column name as this is the column which is referenced during index creation):
Post.contains(:title, 'word')
Post.contains(:title, 'word within title')
Post.contains(:title, 'word within body')
See Oracle Text documentation for syntax that you can use in CONTAINS function in SELECT WHERE clause.
You can also specify some dummy main column name when creating multiple column index as well as specify to update index automatically after each commit (as otherwise you need to synchronize index manually or schedule periodic update):
add_context_index :posts, [:title, :body], :index_column => :all_text,
:sync => 'ON COMMIT'
Post.contains(:all_text, 'word')
Or you can specify that index should be updated when specified columns are updated (e.g. in ActiveRecord you can specify to trigger index update when created_at or updated_at columns are updated). Otherwise index is updated only when main index column is updated.
add_context_index :posts, [:title, :body], :index_column => :all_text,
:sync => 'ON COMMIT', :index_column_trigger_on => [:created_at, :updated_at]
And you can even create index on multiple tables by providing SELECT statements which should be used to fetch necessary columns from related tables:
add_context_index :posts,
[:title, :body,
# specify aliases always with AS keyword
"SELECT comments.author AS comment_author, comments.body AS comment_body FROM comments WHERE comments.post_id = :id"
],
:name => 'post_and_comments_index',
:index_column => :all_text,
:index_column_trigger_on => [:updated_at, :comments_count],
:sync => 'ON COMMIT'
# search in any table columns
Post.contains(:all_text, 'word')
# search in specified column
Post.contains(:all_text, "aaa within title")
Post.contains(:all_text, "bbb within comment_author")
In terms of Oracle Text performance in most cases it is good enough (typical response in not more that hundreds of milliseconds). But from my experience it is still slower compared to dedicated full text search engines like Sphinx. So in case if Oracle Text performance is not good enough (if you need all search operations return in tens of milliseconds) then you probably need to evaluate dedicated search engines like Sphinx or Lucene.
Other changesPlease see change history file or commit list to see more detailed list of changes in this version.
InstallAs always you can install Oracle enhanced adapter on any Ruby platform (Ruby 1.8.7 or Ruby 1.9.1/1.9.2 or JRuby) with
gem install activerecord-oracle_enhanced-adapter
If you have any questions please use discussion group or report issues at GitHub or post comments here.
Please vote for my Ruby session proposals at Oracle OpenWorld
 I am trying to tell more people at Oracle OpenWorld about Ruby and Rails and how it can be used with Oracle database. Unfortunately my session proposals were rejected by organizers but now there is a second chance to propose sessions at mix.oracle.com and top voted sessions will be accepted for conference. But currently my proposed sessions do not have enough votes :(
I am trying to tell more people at Oracle OpenWorld about Ruby and Rails and how it can be used with Oracle database. Unfortunately my session proposals were rejected by organizers but now there is a second chance to propose sessions at mix.oracle.com and top voted sessions will be accepted for conference. But currently my proposed sessions do not have enough votes :(
I would be grateful if my blog readers and Ruby on Oracle supporters would vote for my sessions Fast Web Applications Development with Ruby on Rails on Oracle and PL/SQL Unit Testing Can Be Fun!.
You need to log in to mix.oracle.com with your oracle.com login (or you should create new one if you don’t have it). And also you need to vote for at least one more session as well (as votes are counted if you have voted for at least 3 sessions). Voting should be done until end of this week (June 20).
And if you have other oracle_enhanced or ruby-plsql users in your
organization then please ask their support as well :)
Thanks in advance!
ruby-plsql 0.4.2 - better support for object types and types in packages
I just released ruby-plsql version 0.4.2 which mainly adds support for more PL/SQL procedure parameter types. See change history file for more detailed list of changes.
Object types and object methodsNow you can use ruby-plsql to construct PL/SQL objects and call methods on these object. For example, if you have the following type defined:
CREATE OR REPLACE TYPE t_address AS OBJECT (
street VARCHAR2(50),
city VARCHAR2(50),
country VARCHAR2(50),
CONSTRUCTOR FUNCTION t_address(p_full_address VARCHAR2)
RETURN SELF AS RESULT,
MEMBER FUNCTION display_address(p_separator VARCHAR2 DEFAULT ',') RETURN VARCHAR2,
MEMBER PROCEDURE set_country(p_country VARCHAR2),
STATIC FUNCTION create_address(p_full_address VARCHAR2) RETURN t_address
);
Then you can construct PL/SQL objects and call methods on them:
# call default constructor with named parameters
address = plsql.t_address(:street => 'Street', :city => 'City', :country => 'Country')
# call default constructor with sequential parameters
address = plsql.t_address('Street', 'City', 'Country')
# call custom constructor
address = plsql.t_address('Street, City, Country')
address = plsql.t_address(:p_full_address => 'Street, City, Country')
# returned PL/SQL object is Hash object in Ruby
address == {:street => 'Street', :city => 'City', :country => 'Country'}
# but in addition you can call PL/SQL methods on it
address.display_address == 'Street, City, Country'
address.set_country('Other') == {:street => 'Street', :city => 'City', :country => 'Other'}
# or you can call object member methods also with explicit self parameter
plsql.t_address.display_address(:self => {:street => 'Street', :city => 'City', :country => 'Other'},
:p_separator => ',') == 'Street, City, Country'
# or you can call static methods of type
plsql.t_address.create_address('Street, City, Country') ==
{:street => 'Street', :city => 'City', :country => 'Country'}
Now you can call Pl/SQL procedures with parameters which have record or table of record type that is defined inside PL/SQL package. For example if you have the following package:
CREATE OR REPLACE PACKAGE test_records IS
TYPE t_employee IS RECORD(
employee_id NUMBER(15),
first_name VARCHAR2(50),
last_name VARCHAR2(50),
hire_date DATE
);
TYPE t_employees IS TABLE OF t_employee;
TYPE t_employees2 IS TABLE OF t_employee
INDEX BY BINARY_INTEGER;
FUNCTION test_employee (p_employee IN t_employee)
RETURN t_employee;
FUNCTION test_employees (p_employees IN t_employees)
RETURN t_employees;
FUNCTION test_employees2 (p_employees IN t_employees2)
RETURN t_employees2;
END;
Then you can call these package functions from Ruby:
employee = {
:employee_id => 1,
:first_name => 'First',
:last_name => 'Last',
:hire_date => Time.local(2010,2,26)
}
# PL/SQL record corresponds to Ruby Hash
plsql.test_records.test_employee(employee) == employee
# PL/SQL table corresponds to Ruby Array
plsql.test_records.test_employees([employee, employee]) == [employee, employee]
# PL/SQL index-by table corresponds to Ruby Hash
plsql.test_records.test_employees({1 => employee, 2 => employee}) == {1 => employee, 2 => employee}
If you will use table types defined inside PL/SQL packages then ruby-plsql will dynamically create session specific temporary tables which will be used to pass and get table parameter values. To ensure that these session specific temporary tables will be dropped you need to explicitly call plsql.logoff to close connection. For example, if you use ruby-plsql-spec for PL/SQL unit testing then in spec_helper.rb include
at_exit do
plsql.logoff
end
to ensure that connection will be closed with plsql.logoff before Ruby script will exit. But in case of some script failure if this was not executed and you notice that there are temporary tables with RUBY_ prefix in your schema then you can call plsql.connection.drop_all_ruby_temporary_tables to drop all temporary tables.
Now there is simpler connect! method how to establish new ruby-plsql connection when you need a new connection just for ruby-plsql needs. You can do it in several ways:
plsql.connect! username, password, database_tns_alias
plsql.connect! username, password, :host => host, :port => port, :database => database
plsql.connect! :username => username, :password => password, :database => database_tns_alias
plsql.connect! :username => username, :password => password, :host => host, :port => port, :database => database
And the good thing is that this method will work both with MRI 1.8 or 1.9 or with JRuby – you do not need to change the way how you are establishing connection to database.
SavepointsNow there is simpler way how to define savepoints and how to rollback to savepoint:
plsql.savepoint "before_something"
plsql.rollback_to "before_something"
Now ruby-plsql will check if referenced database object is valid before trying to call it. And if it will not be valid then corresponding compilation error will be displayed. For example, if you have invalid database object:
CREATE OR REPLACE FUNCTION test_invalid_function(p_dummy VARCHAR2) RETURN VARCHAR2 IS
l_dummy invalid_table.invalid_column%TYPE;
BEGIN
RETURN p_dummy;
END;
then when trying to call it
plsql.test_invalid_function('dummy')
you will get the following error message:
ArgumentError: Database object 'HR.TEST_INVALID_FUNCTION' is not in valid status
Error on line 2: l_dummy invalid_table.invalid_column%TYPE;
position 11: PLS-00201: identifier 'INVALID_TABLE.INVALID_COLUMN' must be declared
position 11: PL/SQL: Item ignored
See History.txt file for other new features and improvements and see RSpec tests in spec directory for more usage examples.
ActiveRecord Oracle enhanced adapter version 1.2.4
I have released maintenance version of ActiveRecrod Oracle enhanced adapter with some bug fixes and some new features. This is the last maintenance version for Rails 2, I have already done majority of work to support also Rails 3 in next adapter versions, but that deserves another post when it will be ready :).
Detailed changes can be found in change history file and commit log, here I will point out the main changes.
Schema and structure dumpThere are several improvements in schema (rake db:schema:dump) and structure dump (rake db:structure:dump) tasks. Now structure dump is improved to contain all schema objects in SQL statements format.
Also db:test:purge rake task (which is run before recreating test schema when running rake test or rake spec) is changed that it will delete all schema objects from test schema – including also views, packages, procedures and functions which are not recreated from schema.rb. So if you need to have additional database objects in your schema besides tables, indexes, sequences and synonyms (which are dumped in schema.rb) then you need to recreate them after standard rake task db:schema:load is run. Here is example how to execute any additional tasks after db:schema:load (include this in some .rake file in lib/tasks directory):
namespace :db do
namespace :schema do
task :load do
Rake::Task["db:schema:create_other_objects"].invoke
end
task :create_other_objects do
# include code here which creates necessary views, packages etc.
end
end
end
You can pass :temporary => true option for create_table method to create temporary tables.
You can use :tablespace => "tablespace name" option for add_index method to create index in non-default Oracle tablespace that is specified for user (e.g. if it is requested by your DBA for performance reasons). You can also define function based indexes using add_index and they will be correctly dumped in schema.rb.
oracle_enhanced adapter now supports ActiveRecord nested transactions using database savepoints.
ruby-oci8 versionAs I am using and testing oracle_enhanced adapter just with ruby-oci8 2.0.3 then I have made this as precondition (if you use MRI 1.8 or 1.9). So if you haven’t yet upgraded to latest ruby-oci8 version then please do so before upgrading to oracle_enhanced 1.2.4.
JNDI connection supportIf you are using oracle_enhanced with JRuby then now you can also use JNDI database connections – please see this issue with comments to see some examples.
InstallAs always you can install Oracle enhanced adapter on any Ruby platform (Ruby 1.8.6 / 1.8.7 or Ruby 1.9.1 or JRuby) with
gem install activerecord-oracle_enhanced-adapter
If you have any questions please use discussion group or post comments here.
Screencasts of Oracle PL/SQL unit testing with Ruby
In my previous post I already described how to do Oracle PL/SQL unit testing with Ruby. I now have named it as ruby-plsql-spec unit testing framework. But probably you didn’t want to read such long text or maybe it seemed for you too difficult to try it out therefore I prepared two screencasts to show how easy and fun it is :)
Testing simple functionThe first example is based on classic BETWNSTR function example from utPLSQL tutorial.
Testing procedure that changes tables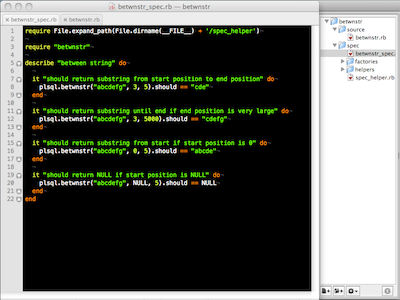
Second example is based on Quest Code Tester for Oracle testing tables demo screencast. So you can see both unit testing frameworks in action and can compare which you like better :)
Test driven development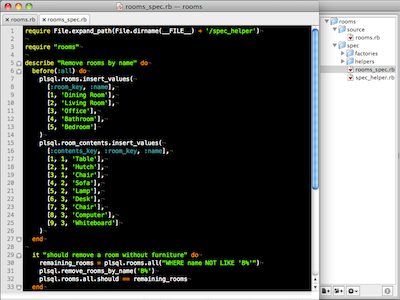
In both these screencasts I demonstrated how to do test driven development of PL/SQL
- Write little test of indended functionality before writing code.
- Write implementation of new functionality until this test passes and verify that all existing tests pass as well.
- Refactor implementation when needed and verify that all tests still pass.
From my experience TDD style of development can improve design and testability of code and also make you think before coding what you actually want to implement. But existing visual PL/SQL testing tools (Quest Code Tester, SQL Developer 2.1) do not quite support TDD style of development, they expect that there is already existing code that should be tested. Therefore this is one more ruby-plsql-spec advantage if you would like to do TDD style development in PL/SQL.
More informationExamples shown in screencasts are available in ruby-plsql-spec GitHub repository. And if you want to see more examples how to use ruby-plsql library for PL/SQL unit testing then you can take a look at ruby-plsql own RSpec tests or read previous posts about ruby-plsql.
ruby-plsql 0.4.1 - support for package variables, views, dbms_output and more
Based on feedback from using ruby-plsql for PL/SQL unit testing I have release new version 0.4.1 with several new features. You can read about initial versions of ruby-plsql in previous blog posts.
Package variablesWhen you call methods on plsql Ruby object then ruby-plsql uses all_procedures and all_arguments data dictionary views to search for procedures and their argument metadata to construct corresponding PL/SQL block for execution. Unfortunately there are no corresponding data dictionary views for package variables (sometimes called “global variables”) that are defined in package specifications. Therefore there was no support for package variables in initial ruby-plsql versions.
But as there is quite frequent need in PL/SQL tests to set and get package variable values then I created the following solution for accessing package variables. I assume that typically package variables are defined in one line in package specifications and I scan PL/SQL package specification source in all_source data dictionary view for potential package variable definitions.
As a result if you have the following example of package specification:
CREATE OR REPLACE PACKAGE test_package IS
varchar2_variable VARCHAR2(50);
number_variable NUMBER(15,2);
string_constant CONSTANT VARCHAR2(10) := 'constant';
integer_constant CONSTANT INTEGER := 1;
END;
then you can access these package variables in the same way as procedures:
plsql.test_package.varchar2_variable = 'test'
plsql.test_package.number_variable = 123
plsql.test_package.varchar2_variable # => 'test'
plsql.test_package.number_variable # => 123
plsql.test_package.string_constant # => 'constant'
plsql.test_package.integer_constant # => 1
Other basic data types as well as %ROWTYPE, %TYPE and schema object types are also supported for package variables. Only custom types defined in package specification are not supported (they are not supported for procedure parameters as well). As there are no data dictionary views for types defined in package specifications I don’t feel very enthusiastic about parsing package sources from all_source to get information about types defined inside packages :)
In previous post I described how to use ruby-plsql to perform basic table operations. Now these operations can be performed also with views:
plsql.view_name.insert
plsql.view_name.first
plsql.view_name.all
plsql.view_name.count
plsql.view_name.update
plsql.view_name.delete
Additional insert_values method is added for tables and views which can be helpful in PL/SQL tests for test data preparation. You can specify with more compact syntax which data you would like to insert into table or view:
plsql.employees.insert_values [:employee_id, :first_name, :last_name],
[1, 'First', 'Last'],
[2, 'Second', 'Last']
# => INSERT INTO employees (employee_id, first_name, last_name) VALUES (1, 'First', 'Last')
# => INSERT INTO employees (employee_id, first_name, last_name) VALUES (2, 'Second', 'Last')
If you use DBMS_OUTPUT.PUT_LINE in your PL/SQL procedures to log some debug messages then you can use plsql.dbms_output_stream= method to set where these messages should be displayed. Use the following to display DBMS_OUTPUT messages in standard output:
plsql.dbms_output_stream = STDOUT
Or write DBMS_OUTPUT messages to file:
plsql.dbms_output_stream = File.new('debug.log', 'w')
Procedures from SYS.STANDARD package can be called without sys.standard prefix, e.g.:
plsql.sysdate
plsql.substr('abcde',2,2)
See History.txt file for other new features and improvements and see RSpec tests in spec directory for more usage examples.
And also this version of ruby-plsql requires ruby-oci8 gem latest version 2.0.3 (if you use MRI / standard Ruby interpreter 1.8.6, 1.8.7 or 1.9.1) so please upgrade it as well if you do not have it. But as previously you can use ruby-plsql with JRuby and Oracle JDBC driver as well.
Oracle PL/SQL unit testing with Ruby
Unit testing and TDD (test driven development) practices are nowadays one of the key software development practices. It is especially important if you are doing agile software development in small iterations where you need to automate unit testing as much as possible, as you cannot do manual regression testing of all existing and new functionality at the end of each iteration.
In some languages (like Java, Ruby, Python, C# etc.) there is quite good tools and frameworks support for unit testing and as a result there is quite high testing culture among top developers in these communities. But unfortunately in PL/SQL community so far automated unit testing is not used very often. During recent Oracle OpenWorld conference in presentations about unit testing when it was asked who is doing automated unit testing then only few hands were raised.
Why is it so? And what are current options for doing automated PL/SQL unit testing?
The first unit testing framework for PL/SQL was utPLSQL which was created by Steven Feuerstein and based on API defined by many other xUnit style frameworks (like e.g. JUnit). But the issue with this approach was that PL/SQL syntax for tests was quite verbose and tests were not very readable (see example). As a result Steven stopped developing further utPLSQL and currently there are no other active maintainers of this project. There are some other alternative frameworks which tried to simplify writing tests in PL/SQL (OUnit, pl/unit, PLUTO etc.) but none of them are very actively used and maintained by PL/SQL community.
Because of the issues with utPLSQL Steven Feuerstein started development of graphical interface tool for PL/SQL unit testing which is now Quest Code Tester for Oracle. This tool is actively developed and maintained by Quest Software but there are several issues with it:
- It is a commercial tool and as a result it will not become widely accepted by all PL/SQL developers. There is also a freeware edition of it but the functionality of it is very limited.
- It is a graphical tool – it can help you with quick creation of simple tests but when you will need more complex logic you might get stuck that you cannot do it (or you need to do it again in plain PL/SQL and have the same issues as in utPLSQL).
- It stores tests in database repository – and it means that it might be hard to maintain unit tests in version control system like Subversion or Git.
And finally also Oracle started to do something in PL/SQL unit testing area and there is unit testing support in latest SQL Developer version 2.1 which currently still is in early adopter status. SQL Developer has very similar approach to Quest Code Tester – it is graphical tool which stores tests and test results in repository. So the benefit of SQL Developer over Quest Code Tester is that it is free :) But compared to Quest Code Tester it still has less features (e.g. currently not all complex data types are supported) and still is not released as final version and still has bugs.
Ruby as testing tool for PL/SQLAs you probably know I am quite big Ruby fan and always exploring new ways how to use Ruby to increase my productivity. And Ruby community has very high testing culture and has many good tools for testing support (I like and use RSpec testing framework). Therefore some time ago I started to use Ruby and RSpec also for testing PL/SQL code in our projects where we use Ruby on Rails on top of Oracle databases with existing PL/SQL business logic.
I have created ruby-plsql library which provides very easy API for calling PL/SQL procedures from Ruby and recent ruby-plsql version supports majority of PL/SQL data types.
So let’s start with with simple example how to use Ruby, RSpec and ruby-plsql to create PL/SQL procedure unit test. I will use BETWNSTR procedure example from utPLSQL examples:
CREATE OR REPLACE FUNCTION betwnstr (
string_in IN VARCHAR2,
start_in IN INTEGER,
end_in IN INTEGER
)
RETURN VARCHAR2
IS
l_start PLS_INTEGER := start_in;
BEGIN
IF l_start = 0
THEN
l_start := 1;
END IF;
RETURN (SUBSTR (string_in, l_start, end_in - l_start + 1));
END;
I took example tests from utPLSQL and wrote them in Ruby and RSpec:
describe "Between string" do
it "should be correct in normal case" do
plsql.betwnstr('abcdefg', 2, 5).should == 'bcde'
end
it "should be correct with zero start value" do
plsql.betwnstr('abcdefg', 0, 5).should == 'abcde'
end
it "should be correct with way big end value" do
plsql.betwnstr('abcdefg', 5, 500).should == 'efg'
end
it "should be correct with NULL string" do
plsql.betwnstr(nil, 5, 500).should be_nil
end
end
As you can see the tests are much shorter than in utPLSQL and are much more readable (also more readable than utPLSQL template which can be used to generate utPLSQL tests). And also you can create these tests faster than using GUI tools like Quest Code Tester or SQL Developer.
More complex exampleSecond more complex example I took from SQL Developer unit testing tutorial. We will create tests for PL/SQL procedure AWARD_BONUS:
CREATE OR REPLACE
PROCEDURE award_bonus (
emp_id NUMBER, sales_amt NUMBER) AS
commission REAL;
comm_missing EXCEPTION;
BEGIN
SELECT commission_pct INTO commission
FROM employees2
WHERE employee_id = emp_id;
IF commission IS NULL THEN
RAISE comm_missing;
ELSE
UPDATE employees2
SET salary = NVL(salary,0) + sales_amt*commission
WHERE employee_id = emp_id;
END IF;
END award_bonus;
I didn’t quite like the testing approach in SQL Developer unit testing tutorial – it was assuming that there is already specific data in employees2 table and was testing procedure using specific primary key values. As a result tests are not very readable as you cannot see all input data in the test case and tests could easily broke if initial data in table are different.
Therefore I created tests in Ruby using better approach that each test creates all necessary data that are needed for it and at the end of test there are no side effects which can influence other tests:
describe "Award bonus" do
include CustomerFactory
[ [1000, 1234.55, 0.10, 1123.46],
[nil, 1234.56, 0.10, 123.46],
[1000, 1234.54, 0.10, 1123.45]
].each do |salary, sales_amt, commission_pct, result|
it "should calculate base salary #{salary.inspect} + sales amount #{sales_amt} * " +
"commission percentage #{commission_pct} = salary #{result.inspect}" do
employee = create_employee(
:commission_pct => commission_pct,
:salary => salary
)
plsql.award_bonus(employee[:employee_id], sales_amt)
get_employee(employee[:employee_id])[:salary].should == result
end
end
end
I am generating three different tests with three different sets of input values. When you run these tests you see result:
Award bonus
- should calculate base salary 1000 + sales amount 1234.55 * commission percentage 0.1 = salary 1123.46
- should calculate base salary NULL + sales amount 1234.56 * commission percentage 0.1 = salary 123.46
- should calculate base salary 1000 + sales amount 1234.54 * commission percentage 0.1 = salary 1123.45
In addition I am using factory pattern (create_customer method) for test data creation. When using factory pattern you create test data creation method which will create valid new record with default field values. If in your test you need some specific non-default values then you can pass just these values as parameters to factory method. Factory pattern also helps in the maintenance of tests. For example, if new mandatory columns will be added to employees table then it will be necessary to add new fields with default values in factory methods and nothing should be changed in individual tests.
Here is example of employee factory implementation:
module EmployeeFactory
# Creates new employee with valid field values.
# Pass in parameters only field values that you want to override.
def create_employee(params)
employee = {
:employee_id => plsql.employees2_seq.nextval,
:last_name => 'Last',
:email => 'last@example.com',
:hire_date => Date.today,
:job_id => plsql.jobs.first[:job_id],
:commission_pct => nil,
:salary => nil
}.merge(params)
plsql.employees2.insert employee
get_employee employee[:employee_id]
end
# Select employee by primary key
def get_employee(employee_id)
plsql.employees2.first :employee_id => employee_id
end
end
And here is additional test for testing if procedure will raise exception if one input value is missing:
it "should raise ORA-06510 exception if commission percentage is missing" do
salary, sales_amt, commission_pct = 1000, 1234.55, nil
employee = create_employee(
:commission_pct => commission_pct,
:salary => salary
)
lambda do
plsql.award_bonus(employee[:employee_id], sales_amt)
end.should raise_error(/ORA-06510/)
end
I hope that if you are looking for PL/SQL unit testing tool then you will try this out :) You can get examples from this article together with necessary setup code and installation instructions at http://github.com/rsim/ruby-plsql-spec.
If you have any feedback or questions or feature suggestions then please comment.
More Oracle data types supported by ruby-plsql gem
I have just released ruby-plsql gem version 0.4.0 which provides many new features. You can read about initial versions of ruby-plsql in previous blog posts.
Oracle complex data type supportInitial versions of ruby-plsql supported just simple Oracle types like NUMBER, VARCHAR2, DATE, TIMESTAMP, CLOB, BLOB as PL/SQL procedure parameters. Now support for many more complex data types is added. See examples below how to call PL/SQL procedures with these complex data types.
Let’s assume you have PL/SQL procedure with PL/SQL record type parameter (which most typically will be in table%ROWTYPE format):
CREATE TABLE test_employees (
employee_id NUMBER(15),
first_name VARCHAR2(50),
last_name VARCHAR2(50),
hire_date DATE
);
CREATE OR REPLACE FUNCTION test_full_name (p_employee test_employees%ROWTYPE)
RETURN VARCHAR2 IS
BEGIN
RETURN p_employee.first_name || ' ' || p_employee.last_name;
END;
Then you can create Ruby Hash with record field values (specifying field names as Symbols), e.g.:
p_employee = {
:employee_id => 1,
:first_name => 'First',
:last_name => 'Last',
:hire_date => Time.local(2000,01,31)
}
and pass this Hash as a parameter which will be translated to PL/SQL record parameter by ruby-plsql:
plsql.test_full_name(p_employee) #=> "First Last"
# or
plsql.test_full_name(:p_employee => p_employee) #=> "First Last"
In the same way you can get PL/SQL function return values or output parameter values as Hash values.
Object typeIn similar way also object type parameters can be passed as Hash values. In this case also nested objects or nested collections of objects are supported:
CREATE OR REPLACE TYPE t_address AS OBJECT (
street VARCHAR2(50),
city VARCHAR2(50),
country VARCHAR2(50)
);
CREATE OR REPLACE TYPE t_phone AS OBJECT (
type VARCHAR2(10),
phone_number VARCHAR2(50)
);
CREATE OR REPLACE TYPE t_phones AS TABLE OF T_PHONE;
CREATE OR REPLACE TYPE t_employee AS OBJECT (
employee_id NUMBER(15),
first_name VARCHAR2(50),
last_name VARCHAR2(50),
hire_date DATE,
address t_address,
phones t_phones
);
CREATE OR REPLACE FUNCTION test_full_name (p_employee t_employee)
RETURN VARCHAR2
IS
BEGIN
RETURN p_employee.first_name || ' ' || p_employee.last_name;
END;
and from Ruby side you can call this PL/SQL function as:
p_employee = {
:employee_id => 1,
:first_name => 'First',
:last_name => 'Last',
:hire_date => Time.local(2000,01,31),
:address => {:street => 'Main street 1', :city => 'Riga', :country => 'Latvia'},
:phones => [{:type => 'mobile', :phone_number => '123456'}, {:type => 'home', :phone_number => '654321'}]
}
plsql.test_full_name(p_employee) #=> "First Last"
# or
plsql.test_full_name(:p_employee => p_employee) #=> "First Last"
And also object type return values and output parameters will be returned as Ruby Hash values (with nested Hashes or Arrays if necessary).
There is one limitation that these object types should be defined as database types and not just inside PL/SQL package definition. Unfortunately you cannot access type definitions inside packages from OCI or JDBC drivers and as a result cannot call such procedures from outside of PL/SQL.
TABLE and VARRAY collectionsTABLE and VARRAY collection parameters can be passed as Array values:
CREATE OR REPLACE TYPE t_numbers AS TABLE OF NUMBER(15);
CREATE OR REPLACE FUNCTION test_sum (p_numbers IN t_numbers)
RETURN NUMBER
IS
l_sum NUMBER(15) := 0;
BEGIN
IF p_numbers.COUNT > 0 THEN
FOR i IN p_numbers.FIRST..p_numbers.LAST LOOP
IF p_numbers.EXISTS(i) THEN
l_sum := l_sum + p_numbers(i);
END IF;
END LOOP;
RETURN l_sum;
ELSE
RETURN NULL;
END IF;
END;
And from Ruby side:
plsql.test_sum([1,2,3,4]) #=> 10
You can get also cursor return values from PL/SQL procedures:
CREATE OR REPLACE FUNCTION test_cursor
RETURN SYS_REFCURSOR
IS
l_cursor SYS_REFCURSOR;
BEGIN
OPEN l_cursor FOR
SELECT * FROM test_employees ORDER BY employee_id;
RETURN l_cursor;
END;
can be called from Ruby in the following way:
plsql.test_cursor do |cursor|
cursor.fetch #=> first row from test_employees will be returned
end
It is important to pass block parameter in this case and do something with returned cursor within this block as after ruby-plsql finishes PL/SQL procedure call it will close all open cursors and therefore it will not be possible to do anything with returned cursor outside this block.
It is also possible to use returned cursor as input parameter for another PL/SQL procedure:
CREATE OR REPLACE FUNCTION test_cursor_fetch(p_cursor SYS_REFCURSOR)
RETURN test_employees%ROWTYPE
IS
l_record test_employees%ROWTYPE;
BEGIN
FETCH p_cursor INTO l_record;
RETURN l_record;
END;
which can be called from Ruby
plsql.test_cursor do |cursor|
plsql.test_cursor_fetch(cursor) #=> first record as Hash
end
Note: you can pass cursors as PL/SQL procedure input parameter just when using ruby-plsql on MRI 1.8/1.9 with ruby-oci8, unfortunately I have not found a way how to pass cursor as input parameter when using JRuby and JDBC.
BOOLEANAnd finally you can use also PL/SQL BOOLEAN type – it is quite tricky data type as it is supported just by PL/SQL but not supported as data type in Oracle tables. But now you can also use it with ruby-plsql:
CREATE OR REPLACE FUNCTION test_boolean
( p_boolean BOOLEAN )
RETURN BOOLEAN
IS
BEGIN
RETURN p_boolean;
END;
plsql.test_boolean(true) #=> true
You can find more PL/SQL procedure call usage examples in ruby-plsql RSpec tests.
Table and sequence operationsI have been using and promoting to others ruby-plsql as PL/SQL procedure unit testing tool. As current PL/SQL unit testing tools are not so advanced and easy to use as Ruby unit testing tools then I like better to use Ruby testing tools (like RSpec) together with ruby-plsql to write short and easy to understand PL/SQL unit tests.
In unit tests in setup and teardown methods you typically need some easy way how to create some sample data in necessary tables as well as to validate resulting data in tables after test execution.
If you are Ruby on Rails developer then you probably will use ActiveRecord (or DataMapper) for manipulation of table data. But if Ruby is used just for unit tests then probably ActiveRecord would be too complicated for this task.
Therefore I added some basic table operations to ruby-plsql which might be useful e.g. in unit tests. Some syntax ideas for these table operations are coming from Sequel Ruby library.
INSERT# insert one record
employee = { :employee_id => 1, :first_name => 'First', :last_name => 'Last', :hire_date => Time.local(2000,01,31) }
plsql.employees.insert employee # INSERT INTO employees VALUES (1, 'First', 'Last', ...)
# insert many records
employees = [employee1, employee2, ... ] # array of many Hashes
plsql.employees.insert employees
If primary key values should be selected from sequence then you can get next sequence values with
plsql.employees_seq.nextval # SELECT employees_seq.NEXTVAL FROM dual
plsql.employees_seq.currval # SELECT employees_seq.CURRVAL FROM dual
# select one record
plsql.employees.first # SELECT * FROM employees
# fetch first row => {:employee_id => ..., :first_name => '...', ...}
plsql.employees.first(:employee_id => 1) # SELECT * FROM employees WHERE employee_id = 1
plsql.employees.first("WHERE employee_id = 1")
plsql.employees.first("WHERE employee_id = :employee_id", 1)
# select many records
plsql.employees.all # => [{...}, {...}, ...]
plsql.employees.all(:order_by => :employee_id)
plsql.employees.all("WHERE employee_id > :employee_id", 5)
# count records
plsql.employees.count # SELECT COUNT(*) FROM employees
plsql.employees.count("WHERE employee_id > :employee_id", 5)
# update records
plsql.employees.update(:first_name => 'Second', :where => {:employee_id => 1})
# UPDATE employees SET first_name = 'Second' WHERE employee_id = 1
# delete records
plsql.employees.delete(:employee_id => 1) # DELETE FROM employees WHERE employee_id = 1
Any other SELECT statement can be executed with
plsql.select :first, "SELECT ..."
# or
plsql.select :all, "SELECT ..."
or any other non-SELECT SQL statement can be executed with
plsql.execute "..."
And also COMMIT or ROLLBACK could be executed simply with
plsql.commit
plsql.rollback
I plan to write a separate blog post about how I recommend to create PL/SQL unit tests using Ruby and ruby-plsql and RSpec.
InstallAs always you can install latest version of ruby-plsql with
gem install ruby-plsql
Latest gem version is just on Gemcutter but now it should be available as default gem source for all Ruby installations.
And as always ruby-plsql is supported both on
- Ruby 1.8.6/1.8.7 or Ruby 1.9.1 with ruby-oci8 gem version 2.0.3 or later (some specific issues with complex data types will be fixed in later versions of ruby-oci8)
- JRuby 1.3/1.4 with Oracle JDBC driver (testing mainly with ojdbc14.jar but also ojdbc5.jar or ojdbc6.jar should be fine)
Please try it out and tell me if there are any issues with some particular data types or if there are still some unsupported PL/SQL data types that you would like to be supported in ruby-plsql. And also I encourage you to try ruby-plsql out for PL/SQL unit testing if you had no PL/SQL unit tests previously :)
Notes from Oracle OpenWorld 2009
Last week I participated in annual Oracle OpenWorld 2009 conference. There is quite wide coverage of conference in various web sites and blogs therefore I will write just some personal notes that I wanted to highlight.
For me the most value was meeting with different interesting people. At first thanks to Justin Kestelyn and all OTN team for Oracle community support. Oracle ACE dinner, bloggers meetup, OTN lounge and unconference were great places where to meet and discuss with interesting and active Oracle community members.
It was nice to meet Kuassi Mensah and Christopher Jones who are supporters of dynamic languages in Oracle and supporters of Ruby in particular. And also had interesting discussions with Rich Manalang – Ruby guru at Oracle, who is from the AppsLab team.
This year there were quite a few Sun people in the conference. Scott McNealy and James Gosling were doing keynotes. And I had interesting discussions with Arun Gupta and Tim Bray. BTW they have very good coverage of Oracle OpenWorld in their blogs (and also have a fresh look at it as they were for the first time here).
This year I did two unconference sessions – Oracle adapters for Ruby ORMs and Server Installation and Configuration with Chef. They were not very many attendees but at least it seemed that those who attended were satisfied with content :) This year Oracle Develop track was located quite far from unconference location and probably this also was a reason why there were not very many attendees (as my sessions were quite developer oriented).
TechnologiesHere is the list of Oracle products and technologies that I am interested in to spend some time investigating them:
- Fustion applications. I expected to hear more about next-generation of new Fusion applications but there was just short demo in the final keynote and a promise that they will be available sometime next year. User interface of new applications seems much better than for the current Oracle applications as well as current beta-testers are telling that usability is really much better. So I am really looking for trying them out.
- Application Development Framework (ADF). I am not a big fan of ADF drag-and-drop development style (that’s why I prefer Ruby on Rails :)) but as ADF is the main development platform for Fusion Applications then it will be necessary to use it if we would like to extend or customize Fusion applications. But what I would be really interested in is how to integrate JRuby with ADF – it would be nice to use ADF Faces UI components to get ADF look and feel, but to use JRuby for model & controller business logic development.
- SQL Developer unit testing. It was nice to see that finally Oracle has PL/SQL unit testing support in latest version of SQL Developer which hopefully will increase awareness about unit testing among PL/SQL developers. Steven Feuerstein gave very good “motivational” talk about unit testing during converence. But I still can’t decide if SQL Developer repository based unit tests is the best way how to do them. E.g. as all unit tests are stored in database repository you cannot version control them with Subversion or Git (which is the place where we store source of all PL/SQL procedures).
Therefore I plan to make enhancements to my ruby-plsql gem to support more PL/SQL data types and then it would be possible to write PL/SQL unit tests with Ruby and RSpec which would provide more compact syntax compared to current utPLSQL framework. Need to write blog post about it :) - Oracle Coherence. Recently I have heard many references to Oracle Coherence in-memory data grid which is often used to achieve high-scalability of web applications. Therefore I am thinking about Ruby client for Coherence and potentially using Coherence as cache solution in Ruby on Rails applications.
- Java in database. Recently I did some experiments with Java stored procedures in Oracle database – and the main reason is that it could provide integration of Oracle database with other systems that have Java based API. I already did experiments with creating Oracle client for RabbitMQ messaging system.
- Oracle object types. Many Oracle products (like Spatial Data option) are using Oracle object types for storing data. Currently these object data types are not supported by Ruby ActiveRecord and DataMapper ORMs. Need to do investigation how they could be supported and how to use Ruby e.g. for accessing spatial data in Oracle database.
And finally during Oracle OpenWorld annual Oracle Magazine Editors’ Choice Awards 2009 were published. And it was pleasant surprise for me that in this year I got Oracle Magazine’s Developer of the Year award. Thanks to Oracle people who promoted me and thanks for congratulations that I received :) Here is my picture and profile from the latest Oracle Magazine:

Photo © Delmi Alvarez / Getty Images
New features in ActiveRecord Oracle enhanced adapter version 1.2.2
During the last months many new features have been implemented for ActiveRecord Oracle enhanced adapter which are now included in Oracle enhanced adapter version 1.2.2. You can find full list in change history file, here I will tell about the main ones.
DocumentationNow Oracle enhanced adapter has improved RDoc documentation for all public methods. So you can go to RDoc documentation of installed gem or go and view published documentation on-line.
Schema definitionThere are many new features in schema definition methods that you can use in migration files:
- When you use
add_indexthen ActiveRecord is automatically generating index name using format index_table_name_on_column1_and_column2_… which previously could cause Oracle errors as Oracle identifiers should be up to 30 characters long. Now default index names are automatically shortened down to 30 or less characters (of course you can always use also:nameoption to specify shortened version by yourself). - Now adapter is ignoring
:limitoption for:textand:binarycolumns (as in Oracle you cannot specify limit for CLOB and BLOB data types). Previously it could cause errors if you tried to migrate Rails application from e.g. MySQL where:textand:binarycolumns could have:limitin schema definition. - If you define
:stringcolumn with*:limitoption then it will defineVARCHAR2column with size in characters and not in bytes (this makes difference if you use UTF-8 with language where one character might be stored as several bytes). This is expected behavior from ActiveRecord that you define maximum string size in UTF-8 characters. - Now you can use
add_foreign_keyandremove_foreign_keyto define foreign key constraints in migrations (see RDoc documentation for details). Syntax and some implemenatation for foreign key definition was taken from foreigner Rails plugin as well as some ideas taken from active_record_oracle_extensions plugin. add_foreign_keydefinitions will be also extracted in schema.rb byrake db:schema:dumptask. Therefore they will be also present in test database when you will recreate it from schema.rb file.- Foreign keys are also safe for loading of fixtures (in case you are still using them instead of factories :)).
disable_referential_integritymethod is implemented for Oracle enhanced adapter which is called by ActiveRecord before loading fixtures and which disables all currently active foreign key constraints during loading of fixtures. - You can use
add_synonymandremove_synonymto define database synonyms to other tables, views or sequences. add_synonym definitions will also be extracted in schema.rb file. - It is possible to create tables with primary key trigger. There will be no difference in terms how you would create new records in such table using ActiveRecord but in case you have also need to do direct INSERTs into the table then it will be easier as you can omit primary key from INSERT statement and primary key trigger will populate it automatically from corresponding sequence.
- ActiveRecord schema dumper is patched to work correctly when default table prefixes or suffixes are used – they are now removed from schema.rb dump to avoid duplicate prefixes and suffixes when recreating schema from schema.rb.
Some features which can support “weird” legacy database schemas:
- If you are using ActiveRecord with legacy schema which have tables with triggers that populate primary key triggers (and not using default Rails and Oracle enhanced adapter conventions) then you can use
set_sequence_name :autogeneratedin class definition to tell adapter to omit primary key value from INSERTs. - You can use ActiveRecord also with tables that you can access over database link. To do that you need to define local synonym to remote table (and also remote sequence if you want to insert records as well) and then use local synonym in set_table_name in class definition. Previously adapter could not get remote table columns, now it will get table columns also over database link.
But still you cannot specify remote table (like “table_name@db_link”) directly inset_table_nameas table_name will be used as column prefix in generated SQL statements where “@db_link” will not be valid syntax.
And when you define local synonyms then please use the newadd_synonymfeature :)
cursor_sharingoption default value is changed from “similar” to “force” – please read explanation in discussion group post what it is and why the new default value is recommended choice.- When using JRuby and JDBC you can set TNS_ADMIN environment variable to tnsnames.ora directory and then use TNS database alias in database.yml file (specify just database: option and remove host: option). This might be useful for more complex TNS connection definitions, e.g. connection to load balanced Oracle RAC.
- Adapter will not raise error if it cannot locate ojdbc14.jar* file. So either put it in $JRUBY_HOME/lib or ensure that it will be loaded by application server. Would love to hear feedback from people who are using this adapter with JRuby to find out if this behaves well now :)
- Now you can get PL/SQL debugging information into your ActiveRecord log file. Use
dbms_output.put_linein your PL/SQL procedures and functions (that are called from ActiveRecord models) and in your ActiveRecord model useconnection.enable_dbms_outputandconnection.disable_dbms_outputaround your database calls to get dbms_output logging information into ActiveRecord log file. But please use it just in development environment with debug log level as in production it would add too much overhead for each database call. And this feature also requires that you install ruby-plsql gem.
As you see this probably is the largest “point” release that I have had :) Thanks also to other contributors which patches were included in this release.
As always you can install Oracle enhanced adapter on any Ruby platform (Ruby 1.8.6 / 1.8.7 or Ruby 1.9.1 or JRuby) with
gem install activerecord-oracle_enhanced-adapter
If you have any questions please use discussion group or post comments here.
How to install Oracle Database 10g on Mac OS X Snow Leopard
 Oracle Database 10g is not yet officially supported on new Mac OS X 10.6 Snow Leopard but thanks to comments at my previous tutorial I managed to do Oracle 10g installation on fresh Mac OS X Snow Leopard.
Oracle Database 10g is not yet officially supported on new Mac OS X 10.6 Snow Leopard but thanks to comments at my previous tutorial I managed to do Oracle 10g installation on fresh Mac OS X Snow Leopard.
If you have upgraded from Leopard with Oracle 10g installation to Snow Leopard then most probably Oracle 10g should work fine and you should not do anything. These instructions are just for fresh installation of Snow Leopard.
And also please take in mind that Oracle 10g on Snow Leopard is not supported yet by Oracle and therefore please do not run critical production applications on it :)
So here are my updated Oracle 10g installation instructions for Snow Leopard.
Initial preparationAt first you need Xcode tools installed on your Mac OS X.
Then you need to create oracle user as well as increase default kernel parameters. Open Terminal and switch to root user:
sudo -i
Create oinstall group and oracle user (I used group and user number 600 to ensure that they do not collide with existing groups and users):
dscl . -create /groups/oinstall dscl . -append /groups/oinstall gid 600 dscl . -append /groups/oinstall passwd "*" dscl . -create /users/oracle dscl . -append /users/oracle uid 600 dscl . -append /users/oracle gid 600 dscl . -append /users/oracle shell /bin/bash dscl . -append /users/oracle home /Users/oracle dscl . -append /users/oracle realname "Oracle software owner" mkdir /Users/oracle chown oracle:oinstall /Users/oracle
Change password for oracle user:
passwd oracle
Change default kernel parameters:
vi /etc/sysctl.conf
and enter values recommended by Oracle:
kern.sysv.semmsl=87381
kern.sysv.semmns=87381
kern.sysv.semmni=87381
kern.sysv.semmnu=87381
kern.sysv.semume=10
kern.sysv.shmall=2097152
kern.sysv.shmmax=2197815296
kern.sysv.shmmni=4096
kern.maxfiles=65536
kern.maxfilesperproc=65536
net.inet.ip.portrange.first=1024
net.inet.ip.portrange.last=65000
kern.corefile=core
kern.maxproc=2068
kern.maxprocperuid=2068
Oracle DB installation scripts have reference to Java version 1.4.2 which is not present on Snow Leopard. The easiest way to fix it is to create symbolic link to newer version of Java:
sudo ln -s /System/Library/Frameworks/JavaVM.framework/Versions/1.5.0 /System/Library/Frameworks/JavaVM.framework/Versions/1.4.2
After this reboot your computer so that these new kernel parameters would be taken into effect.
After reboot you need to log in as new “Oracle software owner” user (as now Snow Leopard has stricter control for access to X11 display and therefore I couldn’t manage to start Oracle installation just from terminal).
Open Terminal application and set shell settings in .bash_profile
vi .bash_profile
and enter
export DISPLAY=:0.0
export ORACLE_BASE=$HOME
umask 022
ulimit -Hn 65536
ulimit -Sn 65536
As you see I prefer to install all Oracle related files under home directory of oracle user therefore I am setting ORACLE_BASE to home directory. And also include ulimit settings – I forgot to do this initially and got strange TNS service errors because of that.
Now execute this script so that these settings are applied to current shell:
. ./.bash_profile
Now download db.zip installation archive and place it somewhere and unzip it:
mkdir Install cd Install # download db.zip to this directory unzip db.zip cd db/Disk1
Now you are ready to start installation. In Snow Leopard you need to pass -J-d32 option to installation script to force to run Java in 32-bit mode as some native libraries are 32-bit:
./runInstaller -J-d32Installation
In installation wizard I selected the following options:
- Standard Edition – as I don’t need additional features of Enterprise Edition
- Install Software Only – we will need to do some fixes before database creation
In the middle of installation you will get error message “Error in invoking target ‘all_no_orcl ipc_g ihsodbc32’ …” (message truncated). Please do not press anything and switch to Terminal application.
cd ~/oracle/product/10.2.0/db_1/rdbms/lib vi ins_rdbms.mk
and in this file you need to search for line containing HSODBC_LINKLINE (in vi enter /HSODBC_LINKLINE) and comment out this line with putting @# @ in front of it:
# $(HSODBC_LINKLINE)
and save changed file.
In this way we disable failing compilation of library which is anyway not needed for our Oracle DB installation.
After that you can switch back to Oracle installation application and press Retry.
At the end of installation you will be instructed to run one shell script from root. To do that open new tab in Terminal and execute (substitute “username” with your login name):
su - username sudo /Users/oracle/oracle/product/10.2.0/db_1/root.sh
Hopefully installation will complete successfully.
Creation of databaseSwitch back to Terminal tab with oracle user and add the following lines to .bash_profile of oracle user:
export ORACLE_HOME=/Users/oracle/oracle/product/10.2.0/db_1
export DYLD_LIBRARY_PATH=$ORACLE_HOME/lib
export ORACLE_SID=orcl
PATH=$PATH:$ORACLE_HOME/bin
and execute it
. ~/.bash_profile
Now you need to modify $ORACLE_HOME/jdk/bin/java script and change ...java -Xbootclasspath... to ...java -d32 -Xbootclasspath.... This is necessary to force netca and dbca utilities to run in 32-bit mode.
Now you need to do the major installation hack :) Unfortunately the main oracle executable binary when compiled under Snow Leopard is giving core dumps when starting Oracle database and currently the only way how I managed to fix it is to replace this executable file with the one which was compiled previously under Leopard. So you need to download it in trust me that it is correct :)
cd $ORACLE_HOME/bin curl -O http://rayapps.com/downloads/oracle_se.zip unzip oracle_se.zip chmod ug+s oracle rm oracle_se.zip
(If you installed Oracle Enterprise Edition then please substitute oracle_se.zip with oracle_ee.zip)
Now you can run Network Configuration Assistant
netca
and select all default options to create listener and wait until you get confirmation message that listener is configured and started.
After that you can run Database Configuration Assistant
dbca
and select
- Create a Database
- General Purpose
- Specify orcl as Global Database Name and SID (or set it to something different if you need)
- Specify password for SYS and SYSTEM users
- I selected also Sample Schemas
- and in Character Sets I selected Use Unicode (AL32UTF8)
At the end of installation I tried to use Password Management to unlock additional schemas but it didn’t work – so you need to unlock other sample schemas if needed using sqlplus.
At the end of installation verify if you can connect to newly created database
sqlplus system@orcl
I hope that my fixes will help you as well and you will be able to connect to database.
If you want to unlock other sample users then do it from sqlplus, e.g.:
alter user hr account unlock identified by hr;
Further instructions are the same as for Leopard and there are no more changes.
Change listener to listen on localhostAs I need this Oracle database just as local development database on my computer then I want to change the listener so that it would listen just on localhost port 1521:
vi $ORACLE_HOME/network/admin/listener.ora
and change it to:
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /Users/oracle/oracle/product/10.2.0/db_1)
(PROGRAM = extproc)
)
(SID_DESC =
(SID_NAME = orcl)
(ORACLE_HOME = /Users/oracle/oracle/product/10.2.0/db_1)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC0))
)
)
Then also change ORCL alias definition in $ORACLE_HOME/network/admin/tnsnames.ora to:
ORCL =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = localhost)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orcl)
)
)
After this change restart listener and try to connect with sqlplus to verify that these changes are successful.
Automatic startup of Oracle databaseIf you want that Oracle database is started automatically when your computer is booted then you need to create the following startup script. Start terminal and switch to root.
At first edit /etc/oratab and change N to Y at the end of line for ORCL database – this will be used by dbstart utility to find which databases should be started automatically.
Then create startup script for Oracle database:
mkdir /Library/StartupItems/Oracle cd /Library/StartupItems/Oracle vi Oracle
and enter the following:
#!/bin/sh
# Suppress the annoying "$1: unbound variable" error when no option
# was given
if [ -z $1 ] ; then
echo "Usage: $0 [start|stop|restart] "
exit 1
fi
# source the common startup script
. /etc/rc.common
# Change the value of ORACLE_HOME to specify the correct Oracle home
# directory for the installation
ORACLE_HOME=/Users/oracle/oracle/product/10.2.0/db_1
DYLD_LIBRARY_PATH=$ORACLE_HOME/lib
export ORACLE_HOME DYLD_LIBRARY_PATH
# change the value of ORACLE to the login name of the
# oracle owner at your site
ORACLE=oracle
PATH=$PATH:$ORACLE_HOME/bin
# Set shell limits for the Oracle Database
ulimit -Hu 2068
ulimit -Su 2068
ulimit -Hn 65536
ulimit -Sn 65536
StartService()
{
ConsoleMessage "Starting Oracle Databases"
su $ORACLE -c "$ORACLE_HOME/bin/dbstart $ORACLE_HOME"
}
StopService()
{
ConsoleMessage "Stopping Oracle Databases"
su $ORACLE -c "$ORACLE_HOME/bin/dbshut $ORACLE_HOME"
}
RestartService()
{
StopService
StartService
}
RunService "$1"
and then make this script executable
chmod a+x Oracle
and in addition create properties file:
vi StartupParameters.plist
with the following contents:
{
Description = "Oracle Database Startup";
Provides = ("Oracle Database");
Requires = ("Disks");
OrderPreference = "None";
}
Now you can verify that these scripts are working. Open new terminal and try
sudo /Library/StartupItems/Oracle/Oracle stop
to stop the database and
sudo /Library/StartupItems/Oracle/Oracle start
to start again the database. And later you can reboot your computer also to verify that Oracle database will be started automatically.
Hide oracle user from login windowAfter computer reboot you probably noticed that now you got oracle user in initial login window. To get rid of it execute this from terminal:
sudo defaults write /Library/Preferences/com.apple.loginwindow HiddenUsersList -array-add oracleWhat next?
Now when you have Oracle database installed you would need some development tools that you could use to access the database. Here are some links:
- Oracle SQL Developer – free Oracle GUI tool that supports Mac OS X as well
- If you would like to use Ruby and Ruby on Rails then check out my tutorial how to setup Ruby and Oracle client on Snow Leopard
Please comment if you find any issues with Oracle Database 10g installation on Snow Leopard using this tutorial.