

Yann Neuhaus

Oracle Database 26ai Client and SQLNET.EXPIRE_TIME
We have been facing one issue at one of our customer where the Oracle Client connections remained opened for days blocking some avaloq JobNetz. We have been doing some tests and we could fortunately find a solution resolving the problem thanks to Oracle Database 26ai supporting now SQLNET.EXPIRE_TIME on the client side. Through this blog, I would like to share with you the problem and then the tests that have been performed helping us to conclude to a solution.
Environment and problem descriptionAt our customer environment, client connection run from the HelperVM does not establish database connections directly to the database listener. The connection goes through the Network Load Balancer, so called NLB, and the Oracle Connection Manager, so called CMAN.
The diagram below describes the database connection establishment process.
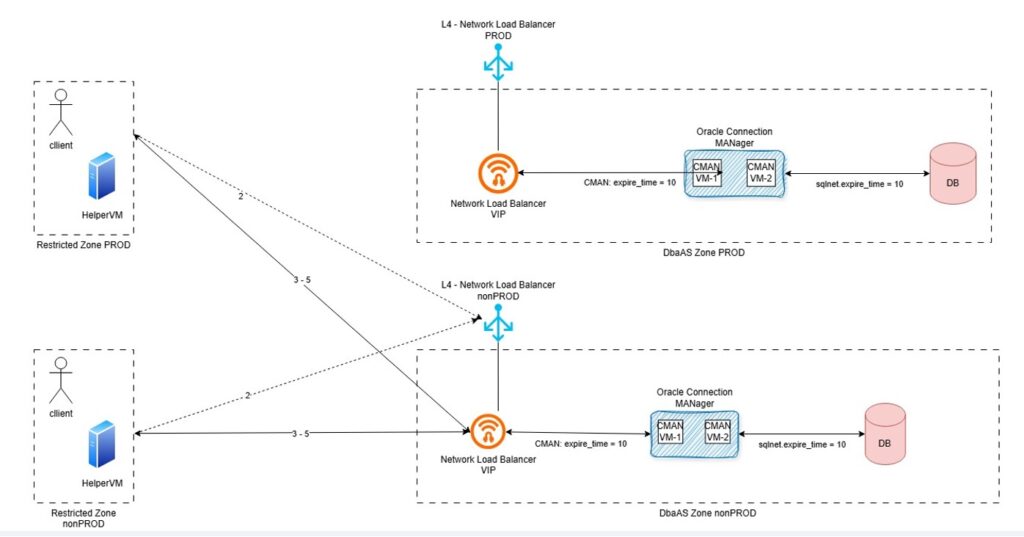
This is how it works.
- 1 – Client seeks for connection details (ideally, get the connection details from Oracle Directory Service)
- 2 – Client connects to Network Load Balancer
- 3 – Network Load Balancer “forwards” the request to Oracle Connection MANager using Virtual IP
- 4 – Oracle Connection MANager acts as a rule-based firewall and ensure the database target service is running on the “white listed targets (next_hop)
- 5 – Oracle Database establish connectivity upon credential validate (Oracle listener acts in between). The listener hands the connection over to the Oracle CMAN gateway process, which passes data back and forth between the client and the db-server and collects statistics.
We could observed per reverse engineering technique that the TCP connection established between the Oracle client and Oracle CMAN works upon Network Load Balancer Virtual IP.
The Network Load Balancer needs for Session persistence “statefullnes” to be enabled. This means that once the connection is established, the NLB “remembers” established connections and fails them over in case of planned downtime.
We have been facing some broken connectivity issue. Checking Linux socket connection with linux ss command (# ss -nop) we could see TCP connection hungs between client and NLB virtual IP (CNAME DNS entry). On CMAN and DB-Server side the connection were already cleaned up as per Dead Connection Detection configuration. We can see in the diagram that EXPIRE_TIME is setup with a value of 10 minutes on the CMAN side and the listener configuration from the VM Cluster database.
The connection was still opened on the client side because:
- The client was still waiting on a result which would never come
- TCP connection to the NLB Virtual IP was still existing albeit closed with the CMAN and database listener
- TCP connection to the NLB would remain alive for days
The problem is that by default Oracle client does not enable TCP Keepalive, which is an expected behavior. Oracle expects the keepalive to be set on the server side. The “Dead Connection Detection” will then be enforced for all clients.
TCP Keepalive should then be managed in our case on the client side. And we are currently running Oracle 19c Client.
EXPIRE_TIME handled on Oracle 19c ClientOracle 19c client does not come with SQLNET.EXPIRE_TIME aka “Oracle dead connection detection”, unless hacked over connection string hidden (unsupported) parameter ENABLE_BROKEN.
See following blog from a one of my former colleagues:
sqlnet-expire_time and enablebroken
And what about Oracle 26ai Client? Let’s do some test…
Installation of Oracle 26ai ClientOn the lab, I will use the VM called bastion to act as the client. The bastion has already an Oracle 19c Client installed. I’m going to installed new Oracle 26ai Client on it.
First we need to download the client version, which can be done from the following website:
https://www.oracle.com/database/technologies/oracle26ai-linux-downloads.html
I will install Oracle 26ai Client version in /opt/oracle.
[root@bastion oracle]# pwd /opt/oracle [root@bastion oracle]# ls -ld client* drwxr-xr-x. 52 oracle oinstall 4096 Jun 6 2024 client19c drwxr-xr-x. 47 oracle oinstall 4096 Nov 11 2025 client_21c [root@bastion oracle]#
I will first unzip the downloaded oracle zip file.
[oracle@bastion oracle]$ pwd /opt/oracle [oracle@bastion oracle]$ unzip -q LINUX.X64_2326100_client.zip
I will then rename the client installation directory:
[oracle@bastion oracle]$ ls -ld client* drwxr-xr-x. 5 oracle oinstall 90 Jan 17 13:59 client drwxr-xr-x. 52 oracle oinstall 4096 Jun 6 2024 client19c drwxr-xr-x. 47 oracle oinstall 4096 Nov 11 2025 client_21c [oracle@bastion oracle]$ mv client client26ai [oracle@bastion oracle]$ [oracle@bastion oracle]$ ls -ld client* drwxr-xr-x. 52 oracle oinstall 4096 Jun 6 2024 client19c drwxr-xr-x. 47 oracle oinstall 4096 Nov 11 2025 client_21c drwxr-xr-x. 5 oracle oinstall 90 Jan 17 13:59 client26ai [oracle@bastion oracle]$
I will prepare the response file for the command line installation.
[oracle@bastion client26ai]$ cp -p response/client_install.rsp response/client_install_custom.rsp [oracle@bastion client26ai]$ vi response/client_install_custom.rsp [oracle@bastion client26ai]$ diff response/client_install.rsp response/client_install_custom.rsp 22c22 UNIX_GROUP_NAME=oinstall 26c26 INVENTORY_LOCATION=/opt/oracle/oraInventory 30c30 ORACLE_HOME=/opt/oracle/client26ai 34c34 ORACLE_BASE=/opt/oracle 48c48 oracle.install.client.installType=Administrator [oracle@bastion client26ai]$
And I will run the Oracle 26ai Client installation.
[oracle@bastion client26ai]$ pwd /opt/oracle/client26ai [oracle@bastion client26ai]$ ls -ltrh total 24K -rwxrwx---. 1 oracle oinstall 500 Feb 6 2013 welcome.html -rwxr-xr-x. 1 oracle oinstall 8.7K Jan 17 12:38 runInstaller drwxr-xr-x. 4 oracle oinstall 4.0K Jan 17 12:38 install drwxr-xr-x. 15 oracle oinstall 4.0K Jan 17 13:37 stage drwxr-xr-x. 2 oracle oinstall 82 May 21 16:13 response [oracle@bastion client26ai]$ ./runInstaller -silent -responseFile /opt/oracle/client26ai/response/client_install_custom.rsp Starting Oracle Universal Installer... Checking Temp space: must be greater than 415 MB. Actual 5025 MB Passed Checking swap space: must be greater than 150 MB. Actual 4095 MB Passed Preparing to launch Oracle Universal Installer from /tmp/OraInstall2026-05-21_04-16-17PM. Please wait ... [WARNING] [INS-32016] The selected Oracle home contains directories or files. ACTION: To start with an empty Oracle home, either remove its contents or specify a different location. ********************************************* Package: compat-openssl10-1.0.2 (x86_64): This is a prerequisite condition to test whether the package "compat-openssl10-1.0.2 (x86_64)" is available on the system. Severity: IGNORABLE Overall status: VERIFICATION_FAILED Error message: PRVF-7532 : Package "compat-openssl10(x86_64)-1.0.2" is missing on node "bastion" Cause: A required package is either not installed or, if the package is a kernel module, is not loaded on the specified node. Action: Ensure that the required package is installed and available. ----------------------------------------------- [WARNING] [INS-13014] Target environment does not meet some optional requirements. CAUSE: Some of the optional prerequisites are not met. See logs for details. /opt/oraInventory/logs/installActions2026-05-21_04-16-17PM.log. ACTION: Identify the list of failed prerequisite checks from the log: /opt/oraInventory/logs/installActions2026-05-21_04-16-17PM.log. Then either from the log file or from installation manual find the appropriate configuration to meet the prerequisites and fix it manually. The response file for this session can be found at: /opt/oracle/client26ai/install/response/client_2026-05-21_04-16-17PM.rsp You can find the log of this install session at: /opt/oraInventory/logs/installActions2026-05-21_04-16-17PM.log The installation of Oracle Client 26ai was successful. Please check '/opt/oraInventory/logs/silentInstall2026-05-21_04-16-17PM.log' for more details. Successfully Setup Software with warning(s). [INS-10115] All configuration tools were previously ran successfully, no further configuration is required. [oracle@bastion client26ai]$
And the Oracle 26ai Client is now installed.
Prepare target databaseI will create a user on the target lab PDB, named TESTZ_TMR_003I, in order to establish sqlplus connection and test the EXPIRE_TIME configuration.
I will create a user test01 and grant the connect permissions.
[oracle@svl-oat ~]$ echo $ORACLE_SID
CDB001I
[oracle@svl-oat ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Thu May 21 14:30:39 2026
Version 19.23.0.0.0
Copyright (c) 1982, 2023, Oracle. All rights reserved.
Connected to:
Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production
Version 19.23.0.0.0
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 TESTZ_APP_006I READ WRITE NO
4 RCLON_TMR_003I MOUNTED
5 RCLON_TMR_002I MOUNTED
6 RCLON_TMR_001I MOUNTED
7 CLONZ_TMR_002I MOUNTED
8 TESTZ_TMR_003I READ WRITE NO
10 TESTZ_APP_004I READ WRITE NO
11 CLONZ_APP_001I READ WRITE NO
12 RCLON_APP_003I READ WRITE NO
SQL> alter session set container=TESTZ_TMR_003I;
Session altered.
SQL> create user test01 identified by "test_expire";
User created.
SQL> grant connect to test01;
Grant succeeded.
SQL>
Test connection with Oracle 26ai Client
I will first set the ORACLE_HOME variable on the appropriate client directory.
[oracle@bastion client26ai]$ echo $ORACLE_HOME /opt/oracle/client19c [oracle@bastion client26ai]$ export ORACLE_HOME=/opt/oracle/client26ai [oracle@bastion client26ai]$ echo $ORACLE_HOME /opt/oracle/client26ai [oracle@bastion client26ai]$
I will update the PATH variable to get tnsping and sqlplus binary from the appropriate Oracle 26ai Client.
[oracle@bastion client26ai]$ echo $PATH /usr/share/Modules/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/oracle/client19c/bin:/opt/oracle/sqlcl-24.1.0.087.0929//bin [oracle@bastion client26ai]$ export PATH=/opt/oracle/client26ai/bin [oracle@bastion client26ai]$ echo $PATH /opt/oracle/client26ai/bin [oracle@bastion client26ai]$
I will check that the appropriate tnsping and sqlplus is taken.
[oracle@bastion client26ai]$ which sqlplus /opt/oracle/client26ai/bin/sqlplus [oracle@bastion client26ai]$ which tnsping /opt/oracle/client26ai/bin/tnsping
I checked that the connection to target PDB is working.
[oracle@bastion ~]$ tnsping svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com TNS Ping Utility for Linux: Version 23.26.1.0.0 - Production on 21-MAY-2026 16:28:56 Copyright (c) 1997, 2026, Oracle. All rights reserved. Used parameter files: /opt/oracle/client19c/network/admin/sqlnet.ora Used EZCONNECT adapter to resolve the alias Attempting to contact (DESCRIPTION=(CONNECT_DATA=(SERVICE_NAME=testz_tmr_003i.db.jewlab.oraclevcn.com))(ADDRESS=(PROTOCOL=tcp)(HOST=X.X.1.135)(PORT=1521))) OK (0 msec) [oracle@bastion ~]$
The TNS_ADMIN used is from the 19c Oracle client directory, which is absolutely not a problem.
[oracle@bastion ~]$ echo $TNS_ADMIN /opt/oracle/client19c/network/admin [oracle@bastion ~]$Test sqlplus connection with Oracle 26ai Client
As I can see on my client side, I do not have any sqlplus connection running right now.
[opc@bastion ~]$ ss -nop | grep 1521 [opc@bastion ~]$
I will generate a sqlplus connection.
[oracle@bastion client26ai]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 23.26.1.0.0 - Production on Thu May 21 16:34:23 2026 Version 23.26.1.0.0 Copyright (c) 1982, 2025, Oracle. All rights reserved. Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
And I can see that I have got a sqlplus connection with no timer/keepalive.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:51404 X.X.1.135:1521 [opc@bastion ~]$
I will now configure Oracle Dead Connection Detection with SQLNET.EXPIRE_TIME parameter set in the client sqlnet.ora with a value of 1 minute.
[oracle@bastion ~]$ cd $TNS_ADMIN [oracle@bastion admin]$ /usr/bin/grep -i expire sqlnet.ora [oracle@bastion admin]$ [oracle@bastion admin]$ /usr/bin/vi sqlnet.ora [oracle@bastion admin]$ /usr/bin/grep -i expire sqlnet.ora SQLNET.EXPIRE_TIME=1 [oracle@bastion admin]$
I will run a new sqlplus connection.
[oracle@bastion admin]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 23.26.1.0.0 - Production on Thu May 21 16:41:06 2026 Version 23.26.1.0.0 Copyright (c) 1982, 2025, Oracle. All rights reserved. Last Successful login time: Thu May 21 2026 16:34:23 +02:00 Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
I can now see that I have got a connection configured with a timer and keep alive remaining of 38s.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:62868 X.X.1.135:1521 timer:(keepalive,38sec,0) [opc@bastion ~]$
Let’s configure the EXPIRE_TIME with a value of 15 minutes.
[oracle@bastion admin]$ /usr/bin/vi sqlnet.ora [oracle@bastion admin]$ /usr/bin/grep -i expire sqlnet.ora SQLNET.EXPIRE_TIME=15
I run a new sqlplus connection.
[oracle@bastion admin]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 23.26.1.0.0 - Production on Thu May 21 16:43:25 2026 Version 23.26.1.0.0 Copyright (c) 1982, 2025, Oracle. All rights reserved. Last Successful login time: Thu May 21 2026 16:42:29 +02:00 Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
And I now have got a connection configured with a timer and keep alive remaining of 14min.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:60630 X.X.1.135:1521 timer:(keepalive,14min,0) [opc@bastion ~]$
So, all good Oracle 26ai Client is supporting Dead Connection Detection with SQLNET.EXPIRE_TIME parameter.
Let’s test it with Oracle 19c ClientWe can easily confirm again that Oracle 19c Client does not support Dead Connection Detection on the client side.
Let’s move back to Oracle 19c Client home.
[oracle@bastion admin]$ export PATH=/opt/oracle/client19c/bin [oracle@bastion admin]$ which sqlplus /opt/oracle/client19c/bin/sqlplus
Run a sqlplus connection.
[oracle@bastion admin]$ sqlplus test01/test_expire@svl-oat:1521/testz_tmr_003i.db.jewlab.oraclevcn.com SQL*Plus: Release 19.0.0.0.0 - Production on Thu May 21 16:48:09 2026 Version 19.3.0.0.0 Copyright (c) 1982, 2019, Oracle. All rights reserved. Last Successful login time: Thu May 21 2026 16:46:07 +02:00 Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.23.0.0.0 SQL>
And check connection configuration.
[opc@bastion ~]$ ss -nop | grep 1521 tcp ESTAB 0 0 X.X.0.89:64078 X.X.1.135:1521 [opc@bastion ~]$
There is no timer/keepalive handled with Oracle 19c Client.
To wrap up…Oracle Database 26ai Client is now supporting Dead Connection Detection on the client side. For our customer configuration this will help the client to check every X minutes (EXPIRE_TIME configured value) for Dead Connection. So if the CMAN and listener connections have already died and if for any reason the Network Load Balancer is still keeping the connection with the client, the client will close the connection after X minutes.
L’article Oracle Database 26ai Client and SQLNET.EXPIRE_TIME est apparu en premier sur dbi Blog.
Azure Bootcamp Switzerland 2026 edition
Today I attended the Azure Bootcamp Switzerland event in Bern. Here is a summary of what I saw and what I learned in the sessions.

The opening keynote was about Azure Sovereign Architecture where the presenter gave us an update on the current Azure/Microsoft projects. We also had an explanation on how sovereignty works.
Then I joined a session titled “Time Bombs In Entra ID – How Well Are Your Entra ID Apps Managed?”. The speaker explained to us how Azure App registration and service principal really work. He also gave us some advice on best practices when using this kind of Azure/Entra resource.
Before the lunch break I joined a session on how some architects resolved the “multiple teams needed to deploy something” problem. They automated the deployment with CI/CD and Terragrunt. They did a demo on how they use their code and how they make infrastructure changes with it.
After the lunch, I chose to go in a more network oriented presentation. The topic was how to get rid of VPN by using an Azure service called Global Secure Access. Even though I’m not convinced that we can get rid of VPNs, this option could be something for highly Microsoft infrastructure as it uses the Microsoft backbone for all the network routing.

The last two sessions I attended sessions on Azure Policy. The topics were first using code to deploy Azure policies, as it’s a better way to have them identical in multiple environments and as it as also faster than using the Azure interface, which is slow. The second one was about using conditional access as safer alternative for securing Azure tenants with policies. This method is quite interesting but requires a paid version of Entra to be activated.

Finally, for the closing keynote, we had a presentation about an application developed by a Swiss company that helps emergency services coordinate. It’s allowing call centers to locate and contact closest to scene savers and organize their deployment.

Once again, I’m glad that could attend this event. I learned quite a bunch of things and could also refresh my memory on some other topics. The sessions are long enough to detail a topic and the speakers are always performing well.
L’article Azure Bootcamp Switzerland 2026 edition est apparu en premier sur dbi Blog.
Reduce downtime when refreshing your non-production databases using Multitenant
You probably refresh your non-production Oracle databases with production data from time to time or on a regular basis. Without Multitenant, the most common procedure to do this refresh is a DUPLICATE FROM BACKUP with RMAN. The drawback is the unavailability of the database being refreshed during the DUPLICATE. You first need to remove the old version of the database, then start the DUPLICATE and wait until it’s finished. If you have Enterprise Edition and enough CPU, you can lower the time needed for the refresh by allocating a sufficient number of channels. But with a small number of CPU (which is normal for a non-production server), or eventually with Standard Edition (single channel RMAN operations only), a multi-TB database refresh can take several hours to complete. And if it fails for some reasons, you need to retry the refresh, extending even more the downtime.
Multitenant brought new possibilities for refreshing a database, and my favorite one is a CREATE PLUGGABLE DATABASE from a database link (DB link). It’s dead easy compared to a DUPLICATE FROM BACKUP on a non-CDB database. And you can lower the downtime to the very minimum. Here is how I did this for several projects.
How to lower the downtime to the minimum when refreshing a non-production PDB?You probably know that one of the advantage of a pluggable database is the easiness of changing its name. You just need to stop the PDB, rename it, and restart it. You can then use this technique to refresh a PDB under a temporary name and let the actual PDB available during the refresh. Once the refresh is finished, drop or rename the actual PDB, and rename the newest one to its target name. Even if your refresh takes hours, your downtime is limited to a couple of seconds/minutes.
Step 1: add an additional grant for source PDB’s administratorThe PDB administrator on the source database must have the CREATE PLUGGABLE DATABASE privilege:
ssh oracle@p01-srv-ora
. oraenv <<< P19PMT
sqlplus / as sysdba
Alter session set container=P19_ERP;
grant create pluggable database to SYSERP;
exitThe target server must have a TNS entry to the source PDB (production). If your source PDB and its container are protected by a Data Guard configuration, dont’t forget to add both addresses:
ssh root@t01-srv-ora
su – oracle
. oraenv <<< D19PMT
vi $ORACLE_HOME/network/admin/tnsnames.ora
…
P19_ERP =
(DESCRIPTION =
(LOAD_BALANCE = OFF)
(FAILOVER = ON)
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = p01-srv-ora)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = p02-srv-ora)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = P19_ERP)
)
)
tnsping P19_ERP
…
A DB link is required on the target container:
ssh root@t01-srv-ora
su – oracle
. oraenv <<< D19PMT
sqlplus / as sysdba
CREATE DATABASE LINK P19_ERP CONNECT TO SYSERP IDENTIFIED BY "*************" USING 'P19_ERP';
select count(*) from dual@P19_ERP;
COUNT(*)
----------
1
exitBasically, refresh will have 5 main tasks:
- create a new PDB with a temporary name _NEW on the target container from the source PDB
- start the new PDB for its correct registration in the container
- run an optional script for modifying production data (masking, disabling tasks, …)
- stop and rename the current PDB to _OLD, then start it again
- stop and rename the new PDB to its target name and start it again
Task 2 is needed because you cannot rename a PDB immediately after creation. You first need to open it, then close it for being able to change its name.
Let’s create 2 scripts on the target server, one shell script and one SQL script:
vi /home/oracle/scripts/refresh_D19_ERP.sh
#!/bin/bash
export ORACLE_SID=D19PMT
export REFRESH_LOG=/home/oracle/scripts/log/refresh_D19_ERP_`date +%d_%m_%Y-%H_%M_%S`.log
export ORACLE_HOME=`cat /etc/oratab | grep $ORACLE_SID | awk -F ':' '{print $2;}'`
date >> $REFRESH_LOG
$ORACLE_HOME/bin/sqlplus / as sysdba @/home/oracle/scripts/refresh_D19_ERP.sql >> $REFRESH_LOG
date >> $REFRESH_LOG
exit 0
vi /home/oracle/scripts/refresh_D19_ERP.sql
set timing on
show pdbs
alter pluggable database D19_ERP_OLD close immediate;
Drop pluggable database D19_ERP_OLD including datafiles;
show pdbs
create pluggable database D19_ERP_NEW from P19_ERP@P19_ERP ;
show pdbs
alter pluggable database D19_ERP_NEW open;
show pdbs
alter session set container=D19_ERP_NEW;
@/home/oracle/scripts/post_refresh_D19_ERP.sql
alter session set container=CDB$ROOT;
alter pluggable database D19_ERP close immediate;
alter pluggable database D19_ERP rename global_name to D19_ERP_OLD;
alter pluggable database D19_ERP_OLD open;
show pdbs
alter pluggable database D19_ERP_NEW close immediate;
alter pluggable database D19_ERP_NEW rename global_name to D19_ERP;
Alter pluggable database D19_ERP open;
Alter pluggable database D19_ERP save state;
show pdbs
exitIt does the job, although these are very basic scripts: further controls could be added to trap errors, manage services, and so on.
Step 5 : schedule the refreshScheduling can be done through the crontab, for example every evening at 11.30PM:
crontab -l | grep D19_ERP | grep refresh
30 23 * * * sh /home/oracle/scripts/refresh_D19_ERP.sh
This is definitely a smart solution as soon as you have enough space on disk to have 2 copies of the PDB. It’s quite reliable and ticks all the boxes where I deployed these scripts.
L’article Reduce downtime when refreshing your non-production databases using Multitenant est apparu en premier sur dbi Blog.
OGG-08502 Path not found error from OGG Receiver Service
Recently, after a successful migration to GoldenGate 26ai, a customer complained that he was seeing a lot of the following error in the ggserr.log file of a GoldenGate deployment (I replaced the names for the purpose of this blog).
2026-05-18T14:32:35.948+0200 ERROR OGG-08502. Oracle GoldenGate Receiver Service for Oracle: Path path21 not found.More precisely, in that case, path21 is a distribution path sending trail files from deployment ogg_test_02 to ogg_test_01. And the error shown above appeared in the log file of the ogg_test_01 deployment.
While this error did not seem to indicate any operational issue in the replication, after checking on multiple environments, I confirmed that it appears everywhere. So what is happening exactly ?
If you get this error and do not know where it comes from, log in to the web UI of the affected deployment, and go to the Receiver Service Paths tab. You should see a list of the distribution paths that are connecting to your deployments. The example below shows the path21 that is mentioned in the error.
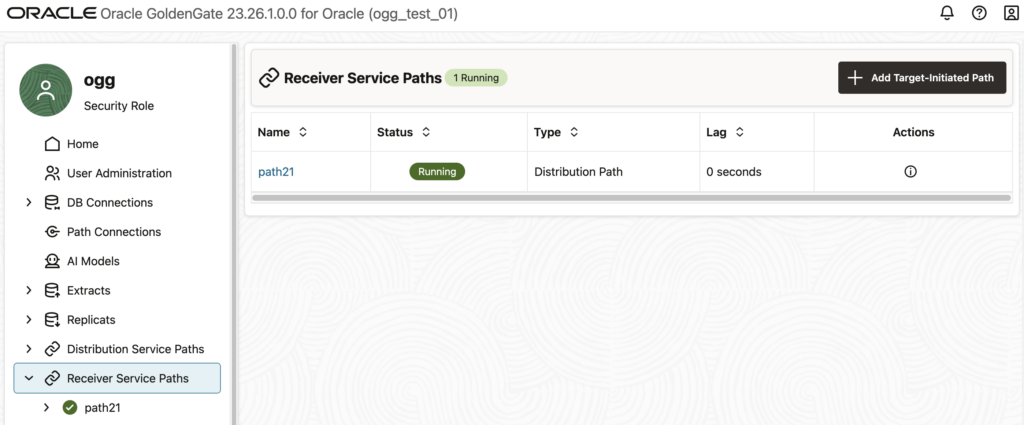
If you click on this path… Nothing happens ! And by “nothing”, I mean “nothing abnormal”. In fact, the statistics are properly displayed (see below), and there is no error shown to the user. However, if you look at your ggserr.log file you will see that the error given above appears.
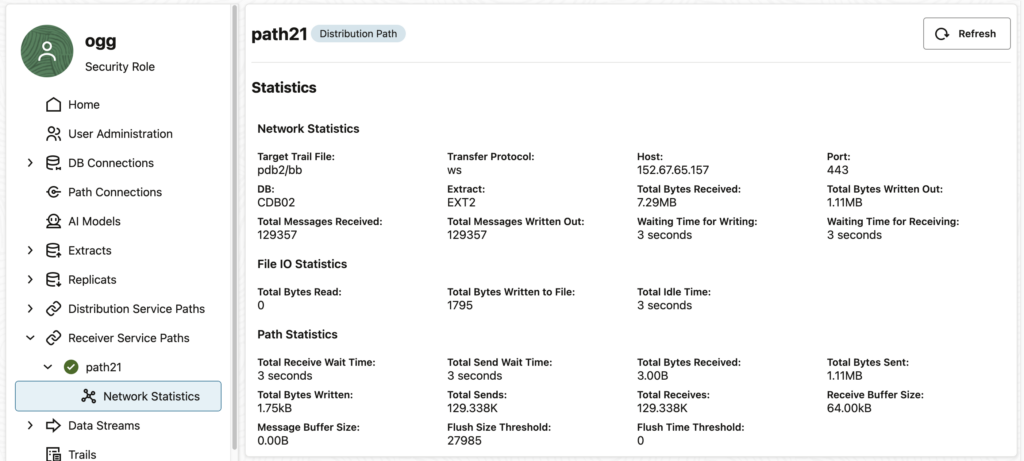
At first glance, this might not seem like a huge issue, because if you don’t click on the receiver path, you will not get the error. However, in the log file of the customer, the error appeared regularly. Every minute, to be precise.
Why do I get this error even when I’m not accessing the web UI ?Luckily, when debugging this issue, I started by putting the target in a blackout in the Oracle Enterprise Manager. To my surprise, the error was gone during the blackout and reappeared right after.
In this case, the Enterprise Manager Plug-in for Oracle GoldenGate is monitoring the status of the deployment every minute and generates the error in the process.
When looking at the targets in the OEM, there is no error. Again, no operational impact.
Does it depend on the way you create the distribution path ?GoldenGate offers multiple ways of managing deployments : REST API, adminclient, or the web UI. Unfortunately, some bugs (and some features…) mean that you should avoid managing some objects with some of these tools (read why you shouldn’t create profiles through the adminclient, for instance).
In this specific case, all distribution path creation methods lead to the same error in the log file. It doesn’t matter whether you create the distribution path with the adminclient, the REST API or the web UI. They will all lead to this error.
Let’s dig a bit to see what is happening behind the scenes. By looking at the restapi.log file (read my blog on how to analyze REST API logs efficiently), we can see the full error:
2026-05-18 09:08:58.402+0000 ERROR|RestAPI.recvsrvr | Request #9: {
"context": {
"httpContextKey": 140097141801744,
"verbId": 2,
"verb": "GET",
"originalVerb": "GET",
"uri": "/services/v2/targets/path21",
"protocol": "http",
"headers": {
...
},
"host": "vmogg",
"securityEnabled": false,
"authorization": {
"authUserName": "ogg",
"authUserRole": "Security",
"authMode": "Cookie"
},
"requestId": 8,
"uriTemplate": "/services/{version}/targets/{path}",
"catalogUriTemplate": "/services/{version}/metadata-catalog/path"
},
"isScaRequest": true,
"content": null,
"parameters": {
"uri": {
"path": "path21",
"version": "v2"
},
"query": {
"WindowRef": "%2Fservices%2Fv2%2Fcontent%2F%23%2FrecvsrvrPaths%2Fpath21%2FpathNetworkStats"
}
}
}
Response: {
"context": {
...
},
"isScaResponse": true,
"content": {
"$schema": "api:standardResponse",
"links": [
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21",
"mediaType": "application/json"
},
{
"rel": "self",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21",
"mediaType": "application/json"
}
],
"messages": [
{
"$schema": "ogg:message",
"title": "Path path21 not found",
"code": "OGG-08502",
"severity": "ERROR",
"issued": "2026-05-18T09:08:58Z",
"type": "https://www.rfc-editor.org/rfc/rfc9110.html#name-status-codes"
}
]
}
}The issue comes from the following endpoint : /services/v2/targets/path21. It is described in the documentation under Retrieve an existing Oracle GoldenGate Collector Path. But looking at another endpoint described in Get a list of distribution paths, we get the following response:
{
"$schema": "api:standardResponse",
"links": [
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets",
"mediaType": "text/html"
},
{
"rel": "self",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets",
"mediaType": "text/html"
},
{
"rel": "describedby",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/metadata-catalog/targets",
"mediaType": "application/schema+json"
}
],
"messages": [],
"response": {
"$schema": "ogg:collection",
"items": [
{
"links": [
{
"rel": "parent",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets",
"mediaType": "application/json"
},
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21_ogg26dist2_7811",
"mediaType": "application/json"
}
],
"$schema": "ogg:collectionItem",
"name": "path21",
"status": "running",
"targetInitiated": false
}
]
}
}Here, we see that the endpoint associated with the path21 object is not recvsrvr/v2/targets/path21 but recvsrvr/v2/targets/path21_ogg26dist2_7811. And looking at this second endpoint, we do not get an error.
{
"$schema": "api:standardResponse",
"links": [
{
"rel": "canonical",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21_ogg26dist2_7811",
"mediaType": "text/html"
},
{
"rel": "self",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/targets/path21_ogg26dist2_7811",
"mediaType": "text/html"
},
{
"rel": "describedby",
"href": "https://vmogg/services/ogg_test_01/recvsrvr/v2/metadata-catalog/path",
"mediaType": "application/schema+json"
}
],
"messages": [],
"response": {
"name": "path21",
"status": "running",
"$schema": "ogg:distPath",
"source": {
"uri": "trail://localhost:7811/services/v2/sources?trail=pdb2/bb"
},
"target": {
"$schema": "ogg:distPathEndpoint",
"uri": "ws://vmogg/services/v2/targets?trail=pdb2/bb"
},
"options": {
"network": {
"appOptions": {
"appFlushBytes": 27985,
"appFlushSecs": 1
},
"socketOptions": {
"tcpOptions": {
"ipDscp": "DEFAULT",
"ipTos": "DEFAULT",
"tcpNoDelay": false,
"tcpQuickAck": true,
"tcpCork": false,
"tcpSndBuf": 16384,
"tcpRcvBuf": 131072
}
}
}
}
}
}The problem is that it was never decided for path21 to be referred to as path21_ogg26dist2_7811 internally. And it looks like GoldenGate does not know about it either… So until the bug is corrected, you will have to filter this OGG-08502 Path not found error out of the ggserr.log file if you use it for monitoring.
L’article OGG-08502 Path not found error from OGG Receiver Service est apparu en premier sur dbi Blog.
What being an external consultant really changes
When people think about consultants, they usually focus on expertise. “They bring experience, frameworks, and best practices.”
That’s true, of course. However, that is not the most impactful aspect of the role.
The real shift happens somewhere less visible: positioning. As an outsider, you don’t just join a team.
You become something different. Over time, I’ve come to think of it as operating within a “shadow team.”

This invisible layer changes how you navigate politics, truth, and influence.
Let’s unpack that.
As an employee, you’re clearly part of the organization.
However, when you’re an external consultant, it’s a different story.
You sit inside delivery teams while remaining outside the organization’s long-term structure. This dual positioning creates what I call a shadow team.
You collaborate closely with internal stakeholders, influence decisions without owning them, and observe dynamics that others are too immersed in to see.
You’re close enough to matter, yet distant enough to stay objective.
This reshapes everything.
Every organization has internal politics, including priorities, power structures, historical tensions, and unwritten rules. The larger the organization, the more politics there are.
Employees must live within that system.
Consultants, on the other hand, can often see the system more clearly because they aren’t fully bound by it.
This doesn’t mean you’re outside of politics, though.
It means:
You can identify misalignments more quickly, notice when decisions are driven by structure, not logic and spot friction between teams that others consider “normal.”
But here’s the key difference:
- You are less constrained by long-term consequences.
- An employee may avoid challenging a decision due to its potential impact on their career.
- However, a consultant can raise the concern because their role is to add clarity, not preserve equilibrium.
- Still, this doesn’t mean ignoring politics. It means navigating them consciously without being controlled by them.
One of the most powerful—and most fragile—assets of being an external consultant lies in the neutrality that people attribute to you.
You are not:
- Competing for a promotion
- Defending a department
- Protecting past decisions
This creates a rare opportunity. You can become a trusted bridge between stakeholders
When done right, people will:
- Share concerns they wouldn’t voice internally
- Ask for your opinion as a “safe” perspective
- Use you to validate or challenge ideas
However, neutrality is not automatic, it must be earned and can easily be lost.
You lose it when:
- You align too strongly with one stakeholder
- You start defending internal logic instead of questioning it
- You behave like an insider too quickly
The best consultants maintain a delicate balance:
They are close enough to build trust and distant enough to stay credible.
Truth vs. Diplomacy: walking the tightropeThis is where the role becomes truly challenging.
As a consultant, you are often expected to:
- Tell the truth
- Challenge assumptions
- Highlight risks
However, you are also expected to:
- Maintain relationships
- Respect stakeholders
- Keep the project moving forward
These two expectations often conflict with each other.
The naive approach: “Just be brutally honest.”
This approach quickly fails. Brutality destroys trust.
The safe approach: “Say what people want to hear.”
This makes you irrelevant.
The real skill is delivering truth in a way that can be heard.
That means:
- Frame issues in terms of impact, not fault.
- Ask questions instead of making accusations.
- Adapt your message to your audience.
For example, rather than saying, “This process isn’t working at all”
A more measured approach might be: “I see a few risks associated with this process. Could we go over them together?”
The observation is the same.
However, the outcome is different.
Being a consultant isn’t just about knowledge. It’s also about positioning. You have a clearer view, speak more freely, and connect across sides.
However, our profession is based on a paradox. We must be objective enough to provide sound advice, yet also be fully committed to the task at hand. Additionally, we must offer honest feedback without hurting the client’s feelings or losing their trust.
At dbi services, we’re passionate about striking that delicate balance, whether the subject is ECM or any other area of our expertise. Learn more about us here.
L’article What being an external consultant really changes est apparu en premier sur dbi Blog.
Install and configure OEM plug-in for GoldenGate
If you are licensed for the GoldenGate Management Pack, using the Enterprise Manager plug-in for GoldenGate improves monitoring and management of your deployments. And after migrating to the Microservices Architecture, you should definitely update your plug-in and rediscover all targets. Let’s see how to do all that here.
In this blog, I will use the latest version of the Enterprise Manager (24ai) and monitor GoldenGate 26ai deployments. The overall workflow is the same for other versions of the Enterprise Manager and GoldenGate, provided OGG is in the Microservices Architecture.
Here are the main steps to monitor GoldenGate targets from the Enterprise Manager:
- Update the catalog in the Enterprise Manager
- Deploy the plug-in on the management server
- Deploy the plug-in on the agent
- Configure the discovery module
- Promote the new targets
Before attempting to install the plug-in, make sure it is not already installed in your environment. To check this, go to Setup > Extensibility > Plug-ins, and expand the Middleware section. If you do not see any line named Oracle GoldenGate, it means the plug-in is not installed yet.
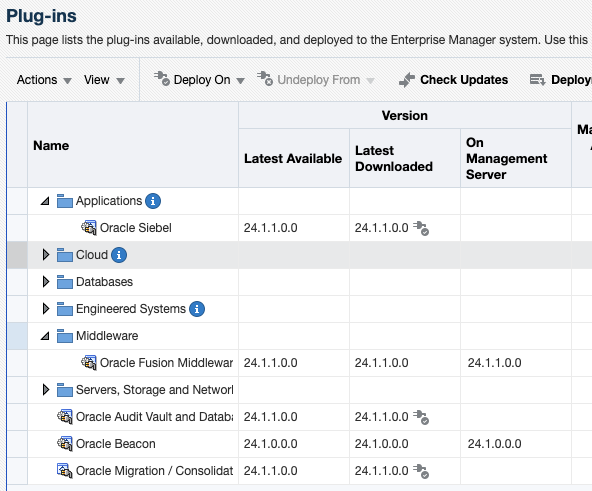
Since most OEM environments do not have access to the Oracle Support directly, we’ll download the plug-in in offline mode. To do so, go to the Setup > Provisioning and Patching > Offline Patching section.
Once in the Offline Patching section, make sure Offline is selected for the connection and download the catalog file as instructed from an environment with access to the Oracle support website. Transfer it to where you have access to the OEM UI, and upload it.
Once the catalog is uploaded, you should see the following information message.
Then, go to Setup > Extensibility > Self Update and click on Check Updates.
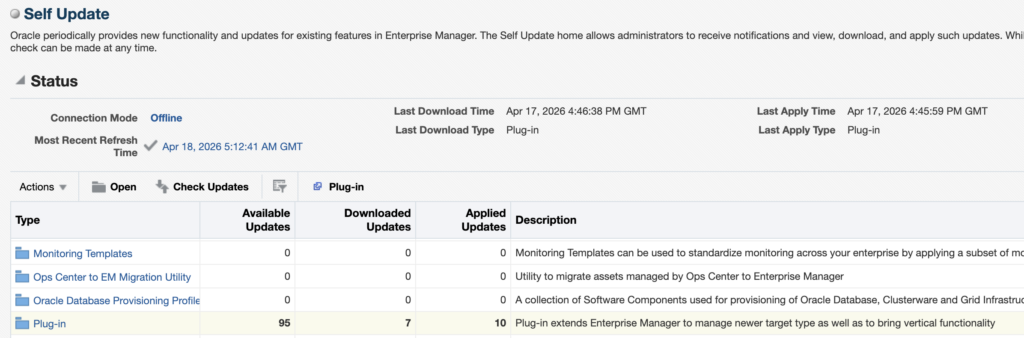
You should see the following pop-up appear, with a link from where you will be able to download the OEM Self Update catalog file. For reference, the one I had when writing this blog was the following : https://updates.oracle.com/Orion/Download/download_patch/p9348486_112000_Generic.zip
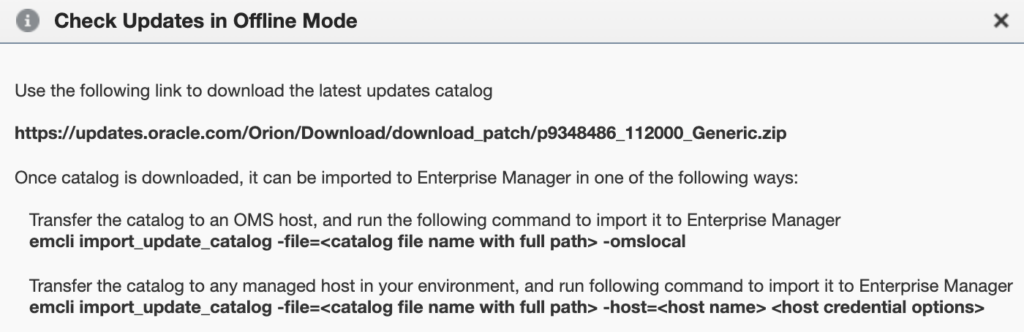
As instructed, transfer this patch to the OMS host and import it with emcli and the import_update_catalog action. You can also import it from another managed host. It should take around twenty seconds to import everything.
oracle@oem24:~/ [oem24] emcli import_update_catalog -file=/tmp/p9348486_112000_Generic.zip -omslocal
Processing catalog for Diagnostic Tools
Processing update: Diagnostic Tools - AHFFI 25.1.0.1.0 for Linux
Processing update: Diagnostic Tools - AHF 25.5.0.0.0 for HP
[...]
Processing update: Plug-in - GoldenGate Plug-in now supports monitoring of Oracle GoldenGate Microservices, in addition to the Oracle GoldenGate Classic
Processing update: Plug-in - GoldenGate Plug-in now supports monitoring of Oracle GoldenGate Microservices, in addition to the Oracle GoldenGate Classic
Processing update: Plug-in - GoldenGate Plug-in now supports monitoring of Oracle GoldenGate Microservices, in addition to the Oracle GoldenGate Classic
Processing update: Plug-in - GoldenGate Plug-in now supports monitoring of GoldenGate Microservices Architecture, in addition to the GoldenGate Classic Architecture
[...]
Successfully uploaded the Self Update catalog to Enterprise Manager. Use the Self Update Console to view and manage updates.
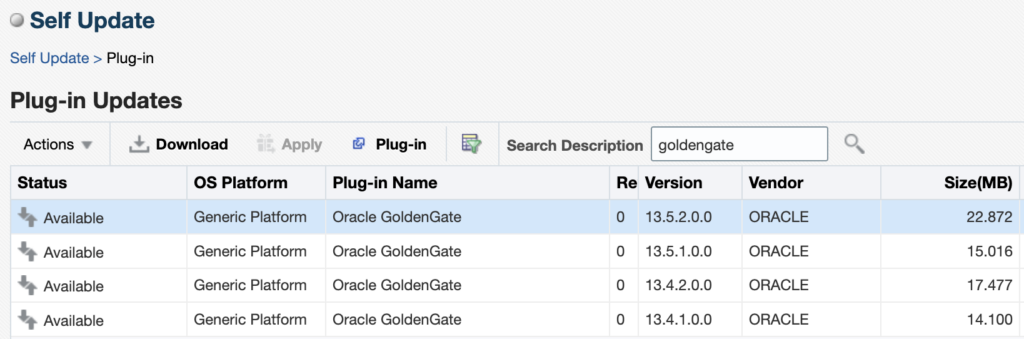
Time taken for import catalog is 17.289 seconds.When this is done, go back to the Self Update page, click on the Plug-In section. You will see the different versions of GoldenGate that are available. When I’m writing this blog, the latest version of the plug-in is 13.5.2.0.0 (the latest patch released in January 2026, 13.5.2.0.6, will be a topic for another blog). Click on the latest version and then on Download.
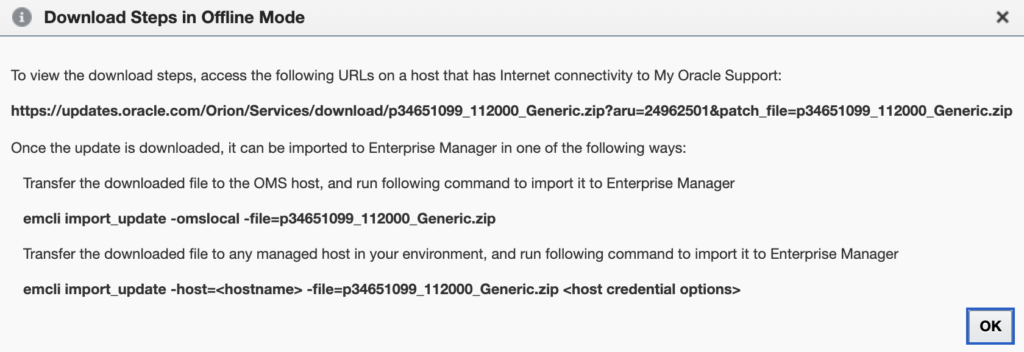
The following pop-up gives you the link from which you should download the plug-in update file. In my case, it was https://updates.oracle.com/Orion/Services/download/p34651099_112000_Generic.zip?aru=24962501&patch_file=p34651099_112000_Generic.zip.
Once the file is downloaded, import it in the same way as before with the catalog, but this time with the emcli import_update action.
oracle@oem24:~/ [oem24] emcli import_update -omslocal -file=/tmp/p34651099_112000_Generic.zip
Processing update: Plug-in - GoldenGate Plug-in now supports monitoring of Oracle GoldenGate Microservices, in addition to the Oracle GoldenGate Classic
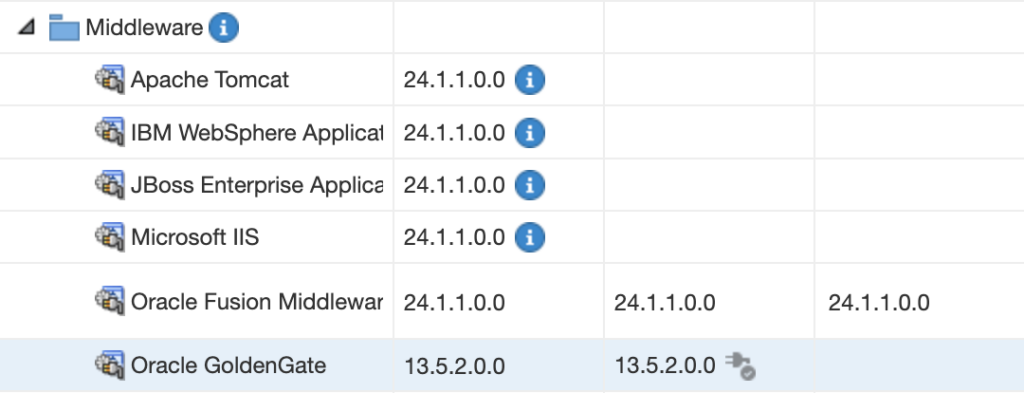
Successfully uploaded the update to Enterprise Manager. Use the Self Update Console to manage this update.Once this is done, go back to the Setup > Extensibility > Plug-in tab and expand the Middleware section. You should now see Oracle GoldenGate, and 13.5.2.0.0 as the downloaded version.
Warning : Deploying the plug-in on the management server will temporarily restart OMS components and briefly interrupt monitoring operations. To deploy the plug-in, you have two options:
- Deploying the plug-in from the web UI.
- Deploying the plug-in from the CLI.
From the web UI, click on the Oracle GoldenGate plug-in, then on Deploy On, and deploy the plug-in on the Management Servers.
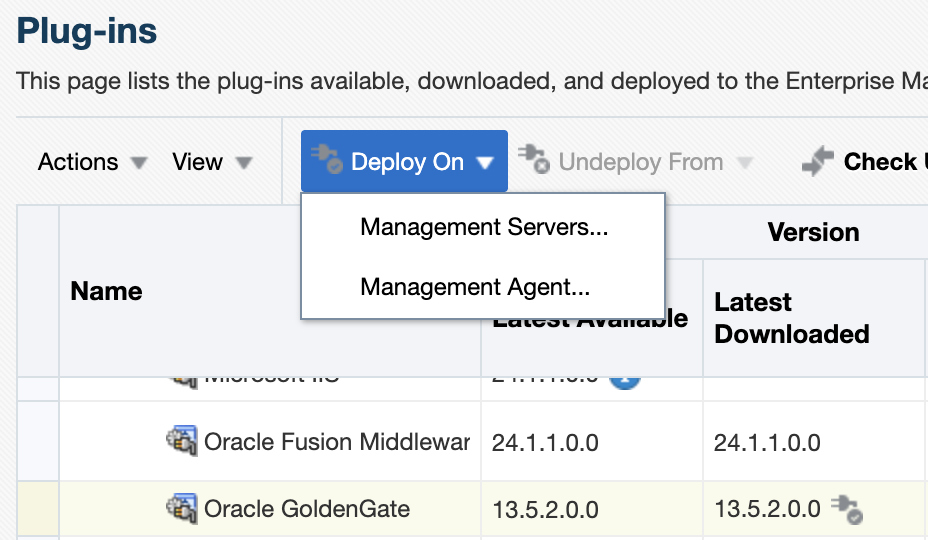
Make sure the correct version of the plug-in is chosen (13.5.2.0.0), and click on Next to run the prerequisite checks.

Once the checks are successfully completed, click on Next.

You should now select the repository credentials for the OEM. You should either use new credentials (if it’s a new environment) or use existing named credentials. Click on Next.
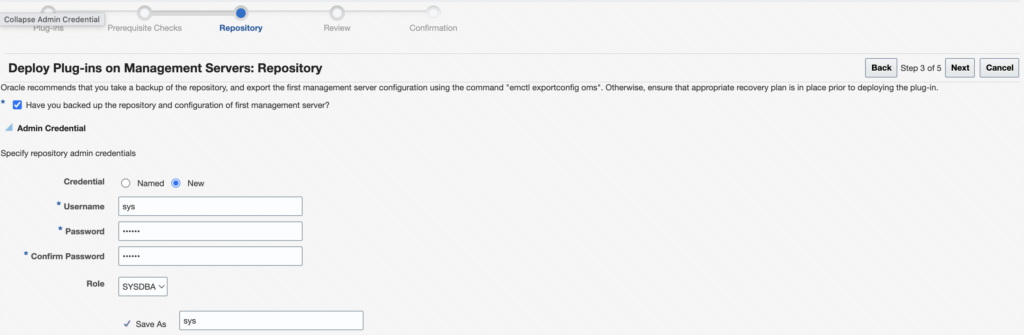
Once everything is done, click on Deploy.
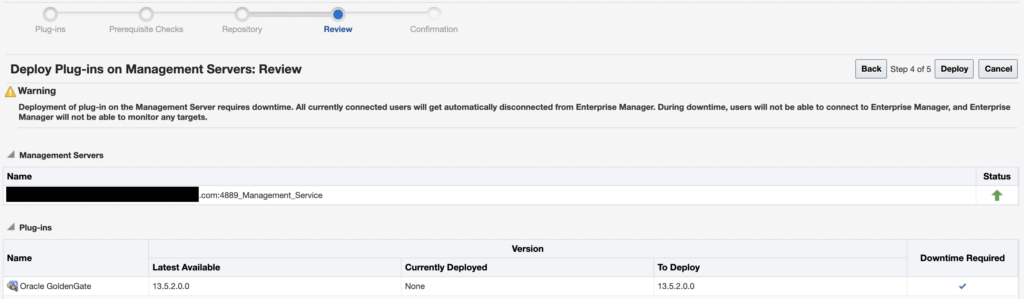
As instructed, you can check the status of the deployment with the emctl status oms -details command.

oracle@oem24:~/ [oem24] emctl status oms
Oracle Enterprise Manager 24ai Release 1
Copyright (c) 1996, 2024 Oracle Corporation. All rights reserved.
WebTier is Up
Oracle Management Server is Down
This is due to the following plug-ins being deployed on the management server or undeployed from it:
----------------------------------------
Plugin name: : Oracle GoldenGate
Version: : 13.5.2.0.0
ID: : oracle.fmw.gg
----------------------------------------Alternatively, you can deploy the plug-in with the following command, using the oracle.fmw.gg ID for the plug-in and the latest 13.5.2.0.0 version.
emcli deploy_plugin_on_server -plugin="oracle.fmw.gg:13.5.2.0.0"Once the plug-in is deployed on the Management Server, you can check again in the web UI : the latest version should be in the On Management Server section.
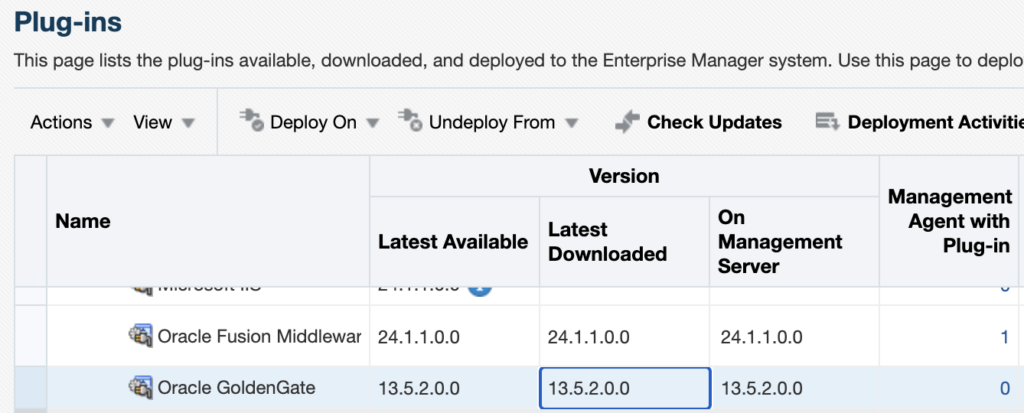 Deploy the plug-in on the agent
Deploy the plug-in on the agent
For each GoldenGate host where an OEM agent is running, deploy the plug-in. To do so, from the web UI, click on the Oracle GoldenGate plug-in, then on Deploy On, and select Management Agent.
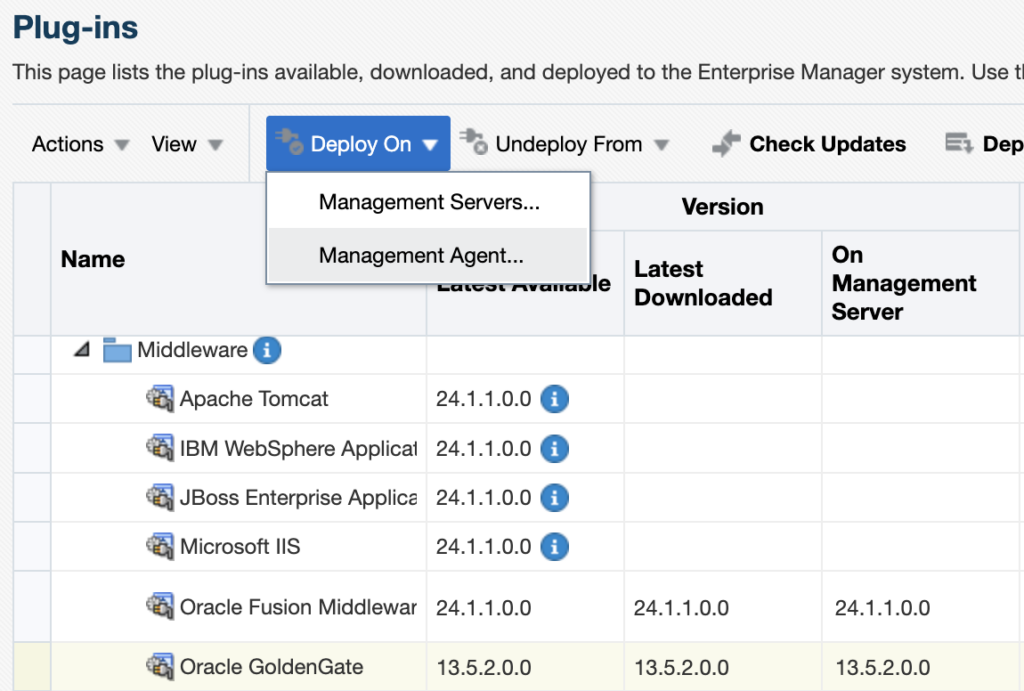
There is currently a bug with the Supported Target Versions. No matter your patch level, you will not see the latest versions of GoldenGate. Do not worry about this yet. Just make sure 13.5.2.0.0 is selected.
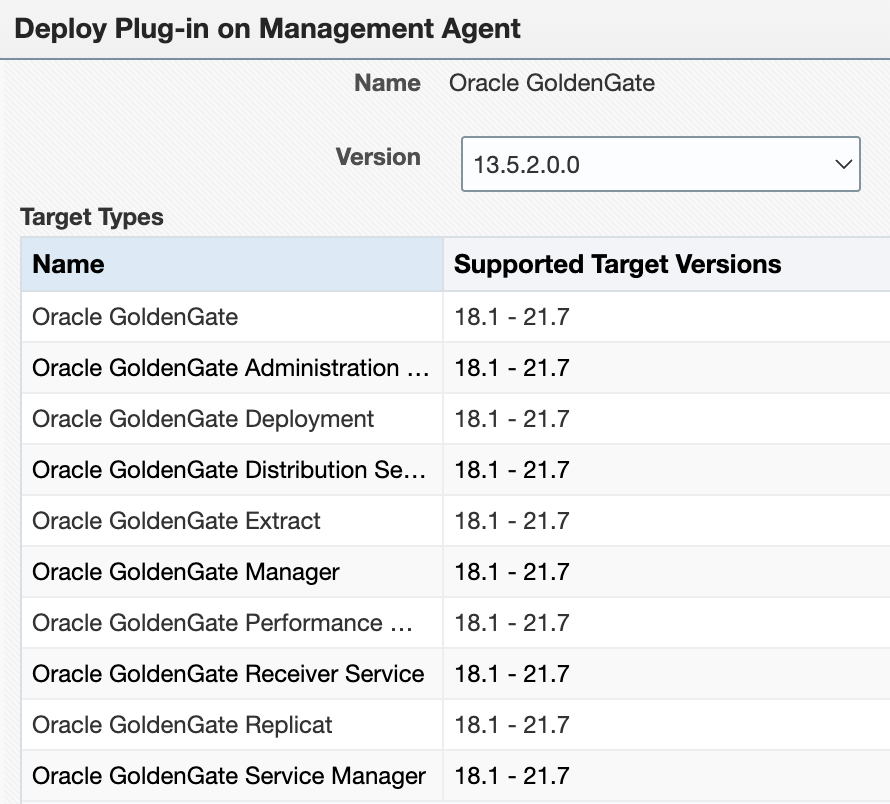
Then, select the agent on which you want to deploy the plug-in.
Let the prerequisite checks run…
And once everything is ready, click on Deploy.
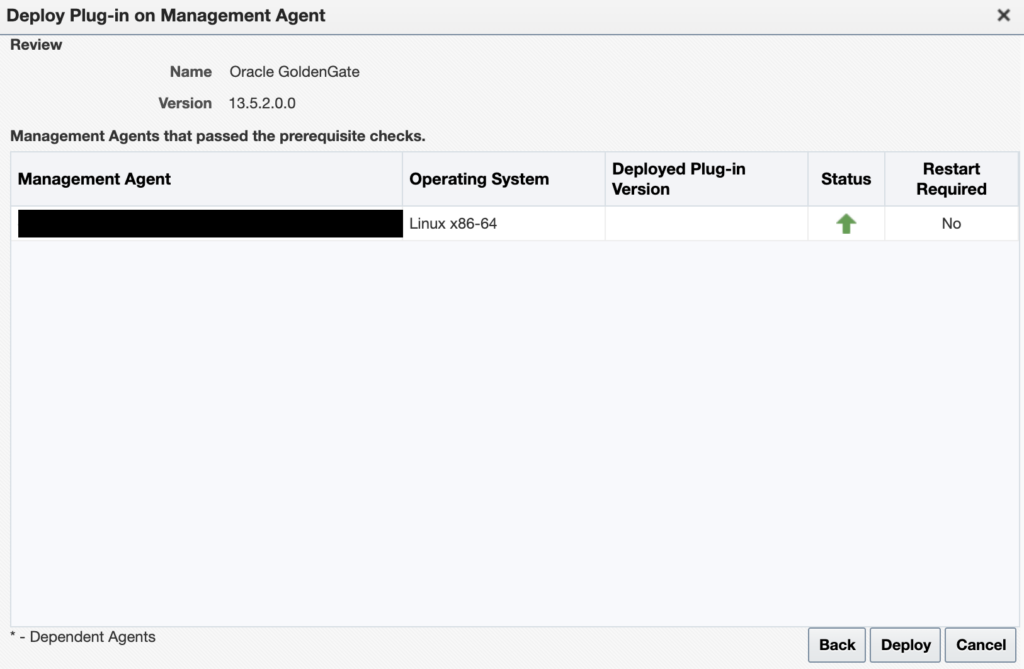
You can check that everything is running properly with the emcli get_plugin_deployment_status command.
 Configure GoldenGate monitoring in the Enterprise Manager
Configure GoldenGate monitoring in the Enterprise Manager
Once the plug-in is correctly deployed on the OMS host and on the GoldenGate host agent, you can configure the module. I will only cover the configuration for the Microservices Architecture. Go to the Setup > Add Target > Configure Auto Discovery tab.
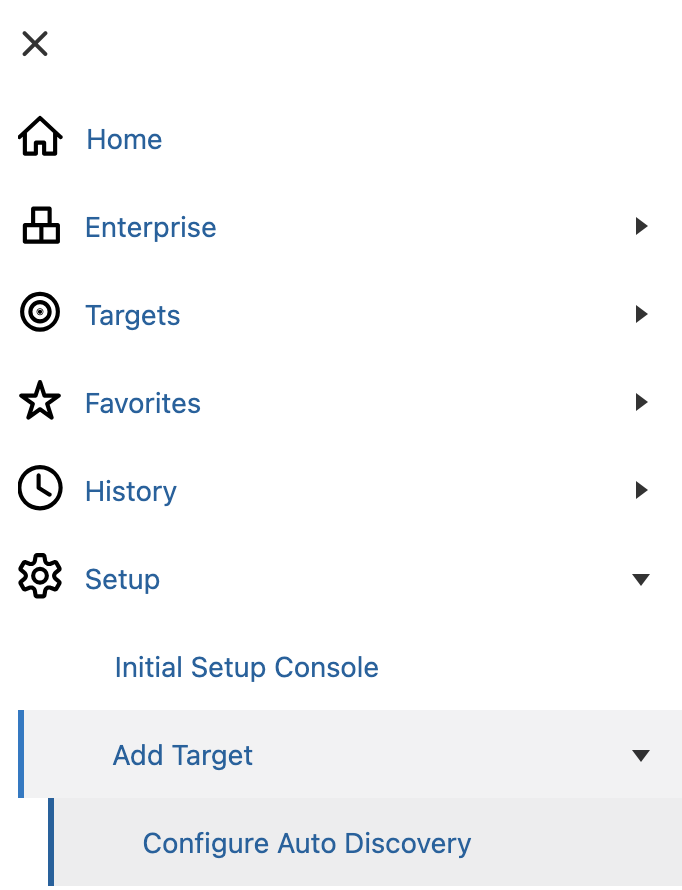
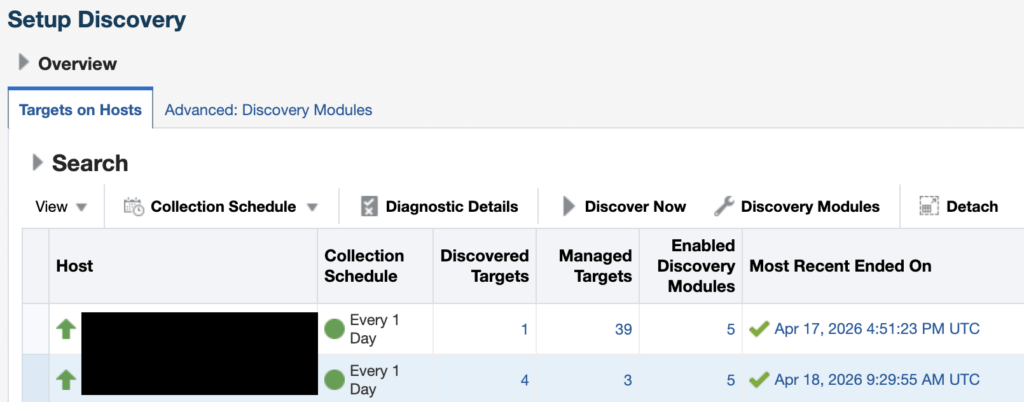
Choose the correct agent host, and click on Discovery Modules.
Enable the Oracle GoldenGate Microservices module, click on it, and then on Edit Parameters.
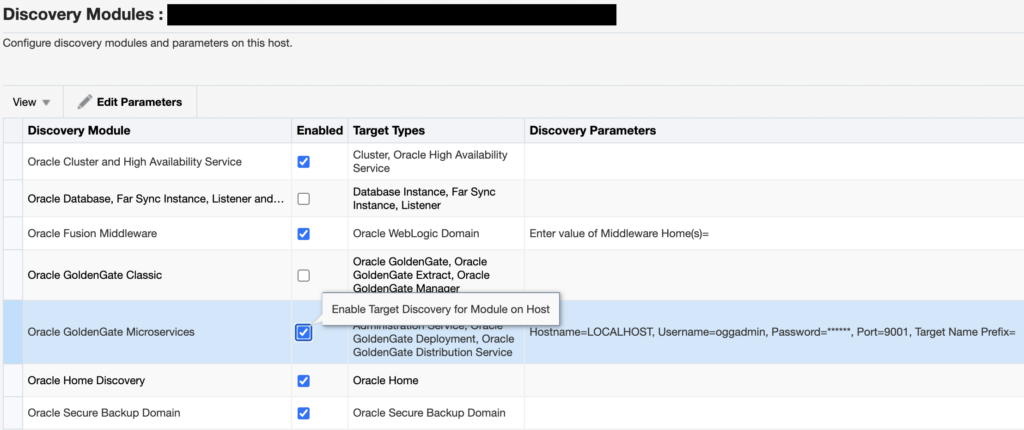
If you deployed GoldenGate with a reverse proxy, set up the plug-in as such.

If you deployed GoldenGate with a port for each service, enter the service manager port (7809, by default).
Warning : if your installation is secured with certificates, make sure to follow the instructions I gave in a blog to avoid EM-90000 errors when discovering new targets.
Once this is done, just go back to the Configure Auto Discovery section, click on the correct host, and then click on Discover Now. Then, go back to the Configure Auto Discovery section. You should now see a greater number of targets in the Discovered targets section.
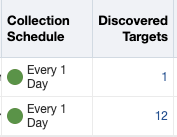
If the number of targets did not increase, despite a successful discovery, check the blog linked above.
Click on the number of targets to jump to the Auto Discovery Results section. Select the newly discovered Service Manager target, and click on Promote. Once the target is promoted, you should see the new GoldenGate targets being monitored by the Enterprise Manager !

L’article Install and configure OEM plug-in for GoldenGate est apparu en premier sur dbi Blog.
Customer case study – automating SQL Server TLS Encryption with Ansible and Certificates (Architecture)
When working with SQL Server environments, securing client connections can become an important requirement, especially when TLS encryption must be implemented using certificates. In this context, a customer asked us to develop an Ansible playbook and role to automate the configuration of TLS for SQL Server. The certificates are generated from the customer PKI and provided as PEM files containing the server certificate, the private key, and the certificate chain.
However, some extractions and conversions are required before these certificates can be used on Windows and configured for SQL Server.
Here, the idea is to propose a solution (the architecture) that prepares the certificate, imports it on the SQL Server host, and configures SQL Server to use it.
We will also see how to separate the preparation and activation steps in order to reduce the impact on the SQL Server service.
In this blog post, we will describe the global approach and the Ansible logic used to implement certificate-based TLS encryption for SQL Server.
Implementation logicBefore configuring TLS encryption on SQL Server, the first point was to understand the certificate format provided by the customer PKI.
In our case, the generated file is a <machine>.pem file. This file contains the server certificate used for TLS, the private key and the certificate chain with the intermediate and root certificates.
As this format cannot be directly used as-is on the Windows side for SQL Server, some extraction and conversion steps are required.
The general idea is to use the Ansible control node as a working area.
The PEM file is first copied into a temporary folder where the different parts of the certificate are extracted:
- the leaf certificate
- the intermediate certificate
- the root certificate
- the private key
These elements are then used to build a PFX file which can be imported on the Windows SQL Server host.
The PFX is installed in the LocalMachine\My certificate store while the intermediate and root certificates are imported into the appropriate Windows certificate stores.
The implementation has been designed around three different execution modes: stage, activate, and full.
The stage mode is used to prepare the certificate without any impact on the SQL Server service. It copies the PEM file, performs the extractions, builds the PFX file, copies it to the managed Windows node and imports the certificates into the Windows certificate stores. No registry change is performed, and the SQL Server service is not restarted. This mode is useful when we want to prepare the server in advance before switching SQL Server to the new certificate.
The activate mode assumes that the certificate is already present on the Windows server. Its role is to configure SQL Server to use the installed certificate and depending on the selected option, restart the SQL Server service or leave the change pending until the next planned reboot.
This can be useful when the certificate activation must be aligned with an existing maintenance window, for example during monthly OS patching.
The full mode executes the complete configuration from end to end. It performs the extraction and conversion steps, imports the certificates, grants the required permissions, configures SQL Server to use the expected certificate, and restarts the SQL Server service only if required. To avoid unnecessary impact, the role relies on the certificate thumbprint. If the expected certificate is already configured, no change is applied and the SQL Server service is not restarted. This behavior is important for idempotency.
For example, if the full mode is executed after an activate mode, nothing should be changed if the certificate is already the correct one. The same logic applies if the playbook is executed by mistake while the certificate has not been renewed.
Another point to manage is the restart of the SQL Server service. SQL Server loads the certificate configuration when the service starts. Therefore, when a new certificate is configured, the change is only effective after a restart of the SQL Server service.
For this reason the role should provide an option to control whether the restart is performed immediately or postponed to the next planned reboot.
We also have to consider DNS aliases. The standard use case is to generate a certificate containing at least the short name and the FQDN of the SQL Server host in the subjectAltName. If DNS aliases are used by client applications, they can also be added to the certificate SAN.
For example:
[alt_names]
DNS.1 = A-WS2022-2.lab.local
DNS.2 = A-WS2022-2Finally, the customer confirmed that the private key included in the PEM file is not encrypted.
This simplifies the conversion process to PFX, but it also means that the PEM file must be handled carefully during the Ansible execution, especially in temporary folders and during file transfers. With this approach, the role provides a controlled way to prepare, activate, or fully configure TLS encryption for SQL Server while keeping the impact on the SQL Server service under control.
Logical workflowThe complete workflow can be represented as follows:
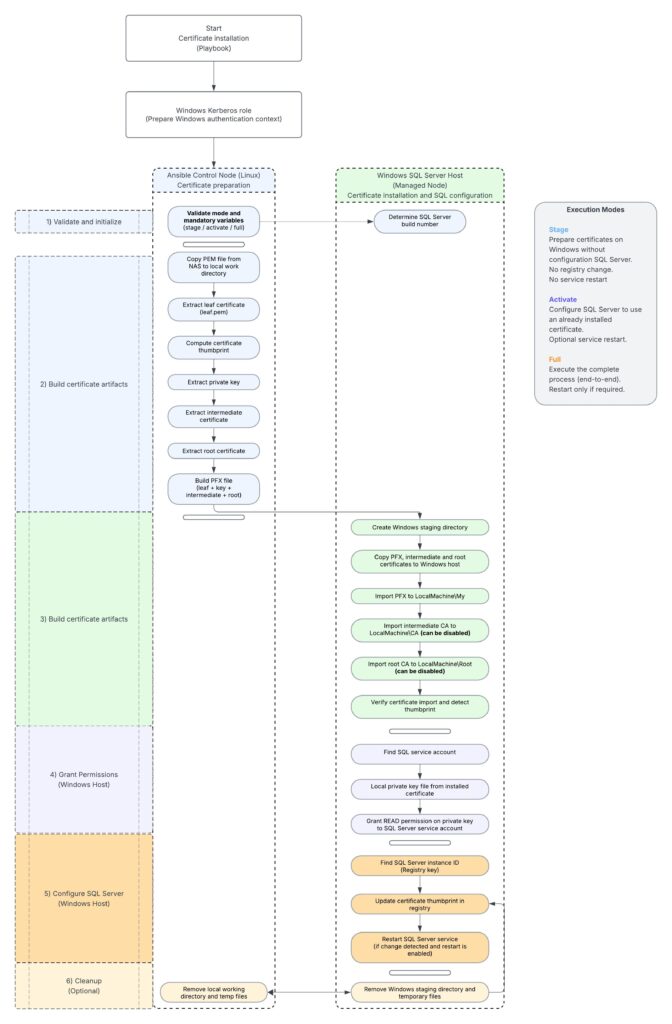 Architecture summary
Architecture summary
The certificate manipulation is performed on the Ansible control node.
The Windows certificate import and SQL Server configuration are performed on the managed Windows SQL Server host.
This separation is useful because the PEM processing and PFX generation are handled with Linux tools such as OpenSSL while the certificate installation, private key permissions, registry configuration and SQL Server restart are handled through Windows modules and PowerShell. The design also supports a controlled deployment approach.
The certificate can first be staged without service impact then activated later during a maintenance window.
The full mode can be used when the complete implementation must be executed in a single run. The use of the certificate thumbprint is important for idempotency. It allows the role to detect whether SQL Server is already configured with the expected certificate and avoids unnecessary service restarts when no change is required.
RemarksFor certain reasons we do not disclose the code of the created role.
Thank you. Amine Haloui
L’article Customer case study – automating SQL Server TLS Encryption with Ansible and Certificates (Architecture) est apparu en premier sur dbi Blog.
How Row Goal shapes your SQL Server query strategy by hunting for pierogis

SQLDay 2026 took place this week, from May 11th to 13th, in Wroclaw. Among the featured speakers was Erik Darling, who delivered both a main session and a full-day workshop dedicated to SQL Server performance. During his presentations, he emphasized a concept that is not always widely understood, known as the Row Goal.
The purpose of this article is to recap Erik’s key observations and to introduce this topic, which can serve as a powerful lever for query optimization.
A quick culinary detour and why pierogis matterIn order to understand the explanations below, one key concept must be understood: the Pierogi.
“Pierogi are filled dumplings made from unleavened dough, popular in Polish cuisine and enjoyed worldwide, with various savory and sweet fillings” [1], [2].

To be honest, this has nothing to do with our technical topic, but this dish discovered during this trip is so good that I simply had to include it in this blog.
Filling the aisles and designing our databaseIn this article, we will use a custom-made database simulating a Polish supermarket selling pierogis. Unfortunately, there aren’t many left, and the product distribution is not uniform. In fact, pierogis account for much less than 1% of the supermarket’s total stock.
Here is the script to create the DB, along with its article reference table and inventory:
USE master;
GO
IF EXISTS (SELECT * FROM sys.databases WHERE name = 'PierogiMart')
DROP DATABASE PierogiMart;
GO
CREATE DATABASE PierogiMart;
GO
USE PierogiMart;
GO
CREATE TABLE Articles (
ArticleID INT IDENTITY(1,1) PRIMARY KEY,
ArticleName VARCHAR(50) NOT NULL,
Price DECIMAL(10, 2) NOT NULL
);
CREATE TABLE Inventory (
ReferenceID INT IDENTITY(1,1) PRIMARY KEY,
ArticleID INT NOT NULL,
ValidityDate DATETIME NOT NULL,
Quantity INT NOT NULL,
CONSTRAINT FK_Article FOREIGN KEY (ArticleID) REFERENCES Articles(ArticleID)
);
GO
INSERT INTO Articles (ArticleName, Price)
VALUES
('Pierogi', 12.50),
('Pasta', 8.00),
('Sandwich', 6.50),
('Quiche', 9.00);
GO
INSERT INTO Inventory (ArticleID, ValidityDate, Quantity)
SELECT TOP 100000
2,
DATEADD(DAY, ABS(CHECKSUM(NEWID())) % 365, '2025-01-01'),
ABS(CHECKSUM(NEWID())) % 100
FROM sys.all_columns a CROSS JOIN sys.all_columns b;
INSERT INTO Inventory (ArticleID, ValidityDate, Quantity)
SELECT TOP 10000
3,
DATEADD(DAY, ABS(CHECKSUM(NEWID())) % 365, '2025-01-01'),
ABS(CHECKSUM(NEWID())) % 100
FROM sys.all_columns a CROSS JOIN sys.all_columns b;
INSERT INTO Inventory (ArticleID, ValidityDate, Quantity)
SELECT TOP 50000
4,
DATEADD(DAY, ABS(CHECKSUM(NEWID())) % 365, '2025-01-01'),
ABS(CHECKSUM(NEWID())) % 100
FROM sys.all_columns a CROSS JOIN sys.all_columns b;
INSERT INTO Inventory (ArticleID, ValidityDate, Quantity)
SELECT TOP 10
1,
'2026-12-31',
5
FROM sys.all_columns;
GO
We are also including a few indexes to simulate a real-world use case and to support our queries, ensuring we get realistic execution plans:
CREATE NONCLUSTERED INDEX IDX_INV_QUANT ON [dbo].[Inventory] ([Quantity]) include (ArticleID)
CREATE NONCLUSTERED INDEX IDX_INV_VALIDITY on [dbo].[Inventory] ([ValidityDate]) include (ArticleID)
CREATE NONCLUSTERED INDEX IDX_INV_ART on [dbo].[Inventory] (ArticleID)
Normally, the SQL Server optimizer seeks to minimize the total cost of processing all data for a query. However, if it knows that you only need a specific number of rows (for example, via a TOP, FAST(N), or EXISTS clause), it changes its strategy.
The Row Goal is this specific row target that pushes the optimizer to favor a plan capable of delivering the first few rows as quickly as possible, even if that same plan would be catastrophic for processing the entire table.
TOP(N): Hunting for the best PierogiTo illustrate the definition above, let’s search for the pierogis with the furthest expiration dates.
Note that the IDX_INV_VALIDITY index supports this query:
SELECT
A.ArticleName,
A.Price,
I.ValidityDate
FROM Articles A
INNER JOIN Inventory I ON A.ArticleID = I.ArticleID
WHERE A.ArticleName = 'Pierogi'
order by I.ValidityDate desc;
SELECT top 10
A.ArticleName,
A.Price,
I.ValidityDate
FROM Articles A
INNER JOIN Inventory I ON A.ArticleID = I.ArticleID
WHERE A.ArticleName = 'Pierogi'
order by I.ValidityDate desc
The difference between these two queries is that one requests only the first 10 rows, while the other requests all matching rows. However, this simple distinction is not merely applied when displaying the results; this condition is pushed deeper into the execution plan to influence the choice of operators (Nested Loop, Hash Join, Merge Join) further down the tree.
For the first query, here is the resulting plan:
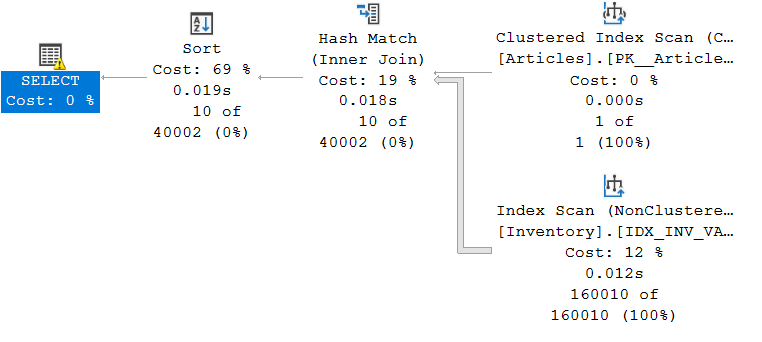
As we can see, the optimizer chose a Hash Join given the volume of data to be joined. A Hash Match implies that all the data must be read in order to produce the desired result.
For the second query, here is the execution plan:
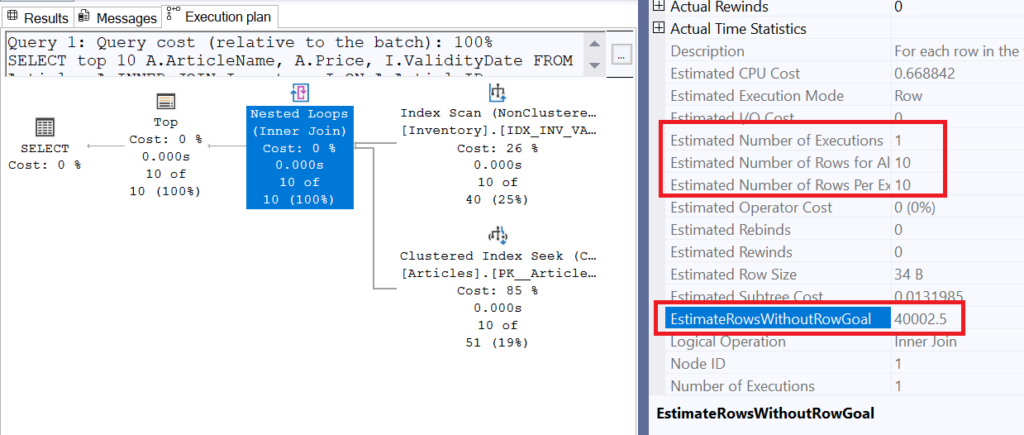
We can see that this time, the optimizer chose a Nested Loop, which takes each row from the reference table (Inventory) and joins them with the Articles table. This operation can be very time-consuming if a large number of rows must be processed. However, this is where EstimateRowsWithoutRowGoal comes into play. The value of this property is 40’002.5; this means that in a case where a subset of rows was not specifically required, the optimizer would have estimated the number of rows returned by this operator at that value. We can see, however, that the estimation actually used is 10 rows for one execution, a value clearly derived from the TOP(10).
In summary, adding the TOP(10) allowed the optimizer to use a less expensive join for a small amount of data, even though the TOP operator is located at the very end of the execution plan (since a plan is read from right to left).
As explained previously, the EXISTS clause has a cardinality of 1 because the very first row meeting the internal condition is enough to validate the case. This triggers a Row Goal, as the optimizer must estimate how many rows it will need to read to satisfy (or not) this condition.
Note: In cases where the condition is never met, the optimizer’s plan can become highly inefficient; for full details, see Erik Darling’s blog [here].
We will now observe this behavior with the following query, varying the internal condition of the EXISTS clause by testing one highly selective (discriminant) case and another much less so.
SELECT
A.ArticleName,
A.Price
FROM Articles A
WHERE not EXISTS (
SELECT 1/0
FROM Inventory I
WHERE I.ArticleID = A.ArticleID
AND I.Quantity > 10 -- vs 98
);
As you may have noticed, I am looking here for products that maintain a certain quantity for every possible consumption date. My goal, of course, is to avoid depleting the stocks of these excellent Polish pierogis so that everyone can enjoy them!
The case where we want to ensure that all existing quantities for an item are greater than 10 is very difficult to satisfy; based on the statistics available to the optimizer, all items have 10 or more units in stock, except for the pierogis!
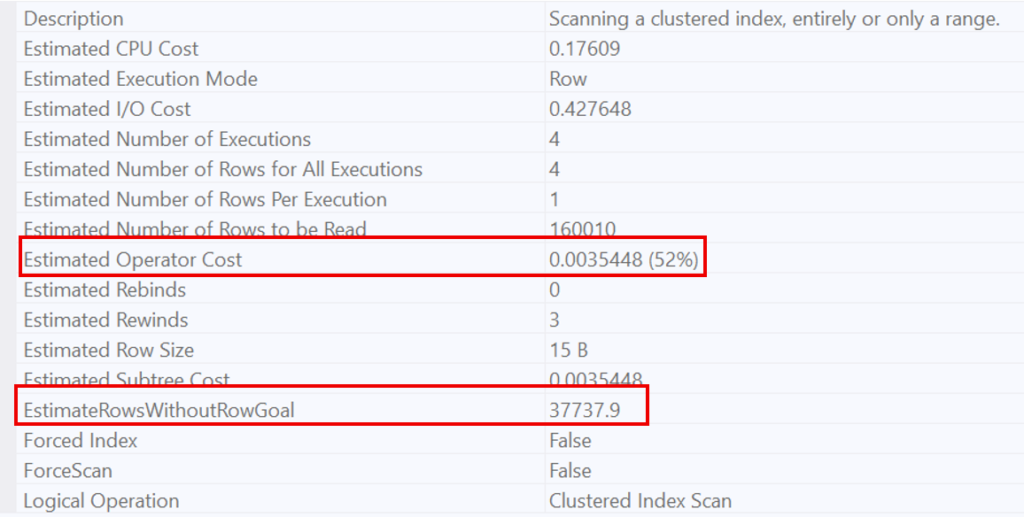
Since this condition is so widespread, the optimizer knows it will have to scan a large number of rows to find a single case where the condition is not met. This is why it opts for a Scan. This behavior is evidenced by the estimated number of rows to be read (160’010, which represents the entire table).
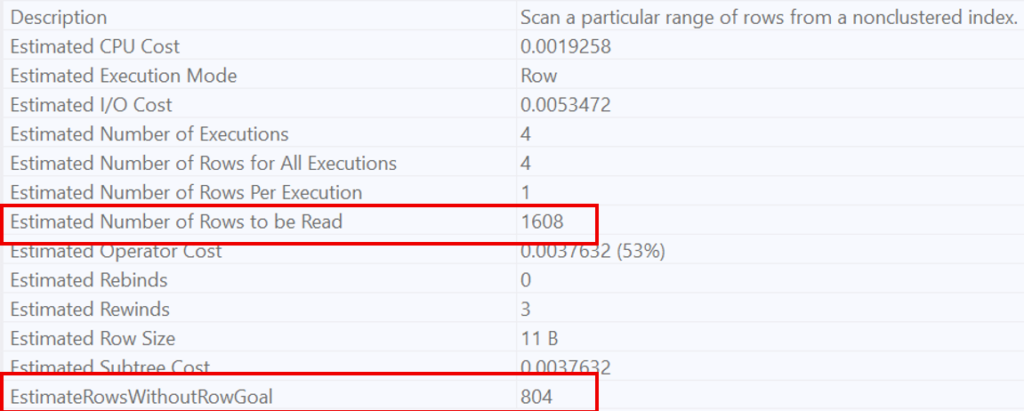
On the other hand, for a very restrictive condition (quantity > 98), the optimizer recognizes that this condition is highly selective. This is why it favors a Nested Loop, estimating that only 1’608 rows will be necessary to prove the non-existence of the condition.
In summary, EXISTS forces the optimizer to estimate the number of rows required to find a single occurrence that proves whether a condition is met or not, thereby triggering a local optimization of the execution plan.
The OPTION(FAST N) hint allows you to manually introduce the Row Goal concept into a query. This hint does not limit the total number of results returned; instead, it optimizes the execution plan to retrieve the first N rows as quickly as possible (potentially at the expense of performance for the remaining rows).
In our example below, we have two identical queries retrieving items with a quantity greater than 10. However, the second one uses an execution plan optimized to return the first row as fast as possible (just to make sure no one steals the last available pierogi from the top of the pile!).
select * from Inventory i
where i.Quantity > 10
order by i.ArticleID
select * from Inventory i
where i.Quantity > 10
order by i.ArticleID option(fast 1)
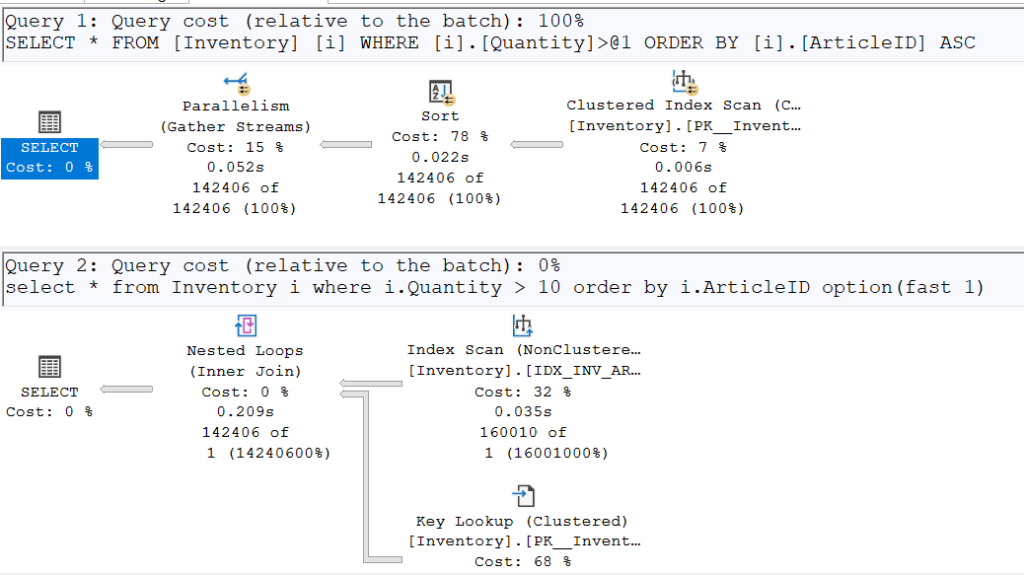
Once again, the plans diverge. To retrieve a single row, the IDX_INV_ART index (which already contains sorted ArticleIDs) is used. It performs a Seek on the smallest ArticleID to check if it satisfies the condition of having a quantity greater than 10.
However, by enabling SET STATISTICS TIME ON, we can see that the second execution plan is slower than the first when returning all requested rows (250ms vs. 204ms). While the gap is not massive due to the small table size, the difference is nonetheless observable.
To conclude, the Row Goal is a double-edged sword; brilliant when you only need a quick glimpse of your data, but it can become a real performance trap if the optimizer’s “bet” fails.
Fortunately, if you find that SQL Server is making bad decisions by being too optimistic, you can take back control. By using the hint OPTION (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL')), you force the optimizer to stop daydreaming and focus on the actual cost of the query. It’s the ultimate tool to ensure your execution plan doesn’t end up as messy as a dropped plate of pierogis!
L’article How Row Goal shapes your SQL Server query strategy by hunting for pierogis est apparu en premier sur dbi Blog.
SQL Server Snapshot Backup and Restore with Proxmox ZFS – REST API with SQL Server 2025 (3/3)
The proposed architecture consists in adding a small internal REST API on the Proxmox server in order to expose a controlled ZFS snapshot operation. SQL Server 2025 can then call this API through sp_invoke_external_rest_endpoint, instead of running SSH commands directly or relying on an external tool.
The role of the API is deliberately limited: it receives a snapshot request, checks that the requested zvol is authorized, and then runs the zfs snapshot command on the Proxmox side. An allowlist is used to restrict the ZFS volumes that can be accessed. This prevents a REST call from being able to manipulate any dataset on the server.
With this approach, we can reproduce a behavior close to what an enterprise storage array provides, but using Proxmox and ZFS. It is important to note that Proxmox does not natively provide the same level of integration as Pure Storage for SQL Server snapshots. Pure Storage provides dedicated mechanisms and integrations. In our case, we need to build a specific orchestration layer. The REST API therefore acts as an adapter between SQL Server, which drives the snapshot backup workflow, and ZFS, which actually performs the storage-level snapshot.
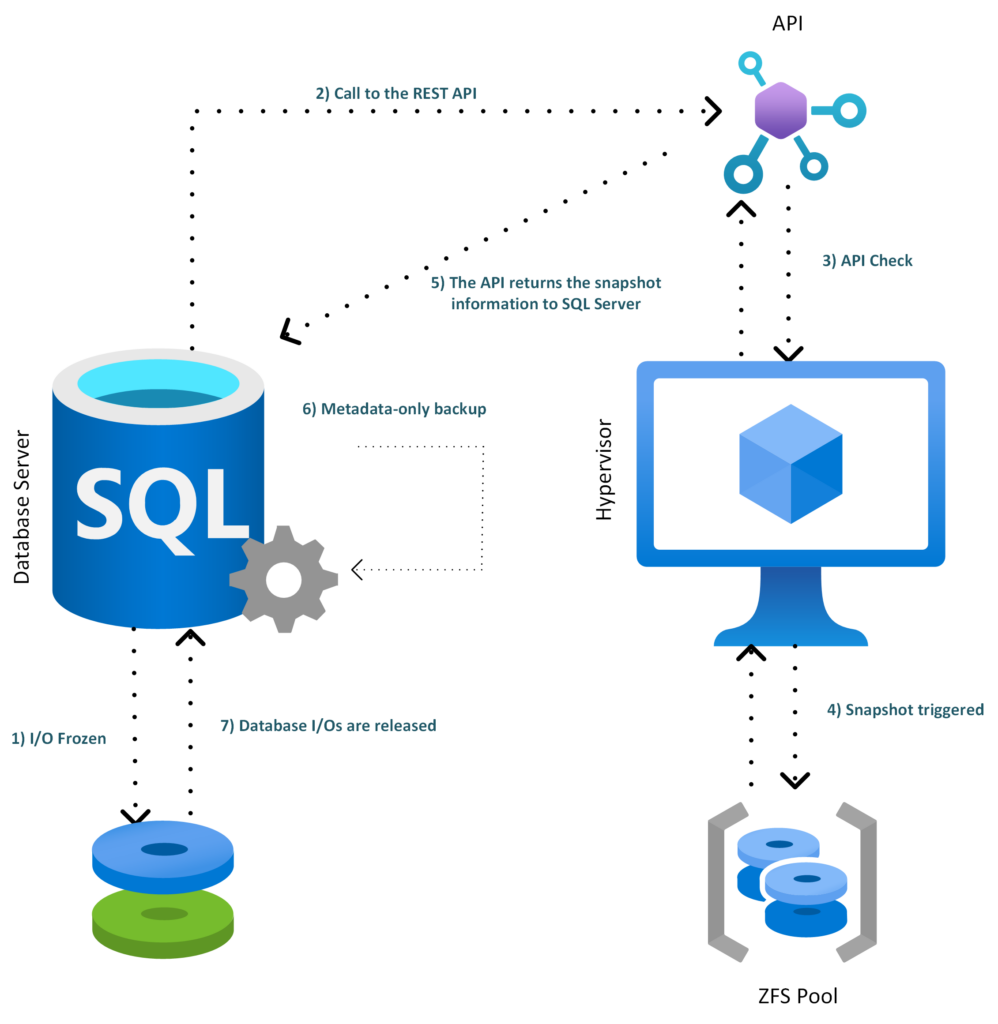
ArchitectureHere is a global overview of the architecture:
- SQL Server freezes the database I/Os
- SQL Server 2025 calls the internal REST API
- The REST API validates the request and checks the zvol allowlist
- The API triggers the ZFS snapshot on Proxmox
- The API returns the snapshot information to SQL Server
- SQL Server creates the metadata-only backup
- The database I/Os are released
 REST API implementation
REST API implementation
Under Proxmox, we install the required packages:
apt update
apt install -y python3-venv sudo opensslWe create a dedicated user:
useradd --system \
--home /opt/sql-zfs-api \
--shell /usr/sbin/nologin \
sqlsnapWe create the following folders:
mkdir -p /opt/sql-zfs-api
mkdir -p /etc/sql-zfs-apiWe declare the authorized zvol :
cat >/etc/sql-zfs-api/allowed-zvols <<'EOF'
sqlpool/pve/vm-302-disk-0
EOFWe create a root-only allowlist:
chown root:root /etc/sql-zfs-api/allowed-zvols
chmod 600 /etc/sql-zfs-api/allowed-zvolsThen we create the secured ZFS helper. This script is executed as root through sudo, but it rejects any dataset that is not defined in the allowlist.
cat >/usr/local/sbin/sql-zfs-helper <<'EOF'
#!/usr/bin/env bash
set -euo pipefail
ALLOW_FILE="/etc/sql-zfs-api/allowed-zvols"
LOCK_FILE="/run/sql-zfs-helper.lock"
die() {
echo "$*" >&2
exit 1
}
exec 9>"$LOCK_FILE"
flock -n 9 || die "another snapshot operation is already running"
[[ -r "$ALLOW_FILE" ]] || die "allowlist not readable: $ALLOW_FILE"
mapfile -t ALLOWED_DATASETS < <(grep -Ev '^\s*(#|$)' "$ALLOW_FILE")
is_allowed() {
local ds="$1"
local allowed
for allowed in "${ALLOWED_DATASETS[@]}"; do
[[ "$ds" == "$allowed" ]] && return 0
done
return 1
}
valid_snapname() {
[[ "$1" =~ ^[A-Za-z0-9_.:-]{1,120}$ ]]
}
ACTION="${1:-}"
shift || true
case "$ACTION" in
snapshot)
SNAPNAME="${1:-}"
shift || true
valid_snapname "$SNAPNAME" || die "invalid snapshot name: $SNAPNAME"
[[ "$#" -ge 1 ]] || die "no zvol specified"
[[ "$#" -le 8 ]] || die "too many zvols"
SNAPSHOTS=()
for DS in "$@"; do
is_allowed "$DS" || die "dataset not allowed: $DS"
/sbin/zfs list -H -t volume -o name "$DS" >/dev/null 2>&1 || die "zvol not found: $DS"
FULLSNAP="${DS}@${SNAPNAME}"
if /sbin/zfs list -H -t snapshot -o name "$FULLSNAP" >/dev/null 2>&1; then
die "snapshot already exists: $FULLSNAP"
fi
SNAPSHOTS+=("$FULLSNAP")
done
/sbin/zfs snapshot "${SNAPSHOTS[@]}"
/sbin/zfs hold sqlsnap "${SNAPSHOTS[@]}"
printf '{"status":"ok","snapshots":['
SEP=""
for S in "${SNAPSHOTS[@]}"; do
printf '%s"%s"' "$SEP" "$S"
SEP=","
done
printf ']}\n'
;;
list)
/sbin/zfs list -H -t snapshot -o name -r sqlpool | grep '@sql_' || true
;;
*)
die "usage: sql-zfs-helper snapshot SNAPNAME ZVOL [ZVOL...]"
;;
esac
EOF
chown root:root /usr/local/sbin/sql-zfs-helper
chmod 750 /usr/local/sbin/sql-zfs-helper
We only allow the helper through sudo:
cat >/etc/sudoers.d/sql-zfs-helper <<'EOF'
sqlsnap ALL=(root) NOPASSWD: /usr/local/sbin/sql-zfs-helper *
EOF
chmod 440 /etc/sudoers.d/sql-zfs-helper
visudo -cf /etc/sudoers.d/sql-zfs-helperWe install the FastAPI API:
python3 -m venv /opt/sql-zfs-api/venv
/opt/sql-zfs-api/venv/bin/pip install fastapi "uvicorn[standard]"We create the application file:
cat >/opt/sql-zfs-api/app.py <<'EOF'
import os
import re
import json
import socket
import secrets
import subprocess
from datetime import datetime, timezone
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel, Field
API_KEY = os.environ.get("SQL_ZFS_API_KEY", "")
ALLOW_FILE = "/etc/sql-zfs-api/allowed-zvols"
SNAP_RE = re.compile(r"^[A-Za-z0-9_.:-]{1,120}$")
app = FastAPI(title="SQL ZFS Snapshot API", version="1.0.0")
class SnapshotRequest(BaseModel):
database: str = Field(..., min_length=1, max_length=128)
vmid: int = 302
snapname: str = Field(..., min_length=1, max_length=120)
zvols: list[str] = Field(..., min_length=1, max_length=8)
def load_allowed_zvols() -> set[str]:
with open(ALLOW_FILE, "r", encoding="utf-8") as f:
return {
line.strip()
for line in f
if line.strip() and not line.strip().startswith("#")
}
def check_api_key(x_sqlsnap_key: str | None) -> None:
if not API_KEY:
raise HTTPException(status_code=500, detail="API key not configured")
if not x_sqlsnap_key:
raise HTTPException(status_code=401, detail="missing API key")
if not secrets.compare_digest(x_sqlsnap_key, API_KEY):
raise HTTPException(status_code=403, detail="invalid API key")
@app.get("/health")
def health():
return {
"status": "ok",
"host": socket.gethostname(),
"utc": datetime.now(timezone.utc).isoformat(),
}
@app.post("/v1/sql-zfs/snapshot")
def create_snapshot(
req: SnapshotRequest,
x_sqlsnap_key: str | None = Header(default=None, alias="x-sqlsnap-key"),
):
check_api_key(x_sqlsnap_key)
if not SNAP_RE.fullmatch(req.snapname):
raise HTTPException(status_code=400, detail="invalid snapname")
allowed = load_allowed_zvols()
for zvol in req.zvols:
if zvol not in allowed:
raise HTTPException(status_code=403, detail=f"zvol not allowed: {zvol}")
cmd = [
"sudo",
"/usr/local/sbin/sql-zfs-helper",
"snapshot",
req.snapname,
*req.zvols,
]
try:
completed = subprocess.run(
cmd,
text=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
timeout=30,
check=False,
)
except subprocess.TimeoutExpired:
raise HTTPException(status_code=504, detail="zfs snapshot timeout")
if completed.returncode != 0:
raise HTTPException(
status_code=500,
detail={
"error": completed.stderr.strip(),
"stdout": completed.stdout.strip(),
},
)
snapshots = [f"{zvol}@{req.snapname}" for zvol in req.zvols]
return {
"status": "ok",
"database": req.database,
"vmid": req.vmid,
"snapname": req.snapname,
"snapshots": snapshots,
"media_description": "zfs|" + socket.gethostname() + "|" + ";".join(snapshots),
}
EOF
chown -R root:root /opt/sql-zfs-api
chmod 755 /opt/sql-zfs-api
chmod 644 /opt/sql-zfs-api/app.py
We configure and generate the key:
APIKEY="$(openssl rand -hex 32)"
echo "$APIKEY"We create the environment file:
cat >/etc/sql-zfs-api/sql-zfs-api.env <<EOF
SQL_ZFS_API_KEY=$APIKEY
EOF
chown root:root /etc/sql-zfs-api/sql-zfs-api.env
chmod 600 /etc/sql-zfs-api/sql-zfs-api.envWe need to save the generated key.
Next, we enable HTTPS. SQL Server sp_invoke_external_rest_endpoint calls HTTPS endpoints, and the documentation specifies that only HTTPS endpoints with TLS are supported.
openssl req -x509 -newkey rsa:4096 -sha256 -days 360 -nodes \
-keyout /etc/sql-zfs-api/tls.key \
-out /etc/sql-zfs-api/tls.crt \
-subj "/CN=promox1" \
-addext "subjectAltName=DNS:promox1,IP:192.168.1.110"
chown root:sqlsnap /etc/sql-zfs-api/tls.key /etc/sql-zfs-api/tls.crt
chmod 640 /etc/sql-zfs-api/tls.key
chmod 644 /etc/sql-zfs-api/tls.crtThe /etc/sql-zfs-api/tls.crt certificate must be imported into the Windows trusted root certification authorities on the SQL Server side. Otherwise, the HTTPS call may fail.
We create the systemd service:
cat >/etc/systemd/system/sql-zfs-api.service <<'EOF'
[Unit]
Description=SQL Server to ZFS Snapshot API
After=network-online.target
Wants=network-online.target
[Service]
User=sqlsnap
Group=sqlsnap
WorkingDirectory=/opt/sql-zfs-api
EnvironmentFile=/etc/sql-zfs-api/sql-zfs-api.env
ExecStart=/opt/sql-zfs-api/venv/bin/uvicorn app:app --host 0.0.0.0 --port 8443 --ssl-keyfile /etc/sql-zfs-api/tls.key --ssl-certfile /etc/sql-zfs-api/tls.crt
Restart=on-failure
RestartSec=3
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now sql-zfs-api
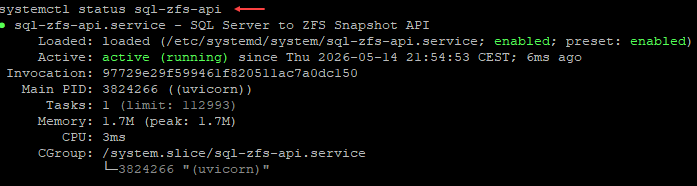
systemctl status sql-zfs-api
We check the status of our API:
It is possible to call the API in PowerShell using Invoke-RestMethod with PowerShell 7:
$headers = @{
"Content-Type" = "application/json"
"x-sqlsnap-key" = "MyKey"
}
$body = @{
database = "StackOverflow"
vmid = 302
snapname = "StackOverflow_test010"
zvols = @("sqlpool/pve/vm-302-disk-0")
} | ConvertTo-Json -Depth 5
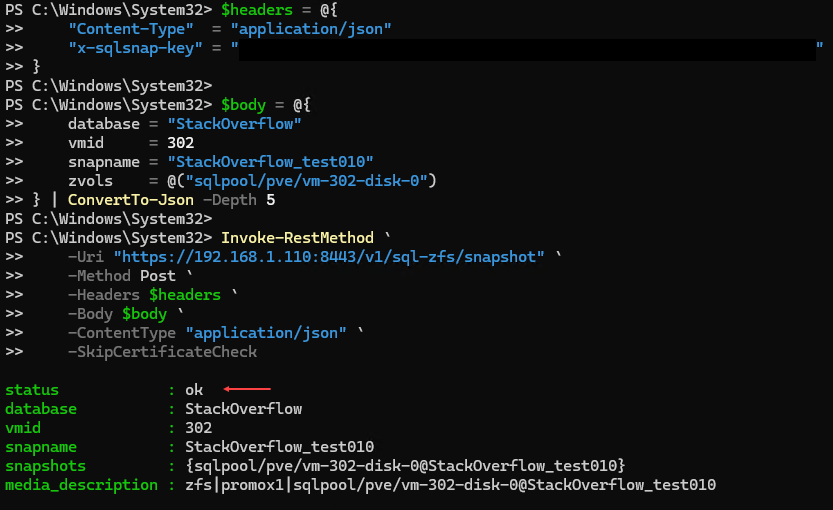
Invoke-RestMethod `
-Uri "https://192.168.1.110:8443/v1/sql-zfs/snapshot" `
-Method Post `
-Headers $headers `
-Body $body `
-ContentType "application/json" `
-SkipCertificateCheck
This gives:
 Test from SQL Server
Test from SQL Server
A certificate was generated on Proxmox and it needs to be imported on the SQL Server host. In my case, it was located here:

I then imported it on Windows Server:


For testing purposes, I created something simple. On the SQL Server side, we can create a database that will be used to store our future stored procedure. This procedure will allow us to interact with the API. In my case, I created a database called dbi_tools:
This database will contain a credential. In our case, the DATABASE SCOPED CREDENTIAL is used to securely store the authentication information required to call the REST API from SQL Server. This allows us, for example, to protect the API key:
USE [dbi_tools]
GO
IF NOT EXISTS (
SELECT 1
FROM sys.symmetric_keys
WHERE name = '##MS_DatabaseMasterKey##'
)
BEGIN
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'MyStrongPassword_%99';
END
GO
CREATE DATABASE SCOPED CREDENTIAL [https://192.168.1.110:8443/v1/sql-zfs/snapshot]
WITH
IDENTITY = 'HTTPEndpointHeaders',
SECRET = '{"x-sqlsnap-key":"MyAPIKey"}';
GOWe then create a stored procedure to encapsulate the code used to call the API:
USE dbi_tools;
GO
CREATE OR ALTER PROCEDURE dbo.usp_BackupDatabase_WithZfsSnapshot
@DatabaseName sysname,
@BackupDirectory nvarchar(4000) = N'D:\Backups\'
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Url nvarchar(4000) =
N'https://192.168.1.110:8443/v1/sql-zfs/snapshot';
DECLARE @Vmid int = 302;
DECLARE @ZvolsJson nvarchar(max) =
N'["sqlpool/pve/vm-302-disk-0"]';
DECLARE @Stamp varchar(20) =
REPLACE(REPLACE(CONVERT(varchar(19), SYSUTCDATETIME(), 126), '-', ''), ':', '') + 'Z';
DECLARE @SafeDbName nvarchar(128) =
REPLACE(REPLACE(REPLACE(@DatabaseName, N' ', N'_'), N'[', N''), N']', N'');
DECLARE @SnapName nvarchar(128) =
CONCAT(N'sql_', @SafeDbName, N'_', @Stamp);
DECLARE @BackupFile nvarchar(4000) =
CONCAT(@BackupDirectory, N'\', @SafeDbName, N'_', @Stamp, N'.bkm');
DECLARE @Payload nvarchar(max) =
(
SELECT
@DatabaseName AS [database],
@Vmid AS [vmid],
@SnapName AS [snapname],
JSON_QUERY(@ZvolsJson) AS [zvols]
FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
);
DECLARE @ReturnCode int;
DECLARE @Response nvarchar(max);
DECLARE @SnapshotList nvarchar(max);
SELECT @SnapshotList =
STRING_AGG(CONCAT([value], N'@', @SnapName), N';')
FROM OPENJSON(@ZvolsJson);
DECLARE @MediaDescription nvarchar(max) =
CONCAT(N'zfs|promox1|', @SnapshotList);
DECLARE @Sql nvarchar(max);
BEGIN TRY
SET @Sql =
N'ALTER DATABASE ' + QUOTENAME(@DatabaseName) +
N' SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON;';
EXEC sys.sp_executesql @Sql;
EXEC @ReturnCode = sys.sp_invoke_external_rest_endpoint
@url = @Url,
@method = N'POST',
@headers = N'{"Content-Type":"application/json","Accept":"application/json"}',
@payload = @Payload,
@credential = [https://192.168.1.110:8443/v1/sql-zfs/snapshot],
@timeout = 30,
@response = @Response OUTPUT;
IF @ReturnCode <> 0
BEGIN
DECLARE @Err nvarchar(max) =
CONCAT(N'ZFS snapshot API failed. ReturnCode=', @ReturnCode, N' Response=', @Response);
THROW 51001, @Err, 1;
END;
SET @Sql =
N'BACKUP DATABASE ' + QUOTENAME(@DatabaseName) + N'
TO DISK = @BackupFile
WITH METADATA_ONLY,
FORMAT,
MEDIANAME = @MediaName,
MEDIADESCRIPTION = @MediaDescription,
NAME = @BackupName;';
EXEC sys.sp_executesql
@Sql,
N'@BackupFile nvarchar(4000),
@MediaName nvarchar(128),
@MediaDescription nvarchar(max),
@BackupName nvarchar(128)',
@BackupFile = @BackupFile,
@MediaName = @SnapName,
@MediaDescription = @MediaDescription,
@BackupName = @SnapName;
SELECT
@DatabaseName AS database_name,
@SnapName AS zfs_snapshot_name,
@SnapshotList AS zfs_snapshots,
@BackupFile AS metadata_backup_file,
@MediaDescription AS media_description,
@Response AS api_response;
END TRY
BEGIN CATCH
IF DATABASEPROPERTYEX(@DatabaseName, 'IsDatabaseSuspendedForSnapshotBackup') = 1
BEGIN
SET @Sql =
N'ALTER DATABASE ' + QUOTENAME(@DatabaseName) +
N' SET SUSPEND_FOR_SNAPSHOT_BACKUP = OFF;';
EXEC sys.sp_executesql @Sql;
END;
THROW;
END CATCH
END;
GO
We then call the stored procedure:
EXEC dbi_tools.dbo.usp_BackupDatabase_WithZfsSnapshot
@DatabaseName = N'StackOverflow',
@BackupDirectory = N'D:\Backups\';
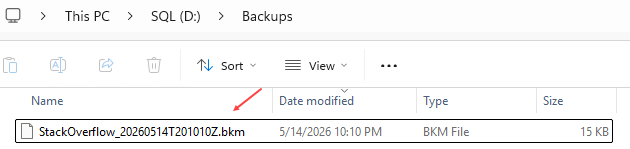
The backup was generated :
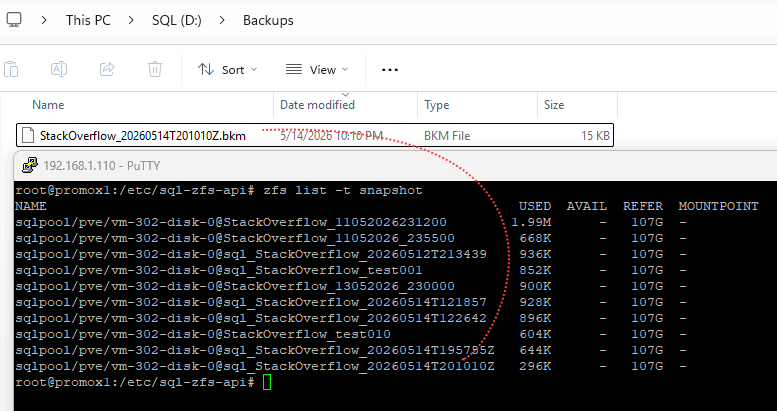 References
References
sp_invoke_external_rest_endpoint
Thank you. Amine Haloui
L’article SQL Server Snapshot Backup and Restore with Proxmox ZFS – REST API with SQL Server 2025 (3/3) est apparu en premier sur dbi Blog.
SQL Server Snapshot Backup and Restore with Proxmox ZFS – Powershell implementation (2/3)
In the previous section, we discussed the drawbacks of running the commands manually. Indeed, the manual process was taking too much time and could directly impact the database state while the freeze was occurring.
To address this issue, it is possible to automate the solution with PowerShell. The idea is to automate the different operations involved in the snapshot backup and restore process.
We will use two scripts:
- One script to perform the backups and create the snapshots.
- One script to perform the restores.
Here is how the backup process works:
- We connect to the corresponding SQL Server instance.
- We change the state of the database using ALTER DATABASE … SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON. At this point, the I/Os are frozen.
- We connect to the hypervisor through SSH.
- We create the snapshot.
- We back up the database using BACKUP DATABASE … WITH METADATA_ONLY.
- We change the state of the database using ALTER DATABASE … SET SUSPEND_FOR_SNAPSHOT_BACKUP = OFF. At this point, the I/Os are unfrozen.
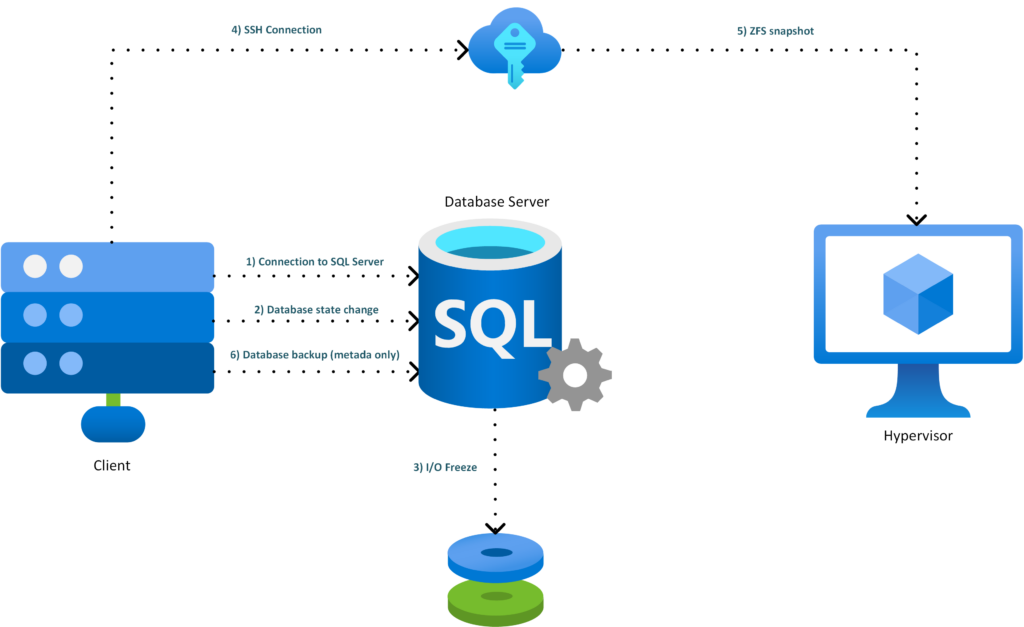 Powershell implementation (backup)
Powershell implementation (backup)
Here is the code used to perform the backup:
param(
[string]$SqlInstance = "VM-WS25-SQL2",
[string]$Database = "StackOverflow",
[string]$BackupDir = "D:\Backups",
[string]$PveHost = "192.168.1.110",
[string]$PveUser = "MyUser",
[string[]]$Zvols = @("sqlpool/pve/vm-302-disk-0")
)
$Timestamp = Get-Date -Format "yyyyMMddTHHmmss"
$SnapName = "sql_${Database}_${Timestamp}"
$DbSafe = $Database.Replace("]", "]]")
$BackupFile = Join-Path $BackupDir "${Database}_${Timestamp}.bkm"
$ZfsSnapshots = $Zvols | ForEach-Object { "$_@$SnapName" }
$ZfsSnapshotArgs = $ZfsSnapshots -join " "
$MediaDescription = "zfs|$PveHost|$ZfsSnapshotArgs"
$BackupFileSql = $BackupFile.Replace("'", "''")
$MediaSql = $MediaDescription.Replace("'", "''")
$connString = "Server=$SqlInstance;Database=master;Integrated Security=True;TrustServerCertificate=True;Application Name=ZFS-TSQL-Snapshot;"
$conn = New-Object System.Data.SqlClient.SqlConnection $connString
function Invoke-SqlNonQuery {
param([string]$Sql)
$cmd = $conn.CreateCommand()
$cmd.CommandTimeout = 0
$cmd.CommandText = $Sql
[void]$cmd.ExecuteNonQuery()
}
try {
$conn.Open()
Write-Host "Freezing SQL database writes..."
Invoke-SqlNonQuery "ALTER DATABASE [$DbSafe] SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON;"
Write-Host "Taking ZFS snapshot on Proxmox..."
ssh "$PveUser@$PveHost" "zfs snapshot $ZfsSnapshotArgs && zfs hold sqlsnap $ZfsSnapshotArgs"
if ($LASTEXITCODE -ne 0) {
throw "ZFS snapshot failed on $PveHost"
}
Write-Host "Writing SQL metadata backup..."
Invoke-SqlNonQuery @"
BACKUP DATABASE [$DbSafe]
TO DISK = N'$BackupFileSql'
WITH METADATA_ONLY,
MEDIADESCRIPTION = N'$MediaSql',
NAME = N'$SnapName';
"@
Write-Host "Snapshot backup completed:"
Write-Host " Snapshot: $ZfsSnapshotArgs"
Write-Host " Metadata: $BackupFile"
}
catch {
Write-Warning $_
try {
Write-Warning "Attempting to unfreeze SQL database..."
Invoke-SqlNonQuery "ALTER DATABASE [$DbSafe] SET SUSPEND_FOR_SNAPSHOT_BACKUP = OFF;"
}
catch {
Write-Warning "Could not unfreeze cleanly. Check SQL Server error log."
}
throw
}
finally {
$conn.Close()
}Here is how the restore process works:
- We connect to the corresponding SQL Server instance.
- We take the database offline.
- The volume dedicated to the StackOverflow database is taken offline.
- We connect to the hypervisor through SSH.
- We roll back the corresponding snapshot.
- We restore the database using the corresponding backup, which was created at the same time as the snapshot.
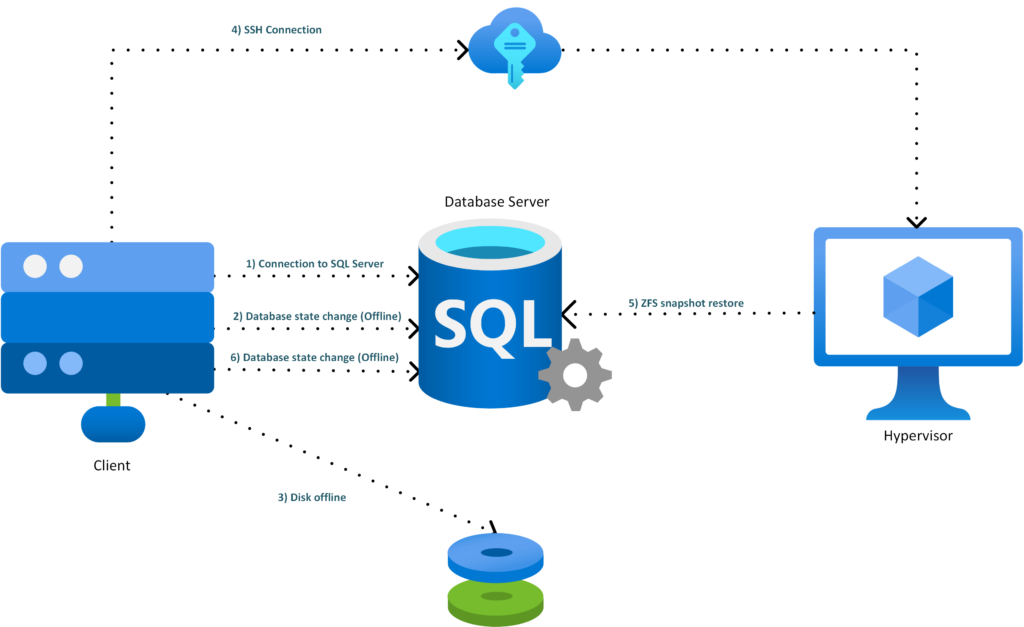 Powershell implementation (restore)
Powershell implementation (restore)
Here is the code used to perform the restore:
param(
[string]$SqlInstance = "VM-WS25-SQL2",
[string]$Database = "StackOverflow",
[string]$BackupFile = "D:\Backups\StackOverflow_20260514T122642.bkm",
[string]$SnapName = "sql_StackOverflow_20260514T122642",
[string]$PveHost = "192.168.1.110",
[string]$PveUser = "MyUser",
[string[]]$Zvols = @("sqlpool/pve/vm-302-disk-0"),
[string[]]$DatabaseDriveLetters = @("T"),
[switch]$NoRecovery
)
$ErrorActionPreference = "Stop"
function Assert-SafeName {
param(
[string]$Value,
[string]$Name,
[string]$Pattern
)
if ($Value -notmatch $Pattern) {
throw "$Name contained not allowed characters : $Value"
}
}
function Normalize-DriveLetter {
param([string]$DriveLetter)
$letter = $DriveLetter.Trim().TrimEnd(":").ToUpperInvariant()
if ($letter -notmatch '^[A-Z]$') {
throw "Drive letter invalid : $DriveLetter"
}
return $letter
}
function Get-DiskForDriveLetter {
param([string]$DriveLetter)
$letter = Normalize-DriveLetter $DriveLetter
$partition = Get-Partition -DriveLetter $letter -ErrorAction Stop
$disk = $partition | Get-Disk -ErrorAction Stop
return [pscustomobject]@{
DriveLetter = $letter
DiskNumber = [int]$disk.Number
IsOffline = [bool]$disk.IsOffline
FriendlyName = $disk.FriendlyName
Size = $disk.Size
}
}
function Invoke-SshChecked {
param([string]$Command)
Write-Host "SSH $PveUser@$PveHost :: $Command"
& ssh "$PveUser@$PveHost" "$Command"
if ($LASTEXITCODE -ne 0) {
throw "SSH command failed with code $LASTEXITCODE : $Command"
}
}
function New-SqlConnection {
$connString = "Server=$SqlInstance;Database=master;Integrated Security=True;TrustServerCertificate=True;Application Name=ZFS-TSQL-Restore-NoVmRestart;"
return New-Object System.Data.SqlClient.SqlConnection $connString
}
function Invoke-SqlNonQuery {
param([string]$Sql)
$conn = New-SqlConnection
try {
$conn.Open()
$cmd = $conn.CreateCommand()
$cmd.CommandTimeout = 0
$cmd.CommandText = $Sql
[void]$cmd.ExecuteNonQuery()
}
finally {
$conn.Close()
}
}
function Invoke-SqlScalar {
param([string]$Sql)
$conn = New-SqlConnection
try {
$conn.Open()
$cmd = $conn.CreateCommand()
$cmd.CommandTimeout = 0
$cmd.CommandText = $Sql
return $cmd.ExecuteScalar()
}
finally {
$conn.Close()
}
}
function Set-DatabaseDisksOffline {
param([object[]]$DiskInfos)
$offlinedByScript = @()
foreach ($diskInfo in ($DiskInfos | Sort-Object DiskNumber -Unique)) {
if ($diskInfo.IsOffline) {
Write-Host "Disque $($diskInfo.DiskNumber) déjà offline. Lecteur $($diskInfo.DriveLetter):"
continue
}
Write-Host "Taking the Windows disk offline $($diskInfo.DiskNumber), drive $($diskInfo.DriveLetter):"
Set-Disk -Number $diskInfo.DiskNumber -IsOffline $true
$offlinedByScript += $diskInfo
}
return $offlinedByScript
}
function Set-DatabaseDisksOnline {
param([object[]]$DiskInfos)
foreach ($diskInfo in ($DiskInfos | Sort-Object DiskNumber -Unique)) {
Write-Host "Bringing the Windows disk back online. $($diskInfo.DiskNumber), drive $($diskInfo.DriveLetter):"
Set-Disk -Number $diskInfo.DiskNumber -IsOffline $false
}
Write-Host "Update-HostStorageCache..."
Update-HostStorageCache
}
Assert-SafeName -Value $SnapName -Name "SnapName" -Pattern '^[A-Za-z0-9_.:-]{1,160}$'
foreach ($zvol in $Zvols) {
Assert-SafeName -Value $zvol -Name "Zvol" -Pattern '^[A-Za-z0-9_.:/-]{1,240}$'
}
$DbQuoted = "[" + $Database.Replace("]", "]]") + "]"
$DbLiteral = $Database.Replace("'", "''")
$BackupFileSql = $BackupFile.Replace("'", "''")
$ZfsSnapshots = $Zvols | ForEach-Object { "$_@$SnapName" }
$ZfsSnapshotArgs = ($ZfsSnapshots | ForEach-Object { "'$_'" }) -join " "
$RecoveryOption = if ($NoRecovery) { "NORECOVERY" } else { "RECOVERY" }
$DatabaseDiskInfos = @()
$DisksOfflinedByScript = @()
Write-Host ""
Write-Host "Restore SQL Server from a ZFS snapshot, without restarting the VM"
Write-Host "SQL Instance : $SqlInstance"
Write-Host "Database : $Database"
Write-Host "BackupFile : $BackupFile"
Write-Host "DB volumes : $($DatabaseDriveLetters -join ', ')"
Write-Host "Snapshots :"
$ZfsSnapshots | ForEach-Object { Write-Host " $_" }
Write-Host ""
try {
Write-Host "Checking ZFS snapshots..."
Invoke-SshChecked "zfs list -H -t snapshot -o name $ZfsSnapshotArgs >/dev/null"
Write-Host "Identifying Windows disks containing SQL Server files..."
foreach ($driveLetter in $DatabaseDriveLetters) {
$diskInfo = Get-DiskForDriveLetter $driveLetter
$DatabaseDiskInfos += $diskInfo
Write-Host "Drive $($diskInfo.DriveLetter): -> Windows disk $($diskInfo.DiskNumber) [$($diskInfo.FriendlyName)]"
}
$backupDrive = $null
if ($BackupFile -match '^([A-Za-z]):\\') {
$backupDrive = Normalize-DriveLetter $Matches[1]
try {
$backupDiskInfo = Get-DiskForDriveLetter $backupDrive
$targetDiskNumbers = @($DatabaseDiskInfos | ForEach-Object { $_.DiskNumber } | Select-Object -Unique)
if ($targetDiskNumbers -contains $backupDiskInfo.DiskNumber) {
throw @"
The backup file $BackupFile is located on drive $backupDrive, which is on the same Windows disk as the SQL Server data volume.
Taking the data disk offline would make the .bkm file inaccessible, and a rollback could also make the .bkm file disappear.
Move the .bkm file to C:, a network share, or another disk that is not rolled back.
"@
}
}
catch {
throw
}
}
Write-Host "Checking whether the SQL Server database exists..."
$DbExists = Invoke-SqlScalar "SELECT CASE WHEN DB_ID(N'$DbLiteral') IS NULL THEN 0 ELSE 1 END;"
if ($DbExists -eq 1) {
Write-Host "Taking database $Database OFFLINE..."
Invoke-SqlNonQuery @"
ALTER DATABASE $DbQuoted SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
ALTER DATABASE $DbQuoted SET OFFLINE WITH ROLLBACK IMMEDIATE;
"@
}
else {
Write-Host "Database $Database does not exist in SQL Server. Continuing with disk offline and ZFS rollback."
}
Write-Host "Taking Windows disks containing MDF/LDF files offline..."
$DisksOfflinedByScript = Set-DatabaseDisksOffline -DiskInfos $DatabaseDiskInfos
Write-Host "Rolling back ZFS snapshot..."
$RollbackCommands = ($ZfsSnapshots | ForEach-Object { "zfs rollback -r '$_'" }) -join "; "
Invoke-SshChecked "set -e; $RollbackCommands"
Write-Host "Bringing Windows disks back online..."
Set-DatabaseDisksOnline -DiskInfos $DisksOfflinedByScript
$DisksOfflinedByScript = @()
Write-Host "Short pause to let Windows and SQL Server detect the restored disk state..."
Start-Sleep -Seconds 5
Write-Host "Restoring SQL Server metadata-only backup..."
$RestoreSql = @"
RESTORE DATABASE $DbQuoted
FROM DISK = N'$BackupFileSql'
WITH METADATA_ONLY,
REPLACE,
$RecoveryOption;
"@
Invoke-SqlNonQuery $RestoreSql
if (-not $NoRecovery) {
Write-Host "Setting database back to MULTI_USER..."
Invoke-SqlNonQuery @"
ALTER DATABASE $DbQuoted SET MULTI_USER;
"@
}
Write-Host ""
Write-Host "Restore completed."
Write-Host "Database : $Database"
Write-Host "Snapshot : $SnapName"
Write-Host "Backup : $BackupFile"
}
catch {
Write-Warning "Restore failed: $_"
if ($DisksOfflinedByScript.Count -gt 0) {
try {
Write-Warning "Attempting to bring disks offlined by the script back online..."
Set-DatabaseDisksOnline -DiskInfos $DisksOfflinedByScript
$DisksOfflinedByScript = @()
}
catch {
Write-Warning "Unable to automatically bring the disks back online. Check with Get-Disk."
}
}
try {
$DbExistsAfterError = Invoke-SqlScalar "SELECT CASE WHEN DB_ID(N'$DbLiteral') IS NULL THEN 0 ELSE 1 END;"
if ($DbExistsAfterError -eq 1 -and -not $NoRecovery) {
Write-Warning "Attempting to set the database back ONLINE/MULTI_USER..."
Invoke-SqlNonQuery @"
ALTER DATABASE $DbQuoted SET ONLINE;
ALTER DATABASE $DbQuoted SET MULTI_USER;
"@
}
}
catch {
Write-Warning "Unable to automatically set the database back ONLINE/MULTI_USER."
}
throw
}We start the backup process:

We verify that the snapshot is present:

We verify that the backup is present:
We drop the StackOverflow database:
We start the restore process:
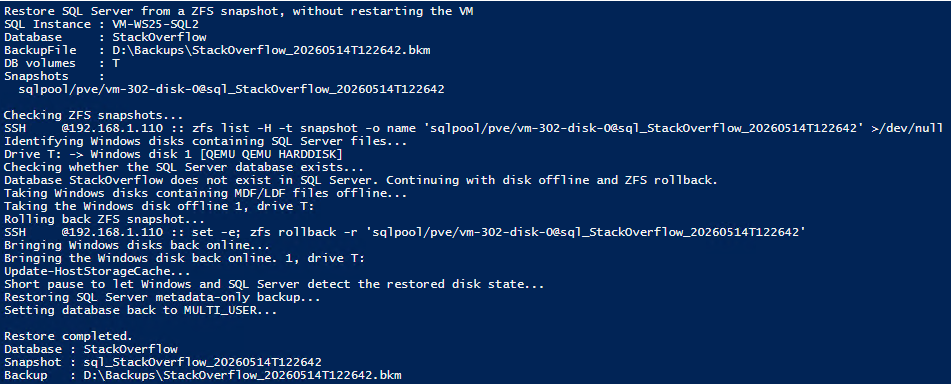
The database is available again. The restore took only a few seconds for a database of approximately 200 GB.
Major drawbacksIn my case, the solution is executed from the SQL Server itself. Ideally, it should rather be hosted on another server or client machine. We could also imagine running these scripts from a scheduler such as RedDeck, for example.
During the database restore, the database is switched to SINGLE_USER mode. This could be an issue if the applications using the database reconnect very frequently. A better approach would probably be to explicitly terminate the active sessions using the KILL command.
We have also not yet covered the use of a REST API.
Thank you. Amine Haloui
L’article SQL Server Snapshot Backup and Restore with Proxmox ZFS – Powershell implementation (2/3) est apparu en premier sur dbi Blog.
SQL Server Snapshot Backup and Restore with Proxmox ZFS (1/3)
We are currently working with clients on migrations to SQL Server 2022 and SQL Server 2025. During a discussion with one client, we reviewed some of the benefits introduced in the latest SQL Server 2022 and 2025 releases.
Among the available features, starting with SQL Server 2022, we have:
- T-SQL snapshot backup : https://learn.microsoft.com/en-us/sql/relational-databases/backup-restore/create-a-transact-sql-snapshot-backup?view=sql-server-ver17
Starting with SQL Server 2025:
- REST API Call through sp_invoke_external_rest_endpoint : https://learn.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-invoke-external-rest-endpoint-transact-sql?view=sql-server-ver17&tabs=request-headers
The customer’s environment consists of a very large number of instances, some of which host very large SQL Server databases. In this customer’s case, we are referring to a database of approximately 6–7 TB, configured for high availability using Always On Availability Groups. For this database, backups take around two hours, and restores take slightly longer.
In addition, the customer has a Pure Storage array.
We explained to the customer that it is possible to use certain SQL Server 2025 features together with their Pure Storage array to perform snapshots and restores very quickly.
In summary, the process consists of performing the following operations:
- Change the database state to suspend writes.
- Create the snapshot using the storage system.
- Perform a backup using the BACKUP DATABASE MyDB WITH METADATA_ONLY command to indicate that a snapshot has been taken.
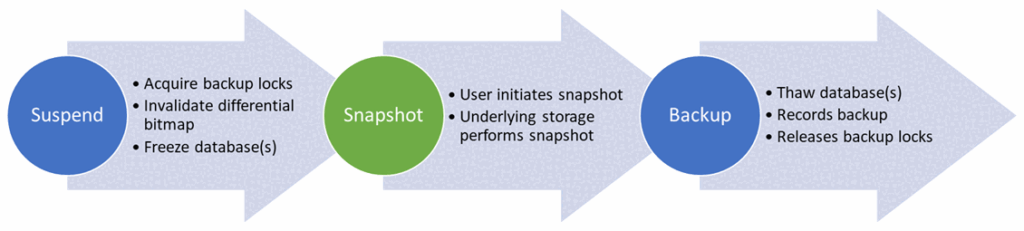
However, the customer raised several interesting questions, which, reading between the lines, can be summarized as follows:
- Can this also be applied to PostgreSQL?
- Are we dependent on Pure Storage to achieve this?
Several articles have been published about the implementation of this process between SQL Server and Pure Storage including the following one:
In my opinion, it is possible to reproduce this operating model with other systems. In my case, we will use Proxmox and ZFS.
Context and environmentZFS pool provides fast, storage-level, copy-on-write snapshots with minimal space overhead. This makes it well suited for SQL Server snapshot backups, where the database writes are briefly suspended while the underlying virtual disk is captured. ZFS also allows precise rollback or cloning of a snapshot, which is useful for both restore testing and recovery scenarios.
On Proxmox, it integrates naturally with VM disks, making it a practical alternative to enterprise storage snapshot platforms.
The environment consists of a server and two disks: one disk used to store the VMs, and a 1 TB Samsung T7 disk that will be used to create our ZFS pool.
Proxmox SetupWe identity the path of the related volume (Samsung T7) :
for d in /dev/disk/by-id/*; do
[ "$(readlink -f "$d")" = "/dev/sda" ] && echo "$d"
done
We create the pool. Everything stored in the disk will be erased :
DISK="/dev/disk/by-id/usb-Samsung_PSSD_T7_S6TWNJ0T300328F-0:0"
wipefs -a "$DISK"
sgdisk --zap-all "$DISK"
zpool create \
-o ashift=12 \
-o autotrim=on \
-O compression=lz4 \
-O atime=off \
-O xattr=sa \
-O acltype=posixacl \
-m /mnt/sqlpool \
sqlpool "$DISK"Then we create a Proxmox dataset for the VM disks:
zfs create sqlpool/pveWe add it to proxmox:
pvesm add zfspool sql-zfs \
--pool sqlpool/pve \
--content images,rootdir \
--sparse 1We check the pool:
zpool status sqlpool
zfs list
pvesm status
pool: sqlpool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
sqlpool ONLINE 0 0 0
usb-Samsung_PSSD_T7_S6TWNJ0T300328F-0:0 ONLINE 0 0 0
errors: No known data errors
NAME USED AVAIL REFER MOUNTPOINT
sqlpool 636K 899G 96K /mnt/sqlpool
sqlpool/pve 96K 899G 96K /mnt/sqlpool/pve
Name Type Status Total (KiB) Used (KiB) Available (KiB) %
local dir active 98497780 42429080 51019152 43.08%
local-lvm lvmthin active 3746553856 285112748 3461441107 7.61%
sql-zfs zfspool active 942931428 96 942931332 0.00%My VM ID is 302 and we have to add the virtual disk into the ZFS pool:
VMID=302
qm set "$VMID" --agent enabled=1
qm set "$VMID" --scsihw virtio-scsi-single
qm set "$VMID" --scsi1 sql-zfs:700,cache=none,discard=on,iothread=1,ssd=1Be carefull to the scsi ID. You may overwrite a used volume.
What does it look like ?Once the pool created we have something like this :
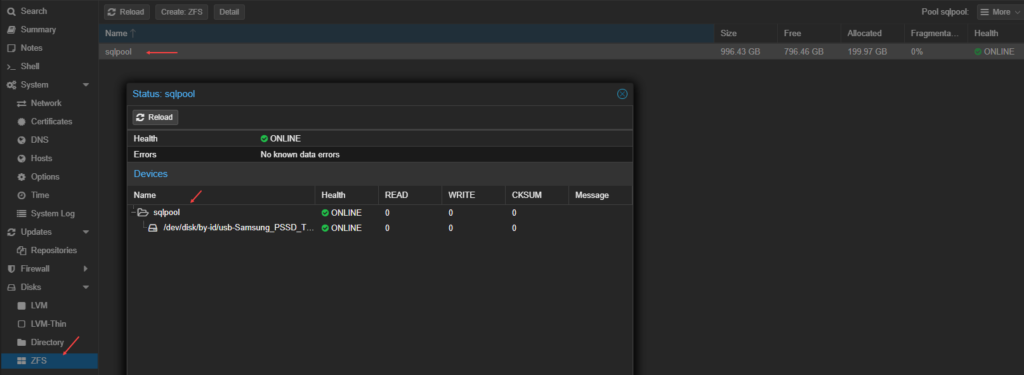
On the virtual machine side, I have 3 disks :
- 1 for my virtual machine (for Windows Server)
- 1 for SQL Server
- 1 linked to the ZFS pool to store the user database (the StackOverflow database)
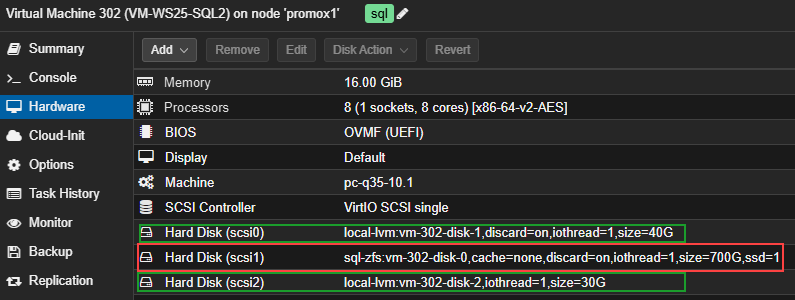 SQL Server setup
SQL Server setup
The virtual machine used for the tests runs with:
- Windows Server 2025 Standard Edition
- SQL Server 2025 Enterprise Developer Edition
The mounted zvol is represented by the Databases (T:) volume. Most of the files related to the SQL Server installation are stored on the SQL (D:) volume while the StackOverflow database is located on the Databases (T:) volume.
 Manual process flow (snapshot)
Manual process flow (snapshot)
Here is how we will proceed to create a snapshot and then restore the database:
- ALTER DATABASE [StackOverflow] SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON;
- Create the snapshot using the zfs snapshot command.
- Run BACKUP DATABASE [StackOverflow] … WITH METADATA_ONLY.
To avoid confusion and to be able to link the snapshot to the backup, we will include the snapshot name in the MEDIADESCRIPTION clause.
Here are the corresponding commands to create the snapshot:
ALTER DATABASE [StackOverflow] SET SUSPEND_FOR_SNAPSHOT_BACKUP = ON;
We perform the snapshot:
zfs snapshot sqlpool/pve/vm-302-disk-0@StackOverflow_11052026_235500In the same session as the ALTER DATABASE command, we perform a backup:
BACKUP DATABASE [StackOverflow]
TO DISK = N'D:\Backups\StackOverflow_11052026_235500.bkm'
WITH METADATA_ONLY, MEDIADESCRIPTION = N'zfs|proxmox1|sqlpool/pve/vm-302-disk-0@StackOverflow_11052026_235500';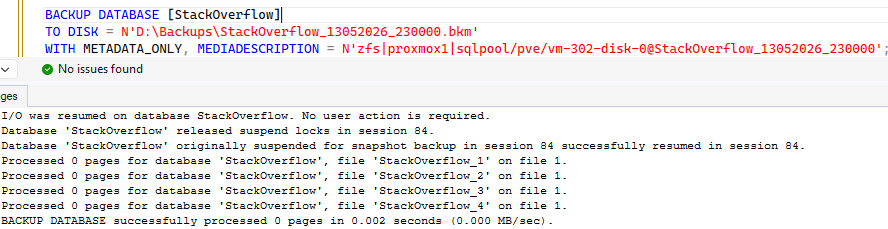
The error log shows the following:

We verify that the snapshot has been successfully created:

And the SQL backup :
 Manual process flow (restore)
Manual process flow (restore)
We now need to be able to restore the database. Before doing so, we can delete a few tables to verify that the database has been restored as expected. We deleted most of the tables, leaving only three:
To perform the restore, we will follow these steps:
- Take the database offline.
- Rollback the snapshot using the zfs rollback command.
- Restore the database using the SQL backup created earlier.
This is done using the following commands:
ALTER DATABASE [StackOverflow] SET OFFLINE WITH ROLLBACK IMMEDIATE;
Snapshot restore:
zfs rollback -r sqlpool/pve/vm-302-disk-0@StackOverflow_13052026_230000Database restore:
RESTORE DATABASE [StackOverflow]
FROM DISK = N'D:\Backups\StackOverflow_13052026_230000.bkm'
WITH METADATA_ONLY, REPLACE, NORECOVERY;
RESTORE DATABASE [StackOverflow] WITH RECOVERY;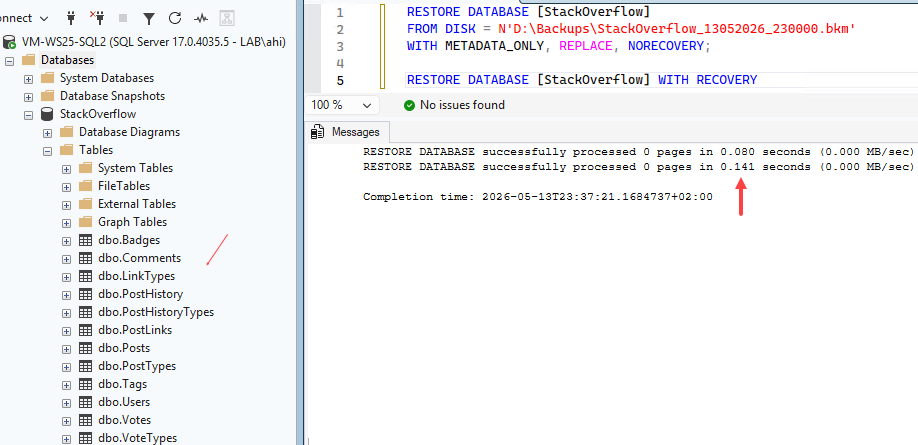
We were able to restore our database in less than one second, even though it is approximately 207 GB in size.
The process is manual, and we need to switch between running commands in SQL Server and performing the snapshot/restore operations in Proxmox. This freezes the database for a certain amount of time. During that period, connected applications could generate errors or timeouts.
The solution to this problem would be to automate the process using PowerShell, for example.
What was not covered in this sectionWhile writing this blog post, I omitted two points:
- When the database is deleted, it is necessary to take the volume dedicated to the StackOverflow database, Databases (D:), offline. Indeed, When you run a DROP DATABASE, SQL Server deletes the files from disk, and the database no longer exists. Then, if you perform a zfs rollback while Windows still sees the disk as online, you are effectively changing the disk “under Windows feet” Windows may keep the previous NTFS state cached: an empty directory, MFT information, file handles, volume metadata, and so on. As a result, the ZFS rollback may have completed successfully, but Windows does not properly refresh its view of the disk.
- We did not make any calls to a REST API. Indeed, this functionality does not exist in my case, but it is possible to implement it.
Thank you. Amine Haloui
L’article SQL Server Snapshot Backup and Restore with Proxmox ZFS (1/3) est apparu en premier sur dbi Blog.
When a Python driver configuration issue may cause blocking in SQL Server
One of our clients encountered blocking during their daily data load. The process loads several million rows and then performs an ALTER TABLE … SWITCH operation into a partitioned table. This operation usually takes some time, but in this case it became blocked.
ContextInitially, I did not have access to much information. The only element I received from the client was a extract of the output from the sp_WhoIsActive procedure.
 Initial analysis
Initial analysis
Based on this extract, we were able to perform a first-level analysis:
A Python session executed a query against MyTable without applying a date filter. On a table containing approximately 244 million rows, this prevented proper partition elimination and forced SQL Server to read a much broader data set than necessary. Queries against partitioned tables only benefit from partition elimination when the predicate references the partitioning column without such a predicate, SQL Server may have to search or scan all partitions.
The Python session eventually became sleeping but remained with open_tran_count = 1. This is a typical sign of an unclosed transaction on the client side: autocommit disabled, cursor not closed, result set not fully consumed, connection returned to the pool without a rollback…
Session 146 then attempted to perform the partition TRUNCATE/SWITCH operation. However, TRUNCATE TABLE requires a schema modification lock, Sch-M, and ALTER TABLE … SWITCH also requires a Sch-M lock on both the source and target tables.
This Sch-M lock could not be acquired while session 167 was still referencing the object. SQL Server documents Sch-M as the lock required to modify the schema and to ensure that no other session is referencing the object. Once the Sch-M request from session 146 was queued, new read queries were also blocked behind it. Even NOLOCK would not avoid this issue: queries still acquire Sch-S locks during compilation and execution, and Sch-S and Sch-M locks block each other.
Second analysisAfter some time, we were able to access the client’s environment. Query Store was enabled on the affected database, and an Extended Events session was configured on the SQL Server instance to track blocking.
Querying the Extended Events session provided detailed information about the blocking events that occurred, and we were able to identify the specific blocking issue reported by the client.

By looking more closely at this blocking issue, we found the following:
EXEC [STAGING_DB].[ETL].[sp_ETL_Exec]
@ETL_StepIKs_List = '["Exec-[TARGET_DB].dbo.[SP_Load_TargetTable]"]',
@StartAsJob = 0
Which is blocked by:
WITH position AS
(
SELECT ...
FROM [SOURCE_DB].[SCHEMA_NAME].[LARGE_PARTITIONED_TABLE]
...
)
<blocking-process>
spid="167"
status="sleeping"
trancount="1"
clientapp="python[version]"
hostname="client-host-..."
loginname="user_account"
inputbuf="... WITH position AS ..."
</blocking-process>However, the blocking report highlights an important point: session 167 was no longer actively executing the query at the time the report was captured:
- status = sleeping
- trancount = 1

However, by correlating this information with Query Store data, we were able to obtain additional details. By retrieving the corresponding query, we could better understand what was happening.
The blocking report also showed that session 146 was requesting a Sch-M lock, meaning a Schema Modification Lock. This is a strong lock required for operations such as TRUNCATE, ALTER TABLE, and partition SWITCH.
According to the data, session 146 waited for more than two hours, approximately 7,770,160 ms.

However, by correlating this information with Query Store data, we were able to obtain additional details. Specifically, by retrieving the query:
It was executed 30 times during the following time interval: 05-05-2026 from 2:00 PM to 3:00 PM. The average execution time was 49.1 seconds, with a maximum execution time of approximately 57 seconds. This represents a total of around 24 minutes of cumulative execution time over a one-hour period.
Based on this data, the issue was therefore not caused by the performance of the query itself, but rather by the state of session 167. Indeed, the session left a transaction open, with an open_tran_count of 1, thereby locking the corresponding objects and preventing other sessions from accessing them.
How is it related to Python driver configuration?The observed blocking can likely be explained by a misconfiguration or misuse of the Python driver used to access SQL Server. The root session was a Python connection in a sleeping state, but with trancount = 1, which indicates that a transaction was still open even though the query was no longer actively running.
In this situation, SQL Server may continue to hold transaction-related locks even if the application appears to have completed its work.
If the Python driver was running with autocommit = 0, each SELECT statement could implicitly start a transaction that then had to be explicitly closed with a commit or rollback. If the cursor was not closed properly, the result set was not fully consumed, or a rollback was not issued before returning the connection to the pool, the session could remain open on the SQL Server side. This residual transaction likely prevented the related ETL process from acquiring the Sch-M lock required for the TRUNCATE or partition SWITCH operation.
As a result the ETL session was not the initial root cause. It was waiting for a lock held by an idle Python connection.
Next queries then accumulated behind the pending Sch-M lock request, creating the impression of a global outage.
Switching to autocommit = 1 significantly reduces this risk, because read operations are no longer tied to an open transaction by default. Finally, preventing parallel pipeline execution helps avoid amplifying the issue when a job is delayed.
Thank you. Amine Haloui
L’article When a Python driver configuration issue may cause blocking in SQL Server est apparu en premier sur dbi Blog.
A Misleading SSAS Error in Power BI Report Server When Using DirectQuery Mode
Our client was experiencing issues after publishing a report that used Direct Query mode. Specifically, when the report was queried, the following error occurred:
Error : We couldn’t connect to the Analysis Services server. Make sure you’ve entered the connection string correctly.
However, this issue did not occur in Power BI Desktop.
In Power BI, several data loading modes are available. Import mode loads data into the Power BI model, which usually provides faster performance and richer modeling capabilities. DirectQuery mode does not store the data in the model instead, each interaction sends queries to the source system in real time. Import is generally better for speed and flexibility, while DirectQuery is useful when data must stay in the source or remain near real-time. The trade-off is that DirectQuery depends more heavily on source performance, network latency, and source-system limitations.
ConfigurationAt first glance, one might think that the corresponding report is trying to connect to an SSAS service and that there is a connectivity issue between Power BI Report Server and a SQL Server Analysis Services instance.
However, after reviewing the data source, there was no connection to SSAS:
We did not have this type of configuration:
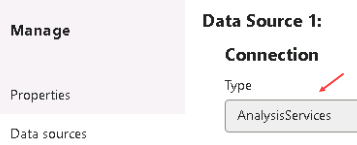
The questions that arise
Why are we getting an error message even though the report is not trying to connect to a SQL Server Analysis Services instance?
Why is our client seeing this error message and unable to query the report?
TroubleshootingBy reviewing the Power BI Report Server logs, it was possible to see this type of message:
Failed to get CSDL. —> MsolapWrapper.MsolapWrapperException: Failure encountered while getting schema.
CannotRetrieveModelException: An error occurred while loading the model… Verify that the connection information is correct and that you have permissions to access the data source.
It is also possible to retrieve some information from the ExecutionLog3 table:
Indeed, whenever a Power BI report is rendered or a scheduled refresh is executed, new entries are written to the ExecutionLog3 table. These entries can be queried through the ExecutionLog3 view in the Report Server catalog database. The ConceptualSchema event corresponds to a user viewing the report.
When querying the Event Viewer, it returned these errors at the time we tried to query the report:
 More details about the first errors
More details about the first errors
We have two error messages that seem to point in two different directions. In reality, the first error messages are not very useful and appear because although the error message refers to Analysis Services, the report was not connecting to an external SSAS instance. Power BI Report Server uses an internal Analysis Services engine to load and query Power BI report models. Therefore, the error was raised by the internal PBIRS Analysis Services engine, not by a standalone SQL Server Analysis Services instance.
Power BI Report Server may report an Analysis Services-related error even when the report does not connect to an external SSAS instance. This is because PBIRS uses an internal Analysis Services engine to host and execute the Power BI semantic model behind the report. In DirectQuery mode, the data remains in SQL Server, but the report model, metadata, relationships, measures, and DAX queries are still processed through this internal engine.
When a user opens the report, PBIRS asks this local Analysis Services process to load the model and generate the queries sent to SQL Server.
Therefore, if the internal engine fails while loading the model, validating metadata, or connecting to the SQL Server data source, the error may mention Analysis Services. This does not mean that the report is connected to a standalone SSAS instance.
More details about the second errorsThis was the second error that pointed us in the right direction to actually resolve the issue. After looking at it more closely, we started considering connection encryption and certificates. This problem is documented, and several solutions are available.
Indeed, the SQL Server instance queried to retrieve the data did not have a certificate issued by a trusted certificate authority. It was using a self-generated certificate.
This can lead to errors such as the ones mentioned above, or errors like the following:
Microsoft SQL: A connection was successfully established with the server, but then an error occurred during the login process. Provider: SSL Provider, error: 0 – The certificate chain was issued by an authority that is not trusted.
SolutionsWe had at least three options to resolve this issue:
- Change the connection mode to Import
- Install a certificate issued by a trusted certificate authority however this would represent a major change
- Create a new environment variable on the Power BI Report Server
The client chose the easiest solution to implement: creating the corresponding environment variable.
We then restarted the corresponding Power BI Report Server service and this resolved the issue.
References :https://learn.microsoft.com/en-us/power-bi/report-server/scheduled-refresh-troubleshoot
Thank you. Amine Haloui
L’article A Misleading SSAS Error in Power BI Report Server When Using DirectQuery Mode est apparu en premier sur dbi Blog.
SQLDay 2026 Workshops Overview

SQLDay 2026 offers a full-day workshop program on 11 May 2026, before the main conference scheduled for 12–13 May 2026 in Wrocław, with onsite and online participation options depending on the session. The workshops cover several areas of the modern data platform: advanced BI, AI and MLOps, SQL performance tuning, PostgreSQL adoption, and Microsoft Fabric automation.
DAX – Beyond the BasicsThis workshop is designed for Power BI users who already know the basics of DAX but now need to solve more complex business problems. The focus is on moving from simple reports to reusable, efficient and business-oriented DAX patterns.
Participants will work on practical scenarios such as advanced slicer logic, hierarchical calculations, year-to-date reporting, visual calculations, cumulative totals, ranking, and relative-period analysis. The main objective is to extend the participant’s DAX toolbox and help them write expressions that are both more powerful and better performing
AI in Databricks: Training, Deployment and MonitoringThis Polish onsite workshop covers the complete lifecycle of machine learning models in Databricks. The goal is to show how to move from data preparation to training, automation, deployment and monitoring in a production-oriented environment.
The workshop focuses on the practical implementation of MLOps using Databricks and MLflow. Topics include AI/ML architecture, data pipelines, feature engineering, model training, deep learning, CI/CD, orchestration, model versioning and monitoring. It is mainly targeted at engineers, data scientists and architects who are already working with machine learning or planning to start.
Building an Intelligent Agent in One Day with Copilot StudioThis Polish onsite workshop focuses on building conversational and autonomous agents with Microsoft Copilot Studio. The format is highly practical, with most of the time dedicated to hands-on exercises.
Participants will build agents that automate business processes, use multimodal data, generate data-driven answers and connect to enterprise data sources. The workshop also covers Dataverse grounding, flows, plugins, actions, autonomous triggers, Responsible AI, moderation and access control. It is a good fit for participants who want to understand how Copilot Studio can be used beyond simple chatbot scenarios.
Advanced T-SQL Triage: The Art of Fixing Terrible CodeThis workshop is focused on real-world SQL Server troubleshooting and refactoring. The starting point is familiar to many DBAs and developers: complex stored procedures, poor query patterns, blocking data modifications, bad use of CTEs, problematic window functions, indexed views, dynamic SQL, user-defined functions and execution plans that are difficult to understand.
The objective is not only to identify what is slow, but also to understand why it is slow and how to rewrite it properly. This session is especially relevant for people who regularly inherit problematic T-SQL code and need a structured way to fix it without guessing.
Adding PostgreSQL to your SQL Server Skill SetThis workshop targets SQL Server professionals who need to add PostgreSQL to their technical scope. The context is clear: many organizations are adding PostgreSQL without immediately replacing SQL Server, which creates a need for people who understand both platforms.
The workshop compares the two database engines, explains the areas of overlap, and highlights the differences that can make PostgreSQL challenging for SQL Server users. It also covers tooling, documentation, cloud options and practical resources to support the learning path.
Automating Your Microsoft Fabric Data Platform: From Blueprint to RealityThis onsite hands-on lab focuses on automation in Microsoft Fabric. The goal is to help participants automate the full lifecycle of a Fabric data platform, from design and setup to deployment and documentation.
The workshop covers platform setup using code and configuration scripts, metadata-driven ingestion, semantic model foundations, CI/CD with GitHub and Azure DevOps, Fabric CLI, REST APIs and the fabric-cicd Python library. The expected outcome is a more robust, scalable and repeatable approach to building Fabric solutions, with less manual work and lower operational risk.
ConclusionThe SQLDay 2026 workshop program is clearly oriented toward practical implementation. Each session addresses a common challenge faced by data teams: improving analytical models, industrializing AI, fixing complex SQL code, extending SQL Server skills to PostgreSQL, or automating a modern Microsoft Fabric platform.
The common thread is operational efficiency. These workshops are not only about learning features; they are about applying them in real environments, with constraints such as performance, maintainability, automation, governance and production readiness.
Thank you. Amine Haloui.
References :
L’article SQLDay 2026 Workshops Overview est apparu en premier sur dbi Blog.
Stop measuring ECM success like this
As I’ve mentioned in some of my previous blog posts, ECM projects don’t fail because of the chosen technology. Most products can meet the necessary requirements. The choice of a solution is driven more by other aspects, such as the effort required for deployment and maintenance, the end-user interface, and the integration capabilities.
As I wrote earlier, an ECM implementation is different from other IT projects. It’s a living system!
For years, organizations have relied on the same familiar KPIs to measure success:
“We migrated one million documents.”
“Two hundred users successfully completed the training.”
And yet, users still can’t find what they need. Decisions are still slow to be made. Content is still seen as a burden rather than an asset.

It’s time to stop measuring ECM success this way.
The problem with traditional KPIs Number of documents migratedMigrating documents is a technical milestone, not a business outcome.
A repository full of poorly classified, duplicated, or outdated documents is not a success; it’s digital clutter on a large scale. Migration only answers the question, “Did we move data?” It completely ignores whether people can actually use it.
Even worse, focusing on volume often encourages lift-and-shift strategies that preserve old folder structures and bad habits, the very things that ECM is designed to address.
Number of trained usersAlthough training metrics can be reassuring, they measure exposure, not adoption.
Completing a training session does not necessarily mean that:
- Users have changed how they work.
- They trust the system.
- They stopped saving content locally or emailing attachments.
In many ECM projects, users are technically “trained” yet still bypass the system because it slows them down instead of helping them.
Why these metrics miss the point?ECM isn’t just about storing documents. It’s about enabling better, faster, and safer work.
If your KPIs don’t reflect this, you may declare success while the business quietly disagrees.
So, what should we measure instead?
Measures that matter Time-To-Find (TTF)This is one of the most honest and revealing ECM KPIs.
In organizations that rely on folders:
- Users browse
- guess locations
- Open the wrong versions
- Ask colleagues, “Where is the latest file?”
With a metadata-driven ECM like M-Files, content is found by what it is, not where it’s stored.
Measuring Time to Find:
- Before ECM
- After going live
- And again after optimization.
This gives you a direct line from ECM value to daily productivity.
If users can’t find content faster, the ECM isn’t working, regardless of how many documents were migrated.
This KPI is even more powerful and strategic.
Decision speed is affected by:
- Content availability
- Version accuracy
- Context (related documents, metadata, and workflow state)
- Trust in information completeness
M Files accelerates decision-making by:
- Ensuring users always see the latest version
- Automatically surfacing related content
- Embedding documents directly into business processes
- Applying governance without slowing people down
When ECM is implemented effectively, decision cycles shorten. Approvals happen faster, issues are resolved sooner, and risks are identified earlier.
That’s real business impact.
Traditional ECM systems force users to adapt to them. M-Files, however, adapts to the business.
M-Files is:
- Metadata-driven
- Process aware
- Contextual
- Automation ready
It enables KPIs centered around work outcomes, not IT activities.
Instead of asking:
“How much content did we store?”
You can ask:
- “How quickly do our teams find information?”
- “Where are decisions still slow, and why?”
- “Which processes would improve most with better information?”
Thinking differently isn’t that hard, and yet it makes a huge difference. You just need the courage to take a step back.
Instead of thinking about “How your documents are stored?”, ask yourself: “What information is available?”
“Are my users trained?” Or rather, “Do my users have the tools they need to take action?”
“Is the metadata understood?”, is more important than “How my folder structure is organized?”
The question isn’t whether I completed the migration, but whether it sped up the decision-making process.
To sum things upIf your ECM success story starts and ends with numbers like documents migrated or users trained, then you’re focusing on the effort rather than the actual impact. That’s a real shame because you’re missing the point of such a project.
Modern ECM success is about:
- Time saved
- Decisions accelerated
- Risk reduced
- Work simplified
With M Files, these outcomes are not side effects but they are the goal.
Stop measuring ECM success like an IT project. Instead start measuring it like a business advantage!
We’re here to help you with that transition.
L’article Stop measuring ECM success like this est apparu en premier sur dbi Blog.
PostgreSQL 19: Dynamically adjust the I/O worker pool
When PostgreSQL 18 was released last year one of the major features was the introduction of the asynchronous I/O subsystem. The main configuration parameter for this was (and still is) io_method, which can be “worker” (the default), io_uring or sync (the old behavior). If you opted for “workers” the number of those workers is controlled by “io_workers” and the default for this is 3. PostgreSQL 19 most probably will change the way how many of those workers are launched, not anymore using the static value of “io_workers” but making this dynamic by launching workers from a predefined pool.
The configuration parameter “io_workers” is gone and four additional parameters show up to control this:
postgres=# \dconfig io_*work*
List of configuration parameters
Parameter | Value
---------------------------+-------
io_max_workers | 8
io_min_workers | 2
io_worker_idle_timeout | 1min
io_worker_launch_interval | 100ms
(4 rows)
“io_min_workes” (as the name implies) controls how many workers are available by default, which is two:
postgres@:/home/postgres/ [DEV] ps -ef | grep postgres | grep worker | grep -v grep
postgres 8564 8562 0 06:34 ? 00:00:00 postgres: pgdev: io worker 0
postgres 8565 8562 0 06:34 ? 00:00:00 postgres: pgdev: io worker 1
“io_max_workers” (again, as the name implies) controls the maximum worker processes which can be launched for the whole instance.
To see that dynamic startup of workers in action lets create a simple table containing twenty million rows:
postgres=# create table t ( a int, b text, c timestamptz );
CREATE TABLE
postgres=# insert into t select i, i::text, now() from generate_series(1,20000000) i;
INSERT 0 2000000
While watching the workers in a separate session:
postgres@:/home/postgres/ [DEV] watch "ps -ef | grep postgres | grep worker | grep -v grep"
Every 2.0s: ps -ef | grep postgres | grep worker | grep -v grep pgbox.it.dbi-services.com: 06:52:20 AM
in 0.022s (0)
postgres 8564 8562 0 06:34 ? 00:00:00 postgres: pgdev: io worker 0
postgres 8565 8562 0 06:34 ? 00:00:00 postgres: pgdev: io worker 1
… and doing a count(*) over the whole table in session one:
postgres=# select count(*) from t;
count
----------
20000000
(1 row)
… you’ll notice that an additional worker (io worker 2) shows up in the second session watching the processes (maybe you have to play a bit with the number of rows depending on your configuration of PostgreSQL):
Every 2.0s: ps -ef | grep postgres | grep worker | grep -v grep pgbox.it.dbi-services.com: 07:02:40 AM
in 0.018s (0)
postgres 8564 8562 0 06:34 ? 00:00:02 postgres: pgdev: io worker 0
postgres 8565 8562 0 06:34 ? 00:00:00 postgres: pgdev: io worker 1
postgres 11914 8562 0 07:02 ? 00:00:00 postgres: pgdev: io worker 2
Once this additional worker is idle for one minute it will disappear and we’re back to two worker processes:
Every 2.0s: ps -ef | grep postgres | grep worker | grep -v grep pgbox.it.dbi-services.com: 07:04:24 AM
in 0.020s (0)
postgres 8564 8562 0 06:34 ? 00:00:02 postgres: pgdev: io worker 0
postgres 8565 8562 0 06:34 ? 00:00:00 postgres: pgdev: io worker 1
This is controlled by “io_worker_idle_timeout” and the default is one minute.
The remaining configuration knob is “io_worker_launch_interval”, and this is the interval at which additional workers can be launched. The reason behind this is, that not too many workers will be launched at once.
This will make tuning the workers easier, compared to PostgreSQL 18. Again, thanks to all involved, the commit is here.
L’article PostgreSQL 19: Dynamically adjust the I/O worker pool est apparu en premier sur dbi Blog.
Increase GoldenGate 26ai Log Retention
GoldenGate logs are a powerful source of information when debugging or analyzing your deployments. However, some of these logs have a rather low retention period in active deployments. They might then not even be useful for debugging if you send them to your dbi consultants or the Oracle support for analysis. So how can you increase GoldenGate log retention ?
In a previous blog, I presented all the log files available in GoldenGate. Each of them has its own format and characteristics, but they have one common aspect: they can be customized.
Standard GoldenGate logging configuration files are located in the $OGG_HOME/lib/utl/logging directory.
> ll $OGG_HOME/lib/utl/logging
-rw-r-----. 1 oracle oinstall 1066 Nov 17 2018 app-adminsrvr-debug.xml
-rw-r-----. 1 oracle oinstall 1076 Jan 10 2019 app-adminsrvr-events.xml
-rw-r-----. 1 oracle oinstall 1066 Nov 17 2018 app-distsrvr-debug.xml
-rw-r-----. 1 oracle oinstall 1040 Apr 17 2017 app-extract-events.xml
-rw-r-----. 1 oracle oinstall 1066 Nov 17 2018 app-pmsrvr-debug.xml
-rw-r-----. 1 oracle oinstall 1397 Apr 1 2018 app-pmsrvr-default.xml
-rw-r-----. 1 oracle oinstall 1066 Nov 17 2018 app-recvsrvr-debug.xml
-rw-r-----. 1 oracle oinstall 1048 Jan 22 2020 app-replicat-debug509.xml
-rw-r-----. 1 oracle oinstall 1040 Apr 17 2017 app-replicat-events.xml
-rw-r-----. 1 oracle oinstall 1066 Nov 17 2018 app-ServiceManager-debug.xml
-rw-r-----. 1 oracle oinstall 2459 Jan 17 2024 app-ServiceManager-services.xml
-rw-r-----. 1 oracle oinstall 1282 Dec 19 18:44 ogg-AIService.xml
-rw-r-----. 1 oracle oinstall 4946 May 14 2020 ogg-audit.xml
-rw-r-----. 1 oracle oinstall 1582 Jun 28 2023 ogg-ConfigService.xml
-rw-r-----. 1 oracle oinstall 4487 Jan 10 2019 ogg-ggserr.xml
-rw-r-----. 1 oracle oinstall 18162 Jun 26 2020 ogg-loggers.json
-rw-r-----. 1 oracle oinstall 1095 Sep 25 2019 ogg-loggers.xml
-rw-r-----. 1 oracle oinstall 2180 Sep 11 2024 sca-default.xml
-rw-r-----. 1 oracle oinstall 1211 Jan 10 2019 sca-restapi.xml
-rw-r-----. 1 oracle oinstall 1210 Jun 6 2022 sca-stdout.xmlThe process to modify logging properties of any GoldenGate log file is to copy one of these files in your deployment and update it. It means that you can have different logging properties between your deployments.
Oracle GoldenGate Microservices uses a hierarchical logger framework with Log4j-style appenders, layouts, logger inheritance, and category namespaces. I will not dwell on all the configuration files in this blog, but let’s try to describe the most useful ones.
sca-restapi.xml
<?xml version="1.0"?>
<configuration>
<!--
/- ============================================================= -\
!- s c a - r e s t a p i . x m l -|
!- -|
!- Logging control file for recording all REST API calls -|
!- to an OGG deployment. -|
\- ============================================================= -/
! -->
<appender name="sca-restapi.log" class="RollingFileAppender">
<level value="info"/>
<param name="File" value="restapi.log"/>
<param name="MaxFileSize" value="10MB"/>
<param name="MaxBackupIndex" value="9"/>
<param name="BufferedIO" value="false"/>
<param name="Append" value="true"/>
<layout class="PatternLayout">
<param name="Pattern" value="%d{%Y-%m-%d %H:%M:%S%z} %-5p|%-36.36c| %m%n"/>
</layout>
</appender>
<!--
!- M i c r o s e r v i c e s A r c h i t e c t u r e
! -->
<logger name="RestAPI">
<appender-ref name="sca-restapi.log"/>
<level value="info"/>
</logger>
</configuration>The sca-restapi.xml file is the logging configuration file for the restapi.log file.
REST API logs are the most verbose across all GoldenGate log files. In production environments where the REST API is often called, you could easily go over the 10 log files in a day or even less. If you have enough space, I would strongly recommend increasing the retention and/or the maximum size of a single log file. This way, you ensure that you keep enough logs for debugging and analysis.
To modify the retention, change MaxFileSize to set the maximum log file size and MaxBackupIndex to choose the number of files you want to keep (on top of the active log file).
Let’s copy the file in the deployment home (it could be any deployment, including the Service Manager home).
cd $OGG_DEPLOYMENT_HOME/etc/conf/logging
cp -p $OGG_HOME/lib/utl/logging/sca-restapi.xml .
vim sca-restapi.xmlFor instance, to have 5 files of 50 MB each, edit the following lines:
<param name="MaxFileSize" value="50MB"/>
<param name="MaxBackupIndex" value="4"/>Once this is done, just restart the administration service.
What about the other log files ?If you want to increase the retention or the log file size of any other log file in GoldenGate, just use the following mapping and repeat the same process. If you want to edit the Service Manager logging properties, you should also restart it.
If you want to modify the log retention for…Copy and modify the following file from$OGG_HOME/lib/utl/loggingMost standard microservice logs, except restapi.log and ER-events.logsca-default.xmlggserr.logogg-ggserr.xmlER-events.logapp-extract-events.xmlrestapi.logsca-restapi.xml
Warning: If you want to use the same configuration across all your deployments, you could modify the standard files in $OGG_HOME/lib/utl/logging and create links from the deployments to this file. However, make sure you do not lose these changes when patching out-of-place !
Yes, there is no problem having more than 10 log files. Just increase the MaxBackupIndex (9, by default) to the number of log files you want, minus 1. For 20 log files, set MaxBackupIndex to 19.
L’article Increase GoldenGate 26ai Log Retention est apparu en premier sur dbi Blog.
PostgreSQL 19: pg_waldump can now read from archives
When PostgreSQL 18 introduced the ability to verify tar based (and compressed) backups with pg_verifybackup there was one limitation: The verification of the WAL files in the tars (or compressed files) had to be skipped (--no-parse-wal) because pg_waldump in that version of PostgreSQL is not able to cope with that (and pg_waldump is used by pg_verifybackup). This will change with PostgreSQL 19 because of this commit: “pg_waldump: Add support for reading WAL from tar archives”.
This is maybe not a feature a lot of people have waited for but it makes two tasks a lot easier:
- As mentioned above: pg_verifybackup can now read from WAL in tar and compressed files and therefore can do WAL verification
- When you have WAL in a tar or compressed file and you know what you’re looking for you do not need to manually extract those archives before using pg_waldump
To see that in action once can create a tar or compressed backup with pb_basebackup:
postgres@:/home/postgres/ [pgdev] mkdir /var/tmp/dummy
postgres@:/home/postgres/ [pgdev] pg_basebackup --checkpoint=fast --format=t --pgdata=/var/tmp/dummy
postgres@:/home/postgres/ [pgdev] ls -la /var/tmp/dummy
total 128476
drwxr-xr-x. 1 postgres postgres 66 May 11 06:36 .
drwxrwxrwt. 1 root root 762 May 11 06:33 ..
-rw-------. 1 postgres postgres 149515 May 11 06:36 backup_manifest
-rw-------. 1 postgres postgres 114619904 May 11 06:36 base.tar
-rw-------. 1 postgres postgres 16778752 May 11 06:36 pg_wal.tar
Looking at the PostgreSQL log file while the backup is running gives us a LSN we can give to pg_waldump:
2026-05-11 06:36:18.397 CEST - 2 - 1731 - - @ - 0LOG: checkpoint complete: fast force wait: wrote 2 buffers (0.0%), wrote 3 SLRU buffers; 0 WAL file(s) added, 1 removed, 0 recycled; write=0.002 s, sync=0.005 s, total=0.019 s; sync files=4, longest=0.003 s, average=0.002 s; distance=16384 kB, estimate=16384 kB; lsn=0/0D000088, redo lsn=0/0D000028
postgres@:/home/postgres/ [pgdev] pg_waldump --path=/var/tmp/dummy/pg_wal.tar -s "0/0D000088"
rmgr: XLOG len (rec/tot): 122/ 122, tx: 0, lsn: 0/0D000088, prev 0/0D000050, desc: CHECKPOINT_ONLINE redo 0/0D000028; tli 1; prev tli 1; fpw true; wal_level replica; logical decoding false; xid 0:729; oid 16420; multi 1; offset 1; oldest xid 684 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 729; checksums on; online
rmgr: Standby len (rec/tot): 54/ 54, tx: 0, lsn: 0/0D000108, prev 0/0D000088, desc: RUNNING_XACTS nextXid 729 latestCompletedXid 728 oldestRunningXid 729; dbid: 0
rmgr: XLOG len (rec/tot): 34/ 34, tx: 0, lsn: 0/0D000140, prev 0/0D000108, desc: BACKUP_END 0/0D000028
rmgr: XLOG len (rec/tot): 24/ 24, tx: 0, lsn: 0/0D000168, prev 0/0D000140, desc: SWITCH
pg_waldump: error: could not find WAL "00000001000000000000000E" in archive "pg_wal.tar
This helps pg_verifybackup fully verify a backup (in previous versions you had to use “–no-parse-wal”):
postgres@:/home/postgres/ [pgdev] pg_verifybackup --progress /var/tmp/dummy/
111933/111933 kB (100%) verified
backup successfully verified
As usual, thanks to all involved.
L’article PostgreSQL 19: pg_waldump can now read from archives est apparu en premier sur dbi Blog.
SQL Server 2025 In-Memory: New Cleanup Features & SQLBits 2026 Insights

Summer is already around the corner, but it’s not too late for some spring cleaning!
If you manage SQL Server databases with In-Memory tables, you may have already tried to delete a MEMORY_OPTIMIZED_DATA file or FILEGROUP, only to find that SQL Server simply won’t let you.
This limitation has existed since the debut of In-Memory with SQL Server 2014, and the only workaround until now was to recreate the database from scratch.
It is with SQL Server 2025 that Microsoft finally lifts this restriction. In this article, we will analyze these behavioral differences before and after this version.
To conclude, we will draw on the key points presented by Thodoris Katsimanis, DBA Team Technology Manager at Kaizen Gaming, during his session at SQLBits 2026 on In-Memory tables, in order to summarize the challenges and benefits this feature can bring to production.
To demonstrate this difference in behavior, we will create a database under SQL Server 2022 with an In-Memory table loaded with data, and then attempt to delete the associated files and FILEGROUP:
DECLARE @DataPath NVARCHAR(512) = '<YOUR_DATA_FOLDER>';
DECLARE @LogPath NVARCHAR(512) = '<YOUR_LOG_FOLDER>';
DECLARE @SQL NVARCHAR(MAX);
SET @SQL = N'
CREATE DATABASE TestInMemory
ON PRIMARY (
NAME = TestInMemory_data,
FILENAME = ''' + @DataPath + N'TestInMemory.mdf''
),
FILEGROUP XTP_FG CONTAINS MEMORY_OPTIMIZED_DATA (
NAME = TestInMemory_XTP,
FILENAME = ''' + @DataPath + N'TestInMemory_XTP''
)
LOG ON (
NAME = TestInMemory_log,
FILENAME = ''' + @LogPath + N'TestInMemory_log.ldf''
);';
EXEC sp_executesql @SQL;
USE TestInMemory;
GO
CREATE TABLE dbo.TestTable
(
ID INT NOT NULL,
Val NVARCHAR(50) NOT NULL,
CONSTRAINT PK_TestTable PRIMARY KEY NONCLUSTERED HASH (ID)
WITH (BUCKET_COUNT = 1024)
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
GO
INSERT INTO dbo.TestTable VALUES (1, 'Hello'), (2, 'World');
GO
Once our table is loaded (to ensure the table exists and is not just metadata), we can then delete it:
DROP TABLE dbo.TestTable;
GO
SELECT name, type_desc
FROM sys.tables
WHERE is_memory_optimized = 1;
The verification clearly shows that no more In-Memory objects exist. We can therefore proceed with the famous cleanup of the files linked to the table we deleted:
ALTER DATABASE TestInMemory
REMOVE FILE TestInMemory_XTP;
GO
ALTER DATABASE TestInMemory
REMOVE FILEGROUP XTP_FG;
GO
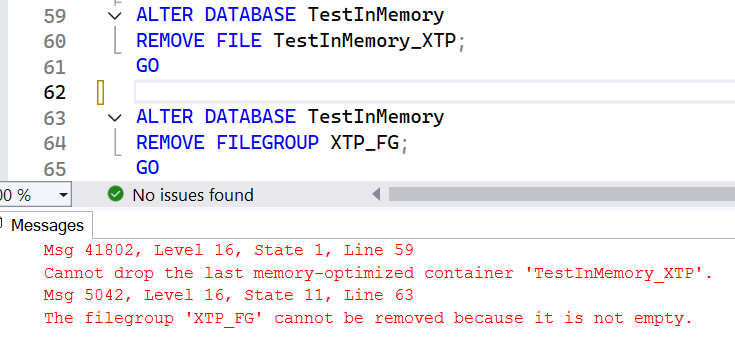
And here is the famous error, impossible to bypass it and sort things out.
Note: This cleanup challenge specifically affects tables using DURABILITY = SCHEMA_AND_DATA, as they are the only ones where data persists within physical files on disk.
SQL Server 2025 does not just lift the restriction: it also introduces a new DMV, sys.dm_db_xtp_undeploy_status, which exposes the precise reason why the deletion is not yet possible.
By querying it at the same stage as our previous example, here is what it returns:
USE TestInMemory;
GO
SELECT
deployment_state,
deployment_state_desc,
undeploy_lsn,
start_of_log_lsn
FROM sys.dm_db_xtp_undeploy_status;
GO
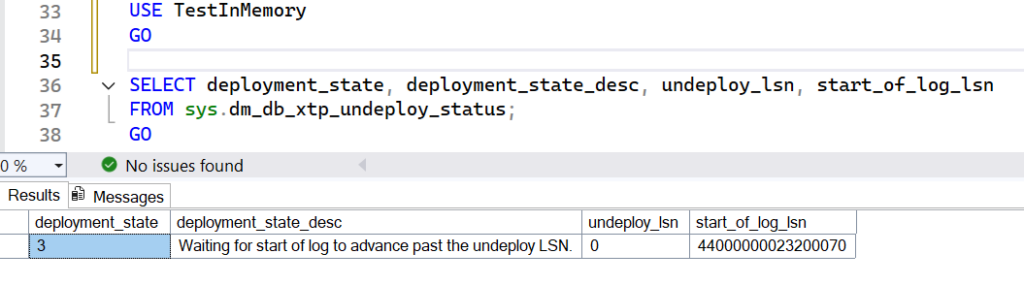
Now we have a clear reason: the start_of_log_lsn is too old, which prevents SQL Server from releasing the FILEGROUP. To resolve this, the LSNs must be advanced. A FULL backup is first required to initialize the backup chain, followed by a LOG backup to effectively advance the position in the logs:
CHECKPOINT;
GO
BACKUP DATABASE TestInMemory TO DISK = 'NUL';
GO
BACKUP LOG TestInMemory TO DISK = 'NUL';
GO
Once the LOG backup is executed and the LSNs are sufficiently advanced, the files can finally be deleted. The sys.dm_db_xtp_undeploy_status view confirms that the XTP engine is no longer deployed and that the cleanup has been successfully performed.

SQL Server 2025 not only introduces the ability to purge empty files that were linked to an In-Memory object but also the ability to troubleshoot their deletion!
From Milliseconds to Microseconds: Thodoris Katsimanis at SQLBits 2026To conclude this article, let’s look back at the key points covered by Thodoris Katsimanis during his session at SQLBits 2026, entitled “Revolutionizing Database Performance: Deep Dive into SQL InMemory Technology”.
His context is particularly telling: at Kaizen Gaming, SQL Server databases handle thousands of transactions per second in real time, in an environment where every millisecond has a direct impact on the user experience. It is precisely in this type of workload that In-Memory tables reveal their full potential.
The presentation exposed limitations of the SQL Server engine: in a high-performance system, latches on disk pages (PAGELATCH_EX) create bottlenecks that can lead to Thread Pool exhaustion. The In-Memory architecture solves this problem at its root via a latch-free structure. By relying on optimistic concurrency control and multi-versioning (MVCC), SQL Server no longer waits for locks. Each row has a Begin-Timestamp and an End-Timestamp, allowing transactions to read the valid version of the data without blocking writes.
The choice between a Hash index and a Nonclustered index is crucial. The Hash index is perfectly suited for Point Lookups (searches on an exact value): it points directly to the memory address via a hash function. Conversely, the Nonclustered index relies on a BW-Tree structure, which is essential for range scans and sorting, where Hash is of little use. To learn more about indexes for In-Memory tables, check the Microsoft’s documentation.
The Critical Impact of BUCKET_COUNT MisconfigurationAs Thodoris points out, the success of a Hash index relies on tuning the BUCKET_COUNT. This parameter defines the number of entry points in the index. If it is too low, the system generates collision chains: multiple values end up in the same bucket, forcing the engine to scan a linked list, which degrades performance. If it is too high, it consumes memory unnecessarily. Thodoris also highlights a crucial observation: using a Nonclustered index for an equality search can consume significantly more memory than a properly sized Hash index.
SQL Server 2025 finally lifts a limitation that has hampered the lifecycle management of In-Memory databases for over ten years. Being able to cleanly delete associated files and FILEGROUPs, understanding why the engine blocks this operation thanks to sys.dm_db_xtp_undeploy_status, and having a clear procedure to remedy it: this is concrete progress for everyone operating this technology in production.
Thodoris Katsimanis’s session at SQLBits 2026 reminds us that the care given to maintenance and monitoring matters just as much as the initial design. In-Memory tables are not a simple performance lever to be activated and forgotten: they require a mastery of their internal mechanisms, thread management to eliminate contention, and rigorous sizing of the BUCKET_COUNT. As he summarizes: the millisecond is no longer a sufficient unit of measurement. In-Memory OLTP aims for the microsecond and in hyper-transactional environments, that is precisely what makes the difference.
L’article SQL Server 2025 In-Memory: New Cleanup Features & SQLBits 2026 Insights est apparu en premier sur dbi Blog.
The metadata trap
You know, metadata is the key of a nice Enterprise Content Management system.
It is supposed to make work easier, promising order instead of chaos, findability instead of frustration, control instead of clutter. In the world of document management, metadata is often treated as the solution, the moment where unstructured content becomes manageable.
In reality, in many organizations, metadata quietly becomes the problem.
Not because metadata is bad. But because too much structure, designed in the wrong way, can actively destroy productivity.
This is the metadata trap: when structure stops serving work and starts working against it.

Every ECM project starts the same way. A workshop room with a whiteboard. Some PowerPoint slides with boxes and arrows. Someone asks:
What metadata do we need?
At first, the answers are sensible:
- Document type
- Customer
- Project
- Status
Then the room warms up. Legal wants contract subtype. Finance wants cost center. Compliance wants retention category. Sales wants region, industry, deal size. IT suggests future-proofing “while we’re at it.”
Before long, a simple document requires:
- 10/15 mandatory fields
- Complex naming conventions
- Conditional rules and dependencies
On paper, it’s beautiful.
In practice, it’s an additional charge on every single user, every single day.
The user “fees” nobody calculatesAlthough metadata only amounts to a few bytes and is therefore seemingly insignificant in the context of a global ECM project, it isn’t free.
Each required field adds:
- A decision the user must make
- Context they must understand
- Time they must spend
Individually, that cost seems trivial. Five extra seconds here. Ten seconds there, but multiply that by:
- Hundreds of users
- Thousands of documents
- Years of daily work
What looked like “good governance” becomes a significant productivity drain.
Worse, the people who pay this tax are rarely the people who designed the metadata model, that’s why it is crucial to involves the right people at the really beginning of the project.
What really happens in the real worldWhen metadata becomes too heavy, users don’t become more disciplined.
They become creative.
They:
- Select the first value in the list just to proceed
- Copy metadata from an old document whether it fits or not
- Create “Miscellaneous” documents whenever possible
- Store drafts locally and upload them later (maybe)
- Avoid the system unless absolutely forced
Although the metadata appears to be complete at this stage, it is far from relevant. The result is a highly detailed structure that lacks substance.
The illusion of controlOne of the most dangerous assumptions in ECM projects is this:
If we enforce the metadata, people will use it correctly.
They won’t.
Not because they’re lazy.
Because their primary job is not data quality.
A project manager wants to move a project forward.
A lawyer wants to close a contract.
An engineer wants to solve a problem.
Metadata is secondary. If it becomes an obstacle, it will be bypassed consciously or subconsciously.
Heavy structure creates the illusion of control while eroding actual adoption.
Metadata designed for reporting vs. for workHere’s a useful distinction:
- Reporting metadata serves management, analytics, and compliance.
- Operational metadata serves daily work.
The trap appears when reporting needs dominate design decisions.
Fields are added because:
- “We might need this later”
- “It could be useful for dashboards”
- “Compliance asked for it”
- “Another department uses it”
Very few fields are added because:
“This helps users get their work done faster”
This imbalance is deadly.
If metadata does not help users perform actions such as finding, reusing, automating or making decisions, it will eventually become redundant.
Metadata isn’t a magic bullet.This may sound heretical in ECM circles, but it’s true.
Metadata itself has no value.
Metadata only becomes valuable when…
- It is used later.
- by a real process.
- with a clear outcome.
Unused metadata is just overhead.
A useful question to ask about every field is:
“What breaks if this metadata is missing or incorrect?”
If the honest answer is “nothing important”, then the field may not be necessary.
The cognitive load problemThere’s also a human factor we often ignore: cognitive load.
Every metadata field requires the user to:
- Understand the difference between similar options
- Interpret abstract definitions
- Predict future use cases
This is exhausting, especially under time pressure.
When systems demand constant classification, users feel policed rather than supported.
The result?
- Reduced satisfaction
- Lower trust in the system
- Gradual disengagement
And no training program can fix that.
Simpler structure, better outcomesThe most successful systems tend to share a few traits:
- Minimal mandatory metadata
- Strong defaults and automation
- Metadata inferred from context whenever possible
- Progressive disclosure (advanced fields only when needed)
They accept a hard truth:
Incomplete but accurate metadata is better than complete but meaningless metadata.
The goal isn’t perfection. The goal is usefulness at scale.
A practical rule of thumbHere’s a very simple rule that works shockingly well:
If a user cannot explain why a metadata field is important for their work in a single sentence, then that field is hindering efficiency.
This doesn’t mean removing governance. It means aligning structure with reality.
Metadata should:
- Reduce friction, not add it
- Follow work, not dictate it
- Evolve over time, not fossilize
Avoiding the metadata trap doesn’t require radical change, but just discipline.
- Start with the minimum viable structure
- Observe real usage, not design intent
- Remove fields that don’t pull their weight
- Treat metadata models as living systems
Most importantly, listen to users. Not in requirements workshops, but in their daily behavior.
They will always tell you when structure has crossed the line.
Life is full of compromises, and so is the life of an ECM too! Structure is powerful. Metadata is necessary. Governance matters. But when structure becomes heavier than the work it supports, productivity collapses quietly and steadily.
The structure should serve the work, not the other way around.
That’s the difference between a system people tolerate and a system they actually use.
Modern ECM systems, such as M-Files, can greatly improve the user experience. There are various mechanisms for doing so:
- Metadata discovery suggests values for you
- Automatic value applies basic rules (concatenation, automatic numbering,…)
- Background calculations perform more complex actions
- A dynamic user interface that displays or hides properties depending on the lifecycle state and or the user profile
These capabilities enable users to work efficiently without wasting time filling out endless forms. Meanwhile, governance keeps everything under control, and management continues to receive relevant analytics data.
As always, dbi services (and I) are here to guide you through this complex yet essential process.
L’article The metadata trap est apparu en premier sur dbi Blog.