| SQL [message #268831] |
Wed, 19 September 2007 21:25  |
mechos
Messages: 11
Registered: September 2007
|
Junior Member |
|
|
Hello Experts,
This is a very weird query, I've put it on the server to run so as to monitor it easily, it's been more than 30 hours and still running and not using too much temp space no waits no locks etc. but CPU time is steadly increasing ..... looks like spinning.
select distinct T373917.INTEGRATION_ID as c1,
T373917.NAME as c2,
T374137.NAME as c3,
T374137.ATTRIB_02 as c4
from W_ORG_D T373917, WC_ORG_EXT_XM_D T374137, W_ORG_FXM T375143
where ( T373917.ROW_WID = T375143.ACCOUNT_WID (+) and T373917.INTEGRATION_ID = T374137.ACCOUNT_ID (+) ) and ( T373917.ACCNT_FLG = 'Y' )
order by c1, c2, c3, c4
Any help would be much appreciated.
Thanks!
|
|
|
|
|
|
| Re: SQL [message #268839 is a reply to message #268833] |
Wed, 19 September 2007 22:03  |
mechos
Messages: 11
Registered: September 2007
|
Junior Member |
|
|
|
I don't get it...how do you remove W_ORG_FXM from the FROM clause but yet use one of its attributes in the WHERE clause?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Re: SQL [message #268900 is a reply to message #268894] |
Thu, 20 September 2007 01:22 |
Frank
Messages: 7901
Registered: March 2000
|
Senior Member |
|
|
| muzahidul islam wrote on Thu, 20 September 2007 07:59 | You should use index on table(s) As your table is full scan
|
You did notice the hash joins?
|
|
|
|
| Re: SQL [message #268943 is a reply to message #268900] |
Thu, 20 September 2007 03:12 |
rleishman
Messages: 3728
Registered: October 2005
Location: Melbourne, Australia
|
Senior Member |
|
|
This plan is saying that the tables are quite small. I suspect you have not gathered statistics. Use DBMS_STATS.GATHER_TABLE_STATS to gather statistics and try again.
Ross Leishman
|
|
|
|
| Re: SQL [message #268984 is a reply to message #268943] |
Thu, 20 September 2007 06:08 |
mechos
Messages: 11
Registered: September 2007
|
Junior Member |
|
|
| rleishman wrote on Thu, 20 September 2007 03:12 | This plan is saying that the tables are quite small. I suspect you have not gathered statistics. Use DBMS_STATS.GATHER_TABLE_STATS to gather statistics and try again.
Ross Leishman
|
I ran this query on a smaller environment so I could get the execution plan. On our bigger environment this query doesn't even complete. Let me at least give the record counts so it gives you an idea.
SELECT COUNT(*) FROM W_ORG_D
2328146
SELECT COUNT(*) FROM WC_ORG_EXT_XM_D
3949852
SELECT COUNT(*) FROM W_ORG_FXM
10512185
|
|
|
|
|
|
|
|
|
|
| Re: SQL [message #269004 is a reply to message #269001] |
Thu, 20 September 2007 07:30 |
JRowbottom
Messages: 5933
Registered: June 2006
Location: Sunny North Yorkshire, ho...
|
Senior Member |
|
|
You don't need to have run the query to generate an explain plan for it.
SQL> explain plan for select sysdate from dual;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1388734953
-----------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-----------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2 (0)| 00:00:01 |
| 1 | FAST DUAL | | 1 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------
Working out whether indexes would help is one of the things we need the Plan for.
[Updated on: Thu, 20 September 2007 07:30] Report message to a moderator |
|
|
|
| Re: SQL [message #269016 is a reply to message #268831] |
Thu, 20 September 2007 07:54 |
mechos
Messages: 11
Registered: September 2007
|
Junior Member |
|
|
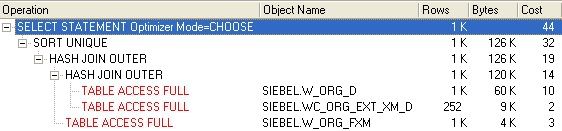
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 35M| 2896M| | 724K|
| 1 | SORT UNIQUE | | 35M| 2896M| 6309M| 371K|
|* 2 | HASH JOIN OUTER | | 35M| 2896M| 346M| 18720 |
|* 3 | HASH JOIN OUTER | | 3949K| 301M| 58M| 9166 |
|* 4 | TABLE ACCESS FULL| W_ORG_D | 1164K| 45M| | 4851 |
| 5 | TABLE ACCESS FULL| WC_ORG_EXT_XM_D | 3949K| 146M| | 1091 |
| 6 | TABLE ACCESS FULL | W_ORG_FXM | 10M| 50M| | 2913 |
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T373917"."ROW_WID"="T375143"."ACCOUNT_WID"(+))
3 - access("T373917"."INTEGRATION_ID"="T374137"."ACCOUNT_ID"(+))
4 - filter("T373917"."ACCNT_FLG"='Y')
Note: cpu costing is off
|
|
|
|
|
|
| Re: SQL [message #269020 is a reply to message #269016] |
Thu, 20 September 2007 08:11 |
JRowbottom
Messages: 5933
Registered: June 2006
Location: Sunny North Yorkshire, ho...
|
Senior Member |
|
|
Well that explains it - you're query is trying to do a distinct on about 35,000,000 rows. That's not going to finish any time soon.
Are the statistics used by the query accurate?
Are there roughly 1.1 million rows in W_ORG_D with ACCNT_FLAG = 'Y'
Are you sure you're not missing a join condition on those tables?
If I were you, I'd try running Anacedent's version of your query on your test DB and seeing if the result set is the same as your current version of the query (I will be very suprised if it's different).
That should return a lot fewer rows.
|
|
|
|
| Re: SQL [message #269031 is a reply to message #269020] |
Thu, 20 September 2007 08:52 |
Frank
Messages: 7901
Registered: March 2000
|
Senior Member |
|
|
Am I overseeing the obvious?
I can see no carthesian product in the query, yet the resultset is bigger than each of the tables.
Where's the craig?
|
|
|
|
|
|
| Re: SQL [message #269162 is a reply to message #269044] |
Thu, 20 September 2007 22:24 |
rleishman
Messages: 3728
Registered: October 2005
Location: Melbourne, Australia
|
Senior Member |
|
|
You are joining on non-unique keys. The result is that a join of tables no larger than 4M rows is returning 35M rows (if Oracle's guess is even remotely correct - it could be a lot worse).
You almost certainly do not understand your data model. Show the query to someone in your office who does understand the data model - or any EXPERIENCED data modeller who has access to your system - and get them to correct it so that you are joining on unique keys.
Now, the principal virtue of the programmer being laziness, I expect you not to bother asking around - that could take MINUTES of your time; you'd much rather the query magically start to run faster and return the correct results. So bearing that in mind, here's how you write mind-bogglingly stupid (yet somewhat more efficient) code.
select distinct
T373917.INTEGRATION_ID as c1,
T373917.NAME as c2,
T374137.NAME as c3,
T374137.ATTRIB_02 as c4
from
( SELECT DISTINCT
ROW_WID
, INTEGRATION_ID
, NAME
FROM W_ORG_D
WHERE ACCNT_FLG = 'Y'
) T373917
, (
SELECT DISTINCT
ACCOUNT_ID
, NAME
, ATTRIB_02
FROM WC_ORG_EXT_XM_D
) T374137
, (
SELECT DISTINCT
ACCOUNT_WID
FROM W_ORG_FXM
) T375143
where T373917.ROW_WID = T375143.ACCOUNT_WID (+)
and T373917.INTEGRATION_ID = T374137.ACCOUNT_ID (+)
order by c1, c2, c3, c4
The trick here is to remove the duplicates so that you get a more nearly unique join
If you actually implement this, please don't quote me, I'd rather not be associated with it.
Ross Leishman
|
|
|
|