Home » SQL & PL/SQL » SQL & PL/SQL » Trigger-summing values (Oracle)
( ) 4 Votes ) 4 Votes
| Trigger-summing values [message #360742] |
Sun, 23 November 2008 18:54  |
scts102
Messages: 1
Registered: November 2008
|
Junior Member |
|
|
Hello,
I gave this a shot on my own, and failed, so I am putting the question to you:
I am looking to create a trigger on the "Account" table
CREATE TABLE Account(Acct_no number, BillAmt number, OpenDate Date, SSN number,
Primary Key (Acct_no),
Foreign Key(SSN) references ResponsibleParty(SSN));
which will update the BillAmt field whenever one of the account's respective records is inserted/updated/deleted from the following tables:
CREATE TABLE Plan(Plan_id number, Cost number, Minutes number,
primary key(Plan_id));
CREATE TABLE Feature(Feature_id number, Description varchar(20), Cost number,
primary key(Feature_id));
These tables are linked through the following table:
CREATE TABLE Phone_Line(MTN number, cStart Date, cEnd Date,
rDate Date, Status char, ESN number, Acct_no number, Plan_id number,
primary key(MTN),
foreign key(ESN) references Equiptment(ESN), foreign key( Acct_no) references Account(Acct_no),
foreign key(Plan_id) references Plan(Plan_id));
If you couldn't tell, this is a school project. He did not cover triggers in class, and offered it as an extra credit deal.
Attached is the ER diagram if that helps any...
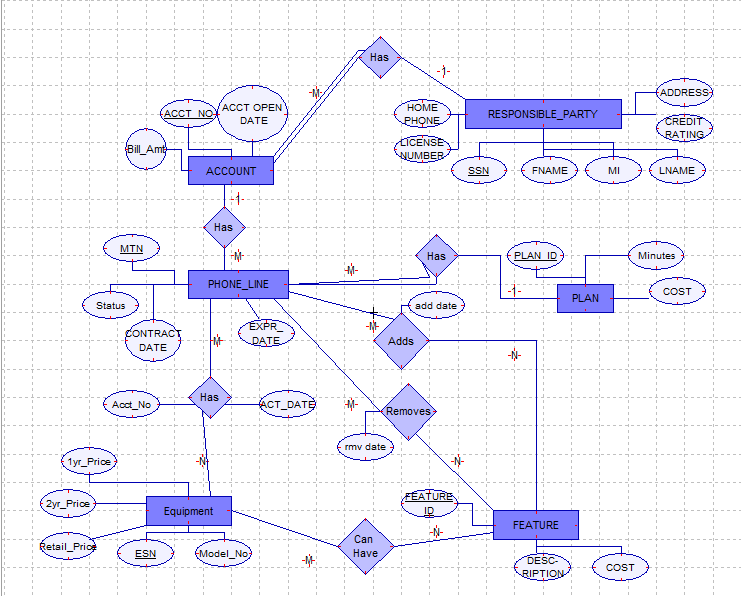
-
 Attachment: ER.png
Attachment: ER.png
(Size: 40.69KB, Downloaded 18372 times)
[Updated on: Mon, 24 November 2008 00:49] by Moderator Report message to a moderator |
|
|
|
|
|
|
|
|
|
| Re: Trigger-summing values [message #360990 is a reply to message #360980] |
Mon, 24 November 2008 09:45  |
 |
Kevin Meade
Messages: 2103
Registered: December 1999
Location: Connecticut USA
|
Senior Member |
|
|
OK, so lets put the trigger usage issue to bed once and for all. Every time someone asks for something like this; to create a set of triggers to do this-and-that, we tell them "bad idea, do ... instead". But we never explain why nor give an exmample of working code and then explain its faults. We just expect people to accept what we say. So...
Does any of us senior members here proport to have a good enouhg understanding of triggers, concurrency, and update anomaly issues that we can give a detailed account of why using triggers would be a bad idea in this situation? I would ask for a working set of triggers for this example, and an accounting of the variuos flaws and issues that would be faced with the "working" trigger solution.
This to me seems like an excellent opportunity. One of our main jobs with this website is to teach. If we provide the kind of material I think we should for this question, then the OP can take this material back to their professor and the professor can work it into the class being taught.
So, who here thinks they understand it and is willing to put three hours into it to make a solution?
I like instead of triggers, so if you guys agree to critique me, I'd be happy to provide a solution (if I can) usig instead of triggers. I promise it will contain plenty of flaws for you to pick out.
What do you guys say? How bout the usual experts, are you game?
Kevin
|
|
|
|
| Re: Trigger-summing values [message #361099 is a reply to message #360990] |
Tue, 25 November 2008 00:59 |
 |
Michel Cadot
Messages: 68776
Registered: March 2007
Location: Saint-Maur, France, https...
|
Senior Member
Account Moderator |
|
|
Quote:We just expect people to accept what we say.
For myself, I expect they ask for more explaination.
I will quote someone that better knows SQL application (and english) that I do: Stephane Faroult, in his latest book (Refactoring SQL applications), chapter 7, "Refactoring flows and database", there is a paragraph called "Adding columns" (with the courtesy of the author):
Quote:[...]For instance, you can add to an orders table an order_amount column, which will be updated with the amount of each row refering to the order in the order_details table, where all articles pertaining to the order are listed one by one.
[...]there is the question of maintenance: keeping an up-to-date throughout inserts, updates, and deletes isn't easy and errors in aggregates are more difficult to debug than elsewhere. Moreover, if the case was sometimes rather good for this type of denormalization in the early days of SQL databases, extensions such as addition of the over() clause to the standard aggregate functions make it much less useful.
[...]
Just consider the case when, for performances reasons, you want to store aggregates alongside details. If you are interested in details and aggregates, there would be no reason to maintain the aggregates: you could compute them at almost no extra cost when retrieving the details. If you want to store the aggregates, it is because you have identified a full class of queries where only the aggregates matter; in other words, a class of queries where the atom is the aggregate. This isn't always true [(e.g., ...)], but in many cases denormalization is a symptom of a collision between operational and reporting requirements. It is often better to acknowledge it, and even if a dedicated decision support database is overkill, to create a dedicated schema based on materialized views rather than painfully maintaining denormalized columns in a transactional database.
(Note that this is a partial quote, the paragraph is about denormalization, aggregate column is just an example.)
Regards
Michel
[Updated on: Wed, 05 May 2010 10:13] Report message to a moderator |
|
|
|
| Re: Trigger-summing values [message #361104 is a reply to message #360990] |
Tue, 25 November 2008 01:21 |
Frank
Messages: 7901
Registered: March 2000
|
Senior Member |
|
|
| Kevin Meade wrote on Mon, 24 November 2008 16:45 | OK, so lets put the trigger usage issue to bed once and for all. [...]
I like instead of triggers, so if you guys agree to critique me, I'd be happy to provide a solution (if I can) usig instead of triggers. I promise it will contain plenty of flaws for you to pick out.
|
Hear hear.
I for one love triggers that auto-fill PK-ID columns with incrementing sequence values.
Seeing people here over and over repeating the mantra "triggers are bad", would imply that this is bad too.
So I concur with Kevin: explain why triggers in general (and in particular for this case) are bad.
[Updated on: Tue, 25 November 2008 01:22] Report message to a moderator |
|
|
|
|
|
| Re: Trigger-summing values [message #361265 is a reply to message #361109] |
Tue, 25 November 2008 10:27 |
|
Kevin Meade
Messages: 2103
Registered: December 1999
Location: Connecticut USA
|
Senior Member |
|
|
I am not sure the problem is actually with TRIGGERS.
I think any issues would be related to the idea of keeping the sum in the first place. Seems to me if the code is in a client side program, or a plsql package that is called by a client side program, or a trigger that is invoked because of an action done by a client side program, in the end it is the same sequence of insert/update/delete that will be happening.
Is this not just a difference in packaging?
If there are concurrency issues or update anomaly issues, would these not exist and need dealing with regardless of the packaging of the code?
What makes one packaging better or worse than the others for any given situation?
Kevin
[Updated on: Tue, 25 November 2008 10:30] Report message to a moderator |
|
|
|
| Re: Trigger-summing values: One Solution [message #362327 is a reply to message #360742] |
Mon, 01 December 2008 16:00 |
|
Kevin Meade
Messages: 2103
Registered: December 1999
Location: Connecticut USA
|
Senior Member |
|
|
For those of us who celebrate it, hope all had a nice ThanksGiving.
Here is a trigger based solution as was originally requested. I seek comment from others, especailly those that feel triggers are a bad way to go.
Some things I would ask be noted:
| Quote: | 1) all trigger solutions have their detractors, in particular, INSTEAD-OF-TRIGGERS as used here have more than the usual. I have noted same, please read these as well as the solution.
2) inspite of the detractors of INSTEAD-OF-TRIGGERS, I feel INSTEAD-OF-TRIGGERS are one of the TOP 10 best features of the Oracle database. When used intelligently, in the right situations, they save lots of money and time. Think ENCAPSULATION.
3) this solution works and I would suggest works well. To my knowledge, there are no concurrency or update anomaly issues introduced as a result of using INSTEAD-OF-TRIGGERS. These issues (if they exist) are a manifest of the basic problem of keeping replicated data and would be seen in other code based solutions as well.
4) it is possible to create update anamolies when one is keeping replicated data, and I have offered up one example of code practice for this as well. HOWEVER, this issue is not related to using triggers, it is inherent in the problem of replication regardless of what code package is eventually employed to provide the solution.
|
Lets get started. I am using a simplified generic solution with tables A and B (like dept and emp). From this solution the OP should be able to construct their specific solution for their class. Once again, I am asking for comments, especially from the nay-sayers.
First we need to see our starting tables:
create table a
(
a number not null primary key
,asum number
)
/
create table b
(
b number not null primary key
,a number not null
,anumber number
,constraint b_fk1 foreign key (a) references a
)
/
As you can see:
| Quote: | 1) table A is the parent of table B
2) table B has a number in it
3) table A has a summary item that we want to always be the sum of the number from the child table B
|
We are going to use INSTEAD-OF-TRIGGERS in our solution. INSTEAD-OF-TRIGGERS require a view upon which we can place the trigger(s).
create or replace view v_b
as
select *
from b
/
Notice how the view does nothing; it simply selects everything off its underlying table (of which there is only one table). One might call this a "pass-through view". At query optimization time this view will simply disappear because Oracle understands that the view cannot change query semantics in any way. Thus there will be no performance difference, or query plan changes as a result of querying against this view. If you find any, then you have happed across an optimizer bug and you should report it to Oracle in a TAR.
The view gives us a place to hang our instead of trigger. It should be apparent that we do not need a non-updatable view in order to make use of INSTEAD-OF-TRIGGERS. This view is clearly easily updatable without an instead-of-trigger because it is only on one table and is key preserving. From this fact one might begin to realize that INSTEAD-OF-TRIGGERS have better uses than simply making non-updatable views, updatable. It is all about the philopsophy of your system design (but we wont' discuss this now).
First we should create a trigger that replicates the original logic for insert/update/delete.
create or replace trigger io_b
instead of insert or update or delete on v_b
for each row
begin
--
-- duplicate the logic of the original dml event
--
if inserting then
insert into b (b,a,anumber) values (:new.b,:new.a,:new.anumber);
elsif deleting then
delete
from b
where b = :old.b;
elsif updating then
update b set
a = :new.a
,anumber = :new.anumber
where b = :old.b;
end if;
end;
/
show errors
This trigger passes the original dml event on to the underlying table. We can test it easily enough witih the following script. Please note that insert/update/delete must be performed against the view and not the original table, othewise the trigger cannot fire:
--
-- clear out the underlying tables so they are empty
--
delete from b;
delete from a;
--
-- create a parent row (notice we start the replicated column at zero)
--
insert into a (a,asum) values (1,0);
select * from a;
select * from b;
--
-- insert a child row
-- notice that we insert through the view not the original table
-- notice also that the summable item is given a value but it is not yet summed
-- our trigger does not yet have any logic to do the summing
--
insert into v_b (b,a,anumber) values (11,1,100);
select * from a;
select * from b;
--
-- update the child row
-- notice again that we update against the view, and that the summing is not yet done
--
update v_b set anumber = 200;
select * from a;
select * from b;
--
-- delete from teh child table
-- notice again ...
--
delete from v_b;
select * from a;
select * from b;
--
-- delete from the parent
-- once again we should have empty tables
--
delete from a;
select * from a;
select * from b;
Executing this script we see these results:
SQL> --
SQL> -- clear out the underlying tables so they are empty
SQL> --
SQL> delete from b;
0 rows deleted.
SQL> delete from a;
0 rows deleted.
SQL> --
SQL> -- create a parent row (notice we start the replicated column at zero)
SQL> --
SQL> insert into a (a,asum) values (1,0);
1 row created.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> --
SQL> -- insert a child row
SQL> -- notice that we insert through the view not the original table
SQL> -- notice also that the summable item is given a value but it is not yet summed
SQL> -- our trigger does not yet have any logic to do the summing
SQL> --
SQL> insert into v_b (b,a,anumber) values (11,1,100);
1 row created.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 100
1 row selected.
SQL> --
SQL> -- update the child row
SQL> -- notice again that we update against the view, and that the summing is not yet done
SQL> --
SQL> update v_b set anumber = 200;
1 row updated.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 200
1 row selected.
SQL> --
SQL> -- delete from teh child table
SQL> -- notice again ...
SQL> --
SQL> delete from v_b;
1 row deleted.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> --
SQL> -- delete from the parent
SQL> -- once again we should have empty tables
SQL> --
SQL> delete from a;
1 row deleted.
SQL> select * from a;
no rows selected
SQL> select * from b;
no rows selected
SQL>
This demonstrates that our trigger duplicates the original insert/update/delete operation. Now we add to our trigger the logic necessary to maintain the summary item on the parent table.
create or replace trigger io_b
instead of insert or update or delete on v_b
for each row
begin
--
-- duplicate the logic of the original dml event
--
if inserting then
insert into b (b,a,anumber) values (:new.b,:new.a,:new.anumber);
elsif deleting then
delete
from b
where b = :old.b;
elsif updating then
update b set
a = :new.a
,anumber = :new.anumber
where b = :old.b;
end if;
--
-- add the additional logic for maintaining the summary item (replicated data) on the parent table
--
if inserting then
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
elsif deleting then
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
elsif updating then
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
end if;
end;
/
show errors
Keeping summary items on a parent based on changes to child rows is actually a pretty simple requirement as use of INSTEAD-OF-TRIGGERS go. Given the initial operation (insert/update/delete) we perform the necessary update of the parent table. Of particular note is the update. Since we are allowing changes to the foreign key on the child table, we will have to update two different rows on the parent table when ever the relationship changes based on the foreign key. Thus we have two update statements. In the usual sitation, there is no change to the foreign key so the old and new values of the foreign key columns (:new.a,:old.a) are the same and the same row will be updated twice. For those looking to reduce updates to the data, this is a spot where a simple check of old/new values could help you to do only one update. This makes the logic longer so I skipped it here. We can test this solution using the same script as before.
SQL> delete from b;
0 rows deleted.
SQL> delete from a;
0 rows deleted.
SQL> insert into a (a,asum) values (1,0);
1 row created.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> insert into v_b (b,a,anumber) values (11,1,100);
1 row created.
SQL> select * from a;
A ASUM
---------- ----------
1 100
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 100
1 row selected.
SQL> update v_b set anumber = 200;
1 row updated.
SQL> select * from a;
A ASUM
---------- ----------
1 200
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 200
1 row selected.
SQL> delete from v_b;
1 row deleted.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> delete from a;
1 row deleted.
SQL> select * from a;
no rows selected
SQL> select * from b;
no rows selected
SQL>
Note that since the logic for maintaining the summary item on the parent, has been included in our trigger, changes to the child are reflected correctly in the parent. As long as updates are done against the view v_b, the parent will always have the right sum of the detail rows. At this point, the OP has a solution for the original problem. Maintenance of our summary item is controled by our instead-of-trigger.
But wait, this ain't the end of it. As you recall, I said there were detractors about INSTEAD-OF-TRIGGERS. Here is a list of what I have experienced over the years when using INSTEAD-OF-TRIGGERS:
| Quote: | 1) potential ambiguity in the audit for columns affected by the change
2) no longer possible to use default values for columns on a table
3) sql in the trigger is only cached for the life of the trigger
4) merge, rowid, returning clause do not work on views with INSTEAD-OF-TRIGGERS
5) parallel dml (insert/update/delete) operations are not supported for views with INSTEAD-OF-TRIGGERS (though parallel query may still be possible)
|
#1 potential ambiguity in the audit for columns affected by the change: you may have noticed that inside the trigger, the insert/update statements we passed through to our underlying table, included all columns in the table. Consider what this means to audit triggers that might exist on the underlying tables themselves. They are not receiving the original insert/update that contains only the columns changed as was issued by the user, they are receiving a different insert/update from our instead-of-trigger that contains all columns. A before/after update of row trigger on the underlying table would not be able to tell by use of UPDATING('<columnhere>') phrase, if a column was being updated, because all columns are updated in the update statement passed on by the instead-of-trigger. In the end however, this is not that big a deal as the workaround is to check actual values of columns to see if they are different, or to move the logic to the instead-of-trigger (my choice). Additionally, I would guess that Oracle Auditing is more intelligent as well and only stores actual changed values in its auditing.
#2 no longer possible to use default values for columns on a table: for the same reason as #1, it is not possible to use the default value clause on the underlying table as these are now meaningless in light of the instead-of-trigger that supplies a value for each column, even if that value is null. The workaround for this is to include the logic for default values in a trigger. My choice would be to add it to the instead-of-trigger.
#3 sql in the trigger is only cached for the life of the trigger: this is in my mind the biggest issue. Last I knew (admittedly I have not checked this for 10g and 11g releases), sql inside a trigger is only cached for the life of a trigger. That means that all the insert/update/delete statements in an instead-of-trigger are parsed for each invocation of the trigger. This would be an issue for systems that needed to achieve super-high transaction rates. However, it is my experience that limits on transaction rates for most systems are imposed by the front ends first rather than being slowed down by Oracle. In every case, my databases have been able to supply data to their front ends faster than the front ends can ask for it, or change it. Delays on getting data, and changing data have always been a result of front end code quirks or middle ware limitations. Additionally, Oracle is always improving; this short lived caching of sql in INSTEAD-OF-TRIGGERS may have changed in 10g or 11g. Maybe someone would like to check for us?
#4 merge, rowid, returning clause do not work on views with INSTEAD-OF-TRIGGERS: it is a simple fact of Oracle life, that although all advanced features of Oracle work, they don't always work together. a) Merge raises an exception when issued against a view with an instead of trigger, even when that view is normally updatable anyway. To me this is not a bad thing since most people do not understand merge as a dml event anyway and maybe should not be using it for this reason. They think it is a simple implementation of UPSERT logic but it is not. b) ROWID should not be used in production code so the fact that it is not possible to query a ROWID from say a join view with two tables, does not bother me either. c) As for the returning clause, this is a procedural programmers construct. If you are not doing procedural programming that you won't be using it. *) In any case, all three can easily be coded around by reverting back to the traditional solution for each: MERGE = write your own update else insert logic instead, ROWID = use primary key like you should have in the first place, RETURNING CLAUSE = do a select after the insert/update to see true results of the event.
#5 parallel dml (insert/update/delete) operations are not supported for views with INSTEAD-OF-TRIGGERS: there is no workaround for this. But my experience is most systems should not be using parallel operations for production work anyway. Their systems do not have the resources (physical cpu counts, free memory) to support it. It is true that there are systems which will live of die by use of parallel query. For these systems, you simply do not use INSTEAD-OF-TRIGGERS when you must do parallel dml. But for most systems in today's businesses, we see the emphasis on hardware is to share it responsibly across an organization which means most systems in business are supporting multiple databases on one box (or one set of boxes (don't forget failover)). This is just a reality of cost vs. return for business. But one ramification is that these systems are poor candidates for parallel operations because parallel operations are not friendly operations. They do not like to share resources with any other work on their box. In an environment where success requires playing well with others, parallel operations will only lead to more meetings and in-house fighting between groups on sharing the same hardware because with a parallel operation, the parallel operation always wins and everyone else always loses.
Another thing that confuses some people is the belief that there is some kind of update anomaly issue associated with the user of triggers (INSTEAD-OF-TRIGGERS). However this is not so, at least not for INSTEAD-OF-TRIGGERS. There is nothing inherent in the use of INSTEAD-OF-TRIGGERS that introduces the potential for update anamolies in a transaction. This protential is part of the basic issue of writing code for a multi-user environment and exists any time you are writing code no matter what the delivery vehicle is for that code. Let me demonstrate with a simple transaction diagram for our trigger.
We will consider the INSERT operation against our view. It is composed of two steps, an insert to simulate the original dml logic, and an update to do the summary maintenance. The transaction looks like this:
If we extend our scenario to include simultaneous inserts by two users at the same time into our v_b view then we must at some point consider how two transactions overlap. In our case there are three possibilities we want to look at:
-- (scenario A)
insert b
update a
insert b
update a
-- (scenario B)
insert b
insert b
update a
update a
-- (scenario C)
insert b
insert b
update a
update a
Here we show the steps of two transactions both inserting into view v_b at around the same time (maybe two Oracle Forms apps). The left side is transaction 1, and the right side is transation 2. We see three scenarios that show how our transactions could overlap each other. This concept in some circles is called "inter-leafing of transactions". In scenario A, there is no inter-leaf of steps. One tranaction finishes completely before the next begins. In scenario B we see a partial inter-leafing of transactions such that some of the steps of transaction 2 are done between steps of transaction 1. In scenario C we see another example of inter-leafing wherein all steps in transaction 2 are completed between steps in transaction 1. We can explore what will happen in each of these three scenarios. We will see that Oracle's default locking plays an important role and indeed is one part of the key to avoiding the update anamolies we are looking to avoid.
Consider first what happens when the two transactions are dealing with fully un-related data. By fully un-related we mean that the row inserted into v_b is different for both transactions and each row is tied to a different parent (table A row). In this situation, since each transaction is dealing with a different table A row, there is no way for them to interfere with each others record keeping. Thus we know that when both these two transactions are completed, we will have two rows in A that reflect the sum of their children.
Alternatively consider what happens when each transaction is attempting to insert the same row into view v_b. Transaction 1 goes first of course (it is transaction 1 after all). It should be clear that as soon as transaction 2 tries to insert its row into table B, it will be blocked by a lock held because of the insert done by transaction 1 into table B. Remember we are ultimately inserting the same row in to table B in both transactions. This is easily tested using two sqlplus sessions. It happens because of the primary (or unique) indexes on table B. Oracle alters unique indexes when transaction 1 inserts into table B. The index page changed is now dirty and although you cannot see dirty pages via an application under any circumstances in Oracle, Oracle itself under the covers is not bound by this restriction. Indeed it needs to see this dirty index page so that when transaction 2 attempts to do the same insert and therefore attempts to make the same change(s) the unique index(es) on table B, it will see that the change has already been made by another pending transaction (transaction 1). This causes transaction 2 to wait until transaction 1 does either a commit or A rollback. If commit, then transaction 2 will get a DUP_VAL_ON_INDEX error. If rollback then transaction 2 will proceed once the rollback is finished (and hence the index change is undone). In this scenario we clearly have the same table A row logically involved with both transactions. But Oracle locking has serialized our transactions such that transaction 2 cannot overlay the work done by transaction 1. Locking forces transaction 2 to wait till transaction 1 is done. Indeed, because each of these transactions is doing exactly the same thing, only one transaction of the two will successfully finish. Thus we can be confident that our summary on table A will be correct at all times.
Lastly consider the more interesting situation wherein transaction 1 and transation 2 are inserting two different rows into view v_b, but these two rows ultimately belong to the same family of rows, they both have the same parent row in table A. The behavior of this situation changes depending upon the three scenarios A,B,C. In all three scenarios however, locking still causes serialization of transactions only this time it is on the row from table A. Again we will see that because of this serialization, there is no chance of a lost update between our two transactions (the type of update anomaly we are looking for). What is different about these three scenarios however is in the valid states we will see in our database before our two transaction are finished. It all depends upon which transaction updates table A row first.
Assume that transaction 1 is inserting into view v_b, a row where ANUMBER = 100, and that transaction 2 is inserting where ANUMBER = 200. In scenario A we will see table A row take on a valid state with ASUM = 100 followed quickly by a valid state with ASUM = 300 (because 100+200 = 300). In scenario B we see the same two valid states for our databse because the update of table A is done by transaction 1 first then an update by transaction 2 is done. The sequence of udpates to table A is the same in scenario B as it was in scenario A. However, if scenario C is the actual inter-leafing of our transactions then we will see table A row take a valid state of 200 first, followed quickly by a valid state of 300 (because 200+100 = 300). In the end all scenarios lead to the same final result across both transactions. But how the transactions serialize (e.g. inter-leaf) can change the valid states our database goes through in getting to its final destination with respect to these two transations. We don't really care, because as long as our database reflects a valid state at all times, we are happy, regardless of what those valid states may be. But this does point out that executing the same workload at different times, though it may result in the same final answer, does not mean one must visit the same valid states on the way, each time the same workload is executed.
For those who are interested, here is some code you can execute manually between two different sqlplus sessions to see the discussion above happen. You can modify this script to account for any of the scenarios and data alternatives we have discussed. Feel free to add selects anywhere to see intermediary data after a change. Also, remember when interpreting what you see, that you have two sessions open and that each session cannot see the others changes until that other commits its work.
-- INSERT
-- DIFF B ROW SAME A ROW
-- NO COMMIT
-- scenario A
delete from b;
delete from a;
insert into a values (1,0);
commit;
-- session 1
insert into b (b,a,anumber) values (11,1,100);
-- session 1
update a set asum = nvl(asum,0) + 100 where a = 1;
-- session 2
insert into b (b,a,anumber) values (12,1,200);
-- session 2
update a set asum = nvl(asum,0) + 200 where a = 1;
-- INSERT
-- DIFF B ROW SAME A ROW
-- NO COMMIT
-- scenario B
delete from b;
delete from a;
insert into a values (1,0);
commit;
-- session 1
insert into b (b,a,anumber) values (11,1,100);
-- session 2
insert into b (b,a,anumber) values (12,1,200);
-- session 1
update a set asum = nvl(asum,0) + 100 where a = 1;
-- session 2
update a set asum = nvl(asum,0) + 200 where a = 1;
-- INSERT
-- DIFF B ROW SAME A ROW
-- NO COMMIT
-- scenario C
delete from b;
delete from a;
insert into a values (1,0);
commit;
-- session 1
insert into b (b,a,anumber) values (11,1,100);
-- session 2
insert into b (b,a,anumber) values (12,1,200);
-- session 2
update a set asum = nvl(asum,0) + 200 where a = 1;
-- session 1
update a set asum = nvl(asum,0) + 100 where a = 1;
compute sum of anumber on report
break on report
select * from b
/
select * from a
/
So contrary to popular belief, just using INSTEAD-OF-TRIGGERS does not introduce potential for update anamolies into your transactions. However, it is useful to see the kind of code that would create such an anomaly, so here it is. This is a modified version of our trigger that employs a common practice when writing procedural code, that of prefetching data into memory and then using it later.
create or replace trigger io_b
instead of insert or update or delete on v_b
for each row
declare
asum_new_v number;
asum_old_v number;
begin
--
-- duplicate the logic of the original dml event
--
if inserting then
insert into b (b,a,anumber) values (:new.b,:new.a,:new.anumber);
elsif deleting then
delete
from b
where b = :old.b;
elsif updating then
update b set
a = :new.a
,anumber = :new.anumber
where b = :old.b;
end if;
--
-- add the additional logic for maintaining the summary item (replicated data) on the parent table
--
if inserting then
select asum into asum_new_v from a where a = :new.a;
update a set asum = nvl(asum_new_v,0) + nvl(:new.anumber,0) where a = :new.a;
elsif deleting then
select asum into asum_old_v from a where a = :old.a;
update a set asum = nvl(asum_old_v,0) - nvl(:old.anumber,0) where a = :old.a;
elsif updating then
select asum into asum_new_v from a where a = :new.a;
update a set asum = nvl(asum_new_v,0) + nvl(:new.anumber,0) where a = :new.a;
select asum into asum_old_v from a where a = :old.a;
update a set asum = nvl(asum_old_v,0) - nvl(:old.anumber,0) where a = :old.a;
end if;
end;
/
show errors
This trigger introduces a select before each update. The update then relies upon the values selected when doing its math to maintain the corresponding summary on table A. The flaw however is that the data used in each select can change between the time the select was issued and the update carried out. If this happens, the update would be relying on a value which is no longer valid and thus the update will result in a wrong answer, e.g. some previous update will be lost.
Consider an updated version of our scenario C from above:
insert b
select a
insert b
select a
update a
COMMIT;
update a
COMMIT;
As a reminder, transaction 2 is started and finished inside of transaction 1. After transaction 1 selects the ASUM value off table A, transaction 2 will change it and commit. Unfortunately, our coding stream has decided to cache the value of ASUM from table A in memory such that the step update a in transaction 1 uses to value of ASUM as it was before transaction 2 updated it and commited. Thus when the step update a in transaction 1 executes, it will overlay the update of transaction 2. In the end our ASUM value on table A will be out of synch with its detail data. Here is a sqlplus script that can be run between two sessions to show this point.
delete from b;
delete from a;
insert into a values (1,0);
commit;
-- INSERT
-- DIFF ROW
-- YES COMMIT
-- scenario C
-- session 1
variable asum number;
-- session 2
variable asum number;
-- session 1
insert into b (b,a,anumber) values (11,1,100);
-- session 1
set serveroutput on
begin select asum into :asum from a where a = 1; dbms_output.put_line(:asum); end;
/
-- session 2
insert into b (b,a,anumber) values (12,1,200);
-- session 2
set serveroutput on
begin select asum into :asum from a where a = 1; dbms_output.put_line(:asum); end;
/
-- session 2
update a set asum = :asum + 200 where a = 1;
COMMIT;
-- session 1
update a set asum = :asum + 100 where a = 1;
COMMIT;
compute sum of anumber on report
break on report
select * from b
/
select * from a
/
Once again I stress that the issue here is not with the instead-of-trigger, but rather with the coding practice used. One could just as easily write this code in a plsql api, or in a client side app. The solution for most systems is once again use of locking to serialze access to rows being modified to make sure that when we cache data, we stop the underyling rows used to get that data from changing. Here is an updated trigger that satisfies for this method.
create or replace trigger io_b
instead of insert or update or delete on v_b
for each row
declare
asum_new_v number;
asum_old_v number;
begin
--
-- duplicate the logic of the original dml event
--
if inserting then
insert into b (b,a,anumber) values (:new.b,:new.a,:new.anumber);
elsif deleting then
delete
from b
where b = :old.b;
elsif updating then
update b set
a = :new.a
,anumber = :new.anumber
where b = :old.b;
end if;
--
-- add the additional logic for maintaining the summary item (replicated data) on the parent table
--
if inserting then
select asum into asum_new_v from a where a = :new.a for update;
update a set asum = nvl(asum_new_v,0) + nvl(:new.anumber,0) where a = :new.a;
elsif deleting then
select asum into asum_old_v from a where a = :old.a for update;
update a set asum = nvl(asum_old_v,0) - nvl(:old.anumber,0) where a = :old.a;
elsif updating then
select asum into asum_new_v from a where a = :new.a for update;
update a set asum = nvl(asum_new_v,0) + nvl(:new.anumber,0) where a = :new.a;
select asum into asum_old_v from a where a = :old.a for update;
update a set asum = nvl(asum_old_v,0) - nvl(:old.anumber,0) where a = :old.a;
end if;
end;
/
show errors
We put a FOR UPDATE clause on the end of those selects who data we will be using to update the database with later. The FOR UPDATE clause causes the rows used to get the data we will be caching in a variable, to be locked and thus not change till the transaction finishes either with a commit or a rollback. The practice of selecting data FOR UPDATE before an update is done is so important in database theory that is has its own name, OPTIMISTIC LOCKING (or maybe pessimistic locking, I forget which means what). Like they say, if you want to sell it you first have to give it a name. I try to write code such that I do not need to use FOR UDPATE. You may see these issues in your travels across PL/SQL code and .NET code, and VB code, and indeed any procedural code you work with. Do not jump right into "fixing" it however. If a piece of code has potential lost update issues in a multi-user environment, it isn't a problem as long as you run the code all by itself. Thus large batch ETL jobs may have lots of this and it is fine as long as job controls are in place to make sure people are not updating the same data that the ETL job is updating.
So far this has been kind of fun. We have:
| Quote: | 1) presented a solution for the OP original problem
2) talked about the potential detractors of using INSTEAD-OF-TRIGGERS
3) reinforced the notation that triggers are not inherently evil
|
Not so bad, but it leaves us wanting to know... what are INSTEAD-OF-TRIGGERS really good for?
Now we introduce a bit of philosophy and opinion and thus begin our more controversial portion of this discussion. I am a huge fan of INSTEAD-OF-TRIGGERS. With them I have done things that others thought impossible, and done so flawlessly and in record time. But mine is not ever the only opinion and I look forward to others poking holes in this work. Indeed, what I believe to be the true magic about INSTEAD-OF-TRIGGERS and the reason why I use them, is what others believe to be their biggest problem and the reason why they won't use them; INSTEAD-OF-TRIGGERS hide logic from the outside world.
This is a powerful idea, the ability to hide logic from the outside world. To grasp what this can mean consider the following revelation many of us have faced, SOX AUDITING. For those who don't know what SOX is, here is a wikpedia link for you to bone up on.
Sarbanes-Oxley Act
SOX in a nutshell is Federal Auditing. For those of us working for financial institutions, we have come to see SOX mandate many changes to code we have run every day for many years in order to make it SOX COMPLIANT. In some circles, the response to SOX has been extreme. More than once corporate auditors have told me that my systems "CANNOT DELETE ANYTHING". I have always felt that being not able to figure out what SOX really means, they decided to take the safe route and not destroy any data. I guess that works and it is certainly technically doable. But what does that cause IM to have to do?
Consider a simple database that has among other things some financial data. It would be covered by SOX because of what it contains. Lets say you have JAVA apps that allow updates to some of the data; you have .NET apps that allow updates to some of the data; you have VB apps that allow updates to some of the data; you may even have some guy using MS-ACCESS to do "TABLE MAINTENANCE" on reference tables.
Today you have been told as of 1-jan-xxxx you can no longer delete any data from these systems. UHOH! what are you going to do? Everywhere you have an application that says DELETE, you have to stop the app from actually deleting and do something else. This can easily ramp up to millions of line of code you must review and hundreds to thousands of delete statements to work around.
In the past this would mean having to define some kind of LOGICAL DELETE solution and then implement that solution in all the code that needs it. One way is to actually change all the code to do LOGICAL DELETE in the code. Not surpisingly this will be expensive. And believe if or not this is the easy part, as it may be only a partial solution for what will you do with third party applications accessing your data? Will the government allow you to pass the buck along and say (their app their problem). Nope they won't. How will you get your third party software vendors to comply for you on time to keep from being fined?
If only we had a way to hide LOGICAL DELETE from everything that touched the database. Then we could be 100% compliaint and not have to change any code to get there. If only, when we were asked to delete, we could do an update INSTEAD-OF the delete.
You are correct. We can use an instead-of-trigger to implement LOGICAL DELETE any way we want without any of our applications being the wiser. Let us change our trigger we built to do summation to include logical delete as well.
create table ld_b
as
select b.*,cast(null as date) del_date,cast(null as varchar2(30)) del_user
from b
where rownum < 1
/
We create a table to save deleted rows. Then we add logic to our trigger to save the row we are deleting to this table.
create or replace trigger io_b
instead of insert or update or delete on v_b
for each row
begin
--
-- duplicate the logic of the original dml event
--
if inserting then
insert into b (b,a,anumber) values (:new.b,:new.a,:new.anumber);
elsif deleting then
delete
from b
where b = :old.b;
elsif updating then
update b set
a = :new.a
,anumber = :new.anumber
where b = :old.b;
end if;
--
-- add the additional logic for maintaining the summary item (replicated data) on the parent table
--
if inserting then
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
elsif deleting then
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
elsif updating then
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
end if;
--
-- add logic for logical delete
--
if deleting then
insert into ld_b (b,a,anumber,del_date,del_User) values (:old.b,:old.a,:old.anumber,sysdate,user);
end if;
end;
/
show errors
Notice we added a section at the end that saves the old version of the row into a seperate table. This should satisfy our SOX guys nicely as nothing is ever deleted from this table now. Instead the row is copied into another location for safe keeping.
Best of all though is that our client side applications which used to say delete, still say delete. As far as they know, they have just deleted the row from the database. Here is a script that you can use to see this.
delete from ld_b;
delete from b;
delete from a;
insert into a (a,asum) values (1,0);
select * from a;
select * from b;
select * from ld_b;
insert into v_b (b,a,anumber) values (11,1,100);
select * from a;
select * from b;
select * from ld_b;
update v_b set anumber = 200;
select * from a;
select * from b;
select * from ld_b;
delete from v_b;
select * from a;
select * from b;
select * from ld_b;
delete from a;
select * from a;
select * from b;
select * from ld_b;
And here is it in action.
SQL> delete from ld_b;
1 row deleted.
SQL> delete from b;
0 rows deleted.
SQL> delete from a;
0 rows deleted.
SQL> insert into a (a,asum) values (1,0);
1 row created.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> select * from ld_b;
no rows selected
SQL> insert into v_b (b,a,anumber) values (11,1,100);
1 row created.
SQL> select * from a;
A ASUM
---------- ----------
1 100
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 100
1 row selected.
SQL> select * from ld_b;
no rows selected
SQL> update v_b set anumber = 200;
1 row updated.
SQL> select * from a;
A ASUM
---------- ----------
1 200
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 200
1 row selected.
SQL> select * from ld_b;
no rows selected
SQL> delete from v_b;
1 row deleted.
SQL> select * from a;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> select * from ld_b;
B A ANUMBER DEL_DATE DEL_USER
---------- ---------- ---------- --------- ------------------------------
11 1 200 01-DEC-08 KM21378
1 row selected.
SQL> delete from a;
1 row deleted.
SQL> select * from a;
no rows selected
SQL> select * from b;
no rows selected
SQL> select * from ld_b;
B A ANUMBER DEL_DATE DEL_USER
---------- ---------- ---------- --------- ------------------------------
11 1 200 01-DEC-08 KM21378
1 row selected.
SQL>
Please notice how after we "delete" a row, it shows up in our deleted rows table. This implementation is transparent to any and all applcations deleting against this database. Assuming you only allow access to the data via the view, this implementation is unavoidable, all deletes will be turned into logical delete no matter where they come from. Additionally this solution is future proof, for even those applications not yet written that will do delete will be using the logical delete when someone gets around to writing the code.
The key to it all, it that it is transparent in its implementation. Code that accesses the database is unaware that this logic even exists.
If at this point you understand what we have just done, then you are in one of two camps. Either you think this is great stuff because look at all the millions of dollars I just saved by not having to modify existing applications to become SOX compliant for deletes, or you don't like the idea of not having control over what is going on under the covers and you are adamant to spend the millions to change your apps and haunt your third party vendors until they comply. One way or the other it all comes down to your philosophy; what you think Information Technology is all about, and how you go about solving problems.
For those of you who do not like what you see, you should take a look at a product called Oracle WORKSPACE MANAGER. It is a software solution created by Oracle. It is a novel idea, has been used by many companies to their advantage, and is done using INSTEAD-OF-TRIGGERS. If Oracle can build entire poduct suites around INSTEAD-OF-TRIGGERS, then why can't we.
For those of you with vision, consider some of the possible uses for INSTEAD-OF-TRIGGERS:
| Quote: | 1) implementing database centric logic in one place and thereby not asking applications to do it all over the place(transparent logical delete, transparent supertype/subtype management, transparent auditing, enforced data edits, basic replication)
2) implementing seriously advanced functionality with minimal or even no changes to existing systems (historical perspective, hypothetical views and "what if" database schemas, the long transaction)
3) implementing "order of magnitude" solutions to common IT problems (application upgrade testing using developer managed on-demand database restore, application migration to industry standardized data models, third party application integration using simulation layers)
|
These are real problems facing most IT shops today. INSTEAD-OF-TRIGGERS offer a possible solution for each of them. A solution that does not require spending tens of millions of dollars, tieing up teams that could be doing other work, and waiting eighteen months for a solution.
But if you don't have the right philosophical perspective, you can't see the opportunity.
I invite comment.
Kevin
|
|
|
|
|
|
|
|
|
|
| Re: Trigger-summing values: One Solution [message #363034 is a reply to message #362327] |
Thu, 04 December 2008 20:57 |
 |
Barbara Boehmer
Messages: 9106
Registered: November 2002
Location: California, USA
|
Senior Member |
|
|
Kevin,
I received your email asking me to take a look at this and comment on it. Triggers have their purposes and I use them when appropriate. I am not addressing triggers in general here, just this specific situation and those like it where the purpose is to maintain a summary column. I completely agree with what Michel Cadot said:
| Quote: |
It is a bad idea and design to have aggregate columns in table and even more trying to keep it consistent with triggers.
Either compute it on the fly (preferred way when possible) or use a materialized view.
|
I see no point in taking up space with an unnecessary column or creating a view and a trigger, when all you need is a view. Although your method works, it does not seem to be the simplest way and to me that is the issue. I believe you will find that experts like Tom Kyte share the same opinion. I disapprove of homework assignments that instruct students to use features in inappropriate situations. I realize that you have gone to a lot of trouble to demonstrate and explain in detail that your code works and how, but to me it is like proving that you can get to the house next door by running around the block. It will get you there, but it is not the easiest way. I have provided code below to show how I believe it should be done simply.
Regards,
Barbara
-- tables you provided, but with summary column removed:
SCOTT@orcl_11g> create table a
2 (
3 a number not null primary key
4 )
5 /
Table created.
SCOTT@orcl_11g> create table b
2 (
3 b number not null primary key
4 ,a number not null
5 ,anumber number
6 ,constraint b_fk1 foreign key (a) references a
7 )
8 /
Table created.
-- all you need is a simple view (no triggers):
SCOTT@orcl_11g> create or replace view a_view as
2 select a.a, nvl (sum (b.anumber), 0) as asum
3 from a, b
4 where a.a = b.a (+)
5 group by a.a
6 /
View created.
-- test like yours:
SCOTT@orcl_11g> delete from b;
0 rows deleted.
SCOTT@orcl_11g> delete from a;
0 rows deleted.
SCOTT@orcl_11g> insert into a (a) values (1);
1 row created.
SCOTT@orcl_11g> select * from a_view;
A ASUM
---------- ----------
1 0
SCOTT@orcl_11g> select * from b;
no rows selected
SCOTT@orcl_11g> insert into b (b,a,anumber) values (11,1,100);
1 row created.
SCOTT@orcl_11g> select * from a_view;
A ASUM
---------- ----------
1 100
SCOTT@orcl_11g> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 100
SCOTT@orcl_11g> update b set anumber = 200;
1 row updated.
SCOTT@orcl_11g> select * from a_view;
A ASUM
---------- ----------
1 200
SCOTT@orcl_11g> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 200
SCOTT@orcl_11g> delete from b;
1 row deleted.
SCOTT@orcl_11g> select * from a_view;
A ASUM
---------- ----------
1 0
SCOTT@orcl_11g> select * from b;
no rows selected
SCOTT@orcl_11g> delete from a;
1 row deleted.
SCOTT@orcl_11g> select * from a_view;
no rows selected
SCOTT@orcl_11g> select * from b;
no rows selected
SCOTT@orcl_11g>
|
|
|
|
| Re: Trigger-summing values [message #363093 is a reply to message #360742] |
Fri, 05 December 2008 01:37 |
|
Kevin Meade
Messages: 2103
Registered: December 1999
Location: Connecticut USA
|
Senior Member |
|
|
Thank you Barbara. This is exactly the kind of commentary I was hoping would be provided by the experts here. Counterpoints are very useful for others when they are looking to make a decision between alternatives.
I am most greatful for the fact that you have posted an actual working alternative. Yes, the view only solution is the simplest of all solutions to the OP original request, and for many situations is the most appropriate solution. I was using the OP request as a way to offer them a solution and as as a way to demonstrate instead-of-triggers in action.
I hope next that someone takes the time to offer up the MATERIALIZED VIEW alternative that has been mentioned twice, at least, in this article. Then we would have the three basic solutions for the original problem presented, in one location. People could examine all three and perform their own evaluations.
However, I feel instead-of-triggers are given a bad wrap by people who do not know how to use them. For example, I agree that the view solution is simpler and it would be my first choice in many situations. But, I get the sense from your reply that you think the simpler view approach is superior because of its simplicity, to the instead-of-trigger alternative. I do not see it that way. Please do not mis-read my comment. I am not suggesting that the instead-of-trigger solution is superior to the simpler view alternative or the materialized view alternative. Rather I believe that they are all three very different solutions to the same specific problem, and which solution one would pick should depend like everything else, on an evaluation of the overall situation being served. To simply dismiss instead-of-trigger alternatives without proper consideration, is to do yourself a disservice. Yet it seems most people do exactly that. I know what they are missing, which is why the topic is important to me.
Let me critique the three alternatives a bit to show what I mean:
The simpler view altenative is as its description implies, simple. In fact, until the advent of instead-of-triggers, and materialized views, it was pretty much the only alternative if one wanted the database to do all the work. However, just because it is the simplest of all solutions does not make the best. One major detractor of the simpler view alternative is that it is the slowest of the three. Every time you want to get a sum, it must be computed. For small datasets this might not prove to be too much of an issue. But... as the number of rows grows this solution slows down considerably, especially under heavier useage. Consider 20 million charge cards held by 1000 different companies, and a web app where company HR reps log in and do account balance queries all day long against your view. This web app could easily be feeding 100 thousand hits per day against the view which means we would be adding up the 20 million row table 100 times each day. That is a lot of work. But if we were using the materialized view alternative, or the instead-of-trigger alternative, then we would have pre-calculated sums already available on master rows we would already be querying. The simple view alternative has high compute cost at report time in many situations, the other two alternatives have zero compute cost at report time. The simple view alternative is clearly a winner for systems who's data is bucketed into small sets with rows that exhibit good locality of reference, but is not a winner for systems that require very fast query events, and as web apps become more the norm, the pressure for fast query events continues to increase.
The materialized view has the advantage of not incurring compute cost at report time but of course has its own problems. First, this is not a simple solution. You would most likely need REFRESH FAST ON COMMIT to make it work. Creating materialized views that work as REFRESH FAST ON COMMIT is no small feat to achieve. Additionally this requires a materialized view log which makes the solution less simple and it requires a second data store which requires more storage and storage management, and it requires either direct coding against the materialized view, or correct use of query re-write which now makes the solution even more involved. But perhapes most importantly, the materialized view solution is a transaction sensitive solution. The MVIEW will not reflect the correct sum at best until a commit is done which means the transaction doing work on the MVIEW's data cannot rely on the MVIEW summary to see the effect of its own changes thus negating some of its value. At worst the MVIEW will not be an ON COMMIT MVIEW and thus is of only marginal value to the operational system it represents. It would be relegated to reporting tasks that accept stale data. The materialized view is a good solution for reporting systems, especially distributed systems that can afford a predefined lag in the data, but the materialized view solution is not a winner for systems that require transaction consistent summaries in flight. We might again look at web apps which usually require such capability.
And then there is the instead-of-trigger solution. OK, it suffers from not being as simple a solution as a basic view is when presented for the OP original problem, and it requires similarly to the MVIEW solution, extra updates at update time, which the simple view solution avoids. But looking at the instead-of-trigger solution from both sides, what does it offer us? First, its fast. It has zero computational cost at query time which means as datasets increase in size, query response stays the same. For many systems this characteristic is highly desireable. Also, it is free of the potentially significant space cost we saw with the MVIEW approach, requiring only a small amount of extra storage. Also unlike the MVIEW solution, it is transactionally consistent and so need not be avoided when coding transactions utilitizing the data that affects it. Additionally, the data would never be stale so all reporting needs can be met. Though the instead-of-trigger is a poor choice for those systems that require very high OLTP transaction rates; for all other systems, if they are ready to exchange some update time for significantly better query times, the instead-of-trigger solution is a highly attractive alternative to the simple view, or MVIEW solution.
So, the only thing clear to me is:
in some situations a simple view is great, in other situations not so great
in some situations a MVIEW is great, in other situations, not so great
in some situations an intead-of-trigger is great, in other situations not so great
So which one should I use? THAT DEPENDS... WHAT IS YOUR SITUATION?
Yet in all this discussion, we are missing the bigger picture. This discussion though cool is actually bad, because it distracts us from the real value of the instead-of-trigger.
The intead-of-trigger is about achieving GAME CHANGING solutions
not doing trivial things like keeping a summary item on a parent row. That is what I tried to demonstrate when I talked about doing the LOGICAL DELETE. Instead-of-triggers offer us a way to solve problems like we have never solved them before. Needs that were very expensive to meet in the past can become trivial problems to solve today given instead-of-triggers at our disposal. The LOGICAL DELETE was only one example of this (and a small one at that). Creating WORKSPACES is a much more powerful example of the GAME CHANGING nature of instead-of-triggers. I think what I must do next is to write an article about WORKSPACES (what they are and how they can be used to CHANGE THE GAME).
In the meantime, can you comment on how you would implement LOGICAL DELETE as compared to the instead-of-trigger solution I demonstrated?
I realize the solution I offered could be enhanced in several ways, but that is not what I need focused on. I would like to hear your thoughts on the workload behind implementing LOGICAL DELETE across a set of applications accessing a database and tell my why the traditional solution of actually changing code is better than an instead-of-trigger solution that can be done with zero changes to code.
Thanks again for taking time to reply. I really think there is a lot of learning opportunity in this thread. But only if you and others like you add your experience.
Kevin
[Updated on: Fri, 05 December 2008 01:47] Report message to a moderator |
|
|
|
| Re: Trigger-summing values [message #363416 is a reply to message #363093] |
Sun, 07 December 2008 04:40 |
|
Michel Cadot
Messages: 68776
Registered: March 2007
Location: Saint-Maur, France, https...
|
Senior Member
Account Moderator |
|
|
This post shows how to do the same thing with a materialized view.
It does not add any information to the previous posts and especially to Kevin one about the limits of this solution.
SQL> create table a (a number not null primary key);
Table created.
SQL> create materialized view log on a with rowid, sequence(a) including new values;
Materialized view log created.
SQL> create table b (
2 b number not null primary key
3 ,a number not null
4 ,anumber number
5 ,constraint b_fk1 foreign key (a) references a
6 )
7 /
Table created.
SQL> create materialized view log on b with rowid, sequence(a, anumber) including new values;
Materialized view log created.
SQL> create materialized view a_mview
2 refresh fast on commit
3 as
4 select a.a, sum(b.anumber) as asum,
5 count(*) as cnt1, count(b.anumber) as cnt2
6 from a, b
7 where a.a = b.a
8 group by a.a
9 /
Materialized view created.
SQL> alter table a_mview add primary key (a);
Table altered.
SQL> create or replace view a_view as
2 select a.a, nvl(mv.asum,0) as asum
3 from a, a_mview mv
4 where mv.a (+) = a.a
5 /
View created.
SQL> delete from b;
0 rows deleted.
SQL> delete from a;
0 rows deleted.
SQL> insert into a (a) values (1);
1 row created.
SQL> commit;
Commit complete.
SQL> select * from a_view;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> insert into b (b,a,anumber) values (11,1,100);
1 row created.
SQL> commit;
Commit complete.
SQL> select * from a_view;
A ASUM
---------- ----------
1 100
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 100
1 row selected.
SQL> update b set anumber = 200;
1 row updated.
SQL> commit;
Commit complete.
SQL> select * from a_view;
A ASUM
---------- ----------
1 200
1 row selected.
SQL> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 200
1 row selected.
SQL> delete from b;
1 row deleted.
SQL> commit;
Commit complete.
SQL> select * from a_view;
A ASUM
---------- ----------
1 0
1 row selected.
SQL> select * from b;
no rows selected
SQL> delete from a;
1 row deleted.
SQL> commit;
Commit complete.
SQL> select * from a_view;
no rows selected
SQL> select * from b;
no rows selected
A couple of remarks:
- outer join prevent from refreshing on commit in this case, so I have a materialized view with inner join and a "normal" view with outer join
- the count columns are there to workaround bugs on fast commit refresh after delete and update operations for all versions up to at least 10.2.0.4, I didn't check in 11g.
Regards
Michel
|
|
|
|
| Re: Trigger-summing values [message #364165 is a reply to message #363093] |
Sun, 07 December 2008 13:33 |
|
Barbara Boehmer
Messages: 9106
Registered: November 2002
Location: California, USA
|
Senior Member |
|
|
If you are determined to maintain a summary column through a trigger, then you might as well just use a simple row trigger, as demonstrated below. If you are going to use a trigger, there is no need to add a view and use an instead of trigger. Either use a view or a trigger, not both.
-- tables:
SCOTT@orcl_11g> create table a
2 (
3 a number not null primary key
4 ,asum number default 0
5 )
6 /
Table created.
SCOTT@orcl_11g> create table b
2 (
3 b number not null primary key
4 ,a number not null
5 ,anumber number default 0
6 ,constraint b_fk1 foreign key (a) references a
7 )
8 /
Table created.
-- single trigger without a view:
SCOTT@orcl_11g> create or replace trigger b_biudr
2 before insert or update or delete on b
3 for each row
4 begin
5 if inserting then
6 update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
7 elsif deleting then
8 update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
9 elsif updating then
10 update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
11 update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
12 end if;
13 end;
14 /
Trigger created.
SCOTT@orcl_11g> show errors
No errors.
-- test:
SCOTT@orcl_11g> delete from b;
0 rows deleted.
SCOTT@orcl_11g> delete from a;
0 rows deleted.
SCOTT@orcl_11g> insert into a (a) values (1);
1 row created.
SCOTT@orcl_11g> select * from a;
A ASUM
---------- ----------
1 0
SCOTT@orcl_11g> select * from b;
no rows selected
SCOTT@orcl_11g> insert into b (b,a,anumber) values (11,1,100);
1 row created.
SCOTT@orcl_11g> select * from a;
A ASUM
---------- ----------
1 100
SCOTT@orcl_11g> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 100
SCOTT@orcl_11g> update b set anumber = 200;
1 row updated.
SCOTT@orcl_11g> select * from a;
A ASUM
---------- ----------
1 200
SCOTT@orcl_11g> select * from b;
B A ANUMBER
---------- ---------- ----------
11 1 200
SCOTT@orcl_11g> delete from b;
1 row deleted.
SCOTT@orcl_11g> select * from a;
A ASUM
---------- ----------
1 0
SCOTT@orcl_11g> select * from b;
no rows selected
SCOTT@orcl_11g> delete from a;
1 row deleted.
SCOTT@orcl_11g> select * from a;
no rows selected
SCOTT@orcl_11g> select * from b;
no rows selected
SCOTT@orcl_11g>
|
|
|
|
| Re: Trigger-summing values [message #364270 is a reply to message #360742] |
Sun, 07 December 2008 14:30 |
|
Kevin Meade
Messages: 2103
Registered: December 1999
Location: Connecticut USA
|
Senior Member |
|
|
Barbara and Michel, you two are awesome (as if we didn't already know that).
I now feel this post is complete. It covers the bases with actual working examples, and expresses several differing opinions on the matter. This is exactly the kind of material and expert opinions people need access to.
I thank the two of you for taking the time to finish off this work. I know it is not easy to take time out of your day to replay and I appreciate it. Your contributions have made this an outstanding thread.
Kevin
[Updated on: Sun, 07 December 2008 17:01] Report message to a moderator |
|
|
|
| Re: Trigger-summing values [message #364594 is a reply to message #364270] |
Tue, 09 December 2008 04:16 |
|
Michel Cadot
Messages: 68776
Registered: March 2007
Location: Saint-Maur, France, https...
|
Senior Member
Account Moderator |
|
|
The main problem when we think about triggers (standard or "instead of" ones) to implement such an aggregate feature is what happen in multi-user environment.
I post here 2 examples leading to deadlock. In the first example I use standard trigger and in the second one "instead of" one but you can switch the examples it works the same.
I have 3 sessions, the first one (SESSION0) just setup the case, the second (SESSION1) and third (SESSION2) ones (try to) modify the data and lock each other.
I put in the SQL prompt the session name and current time to follow the case. I slighty modify Barbara and Kevin triggers to output the current time and add a sleep to be sure to cause the deadlock.
In addition, each session and statement impacts a different B row. Session 1 only handles odd "b" and session 2 only even "b".
First case using updates
Setup
drop table a cascade constraints;
drop table b;
create table a (
a number not null primary key,
asum number default 0
)
/
create table b (
b number not null primary key,
a number not null,
anumber number default 0,
constraint b_fk1 foreign key (a) references a
)
/
insert into a (a) values (1);
insert into a (a) values (2);
create or replace trigger b_biudr
before insert or update or delete on b
for each row
begin
if inserting then
dbms_output.put_line('Insert '||systimestamp||': updating '||:new.a);
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
dbms_output.put_line('Insert '||systimestamp||': '||:new.a||' updated - end');
elsif deleting then
dbms_output.put_line('Delete '||systimestamp||': updating '||:old.a);
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
dbms_output.put_line('Delete '||systimestamp||': '||:old.a||' updated - end');
elsif updating then
dbms_output.put_line('Update '||systimestamp||': updating '||:new.a);
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
dbms_output.put_line('Update '||systimestamp||': '||:new.a||' updated - waiting');
dbms_lock.sleep(20);
dbms_output.put_line('Update '||systimestamp||': updating '||:old.a);
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
dbms_output.put_line('Update '||systimestamp||': '||:old.a||' updated - end');
end if;
end;
/
insert into b (b, a, anumber) values (1,1,100);
insert into b (b, a, anumber) values (2,1,200);
insert into b (b, a, anumber) values (3,2,400);
insert into b (b, a, anumber) values (4,2,800);
commit;
select * from b order by b;
select * from a order by a;
SESSION0> select * from b order by b;
B A ANUMBER
---------- ---------- ----------
1 1 100
2 1 200
3 2 400
4 2 800
4 rows selected.
SESSION0> select * from a order by a;
A ASUM
---------- ----------
1 300
2 1200
2 rows selected.
Session 1
08:55:23 SESSION1> update b set a=2 where b=1;
Update 09/12/2008 08:55:32.070 +01:00: updating 2
Update 09/12/2008 08:55:32.070 +01:00: 2 updated - waiting
Update 09/12/2008 08:55:52.070 +01:00: updating 1
update b set a=2 where b=1
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
ORA-06512: at "MICHEL.B_BIUDR", line 16
ORA-04088: error during execution of trigger 'MICHEL.B_BIUDR'
08:56:10 SESSION1>
Session 2
08:55:47 SESSION2> update b set a=1 where b=4;
Update 09/12/2008 08:55:48.211 +01:00: updating 1
Update 09/12/2008 08:55:48.211 +01:00: 1 updated - waiting
Update 09/12/2008 08:56:08.211 +01:00: updating 2
Update 09/12/2008 08:56:10.868 +01:00: 2 updated - end
1 row updated.
08:56:10 SESSION2>
Second case using inserts
Setup
drop table a cascade constraints;
drop table b;
create table a (
a number not null primary key,
asum number default 0
)
/
create table b (
b number not null primary key,
a number not null,
anumber number default 0,
constraint b_fk1 foreign key (a) references a
)
/
create or replace view v_b as select * from b;
create or replace trigger io_b
instead of insert or update or delete on v_b
for each row
begin
--
-- duplicate the logic of the original dml event
--
if inserting then
insert into b (b,a,anumber) values (:new.b,:new.a,:new.anumber);
elsif deleting then
delete from b where b = :old.b;
elsif updating then
update b set a = :new.a, anumber = :new.anumber where b = :old.b;
end if;
--
-- add the additional logic for maintaining the summary item (replicated data) on the parent table
--
if inserting then
dbms_output.put_line('Insert '||systimestamp||': updating '||:new.a);
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
dbms_output.put_line('Insert '||systimestamp||': '||:new.a||' updated - end');
elsif deleting then
dbms_output.put_line('Delete '||systimestamp||': updating '||:old.a);
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
dbms_output.put_line('Delete '||systimestamp||': '||:old.a||' updated - end');
elsif updating then
dbms_output.put_line('Update '||systimestamp||': updating '||:new.a);
update a set asum = nvl(asum,0) + nvl(:new.anumber,0) where a = :new.a;
dbms_output.put_line('Update '||systimestamp||': '||:new.a||' updated - waiting');
dbms_lock.sleep(20);
dbms_output.put_line('Update '||systimestamp||': updating '||:old.a);
update a set asum = nvl(asum,0) - nvl(:old.anumber,0) where a = :old.a;
dbms_output.put_line('Update '||systimestamp||': '||:old.a||' updated - end');
end if;
end;
/
insert into a (a) values (1);
insert into a (a) values (2);
insert into v_b (b, a, anumber) values (1,1,100);
insert into v_b (b, a, anumber) values (2,1,200);
insert into v_b (b, a, anumber) values (3,2,400);
insert into v_b (b, a, anumber) values (4,2,800);
commit;
select * from v_b order by b;
select * from a order by a;
SESSION0> select * from v_b order by b;
B A ANUMBER
---------- ---------- ----------
1 1 100
2 1 200
3 2 400
4 2 800
4 rows selected.
SESSION0> select * from a order by a;
A ASUM
---------- ----------
1 300
2 1200
2 rows selected.
Session 1
09:45:42 SESSION1> insert into v_b (b, a, anumber) values (5,1,1000);
Insert 09/12/2008 09:45:42.772 +01:00: updating 1
Insert 09/12/2008 09:45:42.772 +01:00: 1 updated - end
1 row created.
09:45:42 SESSION1> exec dbms_lock.sleep(20);
PL/SQL procedure successfully completed.
09:46:02 SESSION1> insert into v_b (b, a, anumber) values (7,2,1000);
Insert 09/12/2008 09:46:03.335 +01:00: updating 2
insert into v_b (b, a, anumber) values (7,2,1000)
*
ERROR at line 1:
ORA-00060: deadlock detected while waiting for resource
ORA-06512: at "MICHEL.IO_B", line 17
ORA-04088: error during execution of trigger 'MICHEL.IO_B'
09:46:12 SESSION1> rollback;
Rollback complete.
09:46:31 SESSION1>
Session 2
09:45:49 SESSION2> insert into v_b (b, a, anumber) values (6,2,2000);
Insert 09/12/2008 09:45:49.975 +01:00: updating 2
Insert 09/12/2008 09:45:49.975 +01:00: 2 updated - end
1 row created.
09:45:49 SESSION2> exec dbms_lock.sleep(20);
PL/SQL procedure successfully completed.
09:46:09 SESSION2> insert into v_b (b, a, anumber) values (8,1,2000);
Insert 09/12/2008 09:46:10.538 +01:00: updating 1
Insert 09/12/2008 09:46:31.148 +01:00: 1 updated - end
1 row created.
09:46:31 SESSION2>
Of course same things can happen when mixing insert/delete/update statements.
What can be seen as very strange for an external user (the one that tries to insert rows) is that he/she can get a deadlock just inserting.
This can't happen with materialized view solution as commits are handled in serialized way but I have to emphasize on the fact (already mentionned by Kevin) that correct sums are only available after commit, even for the session that modifies the data. That is, after modifying B data, the sum are wrong for the current transaction until it ends (commits or rolls back).
Add example of what I said in the previous paragraph:
Setup
drop view a_view;
drop materialized view a_mview;
drop table b;
drop table a;
create table a (a number not null primary key);
create materialized view log on a with rowid, sequence(a) including new values;
create table b (
b number not null primary key
,a number not null
,anumber number
,constraint b_fk1 foreign key (a) references a
)
/
create materialized view log on b with rowid, sequence(a, anumber) including new values;
create materialized view a_mview
refresh fast on commit
as
select a.a, sum(b.anumber) as asum,
count(*) as cnt1, count(b.anumber) as cnt2
from a, b
where a.a = b.a
group by a.a
/
alter table a_mview add primary key (a);
create or replace view a_view as
select a.a, nvl(mv.asum,0) as asum
from a, a_mview mv
where mv.a (+) = a.a
/
insert into a (a) values (1);
insert into a (a) values (2);
insert into b (b, a, anumber) values (1,1,100);
insert into b (b, a, anumber) values (2,1,200);
insert into b (b, a, anumber) values (3,2,400);
insert into b (b, a, anumber) values (4,2,800);
commit;
Test
SQL> select * from b order by b;
B A ANUMBER
---------- ---------- ----------
1 1 100
2 1 200
3 2 400
4 2 800
4 rows selected.
SQL> select * from a_view order by a;
A ASUM
---------- ----------
1 300
2 1200
2 rows selected.
SQL> update b set a=2 where b=1;
1 row updated.
SQL> select * from b order by b;
B A ANUMBER
---------- ---------- ----------
1 2 100
2 1 200
3 2 400
4 2 800
4 rows selected.
SQL> -- Before commit, sums are wrong
SQL> select * from a_view order by a;
A ASUM
---------- ----------
1 300
2 1200
2 rows selected.
SQL> commit;
Commit complete.
SQL> -- After commit, they are now correct
SQL> select * from a_view order by a;
A ASUM
---------- ----------
1 200
2 1300
2 rows selected.
Regards
Michel
[Edit: Added example about drawback of materialized view]
[Updated on: Wed, 10 December 2008 01:48] Report message to a moderator |
|
|
|
|
|
| Re: Trigger-summing values [message #364741 is a reply to message #364694] |
Tue, 09 December 2008 22:04 |
|
Kevin Meade
Messages: 2103
Registered: December 1999
Location: Connecticut USA
|
Senior Member |
|
|
OH MAN! I can't let that one go.
I also would like to say "nice work Michel".
In light of Barbara's remark (her opinion I value greatly (as I do with Michel's opinion also)), I believe there is still some clarification that should be made. I will start with repeating the words of Michel:
Quote:Of course same things [deadlock] can happen when mixing insert/delete/update statements.
This statement is important. One might read Michel's reply and think "aha! triggers cause deadlock; if instead I put the code to maintain my summary item somewhere else other than a trigger, the deadlock will go away". BUT THIS IS NOT TRUE.
Quote:Using triggers does not cause deadlock.
What causes deadlock is the sequence of events that one uses, in order to keep a summary on a parent row. In this regard the triggers here are nothing more than a packaging medium. We could have chosen at least three other packaging mediums for our summary maintenance code, none of which involves triggers and all of which would still be subject to potential deadlock: service orientied API, logic in client side applications, or no packaging at all as in just execute the stuff from sqlplus. It is the code we are trying to write (the code for keeping a summary in a parent record) that by its nature has the potential for deadlock, not the packaging medium used to present the code for execution (eg. not triggers).
Quote:If the same insert/update/delete sequence is written in a plsql api, the deadlock can still occur.
If the same insert/update/delete sequence is written into a client application, the deadlock can still occur.
If the same insert/update/delete sequence is executed from SQLPLUS, the deadlock can still occur.
So... triggers do not cause deadlock, triggers are just packaging. It is the insert/update/delete sequence required to maintain the summary item that holds the potential for deadlock in a multi-user environment.
More correctly, it is the choice to use a "transaction consistent procedural" solution to keep the summary which allows for possible deadlock in a multi-user environment. We have seen from the proposed solutions in this thread, some solutions which are transaction consistent, and some which are not. Also, our solutions are sometimes procedural in nature and sometimes not (definitional so to speak). We can use a cross classification table to show how this breaks down and hopefully, finally put triggers into the correct light.
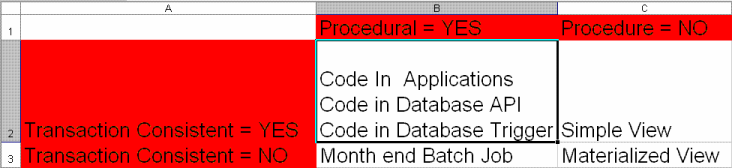
This cross classification table is based on a set of characteristics exhibited by the solutions to the OP problem. Each of the four cells in this table lists a potential solution(s) based on the characteristics of Procedureal/NON-Procedural vs. Transaction Consistent/NON-Transaction Consistent. As we can see, solutions involving TRIGGERS/API CODE/CLIENT APPLICATION CODE are all procedural and transaction consistent. The simple view solution is non-procedural and transaction consistent, the materialized view is non-procedural and non-transaction consistent, and an accounting period batch job that could be used to sum up our totals at the end of an accounting process, would be procedural and non-transaction consistent.
Transaction consistent for our purposes here means that the transaction which made the change to our data, can see the results of each change immediatly after making it. Procedural means we write regular code in order to make things happen, where as NON-Procedural means we define some object with a definition that does the work for us.
This cross classification table is nice in helping us to organize options, but what really helps is the same cross classification listing the pros/cons of our solutions, instead of the actual mechanisms themselves. Here is this cross classification table.
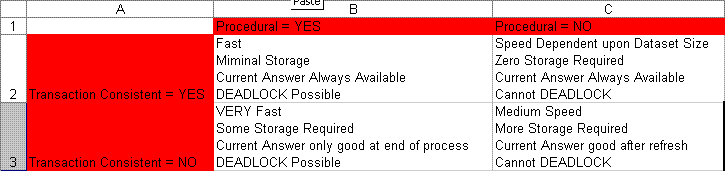
As you can see, this is the same table but rather than listing alternative solutions in the cells, we list the pros/cons of those solutions instead. Now we have a really useful piece of information in this table. Why? Because this cross classification table helps the OP evaluate alternatives when deciding on an approach to solving their problem.
Below reposted for convenience is the ER diagram the OP provided, covering the problem space. Forgetting that the OP was asked to solve their problem by using triggers, the original problem that spawned everything was the desire to see the TOTAL BILLABLE AMOUNT for an account managed by a phone service. Let us make believe we are AT&T. We want access to something called TOTAL BILLABLE AMOUNT for each account. The ER diagram tells us that this amount will be based on the cost of equipment leased by the account, the cost of soft-phone features used by the account, and what if any extra costs or discounts are allowed for under the plan purchased by the account. So...
Quote:QUESTION: How do we provide access to TOTAL BILLABLE AMOUNT?
ANSWER: We cannot provide an answer yet. We cannot provided an answer yet because we have not mapped our actual need to the characteristics as presented in cross classification table #2. We first determine which cell in cross classification table #2 is the best fit for the need we want to address. Once this is done, we use the solution as indicated by our choice of cell, mapped back to cross classification table #1.
To demonstrate we can analyze several different scenarios and see what falls out:
1) If our main purpose for wanting to see TOTAL BILLABLE AMOUNT is because we need to produce a monthly bill for each account so that we can bill them and get paid, we do not need a transaction consistent solution because the total will be updated once at the end of the month, and we do not need to commit storage space to keeping a second list of changes (think materialized view log) in order to compute this total, because we can sum from the detail data which is already available. The most appropriate solution would be MONTH END BATCH JOB.
2) If our main purpose for wanting to see TOTAL BILLABLE AMOUNT is to support our CSRs (Customer Service Reps), because they deal with customers calling in disputing their monthly bills all month long, then we likely should go with the materialized view solution. The materialized view with REFRESH ON COMMIT would be accurate up to when the CSR checked the data. The MVIEW looks good. We don't need a transaction consistent solution, but we need something way more current than month end.
3) If our main purpose for wanting to see TOTAL BILLABLE AMOUNT is to see the affect of changes made to the amount as we add changes in or when we are done adding all changes in but before we are finished(maybe we need to see that the answer falls above some limit and thus need to trigger additional processing before we commit), then we need one of the transaction consistent solutions. If our dataset is small and we only want to check results at the end of each transaction, then the simple view sounds like the way to go because of its ease of implementation. But if the datasets we are summing are large then the simple view may quickly become very expensive as each time we use it we could be visiting lots of rows for summing. In this situation we should consider going to a transaction consistent procedural solution. We see from our first cross classification table this means one of CLIENT CODE/API/TRIGGERS. Inclined to using database oriented solutions as I am, I would choose instead-of-triggers.
Clearly these cross classifications tables and this analysis shows that the simple view solution is not "SUPERIOR" to anything. None of the solutions is superior. Rather, each is a best fit for a specific scenario. Which ever scenario you are addressing, use the solution that fits it best.
However, although we have talked about using instead-of-triggers to maintain a summary item, I have said that this is a trivial use of this feature of Oracle. I have consistently maintained all throughout this discussion that the real power of instead-of-triggers is not demonstrated by being able to keep a summary total, but rather that instead of trigger were meant for way bigger things this. The power of instead-of-triggers is not in getting them to do things that can be seen, but rather, in getting them to do things that are not seen. It is the ability of instead-of-triggers to do things without anybody or any code knowing about it that makes them great. The concept of doing LOGICAL DELETE with instead-of-triggers which I presented earlier in this thread, is one such example. My point with LOGICAL DELETE via instead-of-triggers is that this is a solution which requires zero application changes to implement. An feat which has yet to be commented on. How can anyone call instead-of-triggers a "bad idea" when they can do such wonderful things for us. Indeed even the example of LOGICAL DELETE is but a small glimpse into the world of instead-of-triggers. Instead-of-triggers lead eventually the the idea of a HYPOTHICAL VIEW and in turn to the idea of WORKSPACE SCHEMAS which are extremely powerful and which I will be talking about in some ORAFAQ papers to come.
And once again I want to offer my thanks to Barbara and Michel for their time and willingness to continue this conversation, and to you for having read it all. I hope someone is learning something from the three of us about it all.
Kevin
[Updated on: Tue, 03 April 2012 03:04] by Moderator Report message to a moderator |
|
|
|
| Re: Trigger-summing values [message #364752 is a reply to message #364741] |
Tue, 09 December 2008 23:20 |
|
Barbara Boehmer
Messages: 9106
Registered: November 2002
Location: California, USA
|
Senior Member |
|
|
Kevin,
Perhaps my point of view would have been clearer if I had said that using a view to obtain a sum is superior to using triggers to maintain a summary column or any other method of maintaining a summary column, as maintaining a summary column is something that should not be done. But this was already said back in the beginning of this discussion. I have nothing against triggers. This is just not an appropriate use for them. The problem may be that you have picked a thread about maintaining a summary column to demonstrate how instead of triggers work in a situation that is inappropriate for an instead of trigger or any other trigger, because the summary column should not be maintained through a trigger, a procedure, or any other method. There should not be a summary column, when the information can be selected at any time with plain sql or in a view. All I am saying is that if you want to sum something, then you should select it or use a view, not try to maintain a summary column through a trigger, procedure, or any other means. I know you said you wanted to put this issue to rest once and for all, but at some point we may need to resign ourselves to the idea that Michel and I and whoever are not going to be able to convince you and whoever. It seems like you think you are defending triggers in general as if I were putting down triggers in general, but I am not. I am just saying don't use triggers or any other method to maintain a summary column. Don't use a summary column.
It seems to me that if deadlocks can occur in a multi-user environment with some method, that outweighs everything else. If you have a bunch of people unable to do input due to deadlocks, that makes your whole system pretty useless and far outweighs any added query time. This is one of those issues that is big enough that it should eliminate any method that causes deadlocks. To me it seems just incredible that you are acknowledging that this can happen when using a trigger or any other method to maintain a summary column and still considering that it might be an appropriate thing to do. Unless you have a data warehouse situation, then any normal system is going to need to allow inputs and queries.
[Updated on: Tue, 09 December 2008 23:33] Report message to a moderator |
|
|
|
|
|
|
|
|
|
| Re: Trigger-summing values [message #509506 is a reply to message #509502] |
Sat, 28 May 2011 19:26 |
ThomasG
Messages: 3212
Registered: April 2005
Location: Heilbronn, Germany
|
Senior Member |
|
|
While the thread is already three years old, the STOCK_ITEM is an excellent example I think, because it shows the problem of storing computed values, but also shows that sometimes it is necessary.
We support two applications that were written in the "store the computed value" way. And there are also regrets. Basically here are the main problems I see which each approach, consider the example of "employee loading a order-suggestion that should also display the items in stock for each item":
1) Normal view or calculated on the fly: The query would be too performance intensive.
2) Materialized view: Would not update fast enough. When an item is sold, it should be "Out of stock" immediately, and the transaction that puts it out of stock should already be aware of it.
3) The stored value approach: The values become incorrect over time due to software bugs or other problems.
So basically problems 1) and 2) are a massive everyday problem for *everyone*, while 3) is something that happens (at least in our case) perhaps one or two times a week for a single item and a single employee that has the problem.
Some years back it was a worse problem, where perhaps 60-70% of "wrong item in stock" was due to a bug, and the rest was due to wrong data entry. We are now to perhaps 10% that is left that are bugs, 90% is wrong user input.
Also, what we now have in place is basically a combination. The main approach is still:
"Store the items in stock, and deduct items that are sold, and add items that are received". That of course has the problem that the same item in the same store can't be sold or booked in at the same time, because doing it requires a lock on that row.
For the application that doesn't matter much. The data from the cash registers is read in a serialized server process, and that two people are working on the same item in receiving is also pretty much impossible.
The *additional* approach is, that in a night run we check all STOCK_ITEM values that have changed in the last three days against the computed value (last inventory +/- bookings) to spot errors, and then correct them in case they occur.
But I would like to point out that NONE of that is happening in a trigger, it is happening in the procedure that creates booking documents.
[Updated on: Sat, 28 May 2011 19:27] Report message to a moderator |
|
|
|
| Re: Trigger-summing values [message #509508 is a reply to message #509506] |
Sat, 28 May 2011 19:45 |
 |
sam10
Messages: 13
Registered: May 2011
Location: Los Angeles
|
Junior Member |
|
|
If i understand you correctly, you are not computing the QTY_ONHAND real time in your system. correct?
Here is an approach i did which works pretty well.
I created an MV that computes all the stock ONHAND_QTY every night based on all transactions (shipments, receipts) that occured during the day.
At the same time, I have another STOCK_OVERRRIDE table, so if stock XYZ was shipped during the day I read the values stored in the MV and then subtract the new shipment QTY from it and store it in the OVERRIDE table.
The system will read ONHAND_QTY from the OVERRIDE if there is an entry for XYZ in that table.
Every night after i REFRESH the MV we clean up the OVERRIDE table.
In you situation, if you have multiple users you can do PESSIMISTIC or OPTIMSIITC LOCK o nthe XYZ row so if a two people execute transactions same time, one will be accpeted and second one will have to be redone until the first one updates the ROW so you can a fresh value to add/substract from.
|
|
|
|
Goto Forum:
Current Time: Sun Apr 19 13:49:22 CDT 2026
|





